Cursor、V0、Bolt.new、そして最近ではWindsurfと、AIプログラミング・ツールは最近とてもホットだ。
この投稿では、オープンソースのソリューションであるBolt.newについて話を始める。
役に立たないサイト国内アクセス速度制限そしてフリー・トークンの枠には限りがあります.
それをいかにローカルで運営し、より多くの人々に使ってもらい、AIを加速させるかがモンキーの使命である。
今日のシェア地元のオッラマを配備した大型モデルをボルトでドライブする。AIプログラミングを可能にする トークン 自由だ。
1.Bolt.newの紹介
ボルト.newは、SaaSベースのAIコーディング・プラットフォームであり、LLM主導のインテリジェンスを基盤に、WebContainersテクノロジーと組み合わせることで、ブラウザ内でのコーディングと実行を可能にしている:
- フロントエンドとバックエンドの開発を同時にサポートする。.;
- プロジェクトフォルダ構造の可視化.;
- 依存関係(Vite、Next.jsなど)の自動インストールが可能なセルフホスト環境。.;
- Node.jsサーバーのデプロイから運用まで
Bolt.newのゴールは、ウェブアプリケーション開発をより多くの人に身近なものにし、プログラミング初心者でも簡単な自然言語でアイデアを実現できるようにすることだ。
プロジェクトは正式にオープンソース化された: https://github.com/stackblitz/bolt.new
しかし、公式オープンソースのbolt.newは対応機種が限られており、国内パートナーの多くは海外のLLM APIを呼び出すことができない。
コミュニティには神がいる。 ボルト・ニューアニー・エルム現地のサポートが受けられる。 オーラマ ハンズオンをご覧ください。
2.Qwen2.5-コードのローカル展開
少し前にアリはQwen2.5-Coderシリーズのモデルをオープンソース化したが、その中でも32Bモデルは10回以上のベンチマーク評価でオープンソースとして最高の結果を出している。
GPT-4oを凌駕する多くの主要機能を備えた、世界最強のオープンソース・モデルにふさわしい。
Ollamaモデルリポジトリはqwen2.5-coder用にも公開されている:
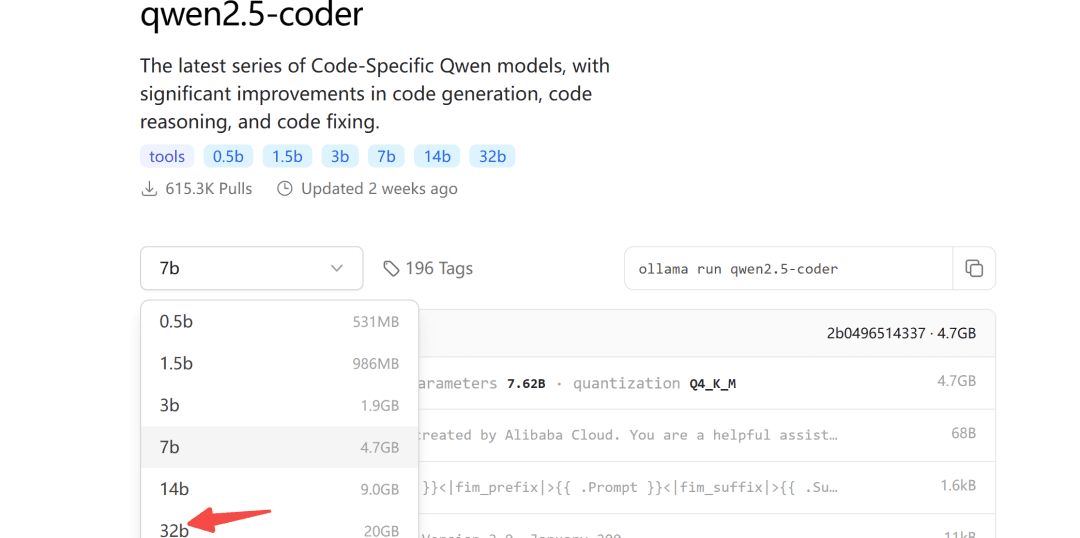
Ollamaは、大規模なモデルを展開するためのガジェットに優しいツールだ。
2.1 モデルのダウンロード
ダウンロードするモデルのサイズについては、ご自身のビデオメモリに応じて選択できますが、32Bモデルの場合、少なくとも24Gのビデオメモリが保証されます。
以下では、7bモデルでこれを実証する:
ollama pull qwen2.5-coder
2.2 モデルの修正
Ollamaのデフォルトの最大出力は4096トークンなので、コード生成タスクには明らかに不十分だ。
そのためには、コンテキスト・トークンの数を増やすために、モデルのパラメータを変更する必要がある。
まず、新しいModelfileファイルを作成し、それを埋めてください:
FROM qwen2.5-coder
パラメタ num_ctx 32768
そして、モデルの変換が始まる:
ollama create -f Modelfile qwen2.5-coder-extra-ctx
変換に成功したら、モデルリストをもう一度表示します:

2.3 モデル走行
最後に、サーバー側でモデルが正常に呼び出されるかどうかを確認します:
def test_ollama():
url = 'http://localhost:3002/api/chat'
data = {
"model": "qwen2.5-coder-extra-ctx"、
「メッセージ": [
{ "role": "user", "content": 'Hello'}.
ストリーム": False
「stream": False
}
response = requests.post(url, json=data)
if response.status_code == 200.
text = response.json()['message']['content'].
print(text)
print(text)
print(f'{response.status_code},failed')
何も問題がなければ、bolt.newで呼び出すことができる。
3.ローカルで走るボルト・ニュー
3.1 現地展開
ステップ1: ローカルモデルをサポートする bolt.new-any-llm をダウンロードする:
git clone https://github.com/coleam00/bolt.new-any-llm
ステップ2環境変数のコピーを取る:
cp .env.example .env
ステップ3環境変数をollama_api_base_urlそれを自分のものに置き換える:
# oLLAMAモデルを使用する場合のみ、この環境変数の設定が必要です。
# EXAMPLE http://localhost:11434
ollama_api_base_url=http://localhost:3002
ステップ4ノードがローカルにインストールされている場合
sudo npm install -g pnpm # pnpmはグローバルにインストールする必要があります。
pnpm インストール
ステップ5ワンクリック操作
pnpm run dev
以下の出力は、起動が成功したことを示している:
➜ ローカル: http://localhost:5173/
➜ ネットワーク: --hostを使って公開する
h + enterでヘルプを表示します。
3.2 効果の実証
ブラウザで開くhttp://localhost:5173/オーラマ・タイプを選択:
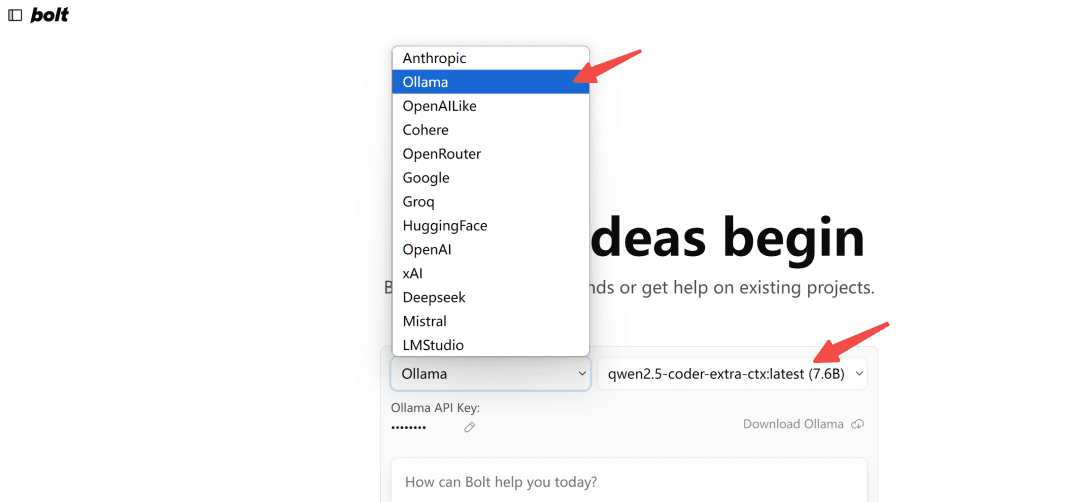
注:最初にロードしたとき、Ollamaにモデルが表示されない場合は、何度かリフレッシュして、どのように表示されるか確認してください。
試してみよう。
ウェブベースのスネークゲームを書く
左側。プロセス実行右側はコードエディタエリア、その下はエンドポイントエリアコードを書いたり、依存関係をインストールしたり、ターミナル・コマンドを実行したりするのは、すべてAIがやってくれる!
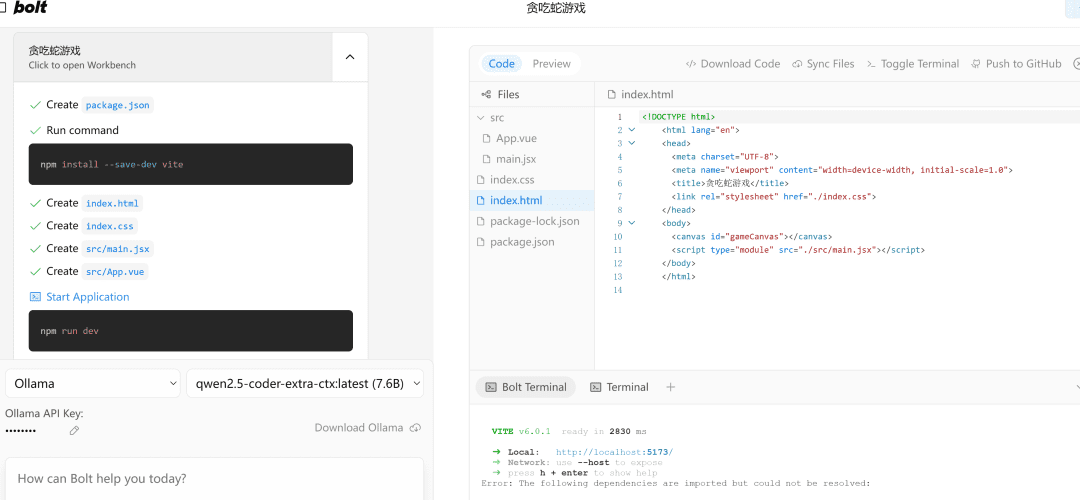
エラーが発生した場合は、そのエラーを投げかけてもう一度実行し、何も問題がなければ右辺のプレビューページが正常に開きます。
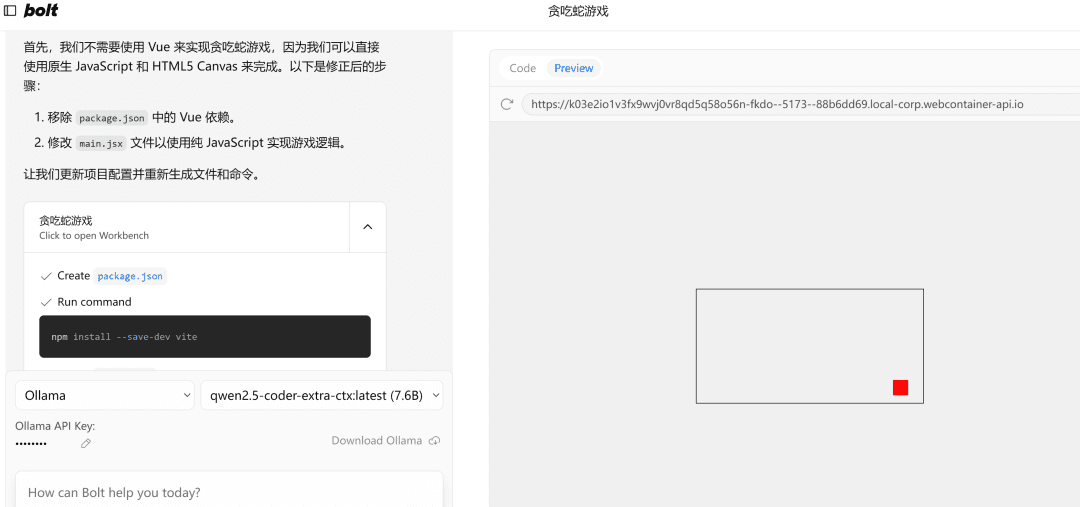
注:この例では7bの小さなモデルを使用しているので、必要であれば32bのモデルを使用してみてください。
最後に書く
この記事では、qwen2.5-codeモデルをローカルにデプロイし、AIプログラミングツールbolt.newをうまく動かす方法を紹介する。
フロントエンドのプロジェクトを開発するために使用することはまだ非常に強力ですが、もちろん、それをうまく使用するには、いくつかの基本的なフロントとバックエンドの概念を知って、2倍の効果があるでしょう。