同包-1.5-プロ
モデルプロフィール
Doubao-1.5-proは非常にスパースである。 MoEアーキテクチャープリフィル/デコードとアテンション/FFNの4つの象限では、計算とアクセスの特性が大きく異なる。4つの異なる象限について、我々は異なる低精度最適化戦略と組み合わせたヘテロジニアスハードウェアを採用し、低レイテンシを確保しながらスループットを大幅に向上させ、TTFTとTPOTの最適化目標を考慮しながら総コストを削減し、性能と推論効率の究極のバランスを達成する。
- マイナーアクティベーションパラメーター非常に大規模な高密度モデルの性能を超える。
- マルチシーンへの適応複数のレビューベンチマークで優れたパフォーマンスを発揮。
📊 パフォーマンス評価
複数のベンチマークにおけるDoubao-1.5-proの結果
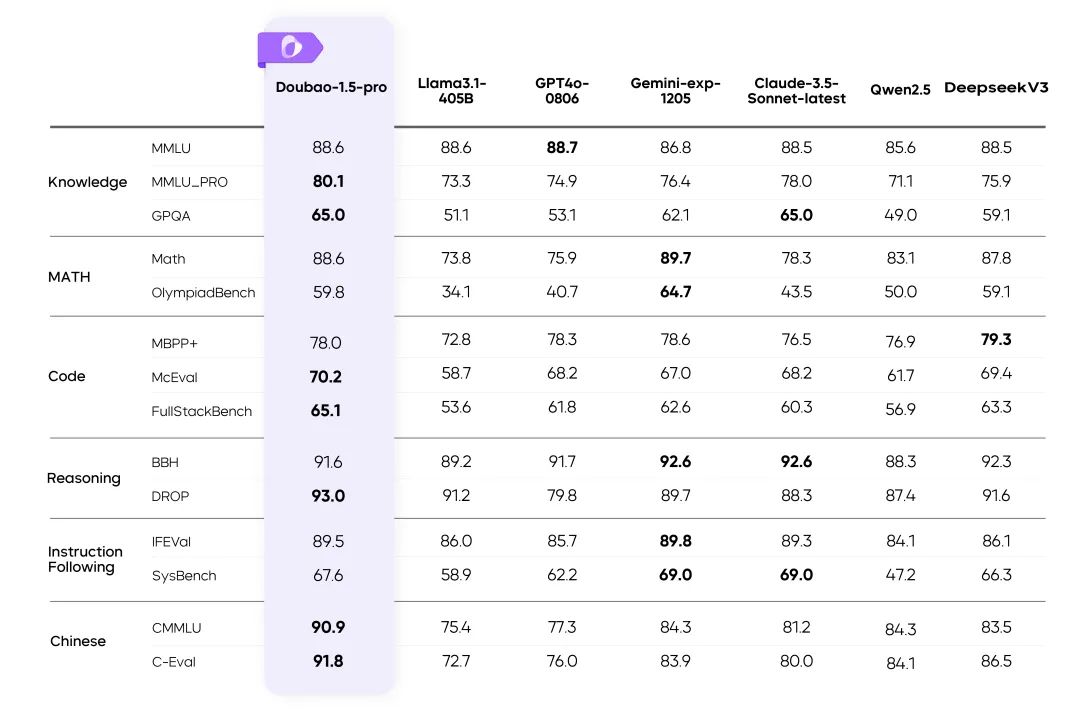
指示::
- 表中の残りのモデルの指標は公式結果からのもので、未発表の部分は内部評価プラットフォームによるものである。
- GPT4o-0806 言語モデルの公開レビューにおける優れたパフォーマンス。
⚙️ パフォーマンスと理性のバランス
効率的なMoEアーキテクチャ
- 利用する スパースMoEアーキテクチャ トレーニング効率と推論効率の二重最適化を実現。
- 研究ハイライトスパースケーリングの法則により、性能と効率の最適なバランス比を決定します。
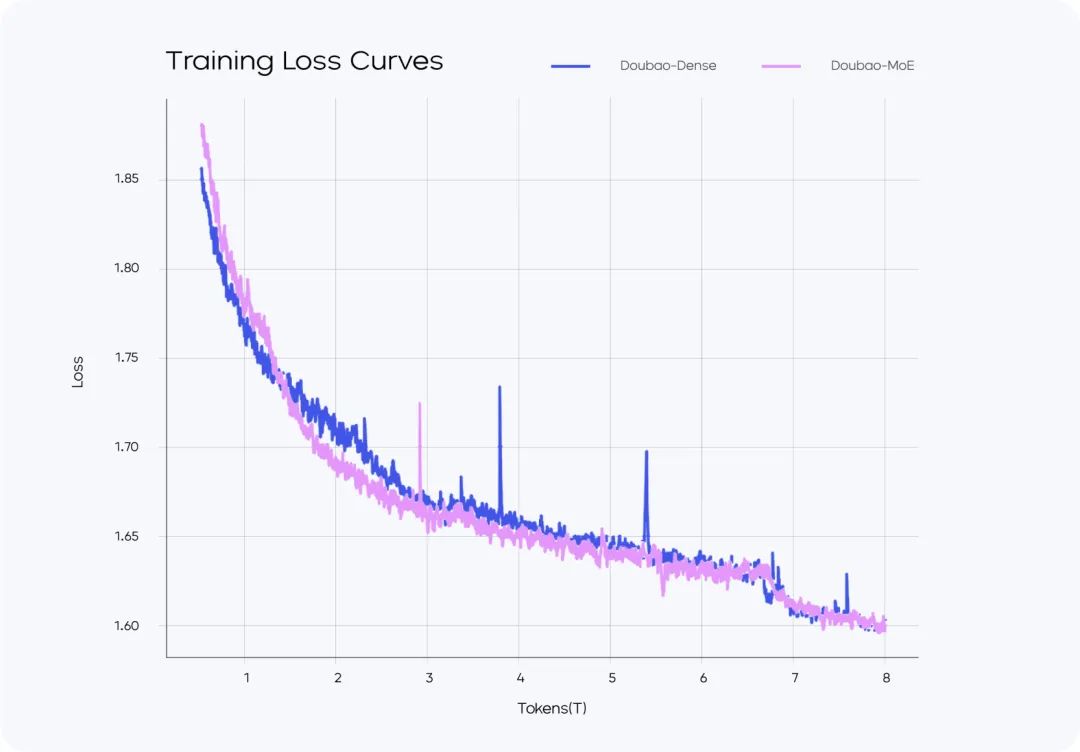
トレーニング・ロス vs. トレーニング・ロス
モデルの性能比較
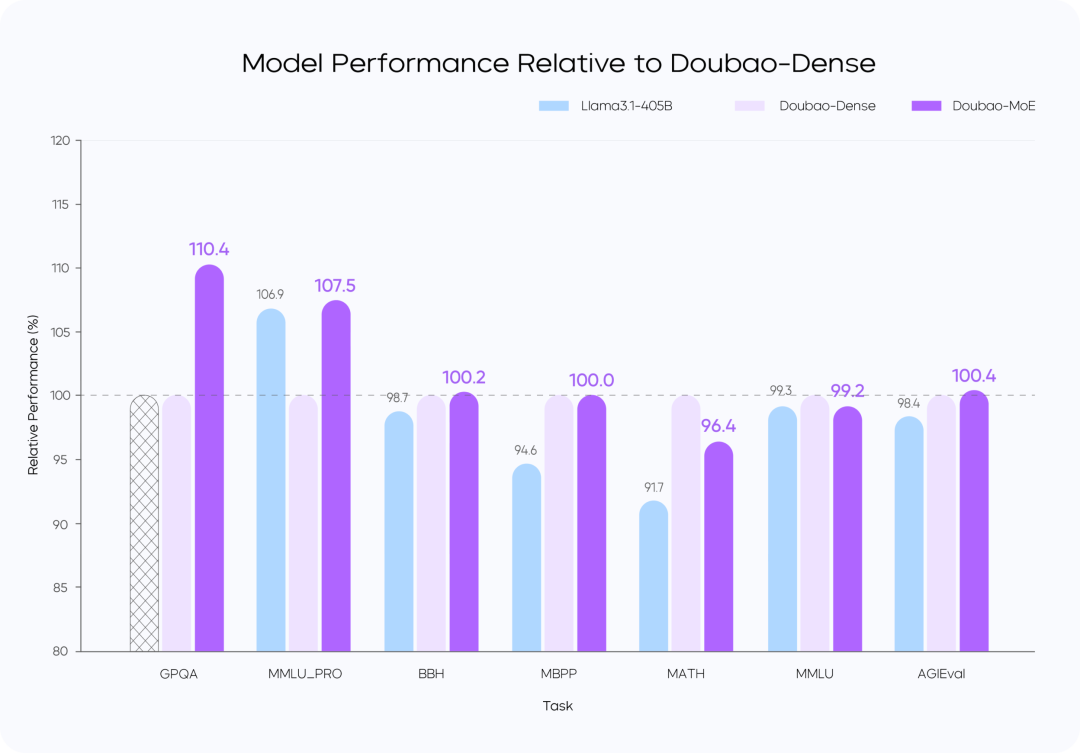
指示::
- Doubao-MoEモデルは、活性化されたパラメータの数が7倍の密なモデル(Doubao-Dense)を上回る。
- ドウバオ 密なモデル・トレーニングは、より効率的である。 ラマ3.1-405Bデータ品質と超参照の最適化が鍵となる。
🚀 高性能推論
計算およびアクセス機能の最適化
Doubao-1.5-proは、4つの計算象限(Prefill、Decode、Attention、FFN)において良好な成績を収めた。
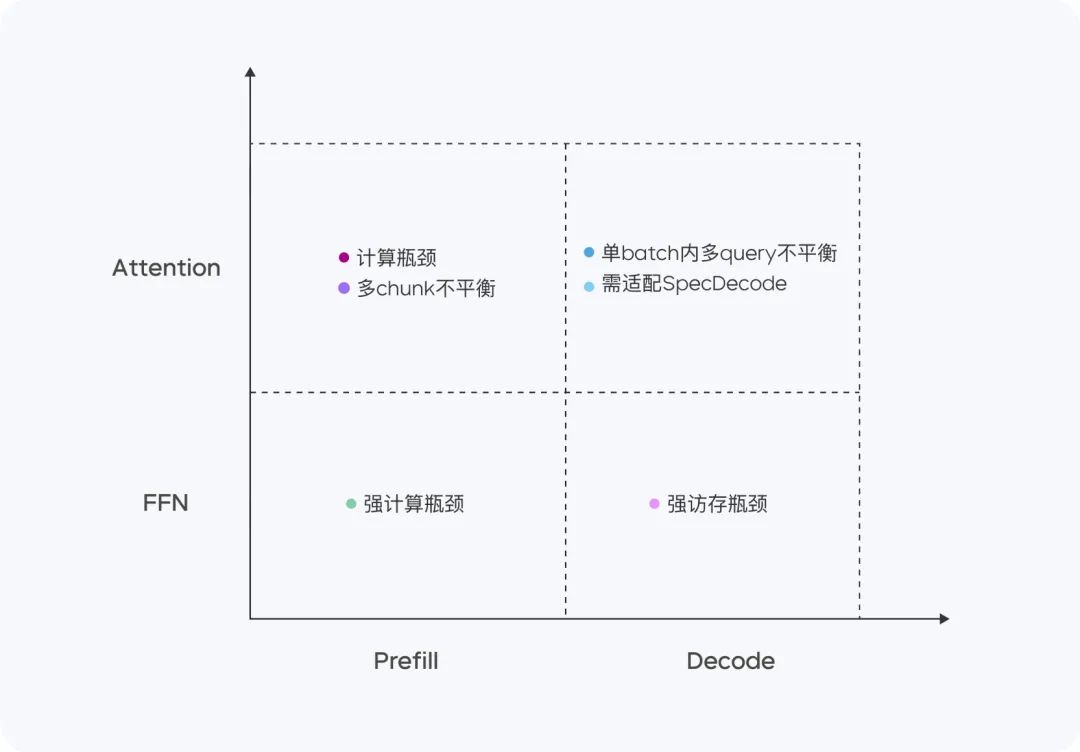
Prefillフェーズでは、通信とアクセスのボトルネックは目立たないが、計算のボトルネックは容易に到達する。LLM一方向注意の特性を考慮し、計算アクセス比率の高い複数のデバイスでChunk-PP Prefill Servingを行うことで、オンラインシステムにおけるTensor Coreの利用率を60%に近づける。
- プリフィル・アテンション:オープンソースのFlashAttention 8ビット実装をMMA/WGMMAなどの命令で拡張し、Per Nと組み合わせる。 トークン シーケンスごとの定量化戦略により、このフェーズは異なるアーキテクチャのGPUでもロスなく実行できる。一方、異なる長さのスライスのアテンション消費をモデル化し、動的クロスクエリバッチング戦略と組み合わせることで、Chunk-PP Serving中のカード間バランシングを実現し、負荷不均衡による空走を効果的に排除します;
- プリフィルFFN: W4A8定量化により、スパースMoEエキスパートのアクセスオーバーヘッドを効果的に削減し、クロスクエリバッチング戦略によりFFNステージにより多くの入力を与え、MFUを0.8に改善。
デコードフェーズでは、計算ボトルネックは明らかではないが、通信とメモリ要件が比較的高い。私たちは、より高いROIを得るために、より計算量とメモリの少ないデバイスであるServingを使用し、同時に、TPOTメトリクスを削減するために、非常に低コストのサンプリングとSpeculative Decoding戦略を使用します。
- デコード・アテンション:TPは、ヒューリスティック検索と積極的な長文分割戦略により、単一バッチ内の異なるクエリのKVの長さが大きく異なるという一般的なシナリオを最適化するために導入される。精度の面では、シーケンスごとのNトークンの定量化が引き続き採用され、さらに、KVキャッシュへのアクセスが一度だけになるように、ランダムサンプリング中のアテンション計算が最適化される。さらに、KVキャッシュが一度しかアクセスされないように、ランダムサンプリングプロセス中のAttention計算を最適化する。
- FFNのデコード:W4A8を定量化し、EPを使用して展開する。
全体として、我々はPD分離サービングシステムに以下の最適化を実施した:
- テンソル転送用のRPCバックエンドをカスタマイズし、ゼロコピー、マルチストリーム並列処理などにより、TCP/RDMAネットワーク上でのテンソル転送効率を最適化。
- PrefillクラスタとDecodeクラスタの柔軟な割り当てと動的な拡張と縮小をサポートし、PrefillとDecodeの両方に冗長な演算がないことを保証し、両側の演算割り当てが実際のオンライントラフィックパターンに一致するように、それぞれの役割に対して独立してHPA弾性拡張を行う。
- GPUコンピューティングとCPUの前後処理非同期のフレームワークでは、GPUの推論ステップNは、CPUがN + 1ステップカーネルの早期起動時に、GPUは常にフルに保つように、GPUの推論のフレームワーク全体の処理アクションは、オーバーヘッドをゼロにします。また、自社開発のサーバクラスターソリューションと低コストのチップのための柔軟なサポートでは、ハードウェアコストが大幅に業界のソリューションよりも低くなっています。また、カスタマイズされたネットワークカードと自社開発のネットワークプロトコルにより、パケット通信の効率を大幅に最適化しています。演算レベルでは、計算と通信の効率的なオーバーラップ(重ね合わせ)を実現し、マルチコンピュータ分散推論の安定性と効率性を確保しています。
Ἷ データ表示:近道はない
- 以下を組み合わせた効率的なデータ生産システムを構築する。 ラベリングチーム 歌で応える セルフ・リフティング技術のモデリングデータの質は大幅に向上した。
🖼️ マルチモーダル機能
ビジュアル・マルチモダリティ:複雑なシーンを簡単に
ダイナミック・レゾリューション・トレーニング:スループット向上 60%
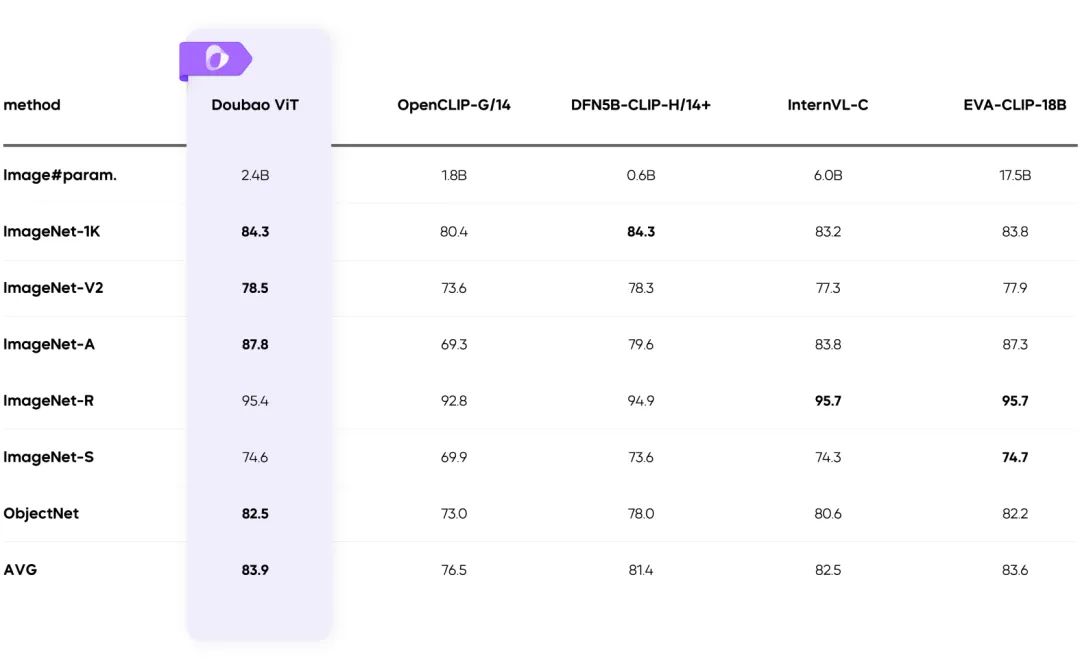
- ビジュアルエンコーダーの不均等な負荷の問題を解決し、効率を大幅に向上させます。
まとめ
Doubao-1.5-proは、高性能と低推論コストの最適なバランスを見つけ、マルチモーダルなシナリオでブレークスルーを起こす:
- 革新的なスパース・アーキテクチャーの設計。
- 高品質のトレーニングデータと最適化システム。
- マルチモーダル技術の新たなベンチマークを牽引。