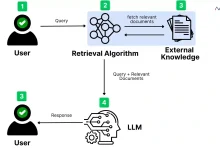
検索補強型生成(RAG)は、AI分野において重要なフレームワークとなっており、外部の知識ソースを用いて応答を生成する際の大規模言語モデル(LLM)の精度と関連性を大幅に向上させている。以下のように データブリック このデータによると、企業におけるLLMアプリケーションのうち60%が検索機能付きジェネレーション(RAG)を使用しており、30%がマルチステッププロセスを使用している。 43%の精度向上ということを示している。 ラグ AIが生成するコンテンツの品質と信頼性を向上させる大きな可能性を秘めている。
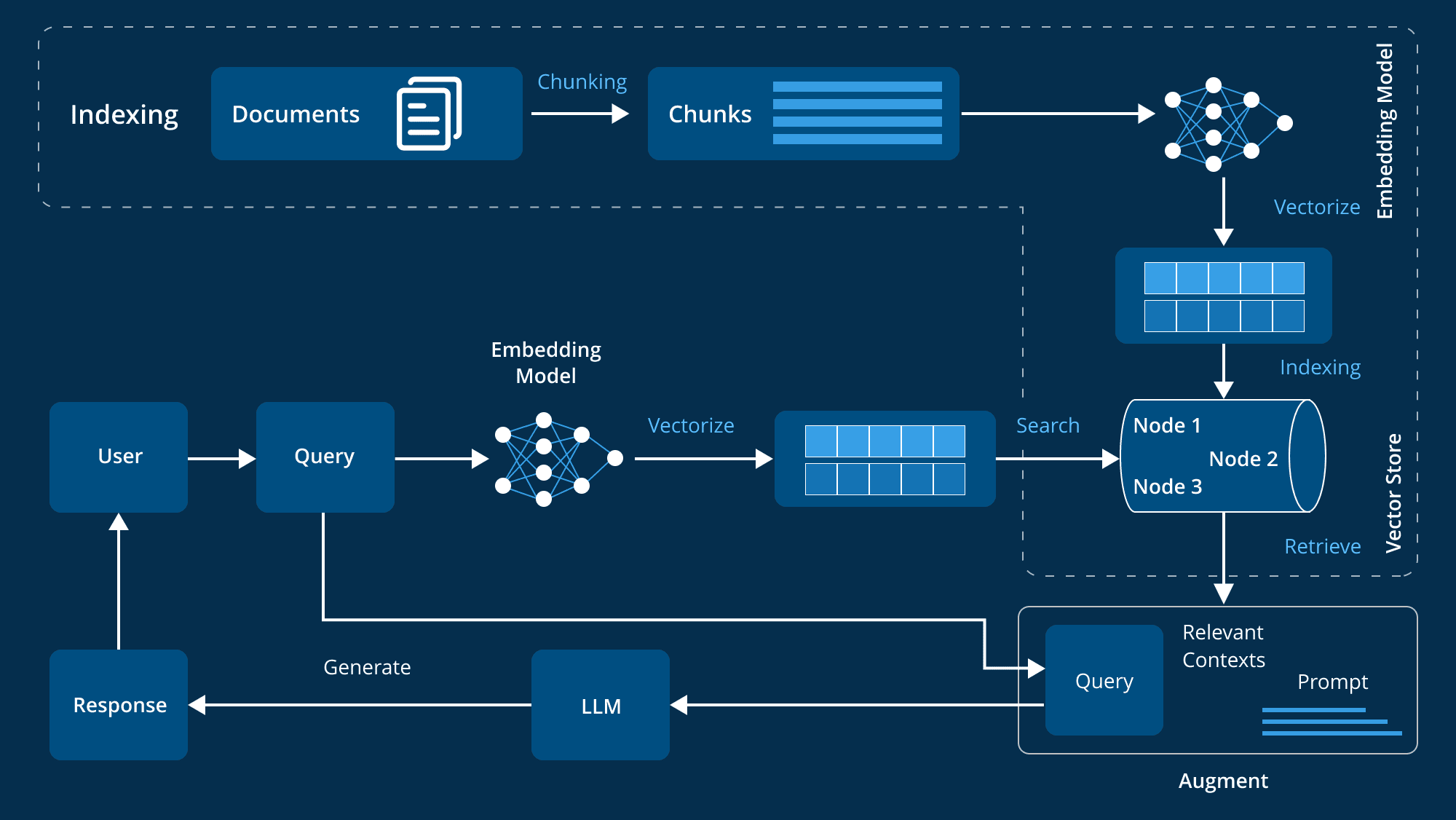
しかし、従来のRAGアプローチは、複雑なクエリへの対応、ニュアンスの異なるコンテキストの理解、複数のデータタイプの取り扱いなど、依然として多くの課題に直面している。これらの限界は、情報検索と生成におけるAIの能力を強化することを目的とした先進的なRAGの創造に拍車をかけている。特に注目すべきは社数 RAGは約60%の製品に搭載されており、実用上の重要性と有効性が実証されている。
この分野における大きなブレークスルーの一つは、マルチモーダルRAGとナレッジグラフの導入である。マルチモーダルRAGは、テキストだけでなく、画像、音声、動画を含む幅広いデータを処理するRAGの能力を拡張する。これにより、AIシステムは、ユーザーと対話する際に、より包括的で、より強力な文脈理解を持つことができる。一方、ナレッジグラフは、構造化された知識表現を通じて、情報検索プロセスと生成されたコンテンツの一貫性と精度を向上させる。マイクロソフトリサーチ は、グラフラグが必要であることを示唆している。 トークン その結果、他の方法に比べて26%から97%に減少し、高い効率と計算コストの削減を示した。
このようなRAG技術の進歩により、いくつかのベンチマークや実世界のアプリケーションで大幅な性能向上が見られた。例えばナレッジマップ RobustQAテストでは86.31%の精度を達成し、他のRAG法を大きく上回った。さらにセケダとアレマン の追跡調査では、オントロジーを組み合わせることで、20%のエラー率が減少することが判明した。企業もこれらの進歩から大きな恩恵を受けている。LinkedIn は、RAGプラスナレッジグラフアプローチにより、カスタマーサポートの解決時間を28.61 TP3T短縮したと報告した。
本稿では、先進的なRAGの進化を掘り下げ、マルチモーダルRAGと知識グラフRAGの複雑性と、AI主導の情報検索・生成の強化におけるそれらの有効性を探る。また、これらの技術革新が様々な産業に応用される可能性や、これらの技術を推進・応用する際に直面する課題についても議論する。
- [検索拡張世代(RAG)とは何か、なぜ大規模言語モデリング(LLM)にとって重要なのか?]
- [RAG建築の種類]
- [基本的なRAGから高度なRAGへ:制限を克服し能力を高める方法]。
- [企業における高度なRAGシステムの構成要素とプロセス]。
- [先進のRAGテクノロジー]
- [アドバンスドRAGの応用とケーススタディ]
- [高度なRAGを使って対話ツールを作るには?]
- [高度なRAGアプリケーションを構築するには?]
- [高度なRAGにおけるナレッジグラフの台頭】。]
- [アドバンスドRAG:マルチモーダル検索による拡張ホライゾンの生成強化】。]
- [LeewayHertzのGenAIコラボレーション・プラットフォーム、ZBrainは先進的なRAGシステムの中でどのように際立っているか】。]
アドバンスドRAG:アーキテクチャ、テクノロジー、アプリケーション、開発の視点 PDFダウンロード

検索補強生成(RAG)とは何か、なぜ大規模言語モデリング(LLM)にとって重要なのか?
大規模言語モデル(LLM)は、バーチャルアシスタントから高度なデータ分析ツールに至るまで、AIアプリケーションの中心的存在となっている。しかし、その能力にもかかわらず、これらのモデルは最新かつ正確な情報を提供することに限界がある。そこで、RAG(Retrieval Augmented Generation)がLLMを強力に補完する。
検索拡張世代(RAG)とは?
Retrieval Augmented Generation (RAG)は、外部の知識ソースを統合することで、大規模言語モデル(LLM)の生成能力を強化する高度な技術です。LLMは、数十億のパラメータを持つ大規模なデータセットで学習され、質問への回答、言語翻訳、テキスト補完などの幅広いタスクを実行することができます。RAGは、モデルを再学習する必要なく、生成されたコンテンツの関連性、正確性、有用性を向上させるために、権威のあるドメイン固有の知識ベースを参照することで、さらに一歩進みます。RAGは、モデルを再学習させることなく、生成されたコンテンツの関連性、正確性、有用性を向上させるために、権威のあるドメイン固有の知識ベースを参照することによって、さらに一歩進みます。この費用対効果が高く効率的なアプローチは、AIシステムの最適化を目指す企業にとって理想的です。
RAG(Retrieval Augmented Generation)は、ラージ・ランゲージ・モデリング(LLM)が核心的な問題を解決するためにどのように役立つのか?
大規模言語モデル(LLM)は、インテリジェントなチャットボットやその他の自然言語処理(NLP)アプリケーションを駆動する上で重要な役割を果たしている。LLMは、広範な訓練を通じて、さまざまな文脈で正確な回答を提供しようとします。しかし、LLM自体にはいくつかの欠点があり、複数の課題に直面しています:
- エラーメッセージLLMの知識が不十分な場合、不正確な回答が生じる可能性があります。
- 古い情報トレーニングデータは静的なものなので、モデルによって生成された回答は古い可能性があります。
- 非権威的情報源生成された回答は、信頼できない情報源から来ることがあり、信頼性に影響を与える。
- 用語の混乱異なるデータソースが同じ用語を使うことは、誤解を招きやすい。
RAGは、LLMに外部の権威あるデータソースを提供し、モデルの応答の精度とリアルタイム性を向上させることで、これらの問題に対処している。RAGがLLMの開発にとって非常に重要である理由は、以下の点にある:
- 正確性と関連性の向上RAGは、学習データが静的なものであるため、モデルの回答がより正確で現在のコンテキストに関連するように、権威あるソースから最新の関連情報を抽出します。
- 静的データの限界を突破するLLMのトレーニングデータは時として古く、最新の研究やニュースを反映していない。
- ユーザーの信頼を高めるRAGは、LLMが出典を引用し、検証可能な情報を提供できるようにすることで、透明性とユーザーの信頼を高めます。
- コスト削減RAGは、新しいデータでLLMを再トレーニングすることで、外部データソースを使用してモデル全体を再トレーニングするよりも費用対効果の高い選択肢を提供し、高度なAI技術をより広く利用できるようにします。
- 開発者のコントロールと柔軟性の強化RAGは、開発者が知識ソースを柔軟に指定し、要求の変化に迅速に対応し、機密情報の適切な取り扱いを保証することで、幅広いアプリケーションをサポートし、AIシステムの有効性を向上させる自由度を提供します。
- カスタマイズされた回答の提供従来のLLMは一般的すぎる回答をしがちであったが、RAGはLLMを組織内のデータベース、製品情報、ユーザーマニュアルと組み合わせることで、より具体的で適切な回答を提供し、カスタマーサポートとインタラクション体験を劇的に改善する。
RAG(Retrieval Augmented Generation)は、LLMが外部の知識ベースと統合することで、より正確でリアルタイムかつ文脈に即した回答を生成することを可能にします。これは、カスタマーサービスからデータ分析まで、AIに依存する組織にとって不可欠なものであり、RAGは効率を改善するだけでなく、AIシステムに対するユーザーの信頼も高めます。
RAG建築の種類
RAG(Retrieval Augmented Generation)は、言語モデルと外部知識検索システムを組み合わせたAI技術の大きな進歩である。このハイブリッド・アプローチは、大規模な外部データ・ソースから詳細かつ関連性の高い情報を取得することで、AIの応答生成能力を向上させる。さまざまなタイプのRAGアーキテクチャを理解することは、特定のニーズに応じてその利点をよりよく活用するのに役立ちます。以下では、3つの主要なRAGアーキテクチャについて詳しく見ていく:
1.ナイーブRAG
ナイーブRAGは、最も基本的な検索機能強化の生成方法である。その原理は単純で、システムはユーザーのクエリに基づいて知識ベースから関連する情報の塊を抽出し、言語モデリングによって答えを生成するためのコンテキストとしてこれらの情報の塊を使用する。
特徴
- 検索メカニズムキーワードのマッチングや基本的な意味的類似性によって、あらかじめ確立されたインデックスから関連する文書のブロックを抽出する。
- 文脈統合検索されたドキュメントは、ユーザーのクエリと融合され、言語モデルに入力され、回答が生成される。この融合は、より関連性の高い回答を生成するために、モデルにより豊かなコンテキストを提供する。
- 処理の流れこのシステムは、検索、接続、生成という決まったプロセスに従う。モデルは抽出された情報を修正せず、回答を生成するために直接使用する。
2.アドバンスドRAG
Advanced RAGは、Naive RAGをベースに、検索精度と文脈関連性を向上させるためのより高度な技術を採用している。文脈情報をより適切に処理・利用するための高度なメカニズムを組み合わせることで、Naive RAGの制限をいくつか克服している。
特徴
- 検索機能の強化クエリ拡張(最初のクエリに関連用語を追加)や反復検索(複数段階で文書を最適化)などの高度な検索戦略を使用して、検索された情報の品質と関連性を向上させます。
- コンテキストの最適化アテンション・メカニズムなどの技術により、文脈の最も関連性の高い部分に選択的に焦点を当てることで、言語モデルはより正確で文脈に即したより正確な応答を生成することができます。
- 最適化戦略関連性スコアリングや文脈強調などの最適化ストラテジーを使用することで、回答生成に最も関連性の高い、質の高い情報を確実に取り込むことができます。
3.モジュラーRAG
モジュラーRAGは、最も柔軟でカスタマイズ可能なRAGアーキテクチャです。検索と生成のプロセスを個別のモジュールに分割し、特定のアプリケーションのニーズに応じて最適化と置き換えを可能にします。
特徴
- モジュール設計RAGプロセスを、クエリの展開、検索、並べ替え、生成といった異なるモジュールに分解する。各モジュールは独立して最適化することができ、必要に応じて置き換えることができる。
- 柔軟なカスタマイズ高度なカスタマイズが可能で、開発者は各ステップでさまざまなコンフィギュレーションやテクニックを試し、最適なソリューションを見つけることができます。この方法論は、様々なアプリケーションシナリオに対してカスタマイズされたソリューションを提供する。
- 統合と適応このアーキテクチャは、メモリーモジュール(過去のインタラクションを記録)や検索モジュール(検索エンジンやナレッジグラフからデータを抽出)などの追加機能を統合することが可能です。この適応性により、RAGシステムは特定のニーズに柔軟に対応することができます。
これらの種類と特徴を理解することは、最も適切なRAGアーキテクチャを選択し、実装する上で極めて重要である。
RAGの基礎から応用へ:限界の突破と能力の向上
検索補強世代(RAG)は、次のように使用される。 自然言語処理(NLP) RAGは、情報検索とテキスト生成を組み合わせて、より正確で文脈に沿った出力を生成するための非常に効果的な手法となっている。しかし、技術が進化するにつれ、初期の「基本的な」RAGシステムにはいくつかの欠点が明らかになり、それがより高度なバージョンの出現につながった。基本的なRAGから高度なRAGへの進化は、これらの欠点を徐々に克服し、RAGシステムの全体的な能力を大幅に向上させていることを意味する。
ベーシックRAGの限界

基礎となるRAGフレームワークは、NLPの検索と生成を組み合わせた最初の試みである。このアプローチは革新的ではあるが、まだいくつかの限界に直面している:
- シンプルな検索方法基本的なRAGシステムのほとんどは、単純なキーワードのマッチングに頼っている。このアプローチでは、クエリのニュアンスや文脈を理解することが難しく、その結果、関連性の不十分な情報や部分的な情報を検索してしまう。
- 文脈の理解が難しいこれらのシステムでは、ユーザーのクエリのコンテキストを正しく理解することは難しい。例えば、基礎となるRAGシステムは、クエリのキーワードを含む文書を検索するかもしれないが、ユーザーの真の意図やコンテキストを捉えることができないため、ユーザーのニーズを正確に満たすことができない。
- 複雑なクエリを処理する能力が限られている基本的なRAGシステムは、複雑なクエリや複数ステップのクエリに直面すると、パフォーマンスが低下する。コンテキストの理解と正確な検索において限界があるため、複雑な問題を効果的に処理することが難しい。
- 静的知識ベース基本的なRAGシステムは静的な知識ベースに依存しており、動的な更新のメカニズムが欠けている。
- 反復最適化の欠如RAGの根底には、フィードバックに基づいて最適化するメカニズムが欠如しており、反復学習によってパフォーマンスを向上させることができない。
上級RAGへの移行

技術の進化に伴い、基本的なRAGシステムの欠点に対処するため、より洗練されたソリューションが利用できるようになった。高度なRAGシステムは、いくつかの方法でこれらの課題を克服している:
- より複雑な検索アルゴリズム高度なRAGシステムは、セマンティック検索や文脈理解のような洗練された技術を使用し、キーワードマッチングを超えて、クエリの背後にある本当の意味を理解し、検索結果の関連性を向上させることができます。
- コンテキスト統合の強化これらのシステムは、検索結果を統合するためにコンテキストと関連性の重みを組み込み、情報が正確であることを保証するだけでなく、コンテキストにおいて適切であり、ユーザーのクエリと意図によりよく応えることを保証します。
- 反復最適化とフィードバック・メカニズム::
アドバンスドRAGシステムは、ユーザーのフィードバックを取り入れることで、時間の経過とともに精度と関連性を継続的に改善する反復最適化プロセスを採用している。 - ダイナミックな知識の更新::
先進的なRAGシステムは、ナレッジベースを動的に更新することができ、常に最新の情報を導入し、システムが常に最新のトレンドや動向を反映することを保証する。 - 複雑な文脈の理解::
より高度なNLP技術を活用することで、高度なRAGシステムはクエリとコンテキストをより深く理解し、意味的なニュアンス、コンテキストの手がかり、ユーザーの意図を分析して、より首尾一貫した適切なレスポンスを生成することができる。
コンポーネントの高度なRAGシステムの改善
ベーシックRAGからアドバンスRAGへの進化は、システムが4つの重要な要素、すなわち保存、検索、強化、生成のそれぞれにおいて大幅な改善を達成することを意味する。
- ざいこ高度なRAGシステムは、単純なキーワードではなく、データの意味によって整理されたセマンティック・インデックスによってデータを保存することで、情報検索をより効率的にします。
- 取り出す意味検索と文脈検索の強化により、システムは関連データを見つけるだけでなく、ユーザーの意図と文脈を理解することができます。
- 補強アドバンスドRAGシステムのエンハンスメント・モジュールは、ユーザーとの対話に基づいて継続的に最適化される動的な学習・適応メカニズムにより、よりパーソナライズされた正確な応答を生成します。
- 生成ジェネレーション・モジュールは、高度な文脈理解と反復的最適化により、より首尾一貫した文脈に沿った回答を生成することができます。
基本的なRAGから高度なRAGへの進化は大きな飛躍である。洗練された検索技術、強化された文脈統合、動的学習メカニズムを用いることで、高度なRAGシステムは、情報検索と生成に対して、より正確で文脈を考慮したアプローチを提供する。この進歩により、AIとの対話の質が向上し、より洗練された効率的なコミュニケーションの基礎が築かれる。
企業レベルの高度なRAGシステムの構成要素とワークフロー

企業アプリケーションの分野では、関連情報をインテリジェントに検索・生成できるシステムの必要性が高まっている。検索拡張生成(RAG)システムは、情報検索の精度と大規模言語モデル(LLM)の生成能力を組み合わせた強力なソリューションとして登場した。しかし、組織の複雑なニーズに適合する高度なRAGシステムを構築するには、そのアーキテクチャを慎重に設計する必要があります。
コア・アーキテクチャ・コンポーネント
高度なRAG(Retrieval Augmentation Generation)システムには、システムの効率性と有効性を確保するために連携する複数のコアコンポーネントが必要である。これらのコンポーネントは、データ管理、ユーザー入力処理、情報検索と生成、および継続的なシステム性能強化をカバーしています。以下は、これらの主要コンポーネントの詳細な内訳である:
- データの準備と管理
高度なRAGシステムの基盤は、データの準備と管理であり、これにはいくつかの重要な要素が含まれる:
- データチャンキングとベクトル化: データはより管理しやすい塊に分解され、ベクトル表現に変換される。これは検索の効率と精度を向上させる上で非常に重要である。
- メタデータと要約の生成: メタデータと要約を作成することで、素早く参照でき、検索時間を短縮できる。
- データクレンジング: データがきれいで、整理され、ノイズがないことを確認することは、検索された情報が正確であることを保証する鍵である。
- 複雑なデータ形式を扱う: 複雑なデータ形式を扱えるシステムの能力により、組織内のさまざまなデータ形式が効果的に活用される。
- ユーザー構成管理: 企業環境ではパーソナライゼーションが重要であり、ユーザー設定を管理することで、個々のニーズに合わせた応答が可能になり、ユーザーエクスペリエンスが最適化される。
- ユーザー入力処理
ユーザー入力処理モジュールは、システムがクエリーを効率的に処理できるようにするために重要な役割を果たす:
- ユーザー認証: 企業システムのセキュリティは非常に重要であり、認証メカニズムにより、許可されたユーザーだけがRAGシステムを使用できるようにする。
- クエリオプティマイザー: ユーザーのクエリの構造は検索に適していない可能性があり、オプティマイザはクエリを最適化し、検索の関連性と精度を向上させる。
- 入力保護メカニズム: 保護メカニズムは、余計な入力や悪意のある入力からシステムを保護し、検索プロセスの信頼性を保証する。
- チャット履歴の活用: 過去のダイアログを参照することで、システムは現在のクエリをよりよく理解し、回答することができる。
- 情報検索システム
情報検索システムは、RAGアーキテクチャの中核であり、前処理されたデータのインデックスから最も関連性の高い情報を検索する役割を担っている:
- データの索引付け: 効率的なインデックス作成技術により、迅速かつ正確な情報検索を実現し、高度なインデックス作成手法により、大量の企業データの処理をサポートします。
- ハイパーパラメーターの調整: 検索モデルのパラメータは、その性能を最適化し、最も関連性の高い結果が検索されるように調整される。
- 結果の並び替え: 検索後、システムは最も関連性の高い情報が最初に表示されるように結果を並べ替え、応答品質を向上させる。
- 最適化を埋め込む: 埋め込みベクトルを調整することで、システムはクエリと関連データをより適切にマッチングさせることができ、検索の精度が向上する。
- HyDE技術に関する仮定の問題点: HyDE(Hypothetical Document Embedding)技術を使って仮想的な質問と答えのペアを生成することで、問い合わせと文書が非対称な場合の情報検索にうまく対応できる。
- 情報の生成と処理
関連情報が検索されると、システムは首尾一貫した、文脈に関連した応答を生成する必要がある:
- 応答生成: 高度な大規模言語モデル(LLM)を使用して、モジュールは検索された情報を包括的で正確な応答に合成する。
- 出力保護と監査: 生成された回答が仕様に合致していることを確認するため、システムはさまざまなルールで審査を行う。
- データのキャッシュ: 頻繁にアクセスされるデータや回答はキャッシュされるため、検索時間が短縮され、システムの効率が向上する。
- パーソナライゼーション世代: システムは、生成されたコンテンツをユーザーのニーズと設定に従ってカスタマイズし、応答の関連性と正確性を確保する。
- フィードバックとシステムの最適化
高度なRAGシステムは、自己学習と改善が可能であるべきであり、継続的な最適化にはフィードバックの仕組みが不可欠である:
- ユーザーからのフィードバック ユーザーからのフィードバックを収集・分析することで、システムは改善点を特定し、ユーザーのニーズをより満たすように進化することができる。
- データの最適化: ユーザーからのフィードバックや新たな知見に基づき、システム内のデータは継続的に最適化され、情報の質と関連性が確保される。
- 品質評価を行う: システムは、生成されたコンテンツの品質を定期的に評価し、継続的な最適化を図る。
- システムの監視: システムのパフォーマンスを継続的に監視し、効率的に稼動していることを確認し、需要の変化やデータパターンの変化に対応できるようにする。
企業システムとの統合
先進的なRAGシステムが組織環境で最良の働きをするためには、既存システムとのシームレスな統合が不可欠である:
- CRMとERPシステムの統合 高度なRAGシステムをCRM(顧客関係管理)やERP(統合基幹業務システム)と連携させることで、主要なビジネスデータへの効率的なアクセスと活用が可能になり、正確で文脈に即した回答を生成する能力が向上する。
- APIとマイクロサービス・アーキテクチャ: 柔軟なAPIとマイクロサービス・アーキテクチャの使用により、RAGシステムは既存の企業ソフトウェアに簡単に統合でき、モジュール式のアップグレードや拡張が可能になる。
セキュリティとコンプライアンス
企業のデータは機密性が高いため、セキュリティとコンプライアンスは特に重要である:
- データ・セキュリティ・プロトコル: 機密情報を保護し、GDPRなどのデータ保護規制を確実に遵守するために、強力なデータ暗号化と安全なデータ処理手段が使用されています。
- アクセス制御と認証: 安全なユーザー認証と役割ベースのアクセス制御メカニズムを導入し、権限を与えられた担当者のみがシステムにアクセスまたは変更できるようにする。
スケーラビリティとパフォーマンスの最適化
エンタープライズクラスのRAGシステムは、スケーラブルで、高負荷下でも優れたパフォーマンスを維持できる必要がある:
- クラウド・ネイティブ・アーキテクチャ: クラウドネイティブアーキテクチャの採用により、リソースをオンデマンドで柔軟に拡張でき、システムの高い可用性とパフォーマンスの最適化が実現します。
- ロードバランシングとリソース管理: 効率的なロードバランシングとリソース管理ストラテジーは、最適なパフォーマンスを維持しながら、システムが大量のユーザーリクエストとデータを処理するのに役立ちます。
分析と報告
先進的なRAGシステムは、強固な分析・報告機能も備えていなければならない:
- パフォーマンス・モニタリング: 高度な分析ツールを統合することで、システム・パフォーマンス、ユーザー・インタラクション、システムの健全性をリアルタイムで監視することは、システムの効率性を維持するために不可欠です。
- ビジネスインテリジェンスの統合: ビジネスインテリジェンスツールとの統合は、意思決定やビジネス戦略の推進に役立つ貴重な洞察を提供します。
企業レベルの先進的なRAGシステムは、最先端のAI技術、堅牢なデータ処理メカニズム、安全で拡張可能なインフラ、シームレスな統合機能の組み合わせを表している。これらの要素を組み合わせることで、組織は効率的に情報を取得・生成できるRAGシステムを構築することができ、同時にエンタープライズ・テクノロジー・システムの中核部分となることができる。これらのシステムは、大きなビジネス価値をもたらすだけでなく、意思決定プロセスを改善し、全体的な業務効率を向上させる。
先進のRAGテクノロジー
高度な検索拡張世代(RAG)は、処理のすべての段階で効率と精度を向上させるように設計された、さまざまな技術ツールを包含しています。これらの高度なRAGシステムは、インデックス作成、クエリ変換から検索、生成に至るまで、プロセスのさまざまな段階で高度な技術を適用することにより、データをより適切に管理し、より正確で文脈に即した応答を提供することができます。以下は、RAGプロセスの各段階を最適化するために使用される高度な技術の一部です:
1.インデックス
インデクシングは、大規模言語モデル(LLM)システムの精度と効率を向上させる重要なプロセスです。インデックス作成は、単にデータを保存するだけではありません。重要な文脈を維持しながら、情報がアクセスしやすく、理解しやすいように、データを体系的に整理し、最適化します。効果的なインデックス作成は、データを正確かつ効率的に検索し、LLMが適切で正確な応答を提供できるようにします。インデックス作成プロセスで使用される技術には、以下のようなものがある:
テクニック1:ブロック最適化によるテキストブロックの最適化
ブロック最適化の目的は、テキストブロックのサイズと構造を調整し、文脈を維持しながら大きすぎたり小さすぎたりしないようにすることで、検索を向上させることである。
テクニック2:高度な埋め込みモデルを使ったテキストからベクトルへの変換
テキストのブロックを作成したら、次はそのブロックをベクトル表現に変換する。このプロセスは、テキストを、その意味的な意味を捉える数値ベクトルに変換する。BGE-largeやE5埋め込みファミリーのようなモデルは、テキストのニュアンスを表現するのに効果的である。これらのベクトル表現は、その後の検索や意味的マッチングにおいて極めて重要である。
手法3:微調整の埋め込みによる意味的マッチングの強化
埋め込み微調整の目的は、埋め込みモデルによってインデックス付けされたデータの意味理解を向上させ、検索された情報とユーザークエリとの一致精度を向上させることである。
手法4:複数表現による検索効率の向上
多重表現技術は、文書を要約のような軽量な検索単位に変換し、検索プロセスを高速化し、大規模な文書を扱う際の精度を向上させる。
テクニック5:階層インデックスを使ってデータを整理する
階層的索引は、RAPTORのようなモデルを通じて、データを詳細から一般まで複数のレベルに構造化することによって検索を強化し、広範かつ正確な文脈情報を提供する。
手法6:メタデータ添付によるデータ検索の強化
メタデータ付加技術は、各データブロックに付加情報を追加して分析・分類能力を向上させ、データ検索をより体系的で文脈に沿ったものにする。
2.クエリー変換
クエリー変換は、ユーザー入力を最適化し、情報検索の質を向上させることを目的としている。LLMを利用することで、変換プロセスは複雑で曖昧なクエリをより明確かつ具体的にすることができ、全体的な検索効率と精度を向上させることができる。
手法1:HyDE(仮説的文書埋め込み)を使ってクエリの明瞭性を高める
HyDEは、質問と参照コンテンツ間の意味的類似性を高める仮説データを生成することにより、情報検索の関連性と精度を向上させる。
テクニック2:マルチステップ・クエリーによる複雑なクエリーの簡素化
マルチステップ・クエリーは、複雑な質問をより単純なサブクエスチョンに分解し、それぞれのサブクエスチョンに対する回答を個別に取得し、その結果を集約して、より正確で包括的な回答を提供する。
テクニック3:バックトラックの手がかりでコンテクストを強化する
バックトラック・ヒンティング技法は、複雑な元のクエリから、より広範な一般的クエリを生成し、コンテキストが特定のクエリの基礎となり、元のクエリと広範なクエリの結果を組み合わせることで最終的なレスポンスを向上させる。
手法4:クエリ書き換えによる検索の改善
LangChainとLlamaIndexの両方がこの手法を使っており、特にLlamaIndexは検索を劇的に改善する強力な実装を提供している。
3.クエリ・ルーティング
クエリ・ルーティングの役割は、クエリの特性に基づいて最も適切なデータ・ソースにクエリを送信することによって検索プロセスを最適化し、各クエリが最も適切なシステム・コンポーネントによって処理されるようにすることである。
手法1:論理ルーティング
論理ルーティングは、クエリの構造を分析し、最も適切なデータソースまたはインデックスを選択することで、検索を最適化します。このアプローチにより、正確な回答を提供するのに最適なデータソースによってクエリが処理されるようになります。
技術2:セマンティック・ルーティング
セマンティックルーティングは、クエリの意味を分析することにより、クエリを正しいデータソースやインデックスに導く。特に複雑で微妙な問題に対して、クエリの文脈と意味を理解することで検索の精度を向上させる。
4.事前検索とデータインデックス作成技術
検索前の最適化は、データインデックスや知識ベース内の情報の品質と検索性を向上させます。具体的な最適化の方法は、データの性質、ソース、サイズによって異なります。例えば、情報密度を高めることで、より少ないトークンでより正確な回答を生成し、ユーザーエクスペリエンスを向上させ、コストを削減することができます。しかし、あるシステムで有効な最適化手法が、他のシステムで有効とは限りません。大規模言語モデル(LLM)は、このような最適化をテストおよびチューニングするためのツールを提供し、異なるドメインやアプリケーションで検索を改善するためにカスタマイズされたアプローチを可能にします。
手法1:LLMを使って情報密度を高める
RAGシステムを最適化する基本的なステップは、インデックスを作成する前にデータの質を向上させることである。データのクレンジング、タグ付け、要約にLLMを活用することで、情報密度を高め、より正確で効率的なデータ処理結果を導くことができる。
手法2:階層的インデックス検索
階層的インデックス検索は、フィルタの第一層としてドキュメントの要約を作成することで、検索プロセスを簡素化する。この多層的なアプローチにより、最も関連性の高いデータのみが検索段階で考慮されるため、検索効率と精度が向上する。
テクニック3:仮説Q&Aペアで検索の対称性を高める
クエリと文書間の非対称性に対処するため、この技術ではLLMを用いて文書から仮想的なQ&Aペアを生成する。これらのQ&Aペアを検索に埋め込むことで、システムはユーザのクエリによりよくマッチし、意味的類似性を向上させ、検索エラーを減らすことができる。
手法4:LLMによる重複排除
重複情報は、RAGシステムにとって有益にも有害にもなり得る。LLMを使用してデータブロックの重複を除去することで、データの索引付けが最適化され、ノイズが減少し、正確な回答が得られる可能性が高まります。
テクニック5:チャンキング戦略のテストと最適化
効果的なチャンキング戦略は検索に欠かせない。チャンクのサイズや重複率を変えてA/Bテストを行うことで、特定のユースケースに最適なバランスを見つけることができます。これにより、関連する情報を拡散させたり薄めたりすることなく、十分なコンテキストを保持することができます。
テクニック6:スライディングウィンドウインデックスを使う
スライディングウィンドウインデクシングは、インデクシング処理中にデータのブロックが重なり、セグメント間で重要な文脈情報が失われないようにする。このアプローチにより、データの連続性が維持され、検索される情報の関連性と精度が向上する。
テクニック7:データの粒度を上げる
データの粒度を高めるには、主にデータクレンジング技術を適用して、無関係な情報を取り除き、最も正確で最新のコンテンツだけをインデックスに残す。これにより検索の質が向上し、関連する情報のみが考慮されるようになる。
テクニック8:メタデータを追加する
日付、目的、セクションなどのメタデータを追加することで、検索の精度が向上し、システムが最も関連性の高いデータに効果的に焦点を当て、検索全体を改善することができます。
テクニック9:インデックス構造の最適化
インデクシング構造を最適化するには、チャンクのサイズを変更し、センテンスウィンドウ検索などの複数のインデクシング戦略を採用することで、データの保存と検索の方法を強化する。文脈ウィンドウを維持しながら個々のセンテンスを埋め込むことで、このアプローチは推論中によりリッチで文脈に正確な検索を可能にする。
5.検索技術
検索段階では、システムはユーザーのクエリに答えるために必要な情報を収集する。高度な検索技術により、検索されたコンテンツが包括的かつ文脈的に完全なものであることが保証され、後続の処理ステップのための強固な基盤が築かれる。
手法1:LLMによる検索クエリの最適化
LLMは、単純な検索であれ、複雑なダイアログ・クエリであれ、検索システムの要求によりマッチするようにユーザーの検索クエリを最適化する。この最適化により、検索プロセスがより的を絞った効率的なものになる。
テクニック2:HyDEでクエリとドキュメントの非対称性を修正する
仮説的な回答文書を生成することで、HyDE技術は検索における意味的類似性を向上させ、短いクエリと長い文書との間の非対称性を解決する。
技術3:クエリ・ルーティングまたはRAG決定モデルの実装
複数のデータ・ソースを使用するシステムでは、クエリ・ルーティングは、検索を適切なデータベースに向けることで検索効率を最適化する。RAG決定モデルは、大規模言語モデルが独立して応答できる場合に、リソースを節約するために検索が必要なタイミングを決定することで、このプロセスをさらに最適化する。
テクニック4:再帰的サーチャーによる深い探索
再帰的検索は、前の結果に基づいてさらにクエリを実行し、関連するデータを深く掘り下げて詳細な情報や包括的な情報を得るのに適している。
手法5:ルート検索によるデータソース選択の最適化
ルーティング・リトリーバーは、LLMを使用して、クエリのコンテキストに基づいて検索プロセスの有効性を向上させるために、最適なデータソースまたはクエリツールを動的に選択する。
手法6:オートサーチャーを使ったクエリの自動生成
オートリトリーバは、LLMを使用してメタデータ・フィルタやクエリ・ステートメントを自動的に生成するため、データベースのクエリ・プロセスを簡素化し、情報検索を最適化する。
手法7:フュージョンサーチャーを使った結果の組み合わせ
フュージョン・レトリーバーは、複数のクエリーとインデックスからの結果を組み合わせ、情報の重複のない包括的なビューを提供し、包括的な検索を保証します。
テクニック8:自動マージサーチャーによるデータコンテキストの集約
Auto Merge Retrieverは、複数のデータセグメントを1つの統一されたコンテキストに結合し、より小さなコンテキストを統合することで情報の関連性と完全性を向上させます。
手法9:埋め込みモデルの微調整
埋め込みモデルをよりドメインに特化したものに微調整することで、特殊な用語を扱う能力が向上する。このアプローチは、ドメイン固有のコンテンツをより密接に整合させることで、検索された情報の関連性と正確性を高める。
テクニック10:ダイナミック・エンベッディングの実装
動的埋め込みは、単語ベクトルを文脈に適応させることで、静的な表現を超え、言語のよりニュアンスに富んだ理解を提供します。OpenAIのembeddings-ada-02モデルのようなこのアプローチは、文脈の意味をより正確に捉え、より正確な検索結果を提供します。
手法11:ハイブリッド検索を活用する
ハイブリッド検索は、ベクトル検索と従来のキーワードマッチングを組み合わせ、意味的類似性と正確な用語認識の両方を可能にする。このアプローチは、正確な用語認識が必要とされるシナリオで特に有効であり、包括的で正確な検索を保証する。
6.検索後のテクニック
関連するコンテンツを取得したら、検索後の段階では、このコンテンツをいかに効果的にまとめるかに焦点を当てる。このステップでは、ラージ・ランゲージ・モデル(LLM)に正確で簡潔な文脈情報を提供し、システムが首尾一貫した正確な応答を生成するために必要なすべての詳細を確実にする。この統合の質は、最終的な出力の妥当性と明瞭性を直接決定する。
手法1:並び替えによる検索結果の最適化
検索後、並べ替えモデルは検索結果を並べ替え、最も関連性の高い文書をクエリに近い場所に配置することで、LLMに提供される情報の質を向上させ、結果として最終的な応答を生成する。並べ替えは、LLMに提供する必要がある文書の数を減らすだけでなく、言語処理の精度を向上させるフィルターとしても機能する。
テクニック2:文脈的ヒントによる圧縮で検索結果を最適化する
LLMは、最終的なプロンプトを生成する前に、検索された情報をフィルタリングし、圧縮することができる。圧縮は、冗長な背景情報を減らし、余計なノイズを取り除くことで、LLMがより重要な情報に集中できるようにする。この最適化により、応答の質が向上し、重要な詳細に集中する。LLMLinguaのようなフレームワークは、余計なトークンを削除することで、このプロセスをさらに改善し、プロンプトをより簡潔で効果的なものにします。
手法3:RAGの修正による取得文書のスコアリングとフィルタリング
コンテンツがLLMに入力される前に、文書を選択し、無関係な文書や精度の低い文書を除去するためのフィルタリングを行う必要がある。この手法により、高品質で関連性の高い情報のみが使用されるため、回答の正確性と信頼性が向上する。Corrective RAGは、T5-Largeのようなモデルを利用して、検索されたドキュメントの関連性を評価し、あらかじめ設定されたしきい値を下回るものをフィルタリングすることで、最終的なレスポンスの生成に重要な情報のみが使用されるようにします。
7.ジェネレーティブ・テクノロジー
生成段階では、検索された情報を評価し、最も重要な内容を特定するために並び替える。この段階での高度な技術には、回答の関連性と信頼性を高める重要な詳細を選択することが含まれる。このプロセスは、生成されたコンテンツがクエリに答えるだけでなく、検索されたデータによって意味のある形で十分にサポートされることを保証します。
テクニック1:思考連鎖のヒントでノイズを減らす
思考の連鎖プロンプトは、LLMがノイズや無関係な背景情報に対処するのを助け、データに干渉があっても正確な応答を生成する可能性を高める。
テクニック2:自己RAGによるシステムの自己省察
Self-RAGでは、生成中にリフレクティブ・トークンを使用するようにモデルを訓練することで、自身の出力をリアルタイムで評価・改善し、事実性と品質に基づいて最適な応答を選択できるようにする。
テクニック3:微調整で余計な背景を無視する
RAGシステムは、LLMが余計な背景を無視する能力を強化し、関連する情報のみが最終的な回答に影響を与えるように、特別に微調整された。
手法4:自然言語推論による、無関係な背景に対するLLMの頑健性の向上
自然言語推論(NLI)モデルを統合することで、検索されたコンテキストと生成された回答を比較することで、無関係なコンテキスト情報をフィルタリングし、関連する情報のみが最終的な出力に影響を与えるようにすることができます。
テクニック5:FLAREによるデータ検索の制御
FLARE(Flexible Language Modelling Adaptation for Retrieval Enhancement)は、LLMが必要なときだけデータを検索するようにする、キューエンジニアリングに基づくアプローチである。クエリを継続的に適応させ、関連文書を検索するきっかけとなる確率の低いキーワードをチェックし、応答の精度を高める。
テクニック6:ITER-RETGENによるレスポンスの質の向上
ITER-RETGEN (Iterative Retrieval-Generation) は、生成プロセスを繰り返し実行することにより、応答の品質を向上させる。各反復は前の結果をコンテキストとして使用し、より関連性の高い情報を検索することで、最終的なレスポンスの品質と関連性を継続的に向上させる。
テクニック7:ToC(明確化の木)を使った課題の明確化
ToCは、最初の質問のあいまいさを明確にするために、特定の質問を再帰的に生成する。このアプローチは、元の質問を継続的に評価し、改良することで、質問と回答のプロセスを洗練させ、より詳細で正確な最終回答をもたらします。
8.評価
高度なRAG(Retrieval Augmented Generation)技術では、検索・合成された情報がユーザーのクエリに対して正確かつ適切であることを保証するために、評価プロセスが重要である。評価プロセスは、品質スコアと要求される能力という2つの重要な要素で構成される。
品質スコアリングは、コンテンツの正確性と関連性を測定することに重点を置いている:
- 背景 関連性 クエリの特定のコンテキストにおいて、検索または生成された情報の適用可能性を評価する。応答が正確で、ユーザーのニーズに合ったものであることを確認する。
- フィデリティに答える。 生成された回答が、検索されたデータを正確に反映し、エラーや誤解を招く情報を含んでいないことを確認する。これは、システムの出力の信頼性を維持するために不可欠である。
- 回答の妥当性 生成された回答がユーザーのクエリに直接かつ効果的に答えているかどうかを評価し、回答が有用であり、質問の要点と一致していることを確認する。
要求される能力とは、質の高い結果を出すためにシステムが備えていなければならない能力である:
- ノイズに強い。 外来またはノイズの多いデータをフィルタリングし、これらの外乱が最終的なレスポンスの品質に影響を与えないようにするシステムの能力を測定する。
- 否定的な拒絶。 生成された出力に混入する誤った情報や無関係な情報を認識し、排除するシステムの有効性をテストする。
- 情報の統合。 複数の関連情報を統合し、一貫性のある包括的な回答としてユーザーに完全な回答を提供するシステムの能力を評価する。
- 反実仮想の頑健性。 仮定のシナリオや反事実のシナリオを扱った場合のシステムのパフォーマンスをチェックし、推測的な質問を扱った場合でも、回答が正確で信頼できるものであることを確認する。
これらの評価要素を組み合わせることで、アドバンスドRAGシステムは、正確かつ適切で、堅牢で信頼性が高く、ユーザーの特定のニーズに合わせてカスタマイズされた回答を提供することができます。
追加技術
チャットエンジン:RAGシステムにおける対話の強化

高度なRAG(Retrieval Augmented Generation)システムにチャットエンジンを統合することで、従来のチャットボット技術と同様に、フォローアップの質問を処理し、対話のコンテキストを維持するシステムの能力が強化される。異なる実装は、異なるレベルの複雑さを提供します:
- コンテキストチャットエンジン: この基本的なアプローチは、以前のチャットを含むユーザーのクエリに関連するコンテキストを取得することにより、大規模言語モデル(LLM)の応答をガイドします。これにより、ダイアログが首尾一貫し、文脈的に適切であることが保証される。
- 集中力プラス文脈モード: これは、各インタラクションからのチャットログと最新のメッセージを最適化されたクエリーに凝縮する、より高度なアプローチである。この洗練されたクエリは、関連するコンテキストを取り込み、それを元のユーザーメッセージと組み合わせてLLMに提供し、より正確でコンテキスト化されたレスポンスを生成します。
これらの実装は、RAGシステムにおける対話の一貫性と関連性を向上させるのに役立ち、ニーズに応じて異なるレベルの複雑さを提供する。
参考文献の引用:出典が正確であることを確認する
生成された回答に複数の情報源が寄与している場合は特に、参考文献の正確性を確保することが重要です。これにはいくつかの方法があります:
- 直接出所表示: 言語モデル(LLM)プロンプトでタスクを設定するには、生成される応答でソースを直接ラベル付けする必要があります。このアプローチでは、元のソースを明確にラベル付けすることができます。
- ファジィマッチング技術: LlamaIndexで使用されているようなファジィ・マッチング技法は、生成されたコンテンツの一部をソース・インデックス内のテキスト・ブロックと整合させるために採用されている。ファジィ・マッチングは、コンテンツの精度を向上させ、ソース情報を確実に反映させる。
これらの戦略を適用することで、参考文献の引用の正確性と信頼性を大幅に向上させることができ、作成された回答が信頼できるものであり、十分な裏付けがあることを保証することができる。
検索拡張世代(RAG)のエージェント

エージェントは、Large Language Model (LLM)に追加のツールと機能を提供し、その範囲を拡張することで、Retrieval Augmented Generation (RAG)システムのパフォーマンスを向上させる重要な役割を果たす。もともとLLM APIを通して導入されたこれらのエージェントは、LLMがその機能を強化するために外部のコード関数、API、さらには他のLLMを利用することを可能にします。
エージェントの重要な用途のひとつに、複数文書の検索がある。例えば、最近のOpenAIアシスタントは、このコンセプトの進歩を示している。これらのアシスタントは、チャットログ、ナレッジストア、ドキュメントのアップロードインターフェース、自然言語を実行可能なコマンドに変換する関数呼び出しAPIなどの機能を統合することで、従来のLLMを補強している。
エージェントの使用は複数のドキュメントの管理にも及び、各ドキュメントはサマリーやクイズなどの専用エージェントによって処理される。中央の高レベルエージェントは、これらのドキュメント固有のエージェントを監督し、クエリをルーティングし、応答を統合します。このセットアップにより、複数のドキュメントにわたる複雑な比較や分析がサポートされ、高度なRAG技術が実証されます。
シンセサイザーへの反応:最終回答を作る
RAGプロセスの最終段階は、検索されたコンテキストと最初のユーザークエリを合成して応答とすることである。コンテキストとクエリを直接組み合わせ、LLMを通して処理することに加え、より洗練されたアプローチには次のようなものがある:
- 反復最適化: 検索されたコンテキストをより小さな部分に分割することで、LLMとの複数回のインタラクションを通じてレスポンスを最適化する。
- 文脈上の要約: LLMのプロンプト内に収まるように、大量のコンテクストを圧縮することで、回答は焦点を絞った適切なものになります。
- マルチ・アンサー・ジェネレーション: 文脈の異なるセグメントから複数の回答を作成し、これらの回答を統合して統一した回答にする。
これらの技術は、RAGシステムの応答の質と精度を高め、応答合成における高度な手法の可能性を示している。
これらの高度なRAGテクノロジーを採用することで、システムのパフォーマンスと信頼性を大幅に向上させることができる。データの前処理からレスポンスの生成まで、あらゆる段階でプロセスを最適化することで、企業はより正確で効率的、かつ強力なAIアプリケーションを作成することができる。
高度なRAGアプリケーションとケース
高度なRAG(Retrieval Augmented Generation)システムは、強力なデータ処理・生成機能により、データ分析、意思決定、ユーザーとのインタラクションを強化するために、幅広い分野で使用されています。市場調査から顧客サポート、コンテンツ作成に至るまで、高度なRAGシステムは多くの分野で大きな利点を発揮している。以下に、様々な分野におけるこれらのシステムの具体的な応用例を紹介します:
1. 市場調査と競合分析
- データ統合RAGシステムは、ソーシャルメディア、ニュース記事、業界レポートなど、さまざまなソースからのデータを統合して分析することができる。
- トレンドの特定大量のデータを処理することで、RAGシステムは市場の新たなトレンドや消費者行動の変化を特定することができる。
- 競合他社の洞察このシステムは、企業の自己評価とベンチマーキングを支援するために、詳細な競合戦略と業績分析を提供します。
- 実用的洞察企業はこれらのレポートを戦略的プランニングや意思決定に利用することができます。
2. カスタマーサポートと交流
- コンテキストを意識した対応RAGシステムは知識ベースから関連情報を検索し、正確で文脈に沿った回答を顧客に提供する。
- 作業負担の軽減一般的な問題を自動化することで、手作業のサポートチームからプレッシャーを取り除き、より複雑な問題に対処できるようになります。
- パーソナル・サービスこのシステムは、顧客の履歴や好みを分析することで、個々のニーズに合わせて対応やインタラクションをカスタマイズする。
- インタラクティブな体験の向上質の高いサポート・サービスは顧客満足度を高め、顧客との関係を強化する。
3. 規制遵守とリスク管理
- 規制分析RAGシステムは、法律文書や規制ガイダンスをスキャンして解釈し、コンプライアンスを確保します。
- リスク識別このシステムは、社内ポリシーと外部規制を比較することで、潜在的なコンプライアンス・リスクを迅速に特定します。
- コンプライアンスに関する推奨事項企業がコンプライアンスのギャップを埋め、法的リスクを軽減するための実践的なアドバイスを提供する。
- 効率的な報告監査や検査が容易なコンプライアンス・レポートやサマリーを作成します。
4. 製品開発とイノベーション
- 顧客フィードバック分析RAGシステムは顧客からのフィードバックを分析し、一般的な問題やペインポイントを特定します。
- 市場インサイト新たなトレンドや顧客ニーズを把握し、製品開発の指針にする。
- 革新的な提案データ分析に基づき、潜在的な製品機能や改善案を提供する。
- ポジショニング市場のニーズを満たし、競合他社に差をつける製品の開発を支援する。
5. 財務分析と予測
- データ統合RAGシステムは、財務データ、市況、経済指標を統合して総合的に分析する。
- トレンド分析金融市場のパターンやトレンドを把握し、予測や投資判断に役立てる。
- 投資アドバイス投資機会とリスク要因に関する実践的なアドバイスの提供
- 戦略計画正確な予測とデータに基づく提案を通じて、戦略的な財務意思決定をサポート。
6. 意味検索と効率的な情報検索
- 文脈理解RAGシステムは、ユーザーのクエリの文脈と意味を理解することにより、セマンティック検索を行う。
- 関連結果: 膨大なデータから最も関連性の高い正確な情報を検索することで、検索効率を向上させる。
- 時間を節約:: データ検索プロセスを最適化し、情報検索に費やす時間を短縮する。
- 精度の向上従来のキーワード検索よりも正確な検索結果を提供します。
7. コンテンツ制作の強化
- トレンドの統合RAGシステムは、生成されるコンテンツが現在の市場動向や視聴者の関心に沿ったものであることを保証するために、最新のデータを活用しています。
- コンテンツの自動生成:: テーマとターゲットオーディエンスに基づいて、コンテンツのアイデアとドラフトを自動的に生成します。
- 参加の促進より魅力的で関連性の高いコンテンツを作成し、ユーザーとのインタラクションを強化する。
- 適時更新:: コンテンツが最新のイベントや市場動向を反映し、常に最新であるようにする。
8. 要約
- ハイライトRAGシステムは、長い文書を効果的に要約し、重要なポイントや重要な発見を抽出することができる。
- 時間を節約多忙なエグゼクティブやマネジャーのために、簡潔なレポートサマリーで読む時間を節約。
- フォーカス:: 意思決定者が要点を素早く把握できるよう、キーメッセージを強調する。
- 意思決定の効率化:: 意思決定の効率を高めるため、関連情報をわかりやすく提供する。
9. 高度な質疑応答システム
- 的確な回答RAGシステムは、幅広い情報源からデータを抽出し、複雑な質問に対する正確な回答を生成します。
- アクセス向上医療や金融など、さまざまな分野における情報へのアクセスを強化する。
- コンテクストセンシティブ:: ユーザーの具体的なニーズや質問に基づき、的を絞った回答を提供する。
- 複雑さ複数の情報源を統合することで、複雑な問題に対処する。
10. 対話エージェントとチャットボット
- コンテキスト情報RAGシステムは、関連するコンテキスト情報を提供することで、チャットボットとバーチャルアシスタント間のインタラクションを強化します。
- 精度の向上:: 対話エージェントの応答が正確で有益であるようにする。
- ユーザーサポート:: インテリジェントで応答性の高いダイアログ・インターフェースを提供することで、ユーザー支援体験を向上させる。
- インタラクティブ・ネイチャー:: 関連するデータをリアルタイムで取得し、インタラクションをより自然で魅力的なものにする。
11. 情報検索
- 高度な検索RAGの検索・生成機能により、検索エンジンの精度を高めます。
- 情報断片の生成ユーザーエクスペリエンスを向上させるために、効果的なスニペットを生成します。
- 検索結果の強化:: クエリ解決を向上させるために、RAGシステムによって生成された回答で検索結果を充実させる。
- ナレッジエンジン人事ポリシーやコンプライアンス問題など、社内の疑問に答えるために会社のデータを利用し、情報へのアクセスを容易にする。
12. パーソナライズされた推薦
- 顧客データの分析過去の購入履歴やレビューを分析することで、パーソナライズされた推奨商品を生成します。
- ショッピング体験の向上:個人的な嗜好に基づいて商品を推薦することで、ユーザーのショッピング体験を向上させる。
- 増収売上を伸ばすために、顧客の行動に基づいて関連商品を勧める。
- 市場マッチング:: 顧客ニーズの変化に対応するため、推奨コンテンツを現在の市場動向に合わせる。
13. テキスト補完
- 文脈上の補足:: RAGシステムは、文脈に応じた適切な方法でテキストの一部を完成させる。
- 効率アップ:: メール作成やコード作成などの作業を簡素化するために、正確な補完を提供する。
- 生産性の向上:: ライティングやコーディングの作業時間を短縮し、生産性を向上させます。
- 一貫性の維持:: テキストの補完が既存のコンテンツやトーンと一貫していることを確認する。
14.データ分析
- 完全なデータ統合RAGシステムは、社内データベース、市場レポート、外部ソースからのデータを統合し、包括的な見解と詳細な分析を提供する。
- 正確な予測:: 最新のデータ、トレンド、過去の情報を分析することで、予測の精度を向上させる。
- インサイト・ディスカバリー:: 包括的なデータセットを分析し、新たな機会を特定・評価し、成長と改善のための貴重な洞察を提供する。
- データに基づく提言:: 戦略的意思決定をサポートし、意思決定の全体的な質を向上させるために、包括的なデータセットを分析することにより、データに基づいた提言を提供する。
15. 翻訳タスク
- 翻訳を探す:: 翻訳作業を支援するためにデータベースから関連する翻訳を取得します。
- コンテキスト生成:: 検索されたコーパスを参照し、文脈に基づいて一貫性のある翻訳を生成します。
- 精度の向上:: 翻訳の精度を向上させるために、複数のソースからのデータを使用する。
- 効率アップ自動化と文脈を考慮した生成により、翻訳プロセスを合理化します。
16. 顧客フィードバック分析
- 総合分析:: 様々な情報源からのフィードバックを分析し、顧客の感情や問題を包括的に理解する。
- 洞察繰り返されるテーマや顧客のペインポイントを明らかにする詳細なインサイトを提供する。
- データ統合社内データベース、ソーシャルメディア、レビューからのフィードバックを統合し、包括的な分析を行う。
- 有益な意思決定:顧客からのフィードバックに基づき、より迅速でスマートな意思決定を行い、製品やサービスを改善する。
これらのアプリケーションは、先進的なRAGシステムの幅広い可能性を示し、効率性、正確性、洞察力を向上させる能力を実証しています。カスタマーサポートの改善、市場調査の強化、データ分析の合理化など、先進的なRAGシステムは、戦略的な意思決定と卓越したオペレーションを推進する貴重なソリューションを提供します。
高度なRAGによる対話ツールの構築
ダイアログAIツールは、様々なプラットフォーム上で生き生きとした迅速なフィードバックを提供し、現代のユーザーインタラクションにおいて重要な役割を果たしています。強力な情報検索と高度な生成技術を組み合わせることで、対話が有益でありながら自然なコミュニケーションの流れを維持できるようにします。対話AIツールに組み込まれたRAGシステムは、自然な対話の流れを維持しながら、正確で文脈に富んだ応答をユーザーに提供することができる。本セクションでは、高度な対話ツールの構築にRAGをどのように利用できるかを検討し、これらのシステムを構築する際に注目すべき重要な要素や、実世界のアプリケーションで効果的かつ実用的に利用する方法を紹介します。
対話プロセスの設計

どのような対話ツールでも、その中心は対話フロー、つまりシステムがユーザーの入力を処理し、応答を生成する方法のステップです。高度なRAGベースのツールの場合、RAGシステムの検索機能と言語モデルの生成を最大限に活用するために、対話フローの設計を慎重に計画する必要があります。このフローは通常、いくつかの重要な段階から構成される:
-
問題の評価とリフレーミング::
- システムはまず、ユーザーから投げかけられた質問を評価し、正確な回答に必要なコンテキストを提供するために再フォーマットが必要かどうかを判断します。質問があまりにも漠然としていたり、重要な詳細が欠けている場合、システムはそれを独立したクエリに再フォーマットし、必要な情報がすべて含まれるようにします。
-
関連性チェックとルーティング::
- 質問が適切にフォーマットされると、システムはベクターストア(インデックス化された情報を含むデータベース)で関連するデータを検索します。関連情報が見つかった場合、質問はRAGアプリケーションに転送され、RAGアプリケーションは回答を生成するために必要な情報を取得します。
- ベクトルストアに関連する情報がない場合、システムは、言語モデルだけで生成された答えを続けるか、満足のいく答えが提供できないことを表明するようRAGシステムに要求するかを決定する必要がある。
-
レスポンスの生成::
- 前のステップで決定されたことに応じて、システムは検索されたデータを使用して詳細な回答を生成するか、言語モデルと対話履歴の知識に依存してユーザーに応答する。このアプローチにより、ツールは実世界の問題に対応することができる一方、よりカジュアルでオープンエンドな対話にも対応することができる。
意思決定メカニズムを活用した対話プロセスの最適化
高度なRAG対話ツールを構築する際に重要な点は、対話の流れを制御する意思決定メカニズムを実装することである。これらのメカニズムは、いつ情報を取得し、いつ生成機能に頼り、いつ関連データがないことをユーザーに通知するかをシステムがインテリジェントに決定するのに役立つ。これらの決定を通じて、ツールはより柔軟になり、様々な対話シナリオに適応することができる。
- 決断のポイント1:改革か継続か?
システムはまず、ユーザーの質問がそのまま扱えるか、それとも形を変える必要があるかを判断する。このステップでは、システムがユーザーの意図を理解し、応答を生成する前に、効率的な検索または生成を可能にするために必要なすべてのコンテキストを持っていることを確認します。 - 決断のポイント2:検索か生成か?
リモデリングが必要な場合、システムはベクトル・ストアに関連情報があるかどうかを判断する。関連するデータが見つかった場合、システムは検索と回答生成にRAGを使用する。そうでない場合、システムは言語モデルだけに頼って回答を生成するかどうかを決定する必要がある。 - 決断のポイント3:情報提供か交流か?
ベクトルストアも言語モデルも満足のいく回答を提供できない場合、システムは関連情報がないことをユーザーに通知し、対話の透明性と信頼性を維持する。
会話型RAGのための効果的なプロンプトをデザインする方法
プロンプトは言語モデルの会話行動を導く上で重要な役割を果たす。効果的なプロンプトをデザインするには、文脈情報、対話のゴール、望ましいスタイルとトーンを明確に理解する必要があります。例
- 背景情報質問を生成または適合させる際に、言語モデルが必要な文脈を確実にとらえられるように、関連する文脈情報を提供する。
- 目標志向のヒント各プロンプトの目的を明確にする。例えば、質問を調整する、検索プロセスを決定する、回答を生成する、など。
- スタイルとトーン言語モデルの出力がユーザーエクスペリエンスの期待に応えられるように、望ましいスタイル(フォーマル、カジュアルなど)とトーン(情報提供、共感など)を指定します。
高度なRAG技術を用いた対話ツールの構築には、検索と生成の長所を組み合わせた統合戦略が必要である。対話の流れを注意深く設計し、インテリジェントな意思決定メカニズムを実装し、効果的なプロンプトを開発することで、開発者は、正確で文脈に富んだ回答と、ユーザーとの自然で有意義な対話の両方を提供するAIツールを作成することができます。
高度なRAGアプリケーションを構築するには?
基本的なRAG(Retrieval Augmented Generation)アプリケーションの構築から始めるのも良いですが、より複雑なシナリオでRAGの可能性を最大限に引き出すには、基本を超える必要があります。このセクションでは、検索プロセスを強化し、応答精度を向上させ、クエリの書き換えや多段階検索などの高度なテクニックを実装する高度なRAGアプリケーションの構築方法について説明します。
高度なテクニックに飛び込む前に、RAGアプリケーションの基本的な機能を簡単におさらいしておこう。RAGアプリケーションは、言語モデル(LLM)と外部知識ベースの機能を組み合わせて、ユーザーのクエリに答える。このプロセスは通常2つのフェーズで構成される:
- 取り出すこのアプリケーションは、ベクターデータベースやその他の知識ベースから、ユーザーのクエリに関連するテキストスニペットを検索します。
- 読む検索されたテキストはLLMに渡され、これらのコンテキストに基づいてレスポンスが生成される。
この「検索して読む」アプローチは、LLMが専門知識を必要とする問い合わせに対してより正確な回答を提供するために必要な背景情報を提供する。
高度なRAGアプリケーションを構築する手順は以下の通り:
ステップ1:高度なテクニックを使って検索を強化する
検索段階は最終的なレスポンスの質にとって非常に重要である。基本的なRAGアプリケーションでは、検索プロセスは比較的単純ですが、高度なRAGアプリケーションでは、以下の拡張機能を使用することができます:
1.多段階サーチ
多段階検索は、複数のステップで検索を絞り込むことで、最も関連性の高いコンテキストをターゲットにするのに役立つ。これには通常
- 最初の幅広い検索関連しそうな文書を幅広く検索することから始める。
- 検索条件を絞り込む予備的な検索結果に基づいて、最も関連性の高いセグメントを絞り込み、より正確な検索を行います。
この方法により、検索された情報の精度が向上し、より正確な回答が得られる。
2.クエリの書き換え
クエリ書き換えは、ユーザーのクエリを、検索で関連性の高い結果が得られやすい形式に変換する。これにはいくつかの方法がある:
- ゼロサンプル書き換え具体的な例なしに、モデルの言語的理解を頼りにクエリを書き換える。
- 書き直しの少ないサンプル精度を向上させるために、モデルが類似のクエリを書き換えるのに役立つ例が提供されている。
- リライターのカスタマイズクエリ書き換え専用のモデルを微調整し、ドメイン固有のクエリをよりうまく扱えるようにする。
これらの書き換えられたクエリは、知識ベース内のドキュメントの言語と構造によく一致するため、検索精度が向上する。
3.サブクエリの分解
複数の質問や側面を含む複雑なクエリの場合、クエリを複数のサブクエリに分解することで、検索を向上させることができます。各サブクエリは元の質問の特定の側面に焦点を当て、システムはそれぞれの部分に関連するコンテキストを取得し、答えを統合することができます。
ステップ2:レスポンス生成の改善
検索プロセスを強化したら、次のステップはビッグ・ランゲージ・モデルがレスポンスを生成する方法を最適化することです:
1.バックトラックのヒント
複雑で多層的な質問に直面した場合、より広範な追加クエリを生成することが役立ちます。これらの「フォールバック」ヒントは、より広範な文脈情報を取得するのに役立ち、ビッグ・ランゲージ・モデルがより包括的な回答を生成することを可能にします。
2.仮説的文書埋め込み(HyDE)
HyDEは、ユーザーのクエリに基づいて仮想的な文書を生成し、これらの文書を使って知識ベース内のマッチする実際の文書を見つけることで、クエリの意図を捉える最先端の技術である。この手法は、クエリが関連する文脈と意味的に類似していない場合に特に適している。
ステップ3:フィードバック・ループの統合
RAGアプリケーションのパフォーマンスを継続的に改善するためには、システムにフィードバックループを組み込むことが重要である:
1.ユーザーからのフィードバック
ユーザーが回答の妥当性と正確性を評価できる仕組みを組み込む。このフィードバックは、検索と生成プロセスの調整に使用できる。
2.学習の強化
強化学習技術を使用し、モデルはユーザーからのフィードバックやその他のパフォーマンス指標に基づいて学習される。これにより、システムは失敗から学び、時間の経過とともに精度と関連性を向上させることができる。
ステップ4:拡張と最適化
RAGアプリケーションが進歩し続けるにつれて、パフォーマンスのスケーリングと最適化がますます重要になってくる:
1.分散検索
大規模な知識ベースに対応するため、複数のノードで並列に検索タスクを処理することで、待ち時間を短縮し、処理速度を向上させる分散検索システムが実装されている。
2.キャッシュ戦略
頻繁にアクセスされるコンテキストブロックを保存するキャッシュ戦略を実装することで、繰り返し検索する必要性が減り、応答時間が短縮される。
3.モデルの最適化
アプリケーションで使用される大規模な言語モデルやその他のモデルを最適化し、精度を維持しながら計算負荷を軽減する。モデルの蒸留や定量化などのテクニックは、ここで非常に役に立つ。
高度なRAGアプリケーションを構築するには、複雑な技術を実装し最適化する能力とともに、検索メカニズムと生成モデルに関する深い理解が必要です。上記で説明したステップに従うことで、ユーザーの期待を上回り、様々なアプリケーションシナリオに対して高品質で文脈に沿った正確な応答を提供する高度なRAGシステムを構築することができます。
高度なRAGにおけるナレッジグラフの台頭
複雑なデータ駆動型タスクにおいてAIへの依存が高まる中、高度な検索補強生成(RAG)システムにおける知識グラフの役割は特に重要になっている。ガートナーによれば ナレッジグラフは、将来いくつかの市場を破壊することを約束する最先端技術のひとつである。レーダーに影響を与える新技術 ナレッジグラフは、高度なAIアプリケーションの中核となるサポートツールであり、データ管理、推論能力、AI出力の信頼性の基盤を提供するものであると指摘した。このため、医療、金融、小売などさまざまな業界でナレッジグラフが広く使用されている。
ナレッジグラフとは何か?

ナレッジグラフは、エンティティ(ノード)とそれらの間の関係(エッジ)が明示的に定義された情報の構造化表現である。これらのエンティティは、具体的なオブジェクト(人や場所など)であったり、抽象的な概念であったりする。エンティティ間の関係は、データ検索、推論、推論をより人間の認知的なものにする知識ネットワークの構築に役立つ。ナレッジ・グラフは、単にデータを格納するだけでなく、ドメイン内の豊かで微妙な関係を捉えることができるため、AIアプリケーションにおいて強力なツールとなる。
知識グラフによるクエリの強化とプランニング
クエリー・エンハンスメントは、RAGシステムにおける不明瞭な質問の問題に対する解決策である。その目的は、曖昧な質問でも正確に解釈できるように、クエリに必要な文脈を追加することである。例えば、金融の分野では、"金融規制の実施における現在の課題は何ですか?"のような質問があります。"金融規制を実施する上での現在の課題は何ですか?"といった質問には、"AMLコンプライアンス "や "KYCプロセス "といった特定のエンティティを含めるように強化することで、検索プロセスを最も関連性の高い情報に集中させることができる。
法的な領域では、"契約に関連するリスクは何か?"のような質問のような質問は、ナレッジグラフによって提供されるコンテキストに基づいて、「労働契約」や「サービス契約」のような特定の契約タイプを追加することによって補強することができます。
一方、クエリープランニングは、サブクエッションを生成することによって、複雑なクエリーを管理可能な部分に分解する。これにより、RAGシステムは最も関連性の高い情報を取得・統合し、包括的な回答を提供することができます。例えば、"新しい財務報告基準が会社に与える影響は何か?"という質問に答えるために、システムはまず、新しい財務報告基準のデータを取得します。という質問には、まず個々の報告基準、実施スケジュール、様々な分野への過去の影響に関するデータを検索します。
医療分野では、「最新の医療機器の進歩は?のような質問は、「埋め込み型機器」、「診断機器」、「手術器具」のような特定の分野の進歩を探る小質問に分けることができ、システムは各小分類から詳細かつ適切な情報を得ることができます。各サブカテゴリーから詳細かつ関連性の高い情報を得ることができる。
ナレッジグラフは、クエリの強化とプランニングを通じて、クエリの最適化と構造化を支援し、情報検索の精度と関連性を向上させ、最終的には金融、法律、ヘルスケアなどの複雑な分野で、より正確で有用な回答を提供します。
RAGにおける知識グラフの役割

検索強化生成(RAG)システムでは、知識グラフは、構造化された文脈の豊富なデータを提供することによって、検索と生成のプロセスを強化する。従来のRAGシステムは、非構造化テキストとベクトルデータベースに依存しており、不正確または不完全な情報検索につながる可能性がある。ナレッジグラフを統合することで、RAGシステムは以下のことが可能になる:
- クエリ理解の向上 ナレッジグラフは、システムがクエリの文脈と関係をよりよく理解し、関連データをより正確に検索するのに役立つ。
- 回答生成の強化: ナレッジグラフによって提供される構造化されたデータは、より首尾一貫した、文脈に関連した回答を生成し、AIのエラーのリスクを低減することができます。
- 複雑な推論を実装する: 知識グラフはマルチホップ推論をサポートし、システムは複数の関係をトラバースすることによって、新しい知識を推論したり、異種の情報を接続したりすることができる。
ナレッジグラフの主な構成要素
ナレッジグラフは次のような主な構成要素からなる:
- ノード 人、場所、物など、知識分野のさまざまな実体や概念を表す。
- サイドだ: ノード間の関係を記述し、これらのエンティティがどのように相互接続されているかを示す。
- 属性: ノードやエッジに関連する追加情報またはメタデータで、より詳細なコンテキストや詳細を提供する。
- トライアド: 知識グラフの基本的な構成要素は、トピック、述語、およびオブジェクト(例えば、"アインシュタイン" [トピック] "発見" [述語] "相対性理論" [オブジェクトなど)、これらのトリプルは、エンティティ間の関係を記述するための基本的な枠組みを構築する。
ナレッジグラフ-RAG手法
KG-RAGの方法論は、3つの主要なステップで構成されている:
- KG建設: このステップでは、構造化されていないテキストデータを構造化された知識グラフに変換し、データが整理され、関連性があることを確認する。
- 取得した: チェーン・オブ・エクスプロレーション(CoE)と呼ばれる新しい検索アルゴリズムを用いて、システムは知識グラフを通してデータ検索を行う。
- 応答生成: 最後に、検索された情報は、ナレッジグラフの構造化されたデータと大規模な言語モデルの機能を組み合わせることで、一貫性のある文脈化された応答を生成するために使用される。
この方法論は、RAGシステムの検索と生成プロセスを強化する上で、構造化知識の重要な役割を強調している。
RAGにおけるナレッジグラフの利点
ナレッジグラフをRAGシステムに組み込むことは、いくつかの大きな利点をもたらす:
- 構造化された知識表現: ナレッジグラフは、エンティティ間の複雑な関係を反映する方法で情報を整理し、データの検索と利用をより効率的にする。
- 文脈の理解: ナレッジグラフは、エンティティ間の関係を把握することで、より豊かなコンテキスト情報を提供し、RAGシステムがより適切で首尾一貫した回答を生成できるようにする。
- 推理力: ナレッジ・マッピングは、より包括的で正確な回答を生成するために、エンティティ間の関係を分析することによって、システムが新しい知識を推論するのに役立つ。
- 知識の統合: ナレッジグラフは、異なるソースからの情報を統合し、より包括的なデータのビューを提供し、より良い意思決定を支援することができます。
- 解釈可能性と透明性: 知識グラフの構造化により、推論経路が明確で理解しやすくなり、結論形成プロセスの説明が容易になり、システムの信頼性が向上する。
KGとLLM-RAGの統合
RAGシステムにおいて、知識グラフを大規模言語モデリング(LLM)と併用することで、全体的な知識表現と推論機能が強化される。LLMは構造化データと非構造化データの両方を利用することができ、より質の高い結果をもたらします。
思考連鎖クイズにおけるナレッジグラフの活用
ナレッジマッピングは、特にラージ・ランゲージ・モデリング(LLM)と併用されることで、思考連鎖クイズで人気を集めています。このアプローチは、複雑な質問をサブクエスチョンに分解し、関連する情報を検索し、最終的な答えを形成するために統合することで機能します。ナレッジグラフはこのプロセスにおいて構造化された情報を提供し、LLMの推論力を強化します。
例えば、LLMエージェントは、まず知識グラフを使ってクエリに関連するエンティティを特定し、次に異なるソースからさらに情報を取得し、最後にグラフ内の相互接続された知識を反映した包括的な回答を生成する。
知識グラフの実践的応用
過去において、ナレッジグラフは主にビッグデータ分析やエンタープライズ検索システムのようなデータ集約的な領域で使用されており、その役割は異なるデータサイロ間の一貫性と均一性を維持することであった。しかし、大規模な言語モデル駆動型RAGシステムの開発により、ナレッジグラフは新たな応用シナリオを発見した。ナレッジグラフは現在、確率的な大きな言語モデルを構造的に補完する役割を果たし、誤った情報を減らし、より多くの文脈を提供し、AIシステムにおける記憶とパーソナライゼーションのメカニズムとして機能する。
GraphRAGの紹介

GraphRAGは、知識グラフとベクトルデータベースをRAG(Retrieval Augmented Generation)アーキテクチャで組み合わせた最先端の検索手法である。このハイブリッド・モデルは、より正確で、文脈に即した、理解しやすいAIソリューションを提供するために、両システムの長所を活用しています。ガートナーは次のように述べている。 商品戦略を強化し、新たなAI応用シナリオを創造する上で、ナレッジグラフの重要性が高まっている。
GraphRAGの特徴は以下の通り:
- より高い精度: 構造化データと非構造化データを組み合わせることで、グラフラグはより正確で包括的な回答を提供することができる。
- スケーラビリティ: このアプローチは、RAGアプリケーションの開発とメンテナンスを簡素化し、より優れたスケーラビリティを可能にする。
- 解釈可能性: GraphRAGは、システムの透明性を高める明確な推論パスを提供し、AIの出力をより理解しやすく、信頼できるものにする。
グラフラグの利点
GraphRAGには、従来のRAG手法と比較していくつかの大きな利点がある:
- より質の高い回答: ナレッジグラフを統合することで、AIが生成する回答の精度と関連性が向上し、最近のベンチマークでは精度が3倍向上している。
- 費用対効果: GraphRAGは、よりコスト効率が高く、より少ないコンピューティングリソースとトレーニングデータを必要とし、AIへの投資を最適化したい組織にとって魅力的な選択肢である。
- より優れたスケーラビリティ: このアプローチは大規模なAIアプリケーションをサポートし、組織がより複雑なクエリや大規模なデータセットを容易に扱えるようにする。
- 解釈可能性の向上: GraphRAGの構造化されたアプローチは、推論パスを明確にし、AIの意思決定プロセスをより透明化し、デバッグを容易にする。
- 隠されたコネクションを明らかにする ナレッジグラフは、大きなデータセットでは気づかない関係性を明らかにし、より深い洞察を提供し、意思決定プロセスの質を高めることができる。
一般的なGraphRAGアーキテクチャ
知識グラフをRAGシステムに効果的に統合する方法として、いくつかのGraphRAGアーキテクチャが登場している:
- セマンティッククラスタリングによる知識グラフ: このアーキテクチャは、回答を生成する前に関連情報をクラスタリングすることで、データ検索の関連性と精度を向上させる。
- 知識グラフとベクトルデータベースの統合: このアーキテクチャは、2つのシステムを組み合わせることで、より大きな言語モデルにより豊かなコンテキストを提供し、その結果、より包括的でコンテキストに適した応答が生成される。
- 知識グラフを強化した質問応答システム: このアーキテクチャでは、ベクトル検索後に大規模言語モデルによって生成された回答にナレッジグラフが事実情報を追加し、回答の正確性と完全性を保証する。
- グラフによるハイブリッド検索 このアプローチでは、ベクトル検索、キーワード検索、グラフ固有のクエリを組み合わせることで、大規模な言語モデルが関連性の高い応答を生成する能力を高める、強力で柔軟な検索システムを提供する。
グラフラグの新モデル
グラフラグは進化を続けており、いくつかの新たなパターンが現れ始めている:
- 問い合わせの強化: ナレッジグラフを使用してクエリを最適化・強化し、最も関連性の高い情報を確実に取得。
- 回答強化: 関連する事実を追加することで、ビッグ・ランゲージ・モデルによって生成された回答の正確性と完全性を向上させる。
- アンサーコントロール: ナレッジグラフを使用して、AIが生成したコンテンツの正確性を検証し、誤った情報や虚偽の情報のリスクを低減する。
これらのパターンは、AIシステムが複雑なクエリを処理して答えを生成する方法を、グラフラックがどのように変えているかを示している。
グラフラグの応用
- 法的調査: 複雑な法律、法学、事例研究の網の目をナビゲートするグラフラグの能力は、関連する法律情報や潜在的なつながりを発見するための強力なツールを法律専門家に提供します。
- ヘルスケア ヘルスケアにおいて、グラフラグは医学的知識、患者の病歴、治療法の選択肢の複雑な関係を理解し、診断の精度と個人に合わせた治療計画を改善するのに役立つ。
- 財務分析: GraphRAGは、複雑な金融ネットワークや依存関係の分析を支援し、ナレッジグラフの相互接続データを使用して、市場動向、リスク管理、投資戦略に関する洞察を提供します。
- ソーシャルネットワーク分析: GraphRAGは、複雑な社会構造と相互作用を探索することを可能にし、研究者やアナリストが社会的ネットワークにおける関係と影響力のパターンを理解することを支援する。
- ナレッジ・マネジメント: グラフラグは、組織内の関係や階層を把握し活用することで、企業の知識ベースを強化し、意思決定プロセスを改善し、ビジネス内のイノベーションを促進する。
AIの進歩に伴い、知識グラフを検索補強生成システムに組み込むことがますます重要になってきている。知識グラフは、データを整理し接続するための強力なフレームワークを提供し、より正確で文脈に沿った、解釈しやすいAIソリューションにつながる。GraphRAGの登場は、知識グラフを従来のベクトル手法と組み合わせることの利点を実証し、情報検索と回答生成により包括的で効率的なアプローチを提供する。
アドバンスドRAG:マルチモーダル検索によるエンハンスド・ジェネレーションで広がる地平
人工知能の進歩は、機械の理解と生成の境界を拡大し続けるブレークスルーを伴ってきた。従来のRAG(Retrieval Augmented Generation)システムは主にテキストデータに焦点を当ててきたが、マルチモーダルRAGの出現は重要な技術的飛躍を意味する。この革新的な技術により、AIはテキスト、画像、音声、動画など複数の形式のデータを処理・統合し、コンテンツが豊富で文脈に応じた出力を生成できるようになる。マルチモーダルデータを活用することで、これらの高度なAIシステムは、より柔軟で文脈に敏感となり、より深い洞察とより正確な応答を提供できるようになる。本セクションでは、マルチモーダルRAGの中核概念、運用メカニズム、潜在的なアプリケーションを探求し、次世代のAIインタラクションにおけるその重要性を強調する。
マルチモーダルRAGを理解する
マルチモーダルRAGは、古典的なRAGフレームワークの高度な拡張であり、複数のデータタイプに対する検索メカニズムと生成AIを組み合わせたものである。従来のRAGシステムは、テキストデータベースへのクエリによって情報を取得するが、マルチモーダルRAGは、テキスト、画像、音声、動画を検索と生成プロセスに統合することによって、この機能を拡張する。この拡張により、AIモデルはより広範な入力を活用し、より包括的でニュアンスのある結果を生成することができる。
マルチモーダルRAGの仕組みは?
マルチモーダルRAGのワークフローでは、AIモデルが処理できるように、さまざまな種類のデータを構造化フォーマット(通常はベクトル)にエンコードする。これらのベクトルは、異なるモダリティからのデータを含む共有埋め込み空間に格納される。クエリーが行われると、モデルはこれらのモダリティから関連情報を検索し、より豊かで正確な応答が提供されるようにする。例えば、歴史的な出来事に関するクエリの場合、システムはテキストの説明、関連する画像、専門家の解説のオーディオクリップ、ビデオ映像を取得することができ、これらを組み合わせることで、より詳細で有益な応答が形成される。
マルチモーダルRAGの実施方法
マルチモーダルなRAGを実現するためには、それぞれ独自の利点と課題を持つ多くのアプローチがある:
- 単一のマルチモーダルモデル:
このアプローチでは、さまざまなデータタイプ(テキスト、画像、音声など)を共通のベクトル空間にエンコードするように訓練された統一モデルを使用する。このモデルは、これらのデータタイプをシームレスに検索し、生成することができる。このアプローチでは、単一のモデルを使用することでプロセスが簡素化される一方で、マルチモーダルデータの正確なエンコードと検索を保証するために複雑なトレーニングが必要となります。 - テキストベースのベースモーダル:
このアプローチでは、非テキストデータをテキスト記述に変換してからエンコードして保存する。このアプローチでは、現在の最先端のテキストモデルを活用する。しかし、画像や音声のニュアンスがテキストに完全に表現されない可能性があるため、変換処理中に情報損失が発生する可能性がある。 - 複数のエンコーダー:
このアプローチでは、異なるデータ型をエンコードするために異なるモデルを使用し、それぞれが専用のモデルで処理される。検索プロセスでは、これらの結果を統合する。このアプローチでは、より専門的なコーディングとより正確なデータ検索が可能になる反面、システムの複雑さが増し、複数のモデルとその相互作用を注意深く管理する必要がある。
マルチモーダルRAGのアーキテクチャ
マルチモーダルRAGのアーキテクチャは、従来のRAGの基礎の上に構築され、同時に複数のデータタイプを扱う複雑さを取り入れている。コアとなるアーキテクチャには以下の主要コンポーネントが含まれる:
- モード別エンコーダー:
テキスト、画像、音声などの各データモダリティは、専用のエンコーダーによって処理される。これらのエンコーダーは、生データを統一された埋め込み空間に変換し、すべてのモダリティを標準化された方法で比較・検索できるようにします。 - 共有の埋め込みスペース:
マルチモーダルRAGの重要な構成要素は、異なるモダリティから符号化されたベクトルを格納する共有埋め込み空間である。この空間は、クロスモーダルな比較と検索を可能にし、モデルが異なるデータタイプの関連情報を認識することを可能にする。 - レトリーバー
Retrieverコンポーネントは、モダリティにまたがって最も関連性の高いデータポイントを見つけるために、共有埋め込み空間に問い合わせを行う。入力クエリとの関連性や、空間内の他のデータポイントとの類似性など、様々な基準に基づいて情報を取得することができる。 - 発電機:
関連情報が検索されると、ジェネレーター・コンポーネントがこのデータをAIモデルの応答に統合する。ジェネレーターは通常、複雑な言語モデルであり、複数のモダリティからの洞察を首尾一貫した文脈に正確な出力に織り交ぜることができる。 - 統合メカニズム:
フュージョンメカニズムは、検索されたマルチモーダルデータを、ジェネレーターが使用するための統一された表現に結合する役割を担う。このプロセスは、包括的な応答を作成するために、最も関連性の高いモダリティを選択するか、異なるソースからの情報を合成することを含むかもしれない。
RAGシステムで異なるモダリティの情報を管理するには、いくつかの重要な戦略を採用する必要がある:
- 空間に均一に埋め込まれている:
すべてのデータタイプを共通の埋め込み空間にエンコードすることで、システムはクロスモーダルな検索操作を効率的に行うことができる。同時に、この埋め込み空間は、異なるソースからのデータを統合し、整合させるための基盤を提供する。 - クロスモーダルな注意のメカニズム:
クロスモーダルアテンションメカニズムを使用することで、検索されたデータがどのモダリティのものであっても、モデルが最も関連性の高い情報に集中できるようになる。これにより、最終的な回答における各データの重要性のバランスをとることができる。 - モダリティ別の後処理:
検索が完了した後、データの統合や生成に最適な状態にするために、画像のリサイズや音声の正規化など、各モダリティごとにデータの後処理が必要になる場合がある。
チャットボットにおけるマルチモーダルRAG
マルチモーダルRAGは、チャットボットの能力を大幅に向上させ、より豊かで文脈に沿ったインタラクティブな体験を提供することを可能にします。従来のチャットボットは主にテキストに依存していたため、視覚や聴覚を伴う情報への対応に限界がありました。マルチモーダルRAGは、チャットボットが画像、動画、音声クリップから情報を取得・統合し、より包括的で興味深いユーザー体験を提供することを可能にします。
例えば、マルチモーダルRAGの カスタマーサポート・チャットボット ユーザーからの問い合わせに対して、説明ビデオ、製品画像、音声ガイドを表示することができ、よりインタラクティブで実用的なヘルプが可能になります。これは、小売、医療、教育など、複数の情報によってコミュニケーションをサポートする必要がある分野で特に重要です。
マルチモーダルRAGアプリケーションの拡大
マルチモーダル機能の導入は、さまざまな業界に新たな可能性をもたらしている:
- ヘルスケア
マルチモーダルRAGは、テキストカルテ、放射線画像、検査結果、患者の音声説明を組み合わせて、診断システムの正確性と包括性を向上させることができる。 - 財務:
金融サービスでは、マルチモーダルRAGは、表、グラフ、説明テキストを含む複雑な文書を処理・分析し、意思決定プロセスを改善することができる。 - 教育:
教育プラットフォームは、マルチモーダルRAGを活用することで、テキスト、ビデオ講義、イラスト、インタラクティブなシミュレーションを完全な教育ストーリーに融合させ、より豊かな学習体験を提供することができる。
マルチモーダルRAGは、AIシステムがユーザーと対話し対応する方法を変える可能性を秘めた重要な技術的進歩である。複数のデータタイプを検索・生成プロセスに組み込むことで、マルチモーダルRAGシステムは、より豊かで、より正確で、文脈に沿った出力を提供することができ、業界全体に新たな可能性を開くことができる。この技術が進化するにつれて、複雑なマルチモーダル情報を処理するAIの能力がさらに強化され、その用途が拡大することが期待される。
LeewayHertzのGenAI連携プラットフォーム「ZBrain」は、先進的なRAGシステムの中でどのように際立っているか。
高度なRAG、マルチモーダルRAG、ナレッジグラフに興味がありますか?高度なAIアプリケーションを簡単に構築できる単一のプラットフォームに、これらの強力な機能を組み合わせることを想像してみてください。それがZBrainです。
ゼットブレインLeewayHertzによって開発されたZBrainは、エンタープライズクラスのAIソリューションの開発とスケーリングを簡素化し、加速するために設計された包括的なオーケストレーションプラットフォームです。ZBrainは、ユーザーフレンドリーなローコード環境を通じて、カスタマイズされたジェネレーティブAI(GenAI)アプリケーションの迅速な作成、デプロイ、拡張を可能にします。このプラットフォームは、企業が独自のデータを活用して高度にカスタマイズされた正確なAIアプリケーションを構築できるようにすることで、企業のAI開発プロセスに革命をもたらします。ZBrainは中央管理センターとして、既存の技術スタックとシームレスに統合し、GenAIアプリケーション開発の効率を向上させます。ZBrain上に構築されたアプリケーションは、レポート生成、翻訳、データ分析、テキスト分類、要約などの自然言語処理(NLP)タスクに優れています。プライベートデータとコンテキストデータを活用することで、ZBrainは、特定のビジネスニーズを満たすために、応答が高度に関連し、パーソナライズされることを保証します。
高度な検索機能拡張世代(RAG)システムとのインターフェイス方法
- 多様なデータソースの統合: ZBrainは、あらゆるデータ形式(構造化、半構造化、非構造化)のプライベート、パブリック、リアルタイムのストリームを含むさまざまなデータソースを統合し、AIの応答の精度と関連性を向上させます。
- ブロックレベルの最適化: このプラットフォームは、情報を管理しやすい塊に分解し、最も効果的な検索戦略を適用することで、正確でカスタマイズされたアウトプットを確実に生成する。
- 検索戦略の自動発見 ZBrainの高度なアルゴリズムは、自動的に最適な検索戦略を特定し適用するため、データとコンテキストに基づく手作業を減らし、データ検索の精度を向上させます。
- 保護措置と幻覚コントロール: ZBrainは、不正確な情報や誤解を招く情報の生成を防ぐためのセーフガードとファントムコントロールを備えており、高い精度と信頼性を確保している。
マルチモーダル機能
- 複数のデータ形式を扱う。 ZBrainは、テキスト、画像、動画、音声など複数のデータ形式の取り扱いに優れており、包括的で詳細な回答を提供します。
- データタイプを超えた統合と分析。 このプラットフォームは、さまざまな種類のデータを統合して分析し、より豊かな洞察と適切な回答を提供することができる。
- クエリ処理の改善 ZBrainは複数のデータモダリティから効率的に情報を管理・検索し、複雑な問題に対する精度と洞察力を向上させます。
ナレッジマップ
- 構造化データフレームワーク。 ZBrainはデータを構造化されたネットワークに整理し、検索精度を向上させ、関連する概念を結びつけることでより深い洞察を提供します。
- より深いデータの洞察 ナレッジグラフの相互接続性により、ZBrainは、より豊かで意味のある洞察につながる、文脈を考慮したニュアンスのある回答を提供することができます。
- データ機能の拡張。 ZBrainは、ブロックやファイルレベルでのデータの拡張、メタ情報の更新、オントロジーの生成をサポートし、データの表現、整理、検索を改善します。
エンタープライズAIソリューション開発でZBrainを使用するメリット
ZBrainは、企業のAIソリューション開発に多くの利点を提供する:
- スケーラビリティ
ZBrainは、AIソリューションの拡張を容易にし、パフォーマンスを損なうことなく、データ量や使用シナリオの増加に対応します。 - 効率的な統合
このプラットフォームは既存のテクノロジー・スタックと容易に統合できるため、導入にかかる時間とコストを削減し、AIの導入を加速する。 - カスタマイズ
ZBrainは、特定のビジネスニーズを満たし、組織の目標に沿った高度にカスタマイズされたAIアプリケーションの開発をサポートします。 - 資源効率
ローコードであるため、多数の開発者を必要とせず、小規模な技術チームを抱える組織に適している。 - 包括的なソリューション
開発から導入まで、ZBrainはAIアプリケーションのライフサイクル全体をカバーし、包括的なソリューションとなっている。 - クラウドニュートラルな展開
ZBrainはクラウドニュートラルであるため、アプリケーションをさまざまなクラウドプラットフォームに展開することができ、さまざまな組織のニーズやインフラの好みに柔軟に対応できる。
ZBrainの先進的なRAGシステム、マルチモーダルサポート、強固なナレッジグラフ統合により、幅広いアプリケーションで精度、効率、洞察力の向上を実現する強力なプラットフォームとなっています。
脚注
RAG(Retrieval-AugmentedGeneration)の進歩はその能力を飛躍的に向上させ、これまでの限界を克服し、AI主導の情報検索・生成における新たな可能性を切り開くことを可能にした。洗練された検索メカニズムを使用することで、高度なRAGは大量のデータにアクセスし、生成される応答が正確かつ文脈に即したものであることを保証することができる。この進歩は、よりダイナミックでインタラクティブなAIアプリケーションへの道を開き、RAGを顧客サービス、研究、知識管理、コンテンツ作成などの分野で重要なツールとする。このような先進的なRAGテクノロジーを応用することで、組織はユーザーエクスペリエンスを向上させ、プロセスを合理化し、複雑な問題をより正確かつ効率的に解決する機会を得ることができる。
Multimodal RAGとKnowledge Graph RAGの導入により、このフレームワークの機能がさらに強化され、業界全体で広く採用されるようになりました。マルチモーダルRAGは、テキスト、ビジュアル、その他の形式のデータを組み合わせ、ラージ・ランゲージ・モデル(LLM)がより包括的で文脈を認識した応答を生成することを可能にし、それによってユーザー体験を向上させ、より豊かでニュアンスのある情報を提供します。また、ナレッジグラフRAGは、相互接続されたデータ構造を利用して、意味的にリッチなコンテンツを検索・生成し、情報の精度と深度を大幅に向上させます。RAGテクノロジーにおけるこれらの進歩は、複雑な情報検索の課題に対してよりスマートで柔軟なソリューションを提供する、AIイノベーションの新しい波を告げるものです。