はじめに
Crawl4AIは、大規模言語モデル(LLM)と人工知能(AI)アプリケーションのために設計されたオープンソースの非同期ウェブクローラツールです。Crawl4AIは、ウェブクローリングとデータ抽出プロセスを簡素化し、効率的なウェブクローリングをサポートし、JSON、クリーンHTML、MarkdownなどのLLMに適した出力フォーマットを提供します。
機能一覧
- 非同期アーキテクチャ:複数のウェブページの効率的な処理、高速なデータクローリング
- 複数の出力形式:JSON、HTML、Markdownをサポート
- マルチURLクロール:複数のウェブページを同時にクロールします。
- メディアタグ抽出:画像、音声、動画タグの抽出
- リンク抽出: すべての外部リンクと内部リンクを抽出
- メタデータ抽出:ページからのメタデータ抽出
- カスタム・フック:認証、リクエスト・ヘッダ、ページ修正のサポート
- ユーザーエージェントのカスタマイズ:ユーザーエージェントのカスタマイズ
- ページスクリーンショット:クロールページのスクリーンショット
- カスタムJavaScriptの実行:クロール前に複数のカスタムJavaScriptを実行する。
- プロキシのサポート:プライバシーとアクセスの強化
- セッション管理:複雑な複数ページのクローリングシナリオの処理
ヘルプの使用
設置プロセス
Crawl4AIは、様々な利用シーンに対応できる柔軟なインストールオプションを提供している。Pythonパッケージとしてインストールすることも、Dockerを使用することもできる。
pipによるインストール
- 基本インストール
pip install crawl4aiCrawl4AIの非同期バージョンがデフォルトでインストールされ、Playwrightを使ってウェブクローリングが行われる。
- Playwrightの手動インストール(必要な場合)
劇作家インストールまたは
python -m playwright install chromium
Dockerを使ったインストール
- Dockerイメージのプル
docker pull unclecode/crawl4ai - Dockerコンテナの実行
docker run -it unclecode/crawl4ai
使用ガイドライン
- 基本的な使い方
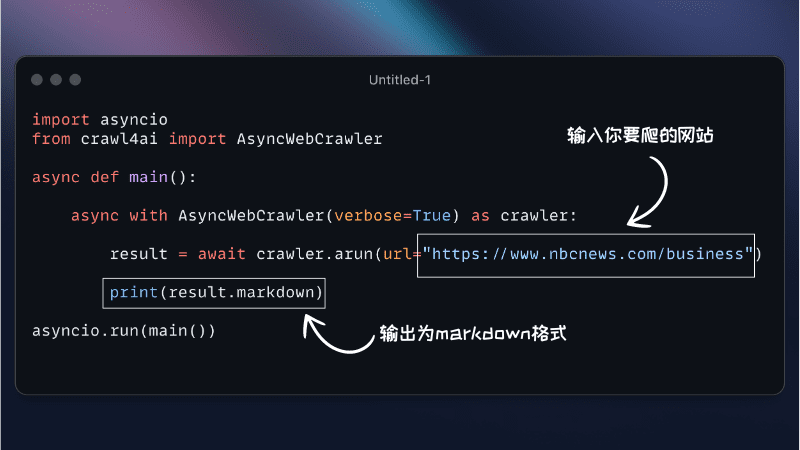
より クロール4アイ インポート 非同期ウェブクローラー クローラー = AsyncWebCrawler() results = crawler.crawl([)"https://example.com"]) プリント(結果) - カスタマイズされた設定
より クロール4アイ インポート 非同期ウェブクローラー クローラー = AsyncWebCrawler( ユーザーエージェント「CustomUserAgent", headers={"認可": 「ベアラー トークン"}, custom_js=["console.log('ハロー、ワールド!')"] ) results = crawler.crawl(["https://example.com"]) プリント(結果) - 特定のデータの抽出
より クロール4アイ インポート 非同期ウェブクローラー クローラー = AsyncWebCrawler() results = crawler.crawl([)"https://example.com"], extract_media=真extract_links=真) プリント(結果) - セッション管理
より クロール4アイ インポート 非同期ウェブクローラー クローラー = AsyncWebCrawler() session = crawler.create_session() session_results = session.crawl([)"https://example.com"]) プリント(セッション_結果)
Crawl4AIは、様々なウェブクローリングやデータクローリングのニーズに対応する豊富な機能と柔軟な設定オプションを提供しています。詳細なインストールガイドと使用ガイドにより、ユーザーは簡単に使い始めることができ、ツールの強力な機能をフルに活用することができます。