450ドルという値段は、最初は高くは感じない。しかし、それが32Bの推論モデルをトレーニングするための全費用だとしたらどうだろう?
そう、2025年に近づくにつれ、推論モデルは開発しやすくなり、コストは以前には想像もできなかったレベルまで急速に低下している。
最近、カリフォルニア大学バークレー校のスカイ・コンピューティング研究所の研究チームであるノヴァスカイが、Sky-T1-32B-Previewをリリースした。興味深いことに、同チームは「Sky-T1-32B-Previewのトレーニング費用は450ドル以下であり、高レベルの推論能力を経済的かつ効率的に再現できることを示唆している」と述べている。

- プロジェクト・ホームページ:https://novasky-ai.github.io/posts/sky-t1/
- オープンソースのアドレス:https://huggingface.co/NovaSky-AI/Sky-T1-32B-Preview
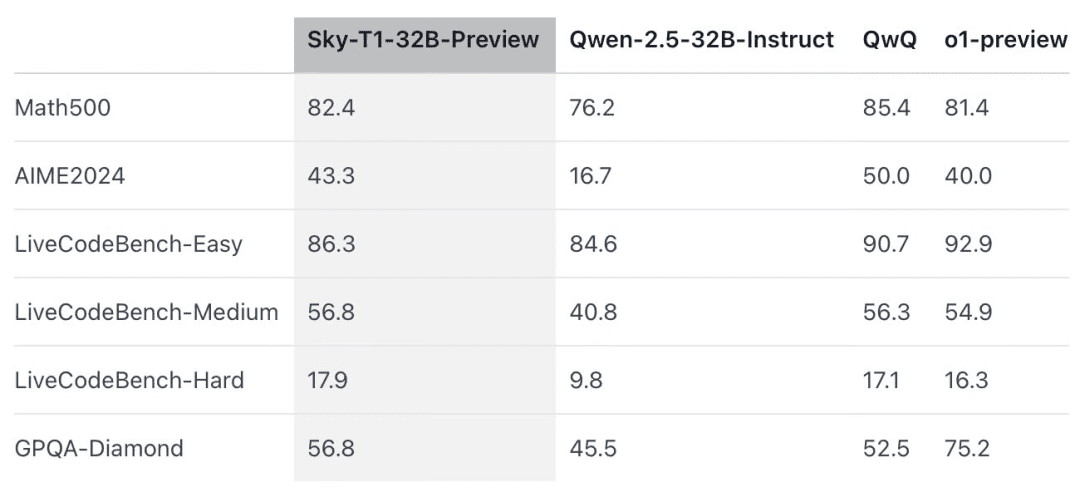
公式情報によると、この推論モデルは、いくつかの主要ベンチマークにおいて、以前のバージョンのOpenAI o1に匹敵した。
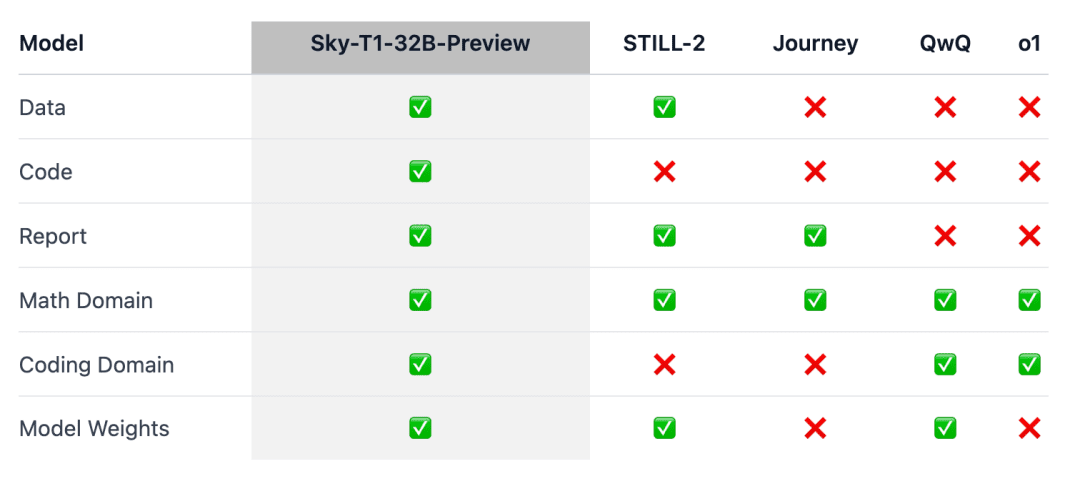
ポイントは、Sky-T1が真にオープンソースの推論モデルとして初めて登場したことである。
人々は「データ、コード、モデルの重み付けにおいて、なんと素晴らしい貢献だろう」と絶賛した。
少し前までは、同等の性能を持つモデルのトレーニングにかかる費用は、数百万ドルに上ることも少なくなかった。合成トレーニングデータや、他のモデルによって生成されたトレーニングデータによって、大幅なコスト削減が可能になった。
以前、AI企業であるWriter社が、ほぼ合成データのみで学習させたパルミラX 004を発表したが、その開発費はわずか70万ドルだった。
このプログラムを、3000ドル(スーパーコンピューターとしては安い)で、最大2000億のパラメーターを持つモデルを実行できるNvidia Project Digits AIスーパーコンピューターで実行することを想像してみてほしい。近い将来、1兆以下のパラメーターを持つモデルは、個人によってローカルで実行されるようになるだろう。
2025年のビッグモデル技術の進化は加速しており、それは本当に強い実感だ。
モデルの概要
推論o1と ジェミニ 2.0 フラッシュ思考のようなモデルは、長い思考の内部連鎖を生み出すことで、複雑なタスクを解決し、他の進歩をもたらした。しかし、技術的な詳細やモデルの重みは公開されていないため、学術的な取り組みやオープンソースコミュニティへの参加の障壁となっている。
一方、カリフォルニア大学バークレー校のNovaSkyチームは、ベースモデルとコマンドチューンドモデルの両方の推論能力を開発するために、さまざまな技術を模索している。
この作品「Sky-T1-32B-Preview」では、数学的な面だけでなく、同じモデルのコーディング面でも競争力のある推論性能を達成した。

この研究が "より広いコミュニティに利益をもたらす "ことを確実にするため、チームはすべての詳細(データ、コード、モデルの重みなど)をオープンソース化し、コミュニティが容易に複製・改良できるようにした:
- インフラ:データ構築、トレーニング、モデルの評価を単一のリポジトリで行う;
- データ:Sky-T1-32B-Previewのトレーニングに使用した17Kデータ;
- 技術的な詳細:テクニカルレポートとwandbログ;
- モデル・ウエイト:32B モデル・ウエイト:32B
技術的詳細
データ照合プロセス
学習データを生成するために、チームはo1-previewと同等の推論能力を持つオープンソースモデルであるQwQ-32B-Previewを使用した。チームは、推論が必要とされるさまざまな領域をカバーするようにデータミックスを整理し、データの質を向上させるために棄却サンプリング手順を使用した。
その後、Still-2に触発されたチームは、GPT-4o-miniを使用してQwQトレースを構造化バージョンに書き換え、データの質を向上させ、解析を簡素化した。
彼らは、解析が単純であることが推論モデルにとって特に有益であることを発見した。推論モデルは特定のフォーマットで応答するように訓練されており、その結果を解析するのは難しいことが多い。例えば、APPsデータセットでは、再フォーマットしなければ、コードは最後のコードブロックに書かれていると仮定するしかなく、QwQは約25%の精度しか達成できなかった。しかし、コードが途中に書かれている場合もあり、再フォーマット後は精度が90%以上に向上する。
サンプルを破棄する。データセットと一緒に提供された解法によって、QwQサンプルが正しくない場合、チームはそのサンプルを破棄する。数学的な問題の場合、チームは真実解との完全一致を実行する。コーディング問題については、チームはデータセットで提供されたユニットテストを実行する。チームの最終データは、APPsとTACOの5kのコーディングデータと、AIME、MATH、NuminaMATHデータセットのOlympiadsサブセットの10kの数学データから構成される。加えて、STILL-2から1kの科学とパズルのデータを保持した。
電車
研究チームは、この学習データを使って、推論機能を持たないオープンソースのモデルであるQwen2.5-32B-Instructを微調整した。モデルの学習には、3エポック、学習率1e-5、バッチサイズ96を使用した。モデルのトレーニングは、DeepSpeed Zero-3オフロード(Lambda Cloudによると価格は約450ドル)を使用し、8台のH100で19時間で完了した。チームはトレーニングにLlama-Factoryを使用した。
評価結果
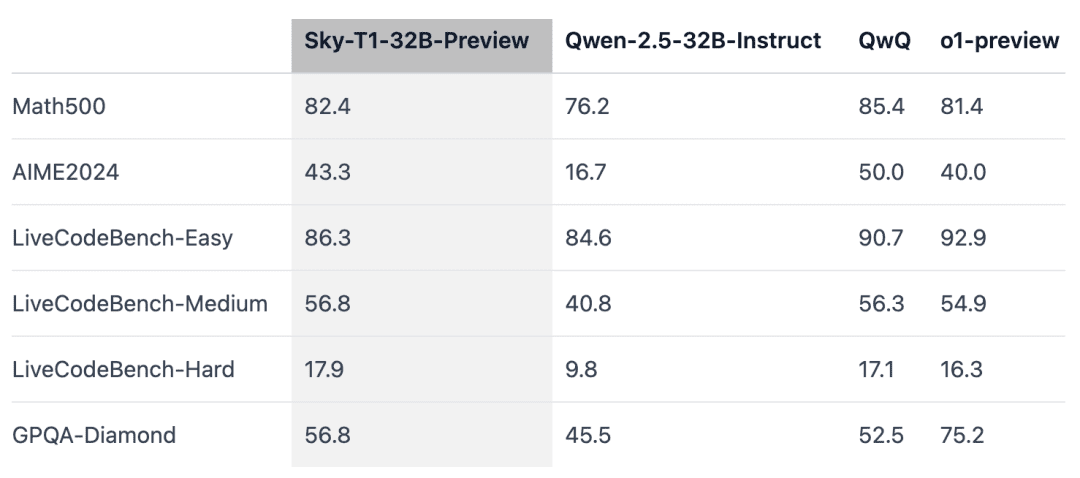
Sky-T1は、"競技レベル "の数学の課題であるMATH500では、以前のプレビュー版のo1を上回り、コーディング評価であるLiveCodeBenchのパズルのセットでもプレビュー版のo1を上回った。しかし、Sky-T1は、GPQA-Diamondのプレビュー版のo1には及ばない。GPQA-Diamondは、物理学、生物学、化学に関連する問題を含み、博士課程を修了した学生なら知っているはずの問題である。
しかし、OpenAIのo1 GAリリースは、o1のプレビュー版よりも強力であり、OpenAIは今後数週間のうちに、より高性能な推論モデルであるo3をリリースする予定である。
注目に値する新知見
モデルのサイズは重要だ。チームは当初、より小さなモデル(7Bと14B)でトレーニングを試みたが、ほとんど改善は見られなかった。例えば、Qwen2.5-14B-Coder-Instruct を APPs データセットでトレーニングしたところ、LiveCodeBench でのパフォーマンスが 42.6% から 46.3% へとわずかに向上しました。その有効性を制限している。
データのブレンドは重要だ。研究チームは当初、Numinaデータセット(STILL-2から提供された)から3~4Kの数学問題を用いて32Bモデルを訓練し、AIME24の精度は16.7%から43.3%へと大幅に向上した。しかし、APPsデータセットから生成されたプログラミングデータを訓練プロセスに組み込むと、AIME24の精度は36.7%まで低下した。この精度の低下は、数学とプログラミングのタスクで必要とされる推論方法が異なるためであると考えられる。
プログラミングの推論では通常、テスト入力のシミュレーションや、生成されたコードの内部実行など、論理的なステップが追加されるが、数学的な問題の推論はより単純で構造化される傾向がある。これらの違いに対処するため、研究チームは、NuminaMathデータセットから難易度の高い数学的問題を、TACOデータセットから複雑なプログラミング課題を学習データに追加した。このバランスの取れたデータの組み合わせにより、モデルは両領域で優れた性能を発揮し、AIME24で43.3%の精度を回復すると同時に、プログラミング能力も向上させた。
同時に、懐疑的な見方を示す研究者もいる:


皆さんはこれについてどう思いますか?コメント欄で自由に議論してください。
参考リンク:https://www.reddit.com/r/LocalLLaMA/comments/1hys13h/new_model_from_httpsnovaskyaigithubio/