このかた チャットグット GPT-1のパラメータ数は1億1700万(117M)だったが、第4世代のGPT-4のパラメータ数は1兆8000億(1800B)に更新された。
ブルーム(1760億、176B)やチンチラ(700億、700B)といった他のLLMモデルと同様、パラメータの数も急増している。パラメータ数はモデルの性能と能力に直接影響し、パラメータ数が多いほど、モデルはより複雑な言語パターンを扱い、より豊富な文脈情報を理解し、幅広いタスクでより高いレベルの知能を発揮できることになる。
しかし、これらの巨大なパラメータは、LLMの学習コストや開発環境にも直接影響し、多くの一般研究企業によるLLMの探求を制限し、その結果、大きな言語モデルは次第に大企業間の軍拡競争になりつつある。
最近、新興のAI企業であるTensorOperaが、次のものを発表した。オープンソース小型言語モデルFOXスモール・ランゲージ・モデル(SLM)がインテリゲンチャの分野でも十分な力を発揮できることを業界に証明した。

FOXはクラウドとエッジ・コンピューティングのために設計された小さな言語モデル.何百億ものパラメータを持つ大規模な言語モデルとは異なり、FOX わずか16億パラメータコンピュータを最大限に活用するための素晴らしい方法だが、複数のタスクにまたがって驚異的なパフォーマンスを見せることができる。
論文のタイトル
FOX-1テクニカルレポート
論文へのリンク
https://arxiv.org/abs/2411.05281

TensorOperaとは?
TensorOperaは、カリフォルニア州シリコンバレーに拠点を置く革新的な人工知能企業です。以前は、TensorOpera® AI Platform生成AIエコシステムとTensorOpera® FedML連邦学習・分析プラットフォームを開発していました。社名のTensorOperaは、テクノロジーとアートを組み合わせたもので、GenAIが最終的にマルチモーダルかつマルチモデルの複合AIシステムを開発することを象徴しています。

TensorOperaの共同設立者兼CEOであるジャレド・カプラン博士は、「FOXモデルはもともと、高いパフォーマンスを維持しながら、必要な計算リソースを大幅に削減するために設計されました。これはAI技術をより身近なものにするだけでなく、企業にとっての利用障壁を下げるものです。"
フォックスのモデルはどのように機能するのか?
より少ないパラメーター数でLLMと同じ効果を得るために、Fox-1モデルはデコーダのみアーキテクチャーにさまざまな改良と再設計を加え、パフォーマンスを向上させた。これらには以下が含まれる。
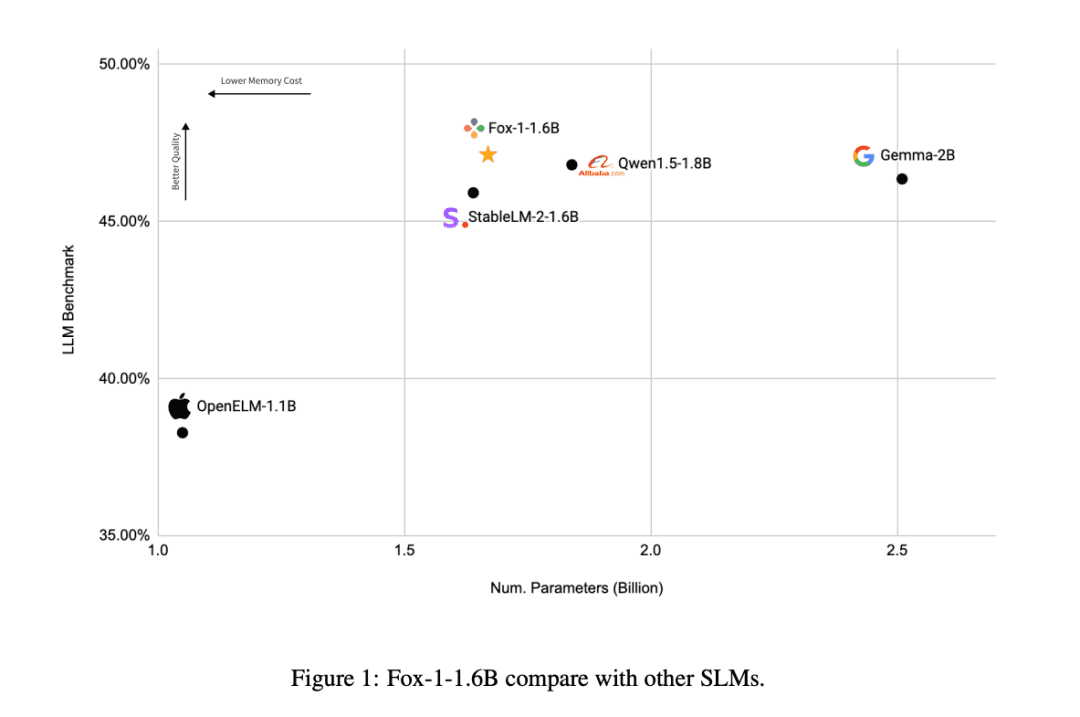
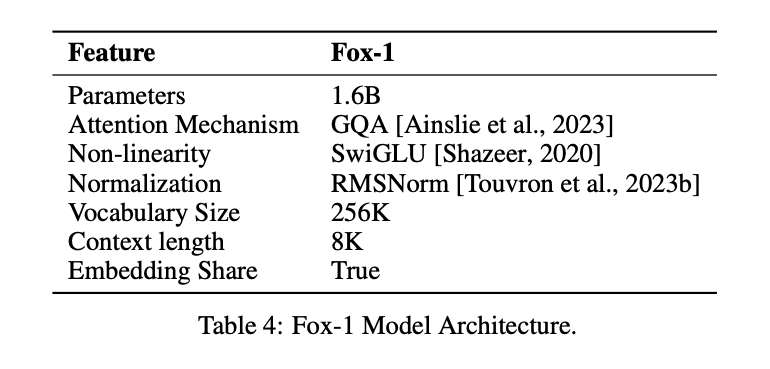
① ネットワーク層モデル・アーキテクチャの設計においては、より広くて浅いニューラルネットワークの方が記憶能力が高く、より深くてスリムなネットワークの方が推論能力が高い。この原則に従い、Fox-1は最新のSLMよりも深いアーキテクチャを採用している。これはGemma-2B(18層)よりも781 TP3T深く、StableLM-2-1.6B(24層)やQwen1.5-1.8B(24層)よりも331 TP3T深い。
② 共有エンベッディングFox-1は2,048の隠れ次元を使用し、約5億のパラメータを持つ256,000の語彙を構築する。より大規模なモデルでは通常、入力層(語彙から埋め込み表現)と出力層(埋め込み表現から語彙)に別々の埋め込み層が使われる。Fox-1の場合、埋め込み層だけで10億個のパラメータが必要になる。パラメータの総数を減らすために、入力と出力の埋め込み層を共有することで、重みの利用を最大化することができる。
三 正規化前Fox-1は各変換レイヤーの入力を正規化するためにRMSNormを使用します。RMSNormは、最新の大規模言語モデルにおける事前正規化のための好ましい選択であり、LayerNormよりも優れた効率を示します。
④ ロータリーポジションエンコーディング(RoPE)Fox-1は、デフォルトで8Kまでの長さの入力トークンを受け入れ、より長いコンテキストウィンドウでのパフォーマンスを向上させるために、θを10,000に設定した回転位置エンコーディングを使用します。 トークン の相対的な位置依存性
⑤ グループクエリーアテンション(GQA)Fox-1は4つのキー・バリュー・ヘッドと16のアテンション・ヘッドを備え、学習と推論のスピードを上げ、メモリ使用量を削減する。
構造的な改善のモデリングに加えFOX-1はまた、トークン化とトレーニングを改善する。.
品詞Fox-1はSentencePieceベースのGemma分類器を使用しており、語彙サイズは256Kである。語彙サイズを大きくすると、少なくとも2つの利点がある。第一に、各トークンがより高密度の情報をエンコードするため、文脈中の隠れた情報の長さが長くなる。例えば、サイズ26の語彙では[a-z]の1文字しかエンコードできないが、サイズ262の語彙では2文字を同時にエンコードできるため、固定長のトークンでより長い文字列を表現できるようになる。Fox-1が使用する大きな語彙は、与えられたテキストコーパスに対してより少ないトークンを生成し、より良い推論性能をもたらす。
フォックス-1事前学習データRedpajama、SlimPajama、Dolma、Pile、Falconの各データセット、合計3兆件のテキストデータを使用。注意メカニズムによる長いシーケンスの事前学習の非効率性を軽減するため、Fox-1は事前学習段階で3段階のカリキュラム学習戦略Fox-1は3段階のコース事前学習パイプラインであり、学習サンプルのチャンク長を2Kから8Kへと徐々に増加させ、少ないコストで長い文脈能力を確保する。Fox-1は、3段階のコース事前学習パイプラインと整合させるために、生データを3つの異なるデータセットに再編成する。3つの異なるデータセットには、教師なしデータセットとインストラクションチューニングデータセットがあり、コード、ウェブコンテンツ、数学文書、科学文書などの異なるドメインのデータも含まれる。
Fox-1のトレーニングは3つの段階に分けられる。.
- 最初のフェーズでは、1兆500億トークンデータセットを2,000の長さのサンプルに分割し、バッチサイズを2Mとする。
- 実際のチャンク長はデータソースによって異なる。第2フェーズは最も時間がかかり、異なるデータセットの異なるソースを含むことを考慮し、バッチサイズも4Mに増加させ、学習効率を向上させる。
- 最後に、第3段階では、62億トークン(全体の約0.02%)の高品質データを使ってFoxモデルを学習し、コマンドフォロー、スモールトーク、ドメイン固有のQ&Aなど、さまざまな下流タスク能力の基礎を築く。
Fox-1の成績は?
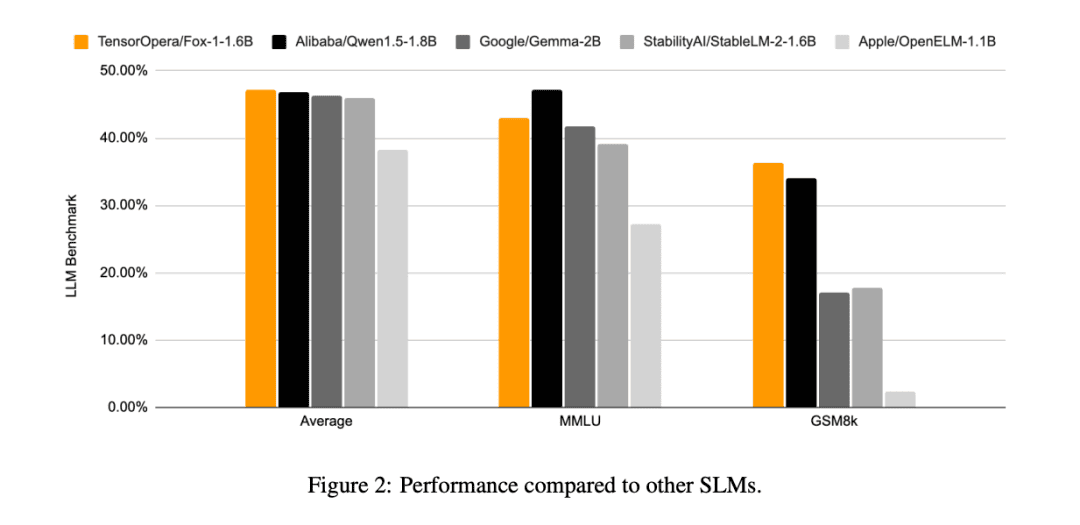
他のSLMモデル(Gemma-2B、Qwen1.5-1.8B、StableLM-2-1.6B、OpenELM1.1B)と比較すると、FOX-1はARCチャレンジ(25ショット)、HellaSwag(10ショット)、TruthfulQA(0ショット)、MMLU(5ショット)、Winogrande(5ショット)、GSM8k(5ショット)、GSM8k(5ショット)、GSM8k(5ショット)でより成功している。MMLU(5ショット)、ウィノグランデ(5ショット)、GSM8k(5ショット)6つのタスクのベンチマークの平均スコアはGSM8kが最も高く、著しく優れていた。
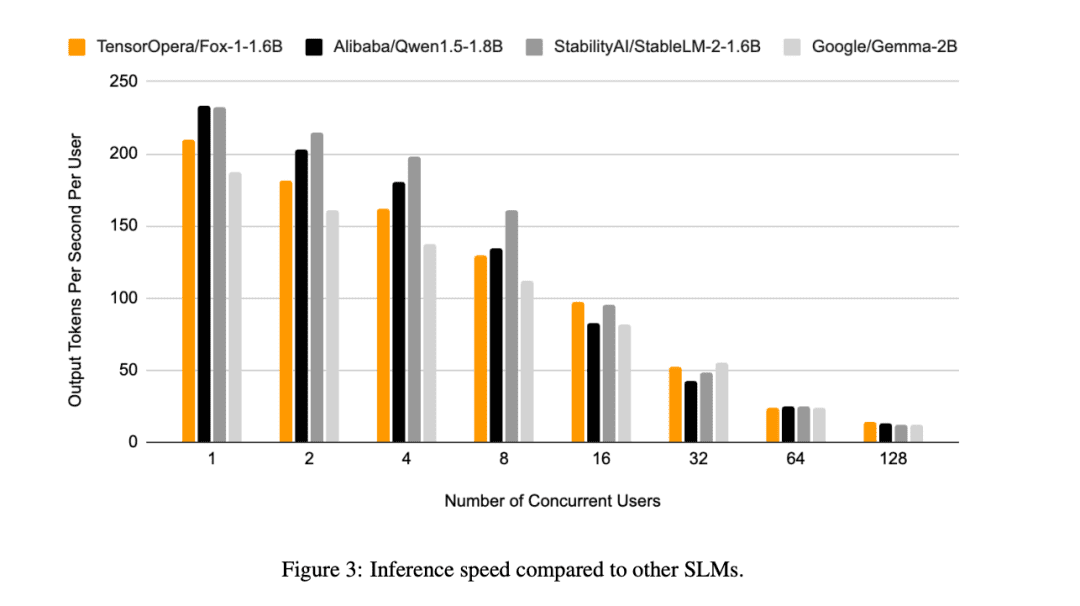
これに加えて、TensorOperaは、Fox-1、Qwen1.5-1.8B、Gemma-2Bを以下の方法で評価した。 ブイエルエルエム シングルNVIDIA H100上のTensorOperaサービスプラットフォームによるエンドツーエンドの推論効率。
Fox-1は毎秒200トークンを超えるスループットを達成し、Gemma-2Bを上回り、同じデプロイ環境ではQwen1.5-1.8Bに匹敵します。BF16精度では、Fox-1が必要とするGPUメモリはわずか3703MiBであるのに対し、Qwen1.5-1.8Bは4739MiB、StableLM-2-1.6Bは3852MiB、Gemma-2Bは5379MiBを必要とする。
パラメータは小さいが、競争力はある
各AI企業が大規模言語モデルでしのぎを削る中、TensorOperaはSLM領域を突破し、わずか1.6BでLLMと同様の結果を出し、各種ベンチマークでも好成績を収めるなど、異なるアプローチをとっている。
限られたデータリソースでも、TensorOperaは競争力のあるパフォーマンスで言語モデルを事前学習することができ、他のAI企業が開発するための新しい考え方を提供する。