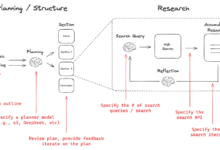
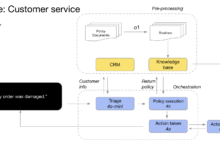
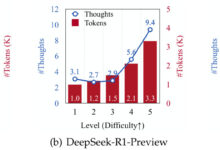
簡単
評価は、RAG(Retrieval Augmented Generation)システムの開発と最適化における重要な要素である。評価には ラグ 検索効果から回答生成に至るまで、関連性や信憑性を含むパフォーマンス、正確性、品質について、プロセスのすべての側面が測定される。
RAG評価の重要性
RAGシステムの効果的な評価は重要である:
- 検索・生成プロセスにおける強みと弱みの特定に役立つ。
- RAGプロセス全体の改善と最適化を指導する。
- システムが品質基準とユーザーの期待に応えていることを確認する。
- 異なるRAGの実装や構成の比較を容易にする。
- 幻覚、偏見、無関係な反応などの問題を発見するのに役立つ。
RAG評価プロセス
RAGシステムの評価には、通常以下のステップが含まれる:

コア評価指標
RAGAS指標
- 妥当性生成されたレスポンスと検索コンテキストとの整合性を測定する。
- 回答の妥当性クエリに対する応答の関連性を評価する。
- コンテキストリコール検索されたチャンクがクエリに答えるために必要な情報を網羅しているかどうかを評価する。
- 文脈の正確さ検索されたチャンクに含まれる関連情報の割合を示す。
- コンテキストの活用生成された応答が提供された文脈を利用する効率を評価する。
- 文脈的実体想起コンテキストの重要なエンティティがレスポンスでカバーされているかどうかを評価する。
- ノイズ感度無関係な情報やノイズの多い情報に対するシステムの頑健性を示す指標。
- 要約スコア回答の要約の質を評価する。
DeepEval指標
- G評価テキスト生成タスクの一般的な評価指標。
- 抄録要約の質を評価する。
- 回答の妥当性レスポンスがクエリにどの程度答えているかを示す指標。
- 妥当性回答や情報源の正確性を評価する。
- 文脈上の再現率と精度文脈検索の効果測定。
- 幻覚検出回答中の虚偽または不正確な情報を特定する。
- 毒物学有害または攻撃的な可能性のあるコンテンツを検出します。
- バイアス生成されたコンテンツにおける不公平な嗜好や傾向を特定する。
トルレンス・インディケーター
- 文脈的関連性検索コンテキストがクエリとどの程度一致するかを評価する。
- 根拠あり回答が検索された情報によって裏付けられているかどうかの尺度。
- 回答の妥当性クエリに対する回答の質を評価する。
- 包括性回答の完全性を測る。
- 有害/攻撃的な言葉潜在的に攻撃的または危険なコンテンツを特定する。
- ユーザー感情ユーザーとの対話における感情的なトーンの分析。
- 言語ミスマッチクエリとレスポンス間の言語使用の不一致を検出する。
- 公正と偏見制度における異なるグループの公平な扱いを評価する。
- カスタム・フィードバック機能特定のユースケース用にカスタマイズされた評価メトリクスの開発が可能です。
RAG評価のベストプラクティス
- 総合評価複数の指標を組み合わせて、RAGシステムのさまざまな側面を評価する。
- 定期的なベンチマークプロセスの変化に伴い、システムを継続的に評価する。
- 人間の参加手作業による評価と自動化された指標を組み合わせた総合的な分析。
- 領域別指標特定のユースケースやドメインに関連するカスタマイズされたメトリクスを開発する。
- エラー分析低得点回答のパターンを分析し、改善点を特定する。
- 比較評価RAGシステムをベースラインモデルや代替実装に対してベンチマークする。
評決を下す
質の高いRAGシステムの開発と維持には、強固な評価フレームワークが不可欠です。広範な評価指標を活用し、ベストプラクティスに従うことで、開発者はRAGシステムが正確で適切かつ信頼できる回答を提供し、パフォーマンスを継続的に改善することができます。