基本コンセプト
情報技術の分野では。検索 とは、大規模なデータセット(通常は文書、ウェブページ、画像、音声、動画、その他の形式の情報)から、ユーザーのクエリーやニーズに基づいて関連情報を効率的に探し出し、抽出するプロセス。 その中心的な目的はユーザーのニーズに最も適した情報そして、それをユーザーに提示する。
- クエリーユーザーが入力した検索語や検索条件。
- インデックス検索効率を高めるためにデータを前処理するデータ構造。
- 関連性検索された結果がクエリと一致する度合い。
大規模なモデル知識ベースの構築に基づくRAGスキームは、単一の「検索」技法、例えば、一般的に使用される:スパース+密なハイブリッド検索を使用しないことが多い。検索手法の選択は、検索されるコンテンツに注意深く適合させる必要があり、多くのデバッグを必要とする。

主流の検索モデル
検索モデルは主に、ブーリアンモデル、ベクトル空間モデル、確率モデル、ニューラルネットワークモデル、グラフモデル(知識グラフなど)、言語モデル(GPT3など)に分類される。
主な検索モデルは "単純に "2つのカテゴリーに分けられるが、核となる違いはテキストをどのように理解し、マッチングさせるかである:
1.語彙/キーワードベースのマッチング。
このタイプのモデルは、クエリとドキュメントに焦点を当てる。文字通りの言葉合わせ言葉の背後にある意味を深く理解することなく。
-
核となる考え。 文書やクエリに含まれる単語の出現回数を数え、それらを照合する。
-
主なモデル
-
ブールモデル。 単にキーワードの有無(AND、OR、NOT)に基づいてマッチする。
-
ベクトル空間モデル(VSM)。 文書とクエリは単語の重みのベクトルとして表現され、ベクトルの類似度(コサイン類似度など)によって照合される。一般的な重み付け方法はTF-IDFである。
-
BM25。 文書の長さなどを考慮した確率統計に基づく改良されたモデルは、多くの検索エンジンの基礎となっている。
-
長所だ。 シンプルで、効率的で、導入しやすい。
デメリット 単語の意味的関係を理解できず、類義語や多義語などの問題に陥りやすい。
2.意味/意味に基づくマッチング。
意味ベースの埋め込みモデルは、異なる埋め込みテキストの長さと次元をサポートすることに加えて、埋め込みモデルによって「文章」の理解方法も異なるため、埋め込みモデルの選択において優先される(ほとんどの埋め込みモデルはより一般的なモデルを使用しているが)。
例えば、"apple "という単語は、あるモデルでは "fruit "よりも意味的に好まれ、他のモデルでは "mobile phone "よりも好まれる。
このようなモデルは、クエリとドキュメントを理解しようとする。深い意味情報表面的な言葉の一致にとどまらない。
-
核となる考え。 テキストを意味空間にマッピングし、意味的類似性によってマッチングする。
-
主なモデル
-
トピックモデル。 トピックの類似性(LDAなど)によって検索された潜在的なトピックのために文書をマイニングする。
-
モデルを埋め込む。 単語、文、文書を低次元の密なベクトル空間にマッピングすることで、意味情報を取得する。
-
単語の埋め込み。 例えば、Word2Vec、GloVe、FastTextなどがある。
-
文の埋め込み。 例えば、Sentence-BERT、Universal Sentence Encoderなどがある。 OpenAIエンベッディング.
-
-
密な検索モデル。 クエリとドキュメントは、ディープラーニングモデル(通常はTransformer)を使って高次元の密なベクトルにエンコードされ、ベクトルの類似性によって検索される。例としては、DPR、Contriever、そして OpenAIエンベッディング 構築された検索システム。
-
神経相互作用モデル。 ColBERTやRocketQAなど、クエリとドキュメント間の相互作用のよりきめ細かなモデリング。
-
グラフニューラルネットワークモデル。 文書とクエリはグラフに構築され、グラフ構造を使って検索される。
-
長所だ。 テキストの意味をよりよく理解し、意味的な関連性に対処し、関連する情報をより正確に見つける能力。
デメリット 通常、より複雑で計算コストがかかる。
大きな違いだ:
-
レキシカル・マッチング・モデルは "リテラル "に見えるキーワードの出現に焦点を当てる。
-
意味照合モデルは "意味 "に注目するテキストの本質的な意味と関係に焦点を当てる。
総括表:
| 分類 | コア・アイデア | 主なモデル | ラグ アプリケーション・フォーカス |
| 語彙ベースのマッチング | 文字通りの言葉合わせ | ブールモデル、ベクトル空間モデル(VSM)、 BM25 | 初期またはシンプルなシナリオ |
| 意味ベースのマッチング | 深い意味情報を理解する | トピックモデル、単語埋め込みモデル、文埋め込みモデル(を含む OpenAIエンベッディングに基づくものを含む)、密な検索モデル。 OpenAIエンベッディング システム)、ニューラルネットワーク相互作用モデル、グラフ・ニューラル・ネットワーク・モデル | 文の埋め込みと集中的な検索に特に重点を置いた主流セレクション |
RAGでのアプリケーション
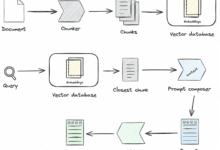
RAG (検索-拡張世代)は、検索技術と生成技術を組み合わせたAIフレームワークで、主な用途は、生成されたコンテンツの精度と文脈上の関連性を向上させることである。
- 検索ステージ大規模な知識ベースから、ユーザーの入力に関連する文書や文章を特定する。
- 生成段階検索された情報を文脈として利用し、回答やコンテンツを生成する。
RAGでは、検索モデルが質の高い情報源の提供を担当し、生成モデルがこの情報に基づいて自然言語の回答を生成する。RAGは外部の知識源から最新の情報を得ることができるため、知識集約的な質問に答える際に特に優れた性能を発揮する。
RAGのアプリケーションフォーカス:
RAG (Retrieval Augmentation Generation)にて。意味的マッチングモデルが好まれることが多いなぜなら、ユーザーのクエリに関連する文脈情報をより正確に取得できるため、生成モデルがより正確で首尾一貫した回答を生成するのに役立つからである。 特に文埋め込みモデルと高密度検索モデル例えば OpenAIエンベッディング その優れた意味表現能力と検索効率により、RAGシステムで広く使用されている。
判例
1.語彙検索の応用 (語彙検索)
-
核となる考え方 検索システムは、クエリと文書に大きく依存している。文字通りのキーワードマッチング.
-
ケース1:技術文書から特定のコマンドを見つける
-
シーン あるソフトウェアを使用していて、ファイルコピー操作の方法を知りたいと思い、関連するコマンドを探す必要がある。
-
検索メカニズム: RAGシステムは、語彙ベースのモデル(BM25など)を使用して、「コピーファイル」、「ファイルコピーコマンド」、「コピーファイル」というキーワードを含む文章をソフトウェアのヘルプ文書から検索する。
-
検索結果の例 システムは、「ファイル管理コマンド」と題されたドキュメントのセクションの中に、「Using the File Management Commands(ファイル管理コマンドの使用)」というセクションを見つけることができる。 cp 以下は「ファイルをコピーするコマンド」の説明である。
-
どのように生成に貢献するか: 検索されたインクルード・コマンドの具体的な指示は生成モデルに提供され、生成モデルはより正確な操作手順を生成することができる。 cp コマンドでファイルをコピーする。例えばcp source.txt destination.txt はsource.txtをdestination.txtにコピーします。"
-
重要なポイント 検索は、キーワードの完全一致に依存しています。異なるフレーズ、例えば "文書の移動コピー "を使用した場合、同じ結果が検索されない可能性があります。
-
-
ケース2:カタログから特定のモデルを探す
-
シーン 特定のモデルのプリンタを購入したい。
-
検索メカニズム: RAGシステムは、正確なモデル名「XYZ-123」を含むエントリーをカタログデータベースから検索します。
-
検索結果の例 プリンター XYZ-123」に関するIT製品やセミナー情報、最新ニュースならキーマンズネット。
-
どのように生成に貢献するか: 検索された製品情報は、プリンターモデルの紹介、価格問い合わせ、購入リンクなどを作成するために直接使用することができます。
-
重要なポイント 製品モデルの正確なマッチングに依存する。ユーザーが「高性能プリンター」のような漠然とした説明を入力した場合、用語ベースの検索はうまく機能しない可能性があります。
-
2.セマンティック検索アプリケーション
-
核となる考え方 検索システムは、クエリと文書を理解する。深い意味情報全く同じキーワードでなくても、関連するコンテンツを見つけることができる。
-
ケース3:医学文献から病気の症状に関する情報を見つける
-
シーン "高血圧が引き起こす一般的な不快症状とは何か "を知りたいですか?
-
検索メカニズム: RAGシステムは、意味ベースのモデル(例えば、Sentence-BERTやOpenAI Embeddingsに基づく密検索)を使用して、クエリと医学文献をベクトル化し、次に意味空間においてクエリベクトルに最も近い通路を見つける。例えば、「高血圧」の代わりに「血圧上昇」を使用したり、「倦怠感」の代わりに具体的な症状説明を使用するなど、文書に全く同じ文言が含まれていなくても、検索することができる。検索できる。
-
検索結果の例 高血圧の人は、頭痛、めまい、胸のつかえなどの症状を訴えることが多い。高血圧をコントロールできない状態が長く続くと、動悸や呼吸困難につながることがあります。"
-
どのように生成に貢献するか: 高血圧は、頭痛、めまい、胸のつかえなど、さまざまな不快感を引き起こすことがある。高血圧が重症化したり長引いたりすると、動悸や呼吸困難を引き起こすこともある。"
-
重要なポイント 同義語(「血圧上昇」対「高血圧」)、近接表現(「身体的不快感」対「頭痛、めまい")や、より豊かな文脈を提供する関連概念を理解できる。
-
-
ケース4:創作支援で似たようなスタイルの文章を見つける
-
シーン あなたはSF小説を書いていて、インスピレーションを得るために似たような文体の文章を探したいと思っている。あなたは「そびえ立つビルと交通量の多い、繁栄した未来都市のビジョンを描写せよ」とタイプする。
-
検索メカニズム: RAGシステムは、セマンティック・ベースのモデルを使って、SFの膨大な文章を検索し、「未来都市」や「ブーム」といったキーワードが正確に使われていなくても、あなたの説明に意味的に最も近い文章を探します。
-
検索結果の例 鋼鉄の巨体が雲を貫き、ガラスのカーテンウォールが色とりどりの光を反射する。空飛ぶ車はビルとビルの間をシャトルのように行き来し、地上は人ごみで賑わい、エネルギーのうなり声が眠らない街を満たしている。"
-
どのように生成に貢献するか: 似たようなムードや描写の文章を取得すると、生成モデルの参考資料として使用でき、より希望するスタイルに沿った文章を作成するのに役立ちます。
-
重要なポイント テキストの暗黙的な意味、感情的な色合い、スタイルを理解できることは、単純なキーワードマッチングを超え、意味的な類似性に重点を置くことになる。
-
![エージェントAI:マルチモーダルインタラクションのフロンティアの世界を探る [フェイフェイ・リー - クラシック必読] - チーフAIシェアリングサークル](https://www.aisharenet.com/wp-content/uploads/2025/01/6dbf9ac2da09ee1-220x150.png)