簡単
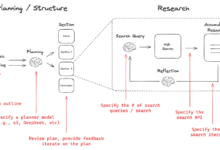
自動マージ検索は拡張検索生成(RAG)フレームワークの高レベルの実装は、以下のとおりである。このアプローチは、潜在的に断片化された小さなコンテキストを、より大きく包括的なコンテキストに統合することで、AIが生成する応答のコンテキスト認識と一貫性を高めることを目的としている。
https://github.com/adithya-s-k/AI-Engineering.academy/tree/main/RAG/05_Auto_Merging_RAG
モチベーションの背景
従来の拡張検索生成システムは、複数のテキストセグメントにまたがる情報を扱う場合、より大きなコンテキストにわたって一貫性を維持するのに苦労したり、パフォーマンスが低下したりすることが多い。自動マージ検索は、特定のしきい値を超える親ノードを参照する子ノードのセットを再帰的にマージすることで、この制限に対処する。
方法論の詳細
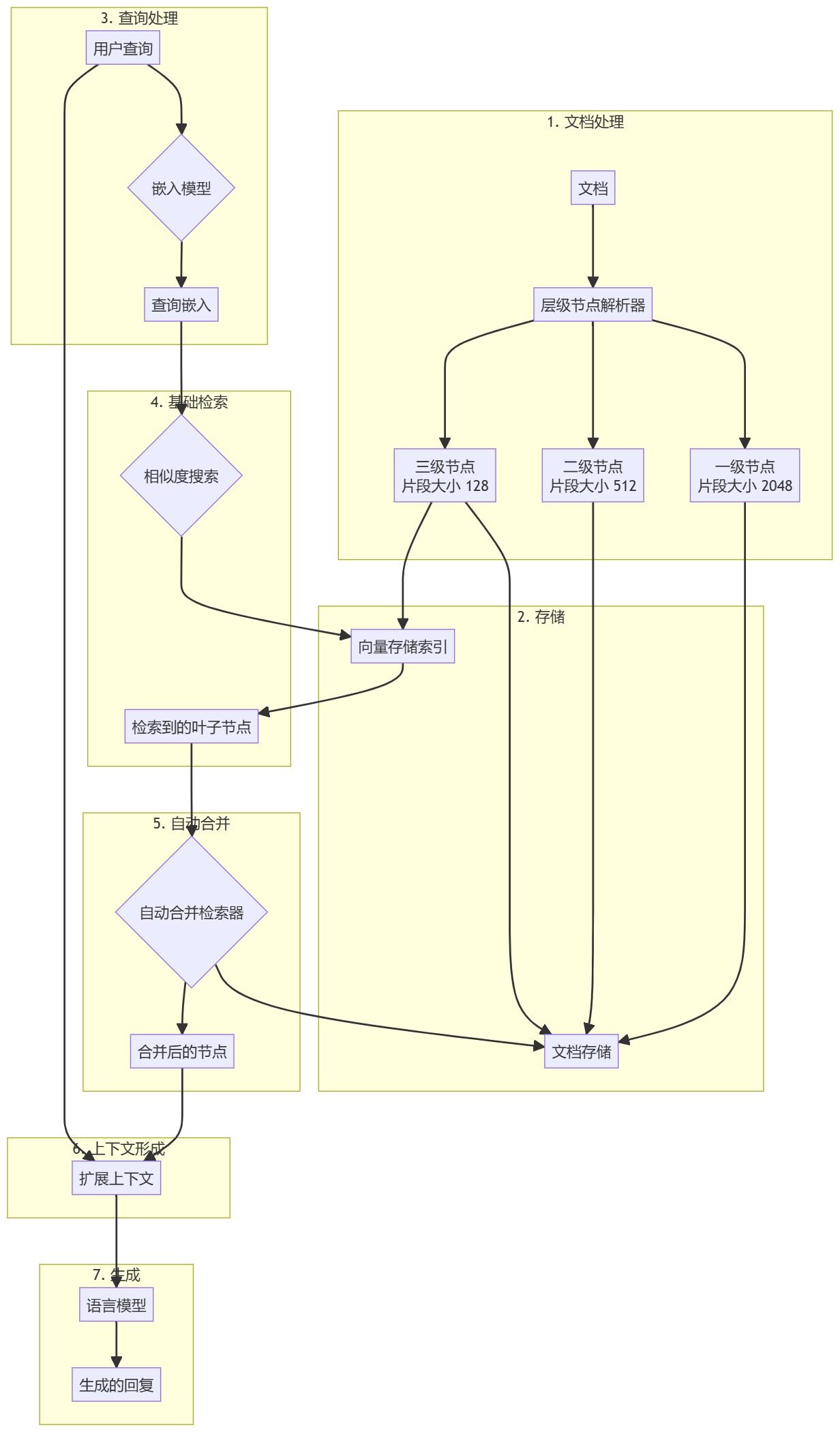
ドキュメントの前処理と階層構造の作成
- ドキュメントの読み込み入力文書(PDFファイルなど)を読み込み、処理します。
- 階層的解決使用
階層ノードパーサードキュメントからノード階層を作成します:- レベル1:ブロック・サイズ2048
- レベル2:ブロック・サイズ512
- レベル3:ブロック・サイズ128
- ノードストレージすべてのノードをドキュメント・ストアに格納し、リーフ・ノードもベクトル・ストアにインデックスされる。
検索生成ワークフローの強化
- クエリの前処理文書ブロックと同じ埋め込みモデルを使って、ユーザーからの問い合わせを処理する。
- 基本検索ベースサーチャーは、関連するリーフノードを見つけるために最初の類似検索を行う。
- オートマージ::
オートマージング・リトリーバー検索されたリーフノードの集合が分析され、与えられた閾値を超えて親ノードを参照するリーフノードのサブセットが再帰的に「マージ」される。 - コンテキスト拡張マージされたノードは拡張コンテキストを形成し、元のクエリとマージされる。
- レスポンスの生成拡張コンテキストとクエリをラージ言語モデル(LLM)に入力してレスポンスを生成します。
自動マージサーチャーの主な機能
- 階層的文書表現文書ブロックの複数レベルの階層を維持します。
- 効率的な基本検索ベクトル類似検索を用いた高速・高精度な事前情報検索の実現。
- 動的コンテキスト拡張関連するテキストブロックをより大きく、より一貫性のあるコンテキストに自動的にマージします。
- 柔軟な実現幅広い文書タイプと言語モデルに対応。
この方法の利点
- 文脈の一貫性を高める関連するテキストの塊を統合することで、より一貫性のある完全な文脈を、より大きな言語モデルに提供する。
- 柔軟な検索適応性マージプロセスは、クエリと検索結果に合わせて自動的に調整され、文脈に関連した情報を提供します。
- 効率的なストレージ構造階層構造を維持したままリーフノードの基本検索を高速に実装。
- 回答品質向上の可能性文脈を拡大することで、より正確で詳細な言語モデルへの応答が期待できる。
結果
実験結果は、自動マージ検索器とベース検索器を比較したものである:
- 正しさ、関連性、正確さ、意味的類似性の測定基準で同様のパフォーマンス。
- 対比較では、52.5%ユーザーが自動マージ検索者の回答を好んだ。
これらの結果から、自動マージ検索機の性能は、従来の検索方法に匹敵するか、わずかに優れていることがわかる。
評決を下す
自動マージ・サーチャーは、次のような改良のための高度な方法を提供する。 ラグ システムにおける検索プロセス。関連するテキストブロックをより大きく、より一貫性のあるコンテキストに動的にマージすることで、従来のテキストブロックベースの検索手法の限界のいくつかに対処している。初期の結果は良好な見通しを示しているが、さらなる研究と最適化により、応答の質と一貫性が大幅に改善されることが期待される。
前提条件
このシステムを導入するには
- テキストを生成できる大規模な言語モデル(GPT-3.5-turbo、GPT-4など)。
- テキストブロックとクエリをベクトル表現に変換する埋め込みモデル。
- 効率的な類似性検索のためのベクトルデータベース(FAISSなど)。
- 完全なノード階層を保存するための文書ストア。
- 提供
ラマインデックスライブラリには階層ノードパーサー歌で応えるオートマージング・リトリーバー実現。 - 大量の文書の処理と保存に十分なコンピューティング・リソース。
- 実装とテストのためのPythonプログラミング言語に精通していること。
使用例
from llama_index.core import StorageContext, VectorStoreIndex
from llama_index.core.node_parser import HierarchicalNodeParser
from llama_index.core.retrievers import AutoMergingRetriever
# ドキュメントをノード階層にパースする
node_parser = HierarchicalNodeParser.from_defaults()
nodes = node_parser.get_nodes_from_documents(docs)
# ストレージコンテキストを設定する
storage_context = StorageContext.from_defaults()
storage_context.docstore.add_documents(nodes)
# ベースインデックスとリトリーバーを作成する
leaf_nodes = get_leaf_nodes(nodes)
base_index = VectorStoreIndex(leaf_nodes, storage_context=storage_context)
base_retriever = base_index.as_retriever(similarity_top_k=6)
# 自動マージレトリバーを作成する
retriever = AutoMergingRetriever(base_retriever, storage_context, verbose=True)
# AutoMerging Retrieverをクエリエンジンで使用する
query_engine=RetrieverQueryEngine.from_args(retriever)
レスポンス = query_engine.query(query_str)