論文:https://arxiv.org/abs/2402.14207
法学修士に、信頼できる情報源に基づき、ゼロから長文を書くことを教えられるだろうか?
ウィキペディアの編集者は、これが自分たちの役に立つと思っているのだろうか?
インターネット検索に基づいてウィキペディア風の記事を書くシステム、STORMを発表します。私は今、日々の研究でSTORMを使っている!
引用を伴う長文の記事を作成するのは難しいし、評価も難しい!
これを2つのステップに分ける:
1️ ⃣ システムが参考文献を収集し、アウトラインを生成するプリライティング。
2️⃣ 執筆。このシステムでは、引用を含む最終的な記事が生成される。

「プレ・ライティング」とは、トピックをゼロからリサーチすること。
これは人間の専門家でも難しい。言語モデル生成の問題を直接促してもうまくいかない!これらの問題には深みがなく、幅も狭い。
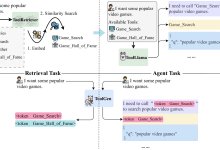
STORMは言語モデリングを教えることを目的としている。

STORMは、研究トピックに関する視点を自動的に発見し、プロンプトに視点を追加することで、質問を改善します。また、情報探索の対話をシミュレートし、より詳細なフォローアップの質問を促すこともできます。

FreshWikiを構築することで、評価用のLMトレーニングデータへのデータ漏洩を抑えた。
品質を測定するために、見出しのソフト・リコールと見出しのエンティティ・リコールを導入した。アウトライン評価により、プロトタイピング手法の事前記述が容易になる。
STORMはよく設計されたRAGベースラインよりも優れている!

最終的な執筆段階では、STORMは引用を含むテキストを生成し、セクションごとに完全な記事を執筆する。
任せる ストーム 生成された記事は、自動化された指標と*経験豊富なウィキペディア編集者によって好まれている!

この例示的な文章は、常に事実に根ざしたものでなければならない。
我々は引用の質を評価し、ウィキペディア編集者に検証可能性を評価してもらった。主な課題は、広く議論されている事実誤認から会話をシフトさせることであることがわかった。
そのためには、ファクトチェック以上のリサーチが必要だ!

また、ウィキペディアの編集者にもSTORMの有用性について尋ねた。エキサイティングなことに、参加者全員が、STORMが執筆前の段階で役立つことに同意しました。さらに、私自身もSTORMを使って、研究のコンセプトを深く掘り下げています(デモビデオをまだご覧になっていない方は、こちらをクリックしてください)。

注目すべきは、STORMはよく設計されたナレッジ・マネジメント・パイプラインであり、単一のヒントやモデルではないということだ。
私たちはSTORMの構築にDSPyを使用しています。DSPyは非常に優れたモジュール性を備えており、多くのヒントファイルに惑わされることなく作業を拡張し続けることができます。