要旨
本稿では、Llama 3と呼ばれる新しい基本モデルのセットを紹介する。Llama 3は、多言語、コード記述、推論、ツール使用を本質的にサポートする言語モデルのコミュニティである。我々の最大のモデルは、4,050億個のパラメータと最大128,000個のトークンのコンテキストウィンドウを持つ密な変換器である。本稿では、Llama 3の一連の実証的評価を広範に行う。その結果、Llama 3は多くのタスクにおいてGPT-4などの主要な言語モデルに匹敵する品質を達成していることがわかった。本論文では、Llama 3を公開し、事前学習済みおよび事後学習済みの4,050億パラメータ言語モデルと、入出力セキュリティのためのLlama Guard 3モデルを提供する。また、本論文では、組み合わせアプローチにより、画像、ビデオ、音声の特徴をLlama 3に統合した実験結果も紹介する。このアプローチは、画像、ビデオ、音声認識タスクに対する最先端のアプローチと競合することが確認された。これらのモデルはまだ開発段階であるため、広く公開されていない。
全文ダウンロードpdf:

1 はじめに
基本モデルは、言語、視覚、音声、その他のモダリティの一般的なモデルであり、幅広いAIタスクをサポートするように設計されている。現代の多くのAIシステムの基礎となっている。
最新のベースモデルの開発は、大きく2つの段階に分けられる:
(1) 事前トレーニング段階。 モデルは、単語の予測やグラフの注釈生成といった単純なタスクを使って、大量のデータで学習される;
(2) トレーニング後の段階。 モデルは指示に従い、人間の好みに合わせ、特定の能力(コーディングや推論など)を向上させるように微調整される。
本稿では、Llama 3と呼ばれる言語ベースモデルの新しいセットを紹介する。 Llama 3 Herdファミリーは、多言語、エンコーディング、推論、ツール使用を本質的にサポートする。我々の最大のモデルは405Bのパラメータを持つ高密度な変換器であり、最大128Kのトークンのコンテキストウィンドウの情報を処理することができる。
表1は、群れの各メンバーのリストである。本稿で紹介するすべての結果は、ラマ3.1モデル(略してラマ3)に基づいている。
私たちは、質の高いベースモデルを開発するための3つの重要なツールは、データ、スケール、複雑性の管理であると考えています。私たちは、開発プロセスにおいて、これら3つの分野を最適化するよう努めます:
- データ 事前訓練と事後訓練で使用したデータの量と質は、以前のバージョンのLlamaに比べて改善された(Touvron et al.事前学習データのより慎重な前処理とキュレーションパイプラインの開発、およびより厳格な品質保証とフィルタリングの開発。Llama 3は約15Tの多言語トークンのコーパスで事前学習され、Llama 2は1.8Tのトークンで事前学習された。
- スコープ 私たちは、以前のLlamaモデルよりも大きなモデルをトレーニングした。25 これはLlama 2の最大バージョンの50倍近くである。具体的には、15.6Tのテキスト・トークンに405Bの訓練可能なパラメータを持つフラッグシップ・モデルを事前訓練した。予想通り

- 複雑さを管理する。 我々は、モデル開発プロセスのスケーラビリティを最大化することを目的とした設計上の選択を行った。例えば、我々は、トレーニングの安定性を最大化するために、エキスパートハイブリッドモデル(Shazeer et al.同様に、我々は、より複雑な強化学習アルゴリズム(Ouyang et al., 2022; Schulman et al., 2017)ではなく、教師あり微調整(SFT)、拒絶サンプリング(RS)、直接選好最適化(DPO; Rafailov et al. (2023))に基づく比較的単純なポストプロセッサを採用した。スケールするのが難しい。
私たちの研究の成果は、ラマ3:8B、70B、405Bのパラメータを持つ3言語多言語である。1言語モデルの母集団。我々はLlama 3の性能を、幅広い言語理解タスクをカバーする多数のベンチマークデータセットで評価した。さらに、Llama 3と競合モデルを比較する手動評価も広範に実施しました。表2は、主要なベンチマークテストにおける主要モデルLlama 3の性能の概要を示しています。我々の実験的評価から、我々のフラッグシップ・モデルは、GPT-4(OpenAI、2023a)などの主要言語モデルと同等であり、様々なタスクにおいて最先端に近いことがわかります。また、Llama 3は、前モデル(Touvron et al., 2023b)よりも、有用性と無害性のバランスが取れている。ラマ3の安全性についてはセクション5.4で詳しく分析する。
私たちは、Llama 3 Community Licenceの更新版のもと、3つのLlama 3モデルすべてを一般に公開しています。https://llama.meta.com。これには、私たちの405Bパラメトリック言語モデルの訓練済みおよび後処理済みバージョンと、入力のセキュリティのためのLlama Guardモデルの新バージョン(Inan et al.を追加した。私たちは、フラッグシップ・モデルの一般公開が、研究コミュニティにおける技術革新の波を刺激し、人工知能(AGI)の責任ある発展に向けた進歩を加速させることを期待している。
多言語:これは、モデルが複数の言語のテキストを理解し、生成する能力を指す。
ラマ3の開発中、画像認識、ビデオ認識、音声理解を可能にするマルチモーダル拡張モデルも開発した。これらのモデルはまだ活発に開発中であり、リリースには至っていない。本稿では、言語モデリングの結果に加え、これらのマルチモーダルモデルを使った初期実験の結果も紹介する。
Llama 3 8Bと70Bは多言語データで事前学習されたが、当時は主に英語に使われていた。

2 一般
Llama 3モデルのアーキテクチャを図1に示す。Llama 3言語モデルの開発は、主に2つのフェーズに分かれています:
- 言語モデルの事前学習。我々はまず、大規模な多言語テキストコーパスを個別のトークンに変換し、次のトークン予測のために、得られたデータで大規模言語モデル(LLM)を事前学習する。LLMの事前学習段階では、モデルは言語の構造を学習し、「読む」テキストから世界に関する大量の知識を獲得する。これを効率的に行うため、事前学習は大規模に行われる。15.6T個のトークンを持つモデルに対して、8K個のトークンのコンテキストウィンドウを使い、405B個のパラメータを持つモデルを事前学習した。この標準的な事前学習フェーズに続いて、サポートされるコンテキストウィンドウを128Kトークンに増やす継続的な事前学習フェーズが行われる。詳細はセクション3を参照のこと。
- モデル後のトレーニング事前に訓練された言語モデルは、言語を豊富に理解しているが、まだ指示に従ったり、我々が期待するアシスタントのように振る舞ったりはしていない。我々は、教師あり微調整(SFT)と直接プリファレンス最適化(DPO; Rafailov et al.このポストトレーニングフェーズでは、ツールの使用状況などの新機能も統合し、コーディングや推論などの分野で大幅な改善を確認した。詳細はセクション4を参照。最後に、セキュリティ緩和策もポストトレーニングフェーズでモデルに統合され、その 詳細はセクション5.4で説明する。生成されたモデルは機能性に富んでいる。少なくとも8つの言語の質問に答えることができ、高品質なコードを書くことができ、複雑な推論問題を解くことができ、すぐに使えるツールやゼロサンプルで使えるツールを使うことができる。
また、複合的なアプローチにより、ラマ3に画像、ビデオ、音声機能を追加する実験も行った。我々が調査したアプローチは、図28に示す3つの追加フェーズで構成されている:

- マルチモーダル・エンコーダのプリトレーニング。画像と音声の別々のエンコーダを訓練する。画像エンコーダーは多数の画像とテキストのペアで学習する。これにより、視覚コンテンツとその自然言語記述の関係を学習することができる。我々の音声エンコーダは、音声入力の一部をマスクし、離散的なマーカー表現を通してマスクされた部分を再構成しようとする自己教師ありの方法を用いる。このようにして、モデルは音声信号の構造を学習する。画像エンコーダの詳細についてはセクション7を、音声エンコーダの詳細についてはセクション8を参照のこと。
- 視覚アダプターのトレーニング。我々は、事前に訓練された画像エンコーダーと事前に訓練された言語モデルを統合するアダプターを訓練する。アダプターは、画像エンコーダーの表現を言語モデルに送り込む一連のクロスアテンションレイヤーで構成される。アダプタはテキストと画像のペアで学習され、画像表現と言語表現を整合させる。アダプタの学習中、画像エンコーダのパラメータも更新するが、言語モデルのパラメータは意図的に更新しない。また、画像アダプタの上にビデオアダプタを学習し、ビデオとテキストのペアデータを使用する。これにより、モデルはフレーム間の情報を集約することができる。詳細はセクション7を参照。
- 最後に、音声符号化をトークン化された表現に変換するアダプタを介して、音声エンコーダをモデルに統合し、微調整された言語モデルに直接入力できるようにする。教師付き微調整フェーズでは、高品質の音声理解を達成するために、アダプタとエンコーダのパラメータが共同で更新される。音声アダプターの学習中に言語モデルを変更することはありません。また、音声合成システムも統合している。詳細はセクション8を参照。
私たちのマルチモーダル実験により、画像や動画の内容を認識し、音声インターフェースによる対話をサポートするモデルが開発されました。これらのモデルはまだ開発中であり、リリースには至っていない。
3 事前トレーニング
言語モデルの事前学習には次のような側面がある:
(1) 大規模な学習コーパスの収集とフィルタリング;
(2) モデルのサイズを決定するためのモデル・アーキテクチャと対応するスケーリング則の開発;
(3) 効率的な大規模事前学習技術の開発;
(4) 事前トレーニングプログラムの開発。以下、それぞれの構成要素について説明する。
3.1 事前学習データ
我々は、2023年末までの知識を含む様々なデータソースから言語モデルの事前学習データセットを作成した。高品質なラベリングを得るために、各データソースに複数の重複排除手法とデータクリーニング機構を適用した。個人を特定できる情報(PII)を大量に含むドメインや、アダルトコンテンツを含むことが知られているドメインを削除した。
3.11 ウェブ・データ・クレンジング
私たちが利用するデータのほとんどはウェブからのもので、以下に私たちのクリーニング・プロセスについて説明する。
PIIとセキュリティフィルタリング。 その他の対策として、安全でないコンテンツや大量の個人情報を含む可能性のあるウェブサイト、さまざまなMetaセキュリティ基準で有害と分類されているドメイン、アダルトコンテンツを含むことが知られているドメインからデータを削除するように設計されたフィルタを導入しています。
テキスト抽出とクレンジング。 私たちは、高品質で多様なテキストを抽出するために生のHTMLコンテンツを処理し、この目的のために切り詰めのないウェブ文書を使用しています。そのために、HTMLコンテンツを抽出し、テンプレート除去の精度とコンテンツ想起を最適化するカスタムパーサーを構築しました。手動評価によってパーサーの品質を評価し、類似記事のコンテンツ用に最適化された一般的なサードパーティのHTMLパーサーと比較したところ、良好なパフォーマンスを示すことがわかりました。数学とコードのコンテンツを含むHTMLページでは、そのコンテンツの構造を保持するように注意しています。数学的コンテンツは通常、alt属性で数学も提供されるプリレンダリング画像として表現されるため、画像のalt属性テキストは保持します。
Markdownは、プレーンテキストに比べて、主にウェブデータでトレーニングされたモデルのパフォーマンスにとって有害であることがわかったので、すべてのMarkdownタグを削除した。
脱力。 URL、文書、行レベルで重複排除を複数回行う:
- URLレベルでの重複排除。 データセット全体に対してURLレベルでの重複排除を行う。URLに対応する各ページについて、最新版を保持する。
- 文書レベルの重複排除。 データセット全体に対してグローバルなMinHash(Broder, 1997)重複排除を行い、重複に近い文書を削除する。
- 行レベルの重複排除。 ccNet(Wenzek他、2019)と同様にラディカルレベルの重複排除を行う。3000万件の文書を含む各グループで6回以上出現する行を削除する。
手作業による定性的な分析によると、行レベルの重複排除は、様々なサイトから残存する定型的なコンテンツ(ナビゲーションメニューやクッキーの警告など)だけでなく、頻繁に使用される高品質なテキストも除去することが示唆されているが、実証的な評価では大幅な改善が見られた。
ヒューリスティック・フィルタリング。 ヒューリスティックは、さらに低品質な文書、外れ値、繰り返しが多すぎる文書を削除するために開発された。ヒューリスティックの例をいくつか挙げる:
- 重複n-タプルカバレッジ(Rae et al., 2021)を使用して、重複コンテンツ(ログやエラーメッセージなど)からなる行を除去する。これらの行は非常に長く、一意である可能性があるため、重複除去ではフィルタリングできない。
- ダーティーワード」カウント(Raffel et al.
- トークン分布のカルバック・ライブラー散らばりを使って、訓練コーパスの分布に比べて異常なトークンを多く含む文書をフィルタリングする。
モデルベースの品質フィルタリング。
さらに、高品質なラベルを選択するために、様々なモデルベースの品質分類器の使用を試みた。これらの方法には以下が含まれる:
- 与えられたテキストがウィキペディアに引用されるかどうかを認識するように訓練されたfasttext(Joulin et al, 2017)のような高速分類器を使用する(Touvron et al, 2023a)。
- より計算量の多いRobertaモデル分類器(Liu et al.
Llama 2ベースの品質分類器を訓練するために、品質要件を記述したクリーンなウェブ文書のセットを作成し、文書がこれらの要件を満たしているかどうかを判断するためにLlama 2のチャットモデルを指示した。 効率化のため、DistilRoberta(Sanh et al. 様々な品質フィルタリング構成の有効性を実験的に評価する。
コードと推論データ。
DeepSeek-AI(2024)らと同様に、コードを含むウェブページと数学関連のウェブページを抽出するためのドメイン固有のパイプラインを構築した。具体的には、コード分類と推論分類の両方が、Llama 2の注釈付きウェブデータを使用して訓練されたDistilledRobertaモデルである。 このような分類を行うことで、数学的推論、STEM領域における推論、自然言語に埋め込まれたコードを含むウェブページを抽出することができる。コードと数学のトークン分布は自然言語とは大きく異なるため、これらのパイプラインはドメイン固有のHTML抽出、カスタムテキスト特徴、フィルタリングのためのヒューリスティックを実装している。
多言語データ。
上記の英語処理パイプラインと同様に、個人を特定できる情報(PII)や安全でないコンテンツを含む可能性のあるウェブサイトデータを削除するフィルターを実装しています。私たちの多言語テキスト処理パイプラインには、次のようなユニークな特徴があります:
- 高速テキストベースの言語認識モデルを用いて、文書を176の言語に分類する。
- 各言語について、文書レベルと行レベルの重複排除を行う。
- 言語固有のヒューリスティックとモデルベースのフィルターを適用し、低品質な文書を除去する。
さらに、多言語Llama 2ベースの分類器を用いて多言語文書の品質をランク付けし、高品質なコンテンツが優先されるようにする。事前学習で使用する多言語トークンの数は実験的に決定され、モデルの性能は英語と多言語のベンチマークテストでバランスされる。
3.12 データ・ミックスの決定
为了获得高质量语言模型,必须谨慎确定预训练数据混合中不同数据源的比例。我们主要利用知识分类和尺度定律实验来确定这一数据混合。
知识分类。我们开发了一个分类器,用于对网页数据中包含的信息类型进行分类,以便更有效地确定数据组合。我们使用这个分类器对网页上过度代表的数据类别(例如艺术和娱乐)进行下采样。
为了确定最佳数据混合方案。我们进行规模定律实验,其中我们将多个小型模型训练于特定数据混合集上,并利用其预测大型模型在该混合集上的性能(参见第 3.2.1 节)。我们多次重复此过程,针对不同的数据混合集选择新的候选数据混合集。随后,我们在该候选数据混合集上训练一个更大的模型,并在多个关键基准测试上评估该模型的性能。
数据混合摘要。我们的最终数据混合包含大约 50% 的通用知识标记、25% 的数学和推理标记、17% 的代码标记以及 8% 的多语言标记。
3.13 アニーリングデータ
実証結果は、少量の高品質なコードと数学データ(セクション3.4.3参照)に対するアニーリングが、主要なベンチマークテストにおける事前学習済みモデルの性能を向上させることを示している。Liら(2024b)の研究と同様に、我々は選択したドメインからの高品質データを含む混合データセットを用いてアニーリングを行う。我々のアニールされたデータには、一般的に使用されるベンチマークテストのトレーニングセットは含まれていない。これにより、Llama 3の真の少数サンプル学習能力とドメイン外汎化能力を評価することができる。
OpenAI(2023a)に従い、GSM8k(Cobbe et al.,2021)とMATH(Hendrycks et al.,2021b)のトレーニングセットでアニーリングの効果を評価しました。しかし、405Bモデルではこの改善はごくわずかであり、我々のフラッグシップモデルが強力な文脈学習と推論能力を持ち、頑健な性能を達成するためにドメイン固有の訓練サンプルを必要としないことを示唆している。
アニーリングを使用してデータの品質を評価する。Blakeneyら(2024)と同様に、我々はアニーリングによって小さなドメイン固有のデータセットの価値を判断できることを発見した。我々は、50%で学習させたLlama 3 8Bモデルの学習率を、400億トークンに対して0になるように線形アニーリングすることで、これらのデータセットの価値を測定する。これらの実験では、30%の重みを新しいデータセットに割り当て、残りの70%の重みをデフォルトのデータミックスに割り当てた。新しいデータソースの評価には、それぞれの小さなデータセットに対してスケール則実験を行うよりも、アニーリングを用いる方が効率的である。
3.2 モデル・アーキテクチャ
Llama 3は標準的な密なTransformerアーキテクチャ(Vaswani et al.)そのモデル・アーキテクチャは、LlamaとLlama 2(Touvron et al.
いくつか細かい修正を加えた:
- 我々はGrouped Query Attention (GQA; Ainslie et al. (2023))を使用し、8つのキーバリューヘッダーを使用することで、推論速度を上げ、デコード時のキーバリューキャッシュのサイズを小さくしている。
- アテンションマスクを使用し、シーケンスの異なる文書間での自己アテンションメカニズムを防ぐ。この変更は、標準的な事前学習では影響は限定的であるが、非常に長いシーケンスの連続的な事前学習では重要であることがわかった。
- 私たちは128Kのトークンの語彙を使用しています。私たちのトークン化された語彙は、tiktoken3語彙の100Kトークンと、英語以外の言語をよりよくサポートするための28K追加トークンを組み合わせたものです。Llama 2の語彙と比較して、私たちの新しい語彙は英語データサンプルの圧縮率を3.17文字/トークンから3.94文字/トークンへと向上させました。これにより、モデルは同じ学習計算量でより多くのテキストを「読む」ことができます。また、特定の非英語言語から28Kトークンを追加することで、英語のトークン化には影響がないものの、圧縮とダウンストリームのパフォーマンスが向上することもわかりました。
- これにより、より長いコンテキストをより適切にサポートできるようになる。Xiongら(2023)は、この値がコンテキストの長さが32,768まで有効であることを示している。

Llama 3 405Bは、126のレイヤー、16,384のマーカー表現次元、128のアテンション・ヘッドを持つアーキテクチャーを使用している。詳細については、表3を参照のこと。この結果、モデル・サイズは、我々のデータと3.8×10^25 FLOPsのトレーニング予算に基づいて、ほぼ計算上最適となる。
3.2.1 規模の法則
スケーリング法則(Hoffmann et al., 2022; Kaplan et al., 2020)を用いて、事前トレーニングの計算予算からフラッグシップモデルの最適なサイズを決定した。最適なモデルサイズを決定することに加え、ダウンストリームベンチマークタスクにおけるフラッグシップモデルの性能を予測することは、以下の理由により重要な課題となる:
- 既存のスケーリング則は通常、特定のベンチマーク性能ではなく、次のマーク予測損失のみを予測する。
- スケーリング・ローは、少ない計算予算での事前学習に基づいて開発されるため、ノイズが多く信頼性に欠ける可能性がある(Wei et al.)
これらの課題に対処するため、下流のベンチマーク性能を正確に予測するスケーリング則を開発する2段階のアプローチを実施した:
- まず、事前学習FLOPsと、下流タスクにおける最良モデルの負の対数尤度の計算との相関を確立する。
- 次に、スケーリング法則モデルと、より高い計算能力を持つFLOPsを使用して事前に訓練された古いモデルを使用して、下流タスクの負の対数尤度とタスクの精度を相関させます。このステップでは、Llama 2ファミリーのモデルのみを使用します。
このアプローチにより、事前訓練された特定のFLOP数に基づいて、(計算上最適なモデルの)下流のタスク性能を予測することができる。同様のアプローチで事前学習データの組み合わせを選択する(セクション3.4参照)。
スケーリング 法実験。具体的には、6×10^18FLOPsから10^22FLOPsの間の計算バジェットを使用してモデルを事前学習することによりスケーリング則を構築した。各計算バジェットにおいて、40Mから16Bのパラメータサイズのモデルを事前学習し、各計算バジェットにおいてモデルサイズの何分の一かを使用した。これらのトレーニング実行では、コサイン学習率スケジューリングと2,000トレーニングステップ内の線形ウォームアップを使用した。ピーク学習率はモデルサイズに応じて2×10^-4から4×10^-4の間に設定した。コサイン減衰はピーク値の0.1倍に設定した。各ステップのウェイト減衰は、そのステップの学習率の0.1倍に設定した。各計算サイズに対して、250Kから4Mの範囲で固定のバッチサイズを使用した。

これらの実験により、図2のIsoFLOPs曲線が得られた。これらの曲線における損失は、別々の検証セットで測定された。測定された損失値を2次の多項式でフィッティングし、各放物線の最小値を求める。放物線の最小値を、対応する事前学習された計算バジェットの下での計算上最適なモデルと呼ぶ。
このようにして特定された計算最適モデルを用いて、与えられた計算予算に対する最適な訓練トークン数を予測する。この目的のために、計算予算Cと最適な訓練トークン数N (C)の間にべき乗の関係を仮定する:
N (C) = AC α .
図 2 のデータを使用して A と α をフィッ トしたところ、(α, A) = (0.53, 0.29) が得られた。得られたスケーリング則を 3.8 × 10 25 FLOPs に外挿すると、402B のパラメー タを持つモデルをトレーニングし、16.55T トークンを使用することが示唆される。
重要な観察点は、IsoFLOPs曲線が、計算予算が増加するにつれて、最小値付近でより平坦になることである。これは、フラッグシップモデルの性能が、モデルサイズとトレーニングマーカーのトレードオフの小さな変動に対して比較的安定していることを意味しています。この観察に基づき、我々は最終的に405Bパラメータを含むフラッグシップモデルを訓練することにしました。
下流タスクのパフォーマンスを予測する。生成された計算上最適なモデルを用いて、ベンチマークデータセットにおける主要なLlama 3モデルの性能を予測する。まず、ベンチマークにおける正解の(正規化された)負の対数尤度と学習FLOPsを線形に関連付ける。この分析では、上記の混合データに対して10^22 FLOPsまで訓練したスケーリング則モデルのみを使用した。次に、スケーリング法則モデルと、Llama 2 データミックスとタグ設定器を使用して学習させた Llama 2 モデルを使用して、対数尤度と精度の間に S 字型の関係を確立した。(図 4 に、ARC チャレンジ・ベンチマークにおけるこの実験の結果を示す)。この2段階のスケーリング法則予測(4桁にわたって外挿)は非常に正確であることがわかります。
3.3 インフラ、拡大、効率性
Llama 3 405Bの事前トレーニングをサポートするハードウェアとインフラについて説明し、トレーニング効率を向上させるためのいくつかの最適化について述べる。
3.3.1 トレーニング・インフラ
Llama 1とLlama 2のモデルは、MetaのAI研究スーパークラスターで学習された(Lee and Sengupta, 2022)。さらにスケールアップするにつれて、Llama 3のトレーニングはMetaのプロダクションクラスタに移行された(Lee et al.)このセットアップにより、プロダクションレベルの信頼性が最適化された。

コンピューティング・リソース Llama 3 405Bは、Meta社のGrand Teton AIサーバープラットフォーム(Matt Bowman, 2022)を使用して、最大16,000個のH100 GPU、それぞれTDP700W、80GB HBM3で動作するGPUをトレーニングします。各サーバーには8つのGPUと2つのCPUが搭載されており、サーバー内では8つのGPUがNVLinkで接続されている。トレーニングジョブは、MetaのグローバルスケールのトレーニングスケジューラーであるMAST(Choudhury et al.
ストレージ: Metaの汎用分散ファイルシステムであるTectonic(Pan et al., 2021)は、Llama 3事前訓練(Battey and Gupta, 2024)のストレージアーキテクチャの構築に使用された。240ペタバイトのストレージスペースを提供し、2TB/秒の持続可能なスループットと7TB/秒のピークスループットをサポートする7,500台のSSD搭載サーバーで構成されています。主な課題は、短時間でストレージファブリックを飽和させるような、非常にバースト性の高いチェックポイント書き込みをサポートすることです。チェックポイントは、リカバリーとデバッグのために、GPUごとに1MBから4GBのモデル状態を保存します。私たちの目標は、チェックポイント中のGPU休止時間を最小化し、チェックポイントの頻度を上げてリカバリ後に失われる作業量を減らすことです。
ネットワーキング: Llama 3 405Bは、Arista 7800およびMinipack2 Open Compute Project(OCP)ラックスイッチをベースとしたRDMA over Converged Ethernet(RoCE)アーキテクチャを使用しています。Llama 3シリーズの小型モデルは、Nvidia Quantum2インフィニバンドネットワークを使用してトレーニングされました。RoCEクラスタとInfinibandクラスタはどちらも、GPU間の400Gbpsリンク接続を利用しています。これらのクラスタの基礎となるネットワーク技術に違いがあるにもかかわらず、これらの大規模なトレーニング作業負荷を処理するために、同等のパフォーマンスを提供するように両者をチューニングしました。RoCEネットワークについては、その設計の完全なオーナーシップを得るにしたがって、さらに詳しく説明する予定です。
- ネットワーク・トポロジー: 我々のRoCEベースのAIクラスターには、3層のClosネットワーク(Lee et al.、2024)を介して接続された24,000個のGPU(脚注5)が含まれている。最下層では、各ラックに16個のGPUがホストされ、2台のサーバーに割り当てられ、1台のMinipack2トップ・オブ・ラック(ToR)スイッチで接続されています。中間層では、これらのラックのうち192台がクラスタースイッチを介して接続され、完全な双方向帯域幅を持つ3,072個のGPUからなるPodを形成し、オーバーサブスクリプションが発生しないようにしています。最上位層では、同じデータセンタービル内の8つのPodがアグリゲーションスイッチを介して接続され、24,000 GPUのクラスタを形成します。ただし、完全な双方向帯域幅を維持する代わりに、アグリゲーション層のネットワーク接続は1:7のオーバーサブスクリプション率を持ちます。我々のモデル並列アプローチ(セクション 3.3.2 参照)とトレーニングジョブスケジューラ(Choudhury et al.
- ロードバランシング: 大規模な言語モデルの学習は、Equal Cost Multipath (ECMP)ルーティングのような従来の方法では、利用可能なすべてのネットワークパスでバランスをとることが困難な、大量のネットワークトラフィックを生成する。この課題に対処するため、2つの手法を採用しています。第一に、当社のアグリゲート・ライブラリでは、1つのGPUではなく2つのGPU間で16のネットワーク・フローを作成することで、フローあたりのトラフィック量を削減し、負荷分散により多くのフローを提供します。第二に、RoCEヘッダー・パケットの他のフィールドをハッシュ化することで、異なるネットワーク・パス間でこれら16のフローを効果的にバランスさせる拡張ECMP(E-ECMP)プロトコルを採用しています。

- 輻輳制御: バックボーンネットワークにディープバッファスイッチ(Gangidi et al.これにより、トレーニングでよく見られる、低速サーバーによる持続的な輻輳やネットワークのバックプレッシャーの影響を抑えることができます。最後に、E-ECMPによる優れた負荷分散は、輻輳の可能性を大幅に低減します。これらの最適化により、DCQCN(Data Center Quantified Congestion Notification)のような従来の輻輳制御手法を必要とすることなく、24,000個のGPUからなるクラスタの実行に成功しました。
3.3.2 モデルのスケールアップにおける並列性
最大のモデルのトレーニングをスケールアップするために、4D並列(4つの異なる並列アプローチを組み合わせたスキーム)を使用してモデルをシャード化しました。このアプローチは、多くのGPUに計算を効果的に分散させ、各GPUのモデルパラメータ、オプティマイザーの状態、勾配、活性化値がHBM内に収まるようにします。我々の4D並列実装(et al. (2020); Ren et al. (2021); Zhao et al. (2023b)に示されている)は、モデル、オプティマイザ、勾配をスライスする一方で、データ並列を実装し、複数のGPUで並列にデータを処理し、各トレーニングステップ後に同期させます。Llama 3では、FSDPを使用してオプティマイザーの状態と勾配をスライスしますが、モデルのスライスでは、リバースパス中の追加のフルコレクション通信を避けるため、フォワード計算後に再スライスは行いません。
GPUの利用。表4に示す構成によると、8K GPU、DP=64の場合の43%と比較して、16K GPU、DP=128の場合の41%へのMFUの低下は、トレーニング中にグローバルマーカーの数を一定に保つために、各DPグループのバッチサイズを小さくする必要があるためです。41%は、トレーニング中にグローバルトークンの数を一定に保つために、各DPグループのバッチサイズを小さくする必要があるためです。
並行改良を合理化する。私たちは、既存の実装でいくつかの課題に遭遇した:
- バッチサイズの制限。現在の実装では、GPUごとにサポートされるバッチサイズに制限があり、パイプラインステージ数で割り切れる必要があります。図6の例では、深さ優先スケジューリング(DFS)(Narayanan et al.しかし、事前学習では通常、バッチサイジングに柔軟性が要求される。
- メモリーのバランスが悪い。既存のパイプライン並列実装では、リソース消費のバランスが悪い。第1段階では、マイクロバッチの埋め込みとウォームアップのために、より多くのメモリを消費する。
- 計算のバランスが悪い。 モデルの最終層の後、出力と損失を計算する必要があり、このフェーズが実行レイテンシのボトルネックとなる。ここで,Di は i 番目の並列次元のインデックスです.この例では、GPU0[TP0, CP0, PP0, DP0]とGPU1[TP1, CP0, PP0, DP0]は同じTPグループ、GPU0とGPU2は同じCPグループ、GPU0とGPU4は同じPPグループ、GPU0とGPU8は同じDPグループです。

これらの問題に対処するため、図6に示すように、パイプラインスケジューリングアプローチを修正し、Nを柔軟に設定できるようにした。この場合、N=5であり、各バッチで実行するマイクロバッチ数を任意に設定できる。 これによって私たちは次のことが可能になる:
(1) バッチサイズに制限がある場合は、ステージ数より少ないマイクロバッチを実行する。
(2)ピアツーピア通信を隠すためにマイクロバッチの実行を増やし、深さ優先スケジューリング(DFS)と幅優先スケジューリング(BFS)の間で最適な通信効率とメモリ効率を見つける。パイプラインのバランスをとるために、最初のステージと最後のステージからそれぞれ1つのTransformerレイヤーを減らします。つまり、初段の最初のモデルブロックには埋め込み層しかなく、最終段の最後のモデルブロックには出力射影と損失計算しかない。
パイプラインのバブルを減らすために、V個のパイプラインステージを持つパイプライン階層上でインターリーブスケジューリングアプローチ(Narayanan et al, 2021)を使用する。 全体のパイプラインバブル比は PP-1 V * M 。さらに、非同期ピアツーピア通信を採用することで、特にドキュメントマスクが計算の不均衡をもたらす場合に、学習を大幅に高速化する。TORCH_NCCL_AVOID_RECORD_STREAMSを有効にして、非同期ピアツーピア通信によるメモリ使用量を削減する。最後に、メモリコストを削減するために、詳細なメモリ割り当て分析に基づいて、各パイプラインステージの入力テンソルや出力テンソルを含む、将来の計算に使用されないテンソルを積極的に解放します。**これらの最適化により、活性化チェックポイントを使用することなく、8Kテンソルを実行することができます。 トークン ラマ3の事前トレーニングのためのシークエンス。
長いシーケンスにはコンテキスト並列化が使われる。 コンテキスト並列化(CP)を活用し、Llama3のコンテキスト長をスケーリングする際のメモリ効率を改善し、128K長までの非常に長いシーケンスでの学習を可能にする。具体的には、入力シーケンスを2×CPブロックに分割し、各CPレベルが2つのブロックを受け取るようにする。第i CPレベルは第iブロックと(2×CP -1 -i)ブロックを受け取る。
リング構造で通信と計算をオーバーラップさせる既存のCP実装(Liu et al., 2023a)とは異なり、我々のCP実装は、まずキー・バリュー(K, V)テンソルをグローバルに集約し、次にローカルなクエリー(Q)テンソルのブロックの注意出力を計算する、オールギャザーベースのアプローチを採用している。オールギャザーの通信レイテンシはクリティカルパス上にあるが、我々は2つの主な理由からこのアプローチを採用している:
(1)オールギャザーベースのCPアテンションにおいて、ドキュメントマスクのような異なるタイプのアテンションマスクをサポートすることがより簡単で柔軟である;
(2)GQAの使用により、通信のKとVテンソルはQテンソルよりはるかに小さいので、露出されたオールギャザーの待ち時間は小さい(Ainslie et al., 2023)。その結果、注目計算の時間複雑度は、全集合のそれよりも一桁大きく(O(S²)対O(S)、ここでSは完全因果マスクのシーケンスの長さを表す)、全集合のオーバーヘッドを無視できるものにする。

ネットワークを意識した並列化コンフィギュレーション。並列化の次元[TP, CP, PP, DP]の順序は、ネットワーク通信に最適化されている。最も内側の並列化レイヤは、最も高いネットワーク帯域幅と最も低いレイテンシを必要とするため、通常は同一サーバ内に限定される。並列化の一番外側のレイヤは,マルチホップ・ネットワークにまたがる可能性があり,より高いネットワーク遅延に耐えられる必要がある.DP(すなわち、FSDP)は、スライシングモデルの重みを非同期にプリフェッチし、勾配を低減することで、より長いネットワーク遅延を許容できるため、並列化の最外層となる。GPUメモリのオーバフローを回避しつつ、通信オーバヘッドを最小化する最適な並列化構成を決定することは難しい課題です。我々は、様々な並列化構成を検討し、全体的なトレーニング性能を予測し、メモリギャップを効率的に特定するのに役立つ、メモリ消費量推定ツールと性能予測ツールを開発した。
数値的安定性。異なる並列設定間の訓練損失を比較することで、訓練の安定性に影響するいくつかの数値的問題を修正する。トレーニングの収束を保証するため、複数のマイクロバッチの逆計算時にFP32勾配蓄積を使用し、FSDPのデータ並列ワーカー間でFP32を使用して勾配を削減する。ビジュアルコーダーの出力など、順方向計算で複数回使用される中間テンソルについては、逆方向勾配もFP32で累積する。
3.3.3 集団的コミュニケーション
Llama3の集団通信ライブラリは、NvidiaのNCCLライブラリのブランチであるNCCLXをベースにしている。 NCCLXは、特に高レイテンシのネットワークにおいて、NCCLの性能を大幅に向上させる。並列次元の順序は[TP、CP、PP、DP]であり、DPはFSDPに対応し、最も外側の並列次元であるPPとDPは、数十マイクロ秒のレイテンシでマルチホップネットワークを介して通信することができることを思い出してください。FSDPでは元のNCCLの集合通信操作all-gatherとreduce-scatterが使用され、PPではポイントツーポイント通信が使用され、データチャンキングと段階的データ複製が必要となる。このアプローチは以下のような非効率性をもたらす:
- データ転送を容易にするために、ネットワーク上で多数の小さな制御メッセージを交換する必要がある;
- メモリコピー操作の追加;
- 追加のGPUサイクルを通信に使用する。
Llama 3のトレーニングでは、チャンキングとデータ転送を、大規模クラスタでは数十マイクロ秒にもなるネットワークレイテンシに適応させることで、これらの非効率性のいくつかに対処している。また、小さな制御メッセージがより高い優先度でネットワークを通過することを許可し、特に深くバッファリングされたコアスイッチにおけるキューの先頭のブロッキングを回避しています。
Llamaの将来のバージョンに向けた私たちの進行中の作業には、上記のすべての問題に完全に対処するためのNCCLXへの深い変更が含まれています。

3.3.4 信頼性と運営上の課題
16KのGPUトレーニングの複雑さと潜在的な故障シナリオは、私たちが操作してきたより大きなCPUクラスタを上回ります。さらに、トレーニングが同期的であるためフォールトトレラント性が低く、GPUが1つ故障するとジョブ全体を再起動する必要があります。このような課題にもかかわらず、Llama 3では、クラスタの自動メンテナンス(ファームウェアやLinuxカーネルのアップグレード(Vigraham and Leonhardi, 2024)など)をサポートしながら、90%を超えるトレーニング時間を達成しました。
有効訓練時間とは、経過時間のうち、有効な訓練に費やされた時間のことである。 54日間のトレーニング前スナップショットの間に、合計466回のオペレーション停止が発生した。このうち47回は、自動メンテナンス作業(ファームウェアのアップグレードや、コンフィギュレーションやデータセットの更新などオペレーター主導の作業)による計画的な中断であった。残りの419件は予期せぬ停止で、表5に分類されている。予期せぬ停止のうち約78%は、GPUやホストコンポーネントの故障など、特定されたハードウェアの問題、またはサイレントデータ破損や計画外の個々のホストのメンテナンスイベントなど、ハードウェア関連の問題が疑われたことに起因しています。多くの障害が発生したにもかかわらず、この期間中に手作業による介入を必要としたのは3件のみで、残りの問題は自動化によって対処された。
効果的なトレーニング時間を改善するために、ジョブの起動とチェックポイントの時間を短縮し、迅速な診断と問題解決のためのツールを開発しました。 PyTorchに内蔵されているNCCL Flight Recorder (Ansel et al., 2024)を大いに活用しました。NCCLXの場合は特にそうだ。これを使用することで、各集合操作の通信イベントと継続時間を効率的にログに記録し、NCCLXウォッチドッグやハートビートタイムアウトが発生した場合にトレースデータを自動的にダンプすることができる。オンライン設定変更(Tang et al., 2015)により、コードのリリースやジョブの再起動なしに、より計算集約的なトレース操作やメタデータ収集を選択的に有効にすることができる。 大規模トレーニングにおける問題のデバッグは、私たちのネットワークにNVLinkとRoCEが混在しているために複雑です。データ転送は通常、CUDAカーネルによって発行されるロード/ストア操作を介してNVLink上で実行され、リモートGPUまたはNVLink接続の障害は、明示的なエラーコードを返すことなく、CUDAカーネルのロード/ストア操作の停止として現れることがよくあります。PyTorchはNCCLXの内部状態にアクセスし、関連する情報を追跡できます。NVLink障害によるストールを完全に防ぐことはできませんが、私たちのシステムは通信ライブラリの状態を監視し、そのようなストールが検出されると自動的にタイムアウトします。さらに、NCCLXは、各NCCLX通信のカーネルとネットワークのアクティビティを追跡し、すべてのランク間のデータ転送の完了と未完了を含む、障害が発生したNCCLXコレクティブの内部状態のスナップショットを提供します。このデータを解析して、NCCLX拡張の問題をデバッグします。
ハードウェアの問題によって、検出が困難な、動作はしているが遅いスト ラグラーが発生することがあります。たとえ、はぐれ者が1つしかなくても、他の何千ものGPUの速度を低下させる可能性があり、多くの場合、正常動作しているが通信が遅いという形になります。 私たちは、選択したプロセス・グループからの潜在的に問題のある通信に優先順位をつけるツールを開発しました。いくつかの重要な容疑者だけを調査することで、多くの場合、はぐれ者を効果的に特定することができます。
興味深い観察は、環境要因が大規模トレーニングのパフォーマンスに与える影響である。Llama 3 405Bでは、時間変化に基づいて1-2%のスループット変動に気づきました。この変動は、GPUの動的電圧および周波数スケーリングに影響を与える真昼の高温が原因です。 トレーニング中、すべてのGPUがチェックポイントや集団通信の終了を待っていたり、トレーニングジョブ全体の開始やシャットダウンを待っていたりすることなどが原因で、何万ものGPUが同時に消費電力を増減させることがあります。このような事態が発生すると、データセンター内の消費電力が数十メガワットのオーダーで過渡的に変動することになり、電力網の限界を超えることになります。この問題は、今後さらに大規模なラマ・モデルのトレーニングを行うにあたり、現在進行中の課題です。
3.4 トレーニング・プログラム
ラマ3 405Bのプレトレーニングレシピには、主に3つの段階がある:
(1)初期プリトレーニング、(2)ロングコンテキストプリトレーニング、(3)アニーリング。これら3つの段階のそれぞれについて以下に説明する。8Bモデルと70Bモデルの事前学習にも同様のレシピを用いる。
3.4.1 最初の事前トレーニング
最大学習率8×10-⁵、8,000ステップまで線形にウォームアップし、1,200,000ステップ後に8×10-⁷まで減衰するコサイン学習率スキームを用いて、Llama 3 405Bモデルの事前学習を行った。訓練の安定性を向上させるため、訓練開始時にはバッチサイズを小さくし、その後バッチサイズを大きくして効率を向上させる。具体的には、最初はバッチサイズを4Mトークン、シーケンス長を4,096とする。252Mトークンを事前学習した後、バッチサイズを8Mシーケンス、シーケンス長を8,192トークンにそれぞれ倍増する。2.87Tトークンを事前学習した後、再びバッチサイズを16Mに倍増する。この訓練方法は非常に安定している:損失スパイクはほとんど発生せず、モデル訓練の偏差を修正するための介入は必要ない。
データの組み合わせの調整学習中、特定の下流タスクにおけるモデルのパフォーマンスを向上させるため、事前学習データの組み合わせをいくつか調整した。特に、Llama 3の多言語能力を向上させるため、事前学習において非英語データの割合を増やしました。また、モデルの数学的推論を向上させるために数学的データの割合を増加させ、モデルの知識カットオフを更新するために事前トレーニングの後期に最新のネットワークデータを追加し、後に低品質であることが判明したデータのサブセットの割合を減少させました。
3.4.2 ロングコンテキストの事前トレーニング
事前学習の最終段階では、最大128,000トークンのコンテキストウィンドウをサポートするために長いシーケンスを訓練する。自己注意層の計算量はシーケンスの長さに応じて2次関数的に増加するため、長いシーケンスの訓練は早めに行わない。我々は、サポートされるコンテキストの長さを徐々に増加させ、モデルが増加したコンテキストの長さにうまく適応した後に事前学習を行う。適応に成功したかどうかは、次の2つを測定することで評価する:
(1)ショートコンテキスト評価におけるモデルのパフォーマンスが完全に回復したかどうか;
(2)モデルがこの長さまで「干し草の山の中の針」タスクを完璧に解くことができるかどうか。Llama 3 405Bの事前学習では、コンテキストの長さを6段階で段階的に増加させ、8,000トークンの初期コンテキストウィンドウから開始し、最終的に128,000トークンのコンテキストウィンドウに到達した。この長いコンテキストの事前学習段階では、約8,000億個の学習用トークンが使用された。

3.4.3 アニーリング
最後の40Mトークンの事前学習では、128Kトークンのコンテキスト長を維持しながら、学習率を0に線形にアニーリングした。このアニーリングフェーズでは、非常に質の高いデータソースのサンプルサイズを増やすためにデータミックスも調整する。最後に、アニーリング中のモデルのチェックポイントの平均(Polyak (1991) average)を計算し、最終的な事前学習済みモデルを生成する。
4 フォローアップ研修
フォローアップ学習を複数回行うことで、Llama 3モデルを生成し、アライメントを行う。これらのフォローアップ訓練は、事前に訓練されたチェックポイントに基づき、モデルの整列のために人間のフィードバックを取り入れる(Ouyang et al.)フォローアップトレーニングの各ラウンドは、教師ありファインチューニング(SFT)と、手動アノテーションまたは合成によって生成された例を用いた直接プリファレンス最適化(DPO; Rafailov et al.4.1節と4.2節で、それぞれ後続の学習モデリングとデータ手法を説明する。さらに、推論、プログラミング能力、ファクタリング、多言語サポート、ツールの使用、長いコンテクスト、正確な指示の遵守の観点からモデルを改善するために、セクション4.3でカスタマイズされたデータ照合戦略の詳細を提供する。
4.1 モデリング
ポストトレーニング戦略の基本は、報酬モデルと言語モデルである。 まず、人間がラベル付けした嗜好データ(セクション4.1.2参照)を用いて、事前学習チェックポイントの上に報酬モデルを学習する。次に、教師付き微調整(SFT; セクション4.1.3参照)を使って事前学習チェックポイントを微調整し、さらに直接嗜好最適化(DPO; セクション4.1.4参照)を使ってチェックポイントと整合させます。このプロセスを図7に示す。特に断りのない限り、我々のモデリング・プロセスは Llama 3 405B に適用され、簡単のため Llama 3 405B と呼ぶ。
4.1.1 チャットの対話形式
大規模言語モデル(LLM)を人間とコンピュータの対話に適応させるためには、モデルが人間のコマンドを理解し、対話タスクを実行できるようなチャット対話プロトコルを定義する必要がある。Llama 3は前作と比較して、ツールの使用(セクション4.3.5)のような新機能があり、1つの対話ラウンドで複数のメッセージを生成し、異なる場所(例:ユーザー、ipython)に送信する必要があるかもしれません。これをサポートするために、様々な特別なヘッダートークンと終了トークンを使用する新しいマルチメッセージチャットプロトコルを設計した。ヘッダートークンは、ダイアログ内の各メッセージの送信元と宛先を示すために使用されます。同様に、終了マーカーは、人間とAIが交互に話す順番がいつになるかを示す。
4.1.2 報酬モデリング
異なる能力をカバーする報酬モデル(RM)を訓練し、事前に訓練したチェックポイントの上に構築した。 訓練目的はLlama 2と同じであるが、データサイズが大きくなるにつれて改善が減少することが観察されたため、損失関数のマージナル項を削除した。 Llama 2と同様に、類似した回答を持つサンプルをフィルタリングした後、報酬モデリングにすべてのプリファレンスデータを使用する。
標準的な(selected, rejected)レスポンスのプリファレンスのペアに加え、アノテーションにより、いくつかのキューでは、ペアから選択されたレスポンスが改善のためにさらに編集された第3の「edited response」が作成される(セクション4.2.1参照)。このように、嗜好選別のサンプルには、2つまたは3つの回答があり、それらは明確にランク付けされています(編集された回答 > 選択された回答 > 拒否された回答)。 トレーニングでは、キューと複数の回答を1行に連結し、回答をランダム化した。これは、回答を別々の行に配置してスコアを計算する標準的なシナリオの近似であるが、我々のアブレーション実験では、このアプローチは精度を失うことなく訓練効率を向上させる。
4.1.3 監督の微調整
人間のラベル付けされたキューは、まず報酬モデルを使用してサンプリングするために拒絶される。この拒絶サンプリングされたデータを他のデータソース(合成データを含む)と組み合わせ、標準的なクロスエントロピー損失を用いて、事前に訓練された言語モデルを微調整する。データブレンドの詳細についてはセクション4.2を参照。学習ターゲットの多くはモデルによって生成されるが、この段階を教師付き微調整(SFT; Wei et al.2022a; Sanh et al.2022; Wang et al.2022b)と呼ぶ。
我々の最大モデルは、8.5Kから9Kステップ内で1e-5の学習率で微調整される。これらのハイパーパラメータ設定は、異なるラウンドやデータミックスに適していることがわかった。
4.1.4 直接プリファレンス最適化
さらに、Direct Preference Optimisation (DPO; Rafailov et al., 2024)を用いて、人間の嗜好アライメントのためのSFTモデルのトレーニングを行った。訓練では、主に前回のアライメントで最も良い結果を出したモデルから収集した最新の嗜好データバッチを使用する。その結果、我々の訓練データは、各ラウンドで最適化された戦略モデルの分布によりよく一致する。我々はPPO(Schulman et al., 2017)のような戦略アルゴリズムも検討したが、DPOの方が計算量が少なく、大規模モデル、特にIFEval(Zhou et al., 2023)のような指示遵守ベンチマークにおいて優れた性能を発揮することがわかった。
Llama3では、学習率を1e-5とし、βハイパーパラメータを0.1に設定した。さらに、DPOに以下のアルゴリズム修正を適用した:
- DPO損失におけるフォーマットマーカーのマスキング。 DPOの学習を安定させるため、選択された応答と拒否された応答から、特殊なフォーマットマー カー(セクション4.1.1で説明したヘッダーと終端マーカーを含む)をマスクアウトする。これらのマーカーが損失に関与することで、末尾の重複や突然の終端マーカの生成など、 望ましくないモデルの動作につながる可能性があることに注意する。これは、DPOロスの対照的な性質によるもので、選択された応答と拒否された応答の両方に共通のマーカーが存在すると、モデルがこれらのマーカーの可能性を同時に増加させたり減少させたりする必要があるため、学習目標が相反する可能性があるという仮説を立てた。
- NLLロスを使った正則化 Pangら(2024)と同様に、0.2のスケーリングファクターで選択配列に負の対数尤度(NLL)損失項を追加した。これは、生成に必要なフォーマットを維持し、選択された応答の対数尤度が低下するのを防ぐことで、DPOトレーニングをさらに安定させるのに役立つ(Pang et al.)
4.1.5 モデルの平均化
最後に、RM、SFT、DPOの各段階において、様々なデータバージョンやハイパーパラメータを用いた実験で得られたモデルを平均した(Izmailov et al.2019; Wortsman et al.2022; Li et al.2022)。ラマ3の条件付けに使用された、内部で収集された人間の嗜好データに関する統計情報を示す。我々は、評価者にモデルと複数ラウンドの対話を行ってもらい、各ラウンドの回答を比較した。後処理では、各ダイアログを複数の事例に分割し、それぞれにプロンプト(可能であれば前のダイアログも含む)とレスポンス(選択されたレスポンスや拒否されたレスポンスなど)を含ませた。

4.1.6 反復ラウンド
Llama 2に続いて、上記の方法を6ラウンド反復した。各ラウンドにおいて、新しい嗜好ラベリングと微調整(SFT)データを収集し、最新のモデルから合成データをサンプリングした。
4.2 トレーニング後のデータ
学習後のデータの構成は、言語モデルの実用性と動作に重要な役割を果たす。本節では、アノテーションの手順とプリファレンスデータの収集(セクション4.2.1)、SFTデータの構成(セクション4.2.2)、データの品質管理とクリーニングの方法(セクション4.2.3)について説明する。
4.2.1 嗜好
嗜好データのラベリングプロセスは、Llama 2と同様である。各ラウンドの後、アノテーションのために複数のモデルを展開し、各ユーザーキューに対して異なるモデルから2つの応答をサンプリングします。これらのモデルは、異なるデータブレンドとアライメントスキームを使用してトレーニングすることができ、その結果、異なる能力の強み(コードの専門知識など)とデータの多様性が向上します。アノテーターには、嗜好のレベルに基づいて、嗜好スコアを4つのレベルのいずれかに分類するよう求めた:「かなり良い」、「良い」、「少し良い」、「少し良い」。
また、優先順位を決定した後に編集ステップを設け、アノテーターが優先順位の高い応答をさらに洗練できるようにしました。アノテーターは、選択された応答を直接編集するか、フィードバックキューモデルを使用して自分の応答を洗練させることができます。その結果、いくつかのプリファレンス・データには、3つの並べ替えられた回答(編集>選択>拒否)があります。
Llama3のトレーニングに使用した嗜好アノテーション統計は表6に報告されている。一般英語は、知識ベースの質疑応答や的確な指示に従うなど、特定の能力の範囲を超えたいくつかのサブカテゴリーを含んでいる。Llama 2と比較すると、プロンプトと回答の平均的な長さが増加していることが観察され、Llama 3がより複雑なタスクをトレーニングしていることが示唆された。さらに、収集されたデータを批判的に評価するために、品質分析と手動評価プロセスを実施し、プロンプトを改良し、アノテーターに体系的で実用的なフィードバックを提供できるようにした。例えば、各ラウンドでLlama 3が改善されるにつれて、私たちはそれに対応してキューの複雑さを増し、モデルが遅れている領域をターゲットにします。
各後期訓練ラウンドにおいて、報酬モデリングにはその時点で利用可能なすべての選好データを使用し、DPO訓練には各能力から最新のバッチのみを使用する。報酬モデリングとDPOの両方において、「選択反応が有意に良い、または良い」とラベル付けされたサンプルで訓練し、類似した反応を持つサンプルは破棄する。
4.2.2 SFTデータ
ファインチューニングのデータは、主に以下のソースから得ている:
- 手作業で注釈を付けたコレクションからの手がかりと、サンプリング回答に対する拒否反応
- 特定の能力に関する合成データ(詳細はセクション4.3を参照)
- 少量の手動ラベル付けデータ(詳細はセクション4.3参照)
ポストトレーニングのサイクルが進むにつれて、Llama 3のより強力な亜種を開発し、これらを使用してより大きなデータセットを収集し、幅広い複雑な能力をカバーするようにした。このセクションでは、棄却サンプリングプロセスの詳細と、最終的なSFTデータ混合物の全体的な構成について説明します。
サンプルの拒否。リジェクトサンプリング(RS)では、手動アノテーション(セクション4.2.1)で収集した各キューに対して、直近のチャットモデリング戦略からK個の出力をサンプリングし(典型的には、前回のポストトレーニングイテレーションからの最良の実行チェックポイント、または特定の能力に対する最良の実行チェックポイント)、Baiら(2022)と同様に、報酬モデルを使用して最良の候補を選択する。ポストトレーニングの後の段階では、システムキューを導入し、RSの応答が望ましいトーン、スタイル、またはフォーマットに適合するように導きます。
拒絶サンプリングの効率を改善するために、PagedAttention(Kwon et al.PagedAttentionは、現在のキャッシュ容量に基づいて動的に要求をスケジューリングすることで、任意の出力長をサポートする。残念ながら、これはメモリが不足したときにスワップするリスクをもたらす。このスワッピングのオーバーヘッドを排除するために、最大出力長を定義し、その長さの出力を保持するのに十分なメモリがある場合にのみリクエストを実行する。pagedAttentionはまた、対応するすべての出力間で、ヒントされたキーバリューキャッシュページを共有することを可能にする。全体として、これは拒絶サンプリング中のスループットを2倍以上増加させる結果となった。
集計データの構成。表7は、「有用性」ミックスに含まれるデータの大まかなカテゴリーごとの統計値を示している。SFTデータと嗜好データは重複する領域を含むが、キュレーションが異なるため、カウント統計量も異なる。セクション4.2.3では、データサンプルの主題、複雑さ、品質を分類するために使用した技法について説明する。ポストトレーニングの各ラウンドでは、幅広いベンチマークに対して複数の軸でパフォーマンスを調整するために、全体的なデータミックスを慎重に調整する。最終的なデータ混合は、特定の高品質なソースについては複数回反復され、その他のソースについてはダウンサンプルされます。

4.2.3 データ処理と品質管理
トレーニングデータのほとんどがモデルによって生成されたものであることを考えると、慎重なクリーニングと品質管理が必要である。
データクレンジング: 初期段階では、顔文字や感嘆符の多用など、データ内に多くの不要なパターンがあることが観察された。そこで、問題のあるデータをフィルタリングまたは削除するために、一連のルールベースのデータ削除および修正戦略を実施した。例えば、謝りすぎのイントネーションの問題を軽減するために、使いすぎのフレーズ(「ごめんなさい」や「申し訳ありません」など)を特定し、データセット内のそのようなサンプルの割合を注意深くバランスさせました。
データの刈り込み: また、低品質なトレーニングサンプルを除去し、モデル全体のパフォーマンスを向上させるために、多くのモデルベースの技術を適用します:
- 主題の分類 まず、Llama 3 8Bをトピック分類器に微調整し、すべてのデータを推論して、粗視化カテゴリ(「数学的推論」)と細視化カテゴリ(「幾何学と三角法」)に分類した。
- 品質評価: 報酬モデルとLlamaベースのシグナルを用いて、各サンプルの品質スコアを求めた。RMベースのスコアでは、最も高い四分位値にあるデータを高品質とみなした。Llamaベースのスコアについては、Llama 3のチェックポイントを促し、一般英語のデータを3つのレベル(正確さ、指示の順守、トーン/プレゼンテーション)、コードのデータを2つのレベル(エラーの認識、ユーザーの意図)で採点し、最も高いスコアを得たサンプルを高品質なデータとみなした。 RMとLlamaベースのスコアは競合率が高く、これらのシグナルを組み合わせることで、内部テストセットで最高の想起が得られることがわかった。最終的に、RMまたはLlamaベースのフィルターによって高品質とラベル付けされたサンプルを選択する。
- 難易度は高い: より複雑なモデル例を優先することにも関心があったため、Instag (Lu et al., 2023)とLlamaベースのスコアリングという2つの難易度メトリクスを用いてデータをスコアリングした。Instagでは、Llama 3 70BにSFTキューに対するインテント・ラベル付けを促した。また、Llama 3に対話の難易度を3段階で測定させた(Liu et al.)
- セマンティック・ディ・エンファシス: 最後に、意味的重複除去を行う(Abbas et al.) まず、RoBERTa (Liu et al., 2019b)を用いて完全なダイアログをクラスタリングし、各クラスタで品質スコア×難易度スコアでソートする。次に、ソートされたすべての例に対して反復することで、貪欲な選択を行い、これまでのクラスタで見られた例との最大余弦類似度が閾値より小さいものだけを残す。
4.3 容量
特に、コード処理能力(4.3.1節)、多言語能力(4.3.2節)、数学的・推論能力(4.3.3節)、長い文脈の理解(4.3.4節)、ツールの使用(4.3.5節)、事実性(4.3.6節)、制御性(4.3.7節)など、特定の能力を高めるために行われた努力のいくつかに焦点を当てる。
4.3.1 コード
このかた コパイロット やCodex (Chen et al., 2021)がリリースされ、コード用のLLMが注目を集めている。開発者は現在、コード・スニペットの生成、デバッグ、タスクの自動化、コード品質の向上のために、これらのモデルを広範に使用している。Llama 3では、Python、Java、JavaScript、C/C++、TypeScript、Rust、PHP、HTML/CSS、SQL、bash/shellといった優先的なプログラミング言語のコード生成、文書化、デバッグ、レビュー機能を改善し、評価することを目標としています。ここでは、コードエキスパートのトレーニング、SFT用の合成データの生成、システムプロンプトによる改善されたフォーマットへの移行、およびこれらのコーディング機能を改善するためのトレーニングデータから不良サンプルを除去する品質フィルタの作成によって得られた結果を紹介します。
スペシャリスト養成。我々は、コードエキスパートを訓練し、その後の複数ラウンドのポストトレーニングで使用し、高品質な人間のコードアノテーションを収集した。これは、メインの事前学習を分岐させ、主に(>85%)コードデータである1Tトークンのミックスで事前学習を継続することで達成された。ドメイン固有のデータで事前学習を継続することは、特定のドメインにおける性能向上に効果的であることが示されている(Gururangan et al.)我々はCodeLlama (Rozière et al., 2023)と同様のレシピに従っている。学習の最後の数千ステップで、リポジトリレベルのコードデータの高品質なブレンドに対して、長いコンテキストの微調整(LCFT)を行い、エキスパートのコンテキストの長さを16Kトークンに拡張する。最後に、セクション4.1で説明したような学習後のモデリングレシピに従い、主にコードに特化したSFTとDPOの混合データを使用してモデルを調整する。このモデルは、コーディングキューのリジェクトサンプリングにも使用される(セクション4.2.2)。
合成データの生成。開発中、私たちは、指示に従うことの難しさ、コードの構文エラー、誤ったコード生成、エラーの修正の難しさなど、コード生成に関する主要な問題を特定した。人間による緻密なアノテーションは理論的にはこれらの問題を解決することができるが、合成データ生成は、より安価で拡張性が高く、アノテーターの専門知識レベルに制限されない補完的なアプローチを提供する。
そこで、Llama 3とCode Expertを使用して、多数の合成SFTダイアログを生成した。 合成コードデータを生成するための3つのハイレベルな方法について述べる。全体として、SFT中に270万以上の合成例を使用した。
1. 合成データ生成:フィードバックの実装。8Bと70Bのモデルは、より大きな、より有能なモデルによって生成された訓練データにおいて、著しい性能の向上を示している。しかし、我々の予備実験によれば、Llama 3 405Bのみをそれ自身が生成したデータでトレーニングしても、役に立たない(あるいは性能が低下する)ことが示唆されている。この限界に対処するため、我々は、モデルがその間違いから学び、軌道に乗ることを可能にする真実の源として、実行フィードバックを導入する。具体的には、以下の手順で約100万の合成コード対話のデータセットを生成する:
- 問題記述の生成:まず、様々なトピック(ロングテール分布を含む)をカバーするプログラミング問題記述の大規模なセットを生成した。この多様性を実現するために、さまざまなソースからコードスニペットをランダムにサンプリングし、これらの例に基づいてプログラミング問題を生成するようにモデルを促した。これにより、幅広いトピックを活用し、包括的な問題記述セットを作成することができた(Wei et al.)
- ソリューション・ジェネレーション:その後、ラマ3に与えられたプログラミング言語で各問題を解くよう促した。プロンプトに適切なプログラミングルールを追加することで、生成された解答の質が向上することが確認された。さらに、モデルに注釈をつけて思考プロセスを説明させることも有効であることがわかった。
- 正しさの分析: 解を生成した後、その正しさが保証されていないこと、そして微調整されたデータセットに不正確な解が含まれるとモデルの質が損なわれる可能性があることを認識することが重要である。完全な正しさを保証することはできませんが、正しさを近似する方法を開発しました。この目的のために、生成された解から抽出されたソースコードを取り出し、静的解析と動的解析のテクニックを組み合わせて適用し、その正しさをテストします:
- 静的解析: 生成されたコードはすべてパーサーとコード・チェック・ツールにかけられ、構文の正しさ、構文エラー、初期化されていない変数やインポートされていない関数の使用、コード・スタイルの問題、型エラーなどが検出されます。
- ユニットテストの生成と実行 それぞれの問題と解決策について、私たちはモデルに単体テストの生成を促し、コンテナ化された環境で解決策とともにテストを実行し、実行時のエラーといくつかのセマンティック・エラーを捕捉する。
- エラー・フィードバックと反復的自己修正: 解がいずれかのステップで失敗すると、モデルを修正するように促す。プロンプトには、元の問題記述、間違った解法、パーサ/コード検査ツール/テストプログラムからのフィードバック(標準出力、標準エラー、リターンコード)が含まれます。単体テストの実行が失敗した後、モデルは既存のテストに合格するようにコードを修正するか、生成されたコードに合うように単体テストを修正することができます。すべてのチェックをパスしたダイアログのみが、教師あり微調整(SFT)のための最終データセットに含まれる。注目すべきは、約20%の解が最初は間違っていたが、自己修正されたことで、モデルが実行フィードバックから学習し、性能を向上させたことが示唆される。
- 微調整と反復改善: ファインチューニングのプロセスは複数回にわたって行われ、各ラウンドは前のラウンドの上に構築される。微調整の各ラウンドの後、モデルは次のラウンドのために、より質の高い合成データを生成するように改善される。この反復プロセスにより、モデル性能の段階的な改良と向上が可能になる。
2.合成データ生成:プログラミング言語翻訳。 主要なプログラミング言語(例:Python/C++)とあまり一般的でないプログラミング言語(例:Typescript/PHP)の間には性能差があることがわかる。これは、一般的でないプログラミング言語の学習データが少ないため、驚くことではありません。これを軽減するために、一般的なプログラミング言語のデータをあまり一般的でない言語に翻訳することで利用可能なデータを補う(推論分野のChenら(2023)と同様)。これは、Llama 3にプロンプトを表示し、構文解析、コンパイル、および実行を通じて品質を確保することで達成される。図8は、Pythonから翻訳された合成PHPコードの例である。これにより、MultiPL-E (Cassano et al., 2023)ベンチマークで測定された、あまり一般的でない言語の性能が大幅に向上している。
3.合成データ生成:逆翻訳。 実行フィードバックからの情報量が品質を決定するのに不十分な特定のコーディング能力(文書化、解釈など)を向上させるために、別の多段階アプローチを使用する。このプロセスを用いて、コードの解釈、生成、文書化、デバッグに関連する約120万の合成ダイアログを生成した。事前学習データから様々な言語のコードスニペットから始める:


- 生成する: 例えば、コード・スニペットにコメントや文書文字列を追加したり、コードの一部を解釈するようモデルに求めたりする。
- 逆翻訳だ。 合成的に生成されたデータを元のコードに "逆翻訳 "するようにモデルを促します(例えば、ドキュメントのみからコードを生成するようにモデルを促したり、説明のみからコードを生成するようにモデルを促したりします)。
- ろ過。 元のコードを参照として使用し、Llama 3に出力の品質を判断するよう促します(例えば、逆翻訳されたコードが元のコードにどれだけ忠実であるかをモデルに尋ねます)。そして、SFTで自己検証スコアが最も高い生成例を使用します。
サンプルを拒否するためのシステムプロンプトガイド。 リジェクト・サンプリングでは、コード固有のシステム・キューを使用して、コードの読みやすさ、ドキュメンテーション、完全性、具体性を向上させる。セクション7で、このデータが言語モデルの微調整に使用されることを思い出してください。図9は、システム・ヒントが生成されたコードの品質を向上させるのに役立つ例を示している。必要なコメントを追加したり、より情報量の多い変数名を使用したり、メモリを節約したりなどである。
実行とモデルを基準としてトレーニングデータをフィルタリングする。 セクション4.2.3で説明したように、誤ったコードブロックが含まれるなど、リジェクトサンプリングデータの品質に問題が発生することがありました。リジェクト・サンプリング・データにおけるこのような問題の検出は、合成コード・データの検出ほど単純ではありません。なぜなら、リジェクト・サンプリング・レスポンスには自然言語とコードが混在していることが多く、必ずしも実行可能であるとは限らないからです。(たとえば、ユーザープロンプトが明示的に擬似コードを要求したり、実行可能ファイルの非常に小さな部分のみの編集を要求したりすることがある)。 この問題に対処するため、私たちは「審査員としてのモデル」アプローチを利用し、以前のバージョンのLlama 3を評価し、コードの正しさとコードスタイルという2つの基準に基づいてバイナリ(0/1)スコアを割り当てます。2点満点のサンプルのみが保持された。当初、この厳格なフィルタリングは、主に挑戦的なヒントを持つサンプルを不釣り合いに除去するため、ダウンストリームベンチマークのパフォーマンスを低下させる結果となりました。これを打ち消すために、最も挑戦的なコード化データと分類された回答のいくつかを、Llamaベースの「モデルを判断材料とする」基準を満たすまで戦略的に修正しました。これらの難易度の高い質問を改善することで、コード化されたデータは品質と難易度のバランスをとり、最適なダウンストリームパフォーマンスを達成しました。
4.3.2 多言語主義
このセクションでは、Llama 3の多言語機能をどのように向上させたかについて説明します。これには、より多くの多言語データに特化したエキスパートモデルのトレーニング、ドイツ語、フランス語、イタリア語、ポルトガル語、ヒンディー語、スペイン語、タイ語の多言語コマンドの高品質なファインチューニングデータの調達と生成、モデルの全体的なパフォーマンスを向上させるための多言語言語ブートストラップ特有の課題の解決などが含まれます。
スペシャリスト養成。Llama 3の事前学習データには、非英語トークンよりもはるかに多くの英語トークンが含まれています。より質の高い非英語の人間によるアノテーションを収集するために、事前学習の実行を分岐し、90%の多言語トークンを含むデータミックスで事前学習を継続することで、多言語エキスパートモデルを訓練する。次に、セクション4.1で説明したように、このエキスパートモデルをポストトレーニングする。このエキスパートモデルは、事前学習が完全に完了するまで、より質の高い非英語の人間によるアノテーションを収集するために使用される。
多言語データ収集。多言語SFTデータは主に以下のソースから入手した。全体の分布は、人間のアノテーションが2.41 TP3T、他のNLPタスクからのデータが44.21 TP3T、リジェクトサンプリングデータが18.81 TP3T、翻訳推論データが34.61 TP3Tです。
- 手動注釈:私たちは、言語学者やネイティブスピーカーから高品質な手動アノテーションデータを収集しています。これらのアノテーションは、主に実際のユースケースを表すオープンエンドのキューで構成されています。
- 他のNLPタスクからのデータ:さらに強化するために、他のタスクの多言語学習データを使用し、対話形式に書き換える。例えば、exames-qa (Hardalov et al., 2020)やConic10k (Wu et al., 2023)のデータを使用する。言語アライメントを改善するために、GlobalVoices (Prokopidis et al., 2016)やWikimedia (Tiedemann, 2012)のパラレルテキストも使用している。LIDベースのフィルタリングとBlaser 2.0(Seamless Communication et al.並列テキストデータについては、2テキストペアを直接使用する代わりに、Wei et al.(2022a)にインスパイアされた多言語テンプレートを適用し、翻訳や言語学習シナリオにおける実際の対話をより適切にシミュレートした。
- サンプリングデータを拒否する:拒絶サンプリングを人間の注釈付きキューに適用することで、英語データの場合と比較してほとんど変更を加えることなく、微調整のための高品質なサンプルを生成した:
- 生成:生成の多様化を図るため、ポストトレーニングの初期段階において、0.2 -1の範囲で温度のハイパーパラメータをランダムに選択することを検討した。高い温度を使用すると、多言語の手がかりに対する応答が創造的で刺激的なものになる可能性があるが、不必要または不自然なコードスイッチングが起こりやすくなる可能性もある。ポストトレーニングの最終段階では、このトレードオフのバランスをとるために0.6の一定値を使用した。さらに、回答フォーマット、構造、一般的な読みやすさを向上させるために、特殊なシステムキューを使用しました。
- 選択:報酬モデルに基づく選択に先立ち、プロンプトと回答が高い確率で言語的に一致するよう、多言語固有のチェックを実施した(例えば、ローマ字表記のヒンディー語のプロンプトは、ヒンディー語のサンスクリット文字を使って回答されることを期待すべきではない)。
- 翻訳データ:翻訳英語(Bizzoni et al., 2020; Muennighoff et al., 2023)、名前の偏り(Wang et al., 2022a)、性別の偏り(Savoldi et al., 2021)、文化的な偏り(Ji et al., 2023)の可能性を防ぐため、モデルの微調整に機械翻訳データを使わないようにした。.加えて、英語圏の文化的文脈に根ざしたタスクにのみモデルがさらされることを防ぐことを目的とした。我々はこの例外を認め、合成された量的推論データ(詳細はセクション4.3.3を参照)を非英語に翻訳し、非英語言語における量的推論のパフォーマンスを向上させた。これらの数学問題の言語は単純であるため、翻訳されたサンプルは品質上の問題がほとんどないことがわかった。この翻訳データをMGSMに追加することで、有意な効果が観察された(Shi et al.、2022)。
4.3.3 数学と推論
推論とは、多段階の計算を実行し、最終的に正しい答えを導き出す能力と定義する。
数学的推論に秀でたモデルを訓練するためのアプローチには、いくつかの課題があった:
- チップ不足。 問題の複雑さが増すにつれて、教師ありファインチューニング(SFT)に有効な手がかりや問題の数は減少する。この希少性により、モデルに様々な数学的スキルを教えるための多様で代表的な訓練データセットを作成することが難しくなる(Yu et al.)
- 真の推論プロセスの欠如。 効果的な推論には、推論プロセスを促進するための段階的な解決策が必要である (Wei et al., 2022c)。しかし、問題を段階的に分解して最終的な答えに到達する方法をモデルに導くために不可欠な、現実的な推論プロセスが欠けていることが多い(Zelikman et al.)
- 中間ステップが正しくない。 モデルによって生成された推論連鎖を使用する場合、中間ステップが必ずしも正しいとは限らない(Cobbe et al.2021; Uesato et al.2022; Lightman et al.2023; Wang et al.2023a)。この不正確さは、最終的な答えを誤らせる可能性があり、対処する必要がある。
- 外部ツールを使用してモデルをトレーニングする。 コード・インタープリターのような外部ツールを利用するためにモデルを強化する能力は、コードとテキストを織り交ぜて推論することを可能にする(Gao et al.2023; Chen et al.2022; Gou et al.2023)。この能力は、問題解決能力を大幅に向上させる。
- 訓練と推論の違い トレーニング中にモデルを微調整する方法は、通常、推論中に使用する方法とは異なる。推論中、微調整されたモデルは人間や他のモデルと相互作用し、推論を改善するためのフィードバックを必要とすることがある。推論のパフォーマンスを維持するためには、トレーニングと実世界のアプリケーションの一貫性を確保することが重要です。
これらの課題に対処するため、以下の方法論を適用する:
- 出番不足の解消 数学的文脈から関連する事前学習データを取得し、教師ありの微調整に使用できる質問応答形式に変換する。さらに、モデルが苦手とする数学的スキルを特定し、これらのスキルをモデルに教えるために、人間から積極的にキューを収集する。このプロセスを促進するために、数学的スキルの分類法(Didolkar et al.
- 段階的推論ステップによるトレーニングデータの補強。 Llama3を使って、一組のキューに対する解答を段階的に生成する。各プロンプトに対して、モデルは生成される結果の数を可変にする。これらの生成結果は、正解に基づいてフィルタリングされる(Li et al., 2024a)。また、Llama 3を使用して、与えられた問題に対して特定のステップバイステップの解法が有効であることを検証する自己検証も行う。このプロセスは、モデルが有効な推論軌道を生成しないインスタンスを排除することで、微調整されたデータの品質を向上させる。
- 誤った推論のステップをフィルタリングする。 我々は、結果とステップワイズ報酬モデル(Lightman et al.これらの報酬モデルは、無効な段階的推論のデータを排除するために使用され、微調整によって高品質のデータが得られるようにする。より困難な手がかりに対しては、学習された段階的報酬モデルを用いてモンテカルロ木探索(MCTS)を行い、有効な推論軌道を生成することで、高品質な推論データの収集をさらに強化する(Xie et al.、2024)。
- コードとテキスト推論を織り交ぜる。 我々は、Llama 3がテキスト推論とそれに関連するPythonコードの組み合わせによって推論問題を解決することを提案する(Gou et al.)コードの実行は、推論チェーンが無効なケースを排除し、推論プロセスの正しさを保証するためのフィードバック信号として使用される。
- フィードバックとミスから学ぶ 人間のフィードバックをシミュレートするために、我々は誤った生成結果(すなわち、誤った推論軌道を導く生成結果)を利用し、正しい生成結果を生成するようにLlama 3に促すことでエラー修正を行う(An et al.)間違った試行からのフィードバックを利用し、それを修正するという自己反復的なプロセスは、モデルが正確に推論し、間違いから学習する能力を向上させるのに役立つ。
4.3.4 長い文脈
最終的な事前学習段階では、Llama 3のコンテキスト長を8Kから128Kトークンに拡張した(これについてはセクション3.4を参照)。事前学習と同様に、微調整の際にも、短い文脈と長い文脈の能力をバランスさせるために、定式化を注意深く調整する必要があることがわかった。
SFTと合成データ生成。 ショートコンテキストデータのみを使用して既存のSFT定式化を適用しただけでは、事前学習においてロングコンテキストの能力が著しく低下する結果となり、SFTデータポートフォリオにロングコンテキストデータを組み込む必要性が浮き彫りになった。しかし、実際には、長い文脈を読むのは面倒で時間がかかるため、これらの例のほとんどを手作業でラベル付けすることは現実的ではない。 Llama3の初期バージョンを使用して、主要なロングコンテキストのユースケースである(潜在的に複数回の)Q&A、長い文書の要約、コードベースに関する推論に基づいて合成データを生成し、これらのユースケースについて以下で詳しく説明する。
- Q&A 事前学習データセットから長文の文書セットを注意深く選んだ。これらの文書を8Kのラベル付きチャンクに分割し、ランダムに選択されたチャンクに対してQAペアを生成するよう、Llama 3モデルの初期バージョンを促した。 文書全体が学習時のコンテキストとして使用される。
- 要旨 我々はまず、8Kの入力長さのブロックを階層的に要約するために、我々の最強のLlama 3 8Kコンテキストモデルを使用することで、長いコンテキスト文書の階層的要約を適用する。次にこれらの要約を集約する。 訓練では、文書全体を提供し、重要な詳細をすべて保存しながら文書を要約するようモデルを促す。 また、文書の要約に基づいてQAペアを生成し、長い文書全体のグローバルな理解を必要とする質問でモデルを促す。
- 長い文脈コード推論: Pythonファイルを解析してimport文を特定し、依存関係を決定する。 ここから、最もよく使われるファイル、特に少なくとも5つの他のファイルから参照されるファイルを選択します。 これらの主要なファイルの1つをリポジトリから削除し、欠落しているファイルの依存関係を特定し、必要な欠落しているコードを生成するようにモデルを促します。
さらに、これらの合成サンプルをシーケンス長(16K、32K、64K、128K)に応じて分類し、入力長をより細かく特定する。
注意深いアブレーション実験により、0.1%の合成的に生成されたロングコンテキストデータを元のショートコンテキストデータと混合することで、ショートコンテキストテストとロングコンテキストベンチマークテストの両方のパフォーマンスが最適化されることが確認された。
DPOである。 SFTモデルがロングコンテキストのタスクでうまく機能する限り、DPOでショートコンテキストの訓練データのみを使用しても、ロングコンテキストの性能に悪影響はないことに留意されたい。これは、DPO の定式化の最適化ステップが SFT よりも少ないためであると考えられる。この知見を考慮し、ロングコンテキストのSFTチェックポイントの上に、標準的なショートコンテキストのDPO定式化を維持する。
4.3.5 道具の使用
ラージ・ランゲージ・モデル(LLM)に検索エンジンやコード・インタープリターなどのツールを使わせることで、LLMが解決できるタスクの幅が大きく広がり、純粋におしゃべりなモデルから、より多目的なアシスタントに変身させることができる(Nakano et al.2021; Thoppilan et al.2022; Parisi et al.2022; Gao et al.20232022; Parisi et al. 2022; Gao et al. 2023; Mialon et al. 2023a; Schick et al. 2024)。我々はLlama 3を以下のツールと相互作用するように訓練した:
- ラマ3は、知識期限後の最近の出来事に関する質問や、ウェブから特定の情報を検索する必要があるリクエストに答えるために、ブレイブサーチ7を使うように訓練された。
- Pythonインタプリタ。Llama 3は、複雑な計算を実行するコードを生成して実行し、ユーザーがアップロードしたファイルを読み込んで、クイズ、要約、データ分析、視覚化など、これらのファイルに基づいてタスクを解決します。
- 数学計算エンジン.Llama 3はWolfram Alpha API8を使って,数学や科学の問題をより正確に解いたり,Wolframのデータベースから正確な情報を取得したりすることができる.
生成されたモデルは、複数ラウンドのダイアログを含むユーザーからの問い合わせを解決するために、チャット設定でこれらのツールを使用することができる。クエリがツールの複数の呼び出しを必要とする場合、モデルはツールを順次呼び出すステップバイステップの計画を書くことができ、各ツール呼び出しの後に推論を行う。
また、Llama 3のゼロサンプルツール使用機能を向上させ、潜在的に未知のツール定義とコンテキスト設定でのユーザークエリが与えられた場合、正しいツールコールを生成するようにモデルを訓練します。
実現。コアとなるツールは、異なるメソッドを持つPythonオブジェクトとして実装します。ゼロサンプルツールは、説明やドキュメント(つまり、使い方の例)を持つPython関数として実装することができ、モデルは適切な呼び出しを生成するためのコンテキストとして、関数のシグネチャとdocstringを必要とするだけです。
また、Web API呼び出しのために、関数定義と呼び出しをJSON形式に変換します。すべてのツールコールはPythonインタプリタによって実行され、Llama 3システムプロンプトで有効にする必要があります。コア・ツールは、システム・プロンプトから個別に有効化または無効化できます。
データ収集。Schickら(2024)とは異なり、我々はLlama 3にツールの使い方を教えるために、人間の注釈と嗜好に頼っている。これは、Llama 3で一般的に使用されるポストトレーニングパイプラインとは2つの重要な点で異なる:
- ツールに関して、ダイアログはしばしば1つ以上のアシスタントメッセージ(例えば、ツールの起動とツールの出力に関する推論)を含む。そのため、詳細なフィードバックを収集するために、メッセージレベルのアノテーションを実行する。アノテータは、同じコンテキスト内の2つのアシスタントメッセージのプリファレンスを提供するか、両方に大きな問題がある場合、メッセージの1つを編集する。選択または修正されたメッセージはコンテキストに追加され、対話が続けられる。これは、ツールを起動し、ツールの出力について推論するアシスタントの能力に関する人間のフィードバックを提供します。注釈者は、ツール出力をランク付けしたり編集したりすることはできない。
- ツールのベンチマークでは利益が観察されなかったため、リジェクトサンプリングは実施しなかった。
アノテーションプロセスをスピードアップするために、まず、前回のLlama 3のチェックポイントから合成データを微調整することで、基本的なツール使用能力をブートストラップした。こうすることで、アノテーターは少ない編集操作で済むようになる。同様に、Llama 3が開発中に時間をかけて改善されるにつれて、私たちは人間によるアノテーションプロトコルを徐々に複雑にしていきます:私たちは、ツール使用のアノテーションを1ラウンドで開始し、次に対話でのツール使用に移行し、最後に複数ステップのツール使用とデータ解析のアノテーションを行います。
ツールデータセット。ツールを使用するアプリケーションで使用するデータを作成するために、以下のステップを使用します。
- シングルステップのツール使用。 まず、少量のサンプル生成を実行し、構造上、コアツールの1つへの呼び出しを必要とするユーザープロンプトを合成する(例えば、知識期限を超える質問)。次に、やはり少量のサンプル生成に頼って、これらのヒントに適切なツールコールを生成し、それらを実行し、出力をモデルのコンテキストに追加します。最後に、ツールの出力に基づき、ユーザーのクエリに対する最終的な答えを生成するよう、再びモデルを促す。最終的に、システムのヒント、ユーザーのヒント、ツールの呼び出し、ツールの出力、そして最終的な回答という形の軌跡が得られる。また、データセットの約30%をフィルタリングして、強制力のないツール呼び出しやその他のフォーマットの問題を除去した。
- 多段階ツールの使用。 我々はまず、基本的な다단계ツール使用能力をモデルに教えるために合成データを生成することで、同様のプロトコルに従う。これを行うために、まずLlama 3に少なくとも2つのツール(同じツールまたはコアセットの異なるツール)の起動を必要とするユーザーヒントを生成するように促します。次に、これらのヒントに基づき、Llama 3に、推論ステップとツール呼び出しが織り成す解を生成するよう促す少数のサンプルを実行する。 リ・アクト (Yaoら、2022)。図10に、多段階の道具使用を伴うタスクを行うラマ3の例を示す。
- ファイルのアップロード .txt、.docx、.pdf、.pptx、.xlsx、.csv、.tsv、.py、.json、.jsonl、.html、.xml。プロンプトは提供されたファイルに基づいており、ファイルの内容の要約、バグの発見と修正、コード・スニペットの最適化、データ分析や視覚化の実行を求める。図11は、ファイルのアップロードを含むタスクを実行するLlama 3の例である。

この合成データを微調整した後、複数ラウンドのインタラクション、3ステップを超えるツールの使用、ツールの起動が満足のいく回答を得られなかった状況など、様々なシナリオから人間のアノテーションを収集した。我々は、起動されたときのみツールを使用するようにモデルを学習させるために、様々なシステムキューで合成データを補強した。単純なクエリに対するツールの呼び出しを回避するようにモデルを訓練するために、我々はまた、ツールを使用しないが、システムキューがツールをアクティブにする、簡単な計算または質問と回答のデータセット(Berant et al. 2013; Koncel-Kedziorski et al. 2016; Joshi et al. 2017; Amini et al. 2019)からのクエリとその応答を追加した。はツールを作動させた。
ゼロサンプルのツール使用データ。 Llama 3のゼロサンプルツール(関数呼び出しとしても知られる)の使用能力を、部分的な構成(関数定義、ユーザークエリ、対応する呼び出し)の大規模かつ多様なタプルを微調整することで向上させる。このモデルを未知のツールのコレクションで評価する。
- 単一、入れ子、並列の関数呼び出し: 呼び出しは、単純なもの、ネストされたもの(つまり、関数呼び出しを別の関数の引数として渡す)、並列のもの(つまり、モデルが独立した関数呼び出しのリストを返す)がある。様々な関数、クエリ、実際の結果を生成することは困難であり(Mekala et al.、2024)、我々はスタックのマイニング(Kocetkov et al.、2022)に依存して、実際の関数に合成ユーザークエリを基づかせる。より正確には、関数呼び出しとその定義を抽出し、それらをクリーンにしてフィルタリングし(例えば、ドキュメント文字列の欠落や実行不可能な関数)、Llama 3を使用して関数呼び出しに対応する自然言語クエリを生成します。
- 複数ラウンドの関数呼び出し: また、Li et al. (2023b)で提示されたものと同様のプロトコルに従い、関数呼び出しを含むマルチラウンドダイアログの合成データを生成する。我々は複数のエージェントを用いて、ドメイン、API、ユーザークエリ、APIコール、レスポンスを生成し、生成されたデータが様々な異なるドメインと実際のAPIをカバーすることを保証する。全てのエージェントはLlama 3の亜種であり、それぞれの責任に依存する方法でプロンプトを表示し、段階的に協力する。
4.3.6 事実関係
大規模な言語モデルにとって、非現実性は依然として大きな課題である。モデルは、知識が不足しているドメインであっても、過信する傾向がある。このような欠点があるにもかかわらず、モデルはしばしば知識ベースとして使用され、誤った情報の拡散といった危険な結果を招きかねない。私たちは、真実性が錯覚を超越したものであることを認識しながらも、ここでは錯覚を第一に考えるアプローチをとる。
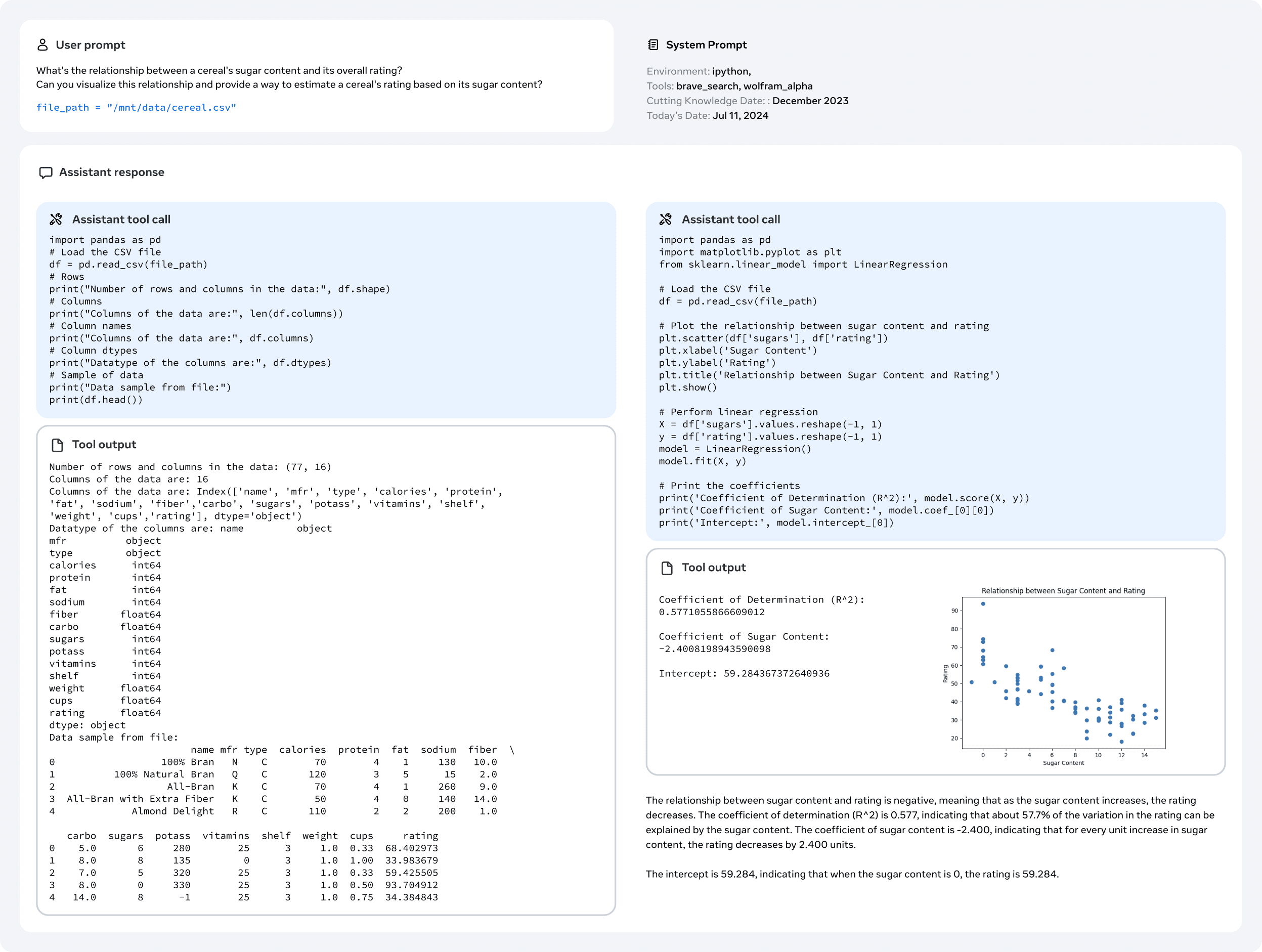
図11 ファイルのアップロード処理。この例は、Llama 3がアップロードされたファイルをどのように分析し、視覚化するかを示している。
我々は、ポストトレーニングは知識を追加するのではなく、「モデルが知っていることを知る」ようにモデルを調整すべきであるという原則に従っている(Gekhman et al., 2024; Mielke et al.)我々の主なアプローチは、モデル生成を事前学習データに存在する実データのサブセットに合わせるデータを生成することである。この目的のために、我々はLlama 3のコンテキスト機能を利用した知識検出技術を開発した。このデータ生成プロセスは以下のステップで構成される:
- 事前学習データからデータセグメントを抽出する。
- ラマ3世に促しながら、これらのセグメント(文脈)に関する事実関係の質問を作成する。
- この質問に対するラマ3世の回答例。
- オリジナルのコンテクストが参照として使われ、ラマ3が生成の正しさを採点するジャッジとして使われた。
- ラマ3を評価者として使用し、生成されたリッチネスを採点する。
- 複数の世代にわたって一貫して有益かつ不正確な回答に対する拒否理由を生成し、ラマ3を使用する。
知識プローブから生成されたデータを使用し、モデルが知っている質問にのみ答え、確信の持てない質問には答えないように促す。さらに、事前学習データは、必ずしも事実に一貫性があるとは限らず、正しいとは限らない。そのため、事実と矛盾する、あるいは正しくない発言が多いデリケートなトピックを扱った、ラベル付きの真実性データも限定的に収集した。
4.3.7 制御性
制御性とは、開発者やユーザーのニーズを満たすために、モデルの動作や結果を制御する能力のことである。Llama 3は汎用的なベースモデルであるため、下流のさまざまなユースケースに対応させることが容易でなければなりません。Llama 3の制御性を向上させるために、私たちは、特に応答の長さ、書式、声のトーン、および役割/キャラクターの設定に関して、(自然言語コマンドを使用した)システムプロンプトによる制御性の強化に焦点を当てました。
データ収集。 一般英語のカテゴリーにおいて、アノテーターにLlama 3用のさまざまなシステムプロンプトを設計してもらい、制御性選好のサンプルを収集しました。その後、アノテーターはモデルを対話に参加させ、対話を通してモデルがシステムプロンプトで定義された指示に一貫して従うことができたかどうかを評価しました。以下は、制御性を高めるためにカスタマイズされたシステムプロンプトの例です:
"あなたは、忙しい家族のための食事計画アシスタントとして役立つ、親切でエネルギッシュなAIチャットボットです。平日の食事は手早く簡単であるべきです。シリアルやイングリッシュマフィンに調理済みのベーコンなど、朝食や昼食には手早く簡単に作れる食品が優先されるべきです。この家族は忙しい。コーヒーやエナジードリンクなど、必需品や好きな飲み物が手元にあるかどうか必ず聞いて、買い忘れがないようにしましょう。特別な日でない限り、予算を節約することを忘れないでください。"
モデリング。 嗜好データを収集した後、このデータを報酬モデリング、拒絶サンプリング、SFT(連続微調整)、DPO(データ駆動型パラメータ最適化)に使用し、ラマ3の制御性を高める。
5 結果
私たちはLlama 3の広範な評価を実施し、(1)事前学習済み言語モデル、(2)事後学習済み言語モデル、(3)Llama 3のセキュリティ機能の性能を調査しました。これらの評価結果は、以下のサブセクションに分けて紹介する。
5.1 言語モデルの事前学習
本節では、事前に学習させたLlama 3(第III部)の評価結果を報告し、同規模の他のモデルと比較する。競合モデルの結果は可能な限り再現する。Llama以外のモデルについては、公表されている結果や(可能であれば)私たち自身が再現した結果のベストスコアを報告します。ショット数、メトリクス、その他の関連するハイパーパラメータや設定などの構成を含む、これらの評価の具体的な詳細は、Githubリポジトリで入手可能です: [ここにリンクを挿入]。さらに、公開ベンチマーク評価の一環として生成されたデータも公開します。
標準的なベンチマークに対するモデル品質の評価(セクションV 5.1.1)、複数選択設定の変化に対する頑健性のテスト(セクションV 5.1.2)、敵対的評価(セクションV 5.1.3)を行う。また、訓練データの汚染がどの程度評価に影響するかを推定するために、汚染分析も行う(セクションV 5.1.4)。
5.1.1 標準ベンチマーク
我々のモデルを現在の最先端技術と比較するため、以下に示す多数の標準ベンチマークテストでLlama 3を評価した:
(1)常識的推論、(2)知識、(3)読解力、(4)数学、推論、問題解決、(5)長い文脈、(6)コード、(7)逆境評価、(8)総合評価。

実験セットアップ。各ベンチマークについて、Llama 3のスコアと、同等のサイズを持つ他の事前学習済みモデルのスコアを計算する。可能であれば、独自のパイプラインを使用して他のモデルのデータを再計算します。公正な比較を確実にするため、計算されたデータとそのモデルによって報告された数値(同じか、より保守的な設定を使用)の間で最も良いスコアを選択します。私たちの評価設定に関するより詳細な情報は、こちらをご覧ください。モデルによっては、ベンチマーク値を再計算することができないものもあります。例えば、事前に訓練されたモデルが公表されていなかったり、APIが対数確率へのアクセスを提供していなかったりするためです。これは特に、Llama 3 405Bに匹敵するすべてのモデルに当てはまります。したがって、Llama 3 405Bのカテゴリー平均は報告していません。これは、すべてのベンチマーク値が利用できる必要があるためです。
有意値。ベンチマークのスコアを計算する際、少数のデモ、ランダムなシード、バッチサイズなど、ベンチマークが測定しようとするモデルの性能の不正確な推定につながる可能性のある分散の原因がいくつかあります。このため、あるモデルが他のモデルよりも統計的に有意に優れているかどうかを理解するのは困難である。そのため、ベンチマークデータの選択によってもたらされる分散を反映するために、95%信頼区間(CI)とともにスコアを報告する。95%信頼区間は、式(Madaan et al., 2024b)を用いて解析的に計算した:

CI_analytic(S) = 1.96 * sqrt(S * (1 - S) / N)
ここで、Sは好ましいベンチマークスコア、Nはベンチマークのサンプルサイズである。ベンチマークデータの分散だけが分散の原因ではないため、これらの95% CIは、実際の能力推定値の分散に対する下界であることに注意されたい。単純平均でない指標については、CIは省略されます。
ラマ3 8Bおよび70Bモデルの結果。図 12 は、常識推論、知識、読解、数学と推論、コード・ベンチマーク・テストにおける Llama 3 8B と 70B の平均成績を示す。その結果、Llama 3 8B は、カテゴリー別勝率と平均成績の両面で、ほぼすべてのカテゴリーで競合モデルを上回っている。また、Llama 3 70Bは、飽和している可能性のあるコモンセンス・ベンチマークを除き、ほとんどのベンチマークにおいて、前モデルであるLlama 2 70Bよりも大幅に性能が向上していることがわかります。Llama 3 70Bは、Mixtral 8x22Bも上回っています。
8Bと70Bのモデル結果。図 12 は、コモンセンス推論、知識、読解、数学と推論、およびコード・ベンチマーク・テストにおける Llama 3 8B と 70B の平均パフォーマンスを示しています。その結果、Llama 3 8Bは、カテゴリー別の勝率とカテゴリーごとの平均成績の両方において、ほぼすべてのカテゴリーで競合モデルを上回っていることがわかった。また、Llama 3 70Bは、飽和状態に達したと思われるCommon Sense Benchmarkを除くほとんどのベンチマークで、前モデルのLlama 2 70Bを大きく上回っていることがわかりました。Llama 3 70Bは、Mixtral 8x22Bも上回っています。
全モデルの詳細結果。表9、10、11、12、13、14は、読解タスク、コーディングタスク、一般知識理解タスク、数学的推論タスク、ルーチンタスクに対する、事前学習済みLlama 3 8B、70B、405Bモデルのベンチマークテストのパフォーマンスを示している。これらの表は、ラマ3のパフォーマンスを同サイズのモデルと比較したものです。この結果から、Llama 3 405Bはこのカテゴリにおいて競争力があり、特に以前のオープンソースモデルを大きく上回っていることがわかります。長いコンテクストを含むテストについては、セクション 5.2 でより包括的な結果(needle-in-a-haystack のような検出タスクを含む)を示している。


5.1.2 モデルの頑健性
ベンチマーク性能に加えて、ロバスト性は事前学習済み言語モデルの品質を左右する重要な要素である。我々は、多肢選択問題(MCQ)設定における事前学習済み言語モデルの設計選択の頑健性を調査する。例えば、モデルのスコアや順位は、文脈例の順序やラベル付けによって変化することがある(Lu et al.2024)、プロンプトの正確な形式(Weber et al., 2023b; Mishra et al., 2022)、または回答の選択肢の形式と順序(Alzahrani et al., 2024; Wang et al., 2024a; Zheng et al., 2023)。この研究に触発され、我々はMMLUベンチマークを用いて、(1)少数ショットのラベル付けバイアス、(2)ラベル付けのバリエーション、(3)答えの順序、(4)キューの形式に対する事前学習済みモデルの頑健性を評価する:
- いくつかのレンズラベルが外れている。 Zhengら(2023)に従い、...。(実験の詳細と結果の説明は省略する)。
- ラベルのバリエーション。 また、選択されたトークンの異なるセットに対するモデルの応答も調べた。Alzahraniら(2024)が提案した2つのタグセットを検討した。すなわち、言語に依存しない一般的なタグセット($ & # @)と、暗黙の相対順序を持たないまれなタグセット(oe § з ü)である。また、2つの正規タグ(A. B. C. D.とA) B) C) D))と数字のリスト(1. 2. 3. 4.)も考慮する。
- 回答順。 Wangら(2024a)に従い、異なる解答順序における結果の安定性を計算する。そのために、データセットのすべての答えを一定の順列に従って再マッピングする。例えば、A B C Dの順列の場合、AとBとラベル付けされたすべての選択肢はそのラベルを維持し、Cとラベル付けされたすべての選択肢はDとラベル付けされます。
- キューのフォーマット。 ある手がかりは単に質問に答えるようモデルに求めるものであり、他の手がかりはモデルの専門知識を主張するものであったり、モデルが最良の答えを選択するよう求めるものであったりする。

表11 一般知識理解課題における事前学習済みモデルのパフォーマンス。結果は95%信頼区間を含む。

表12 数学および推論タスクにおける事前学習済みモデルのパフォーマンス。結果は95%信頼区間を含む。

表13 汎用言語タスクにおける事前学習済みモデルの性能。結果は95%信頼区間を含む。

図13 MMLUベンチマークにおける、異なるデザイン選択に対する事前学習済み言語モデルのロバストネス。左側:異なるラベル付けバリエーションでの性能。右側:サンプルが少ない例で異なるラベルが存在する場合の性能。

図14 MMLUベンチマークテストにおける、異なるデザイン選択に対する事前学習済み言語モデルのロバストネス。左側:異なる回答シーケンスに対する性能。右側:異なるプロンプト形式に対する性能。
図13は、ラベルのバリエーション(左)と少数ショットのラベルの偏り(右)に対するモデル性能の頑健性を調査した実験結果を示しています。この結果から、我々の事前訓練された言語モデルは、MCQラベルのバリエーションに対しても、少数ショットの手がかりラベルの構造に対しても、非常に頑健であることがわかる。この頑健性は、特に405Bパラメトリックモデルにおいて顕著である。
図14は、回答順序とキュー形式の頑健性に関する研究結果を示している。これらの結果は、私たちが事前に訓練した言語モデルの性能の頑健性、特にLlama 3 405Bの頑健性をさらに強調しています。

5.1.3 敵対的ベンチマーキング
上記のベンチマークテストに加えて、質問と回答、数学的推論、文の書き換え検出の3つの領域で、いくつかの敵対的ベンチマークを評価した。これらのテストは、特にチャレンジングに設計されたタスクにおけるモデルの能力を調査するために設計されており、ベンチマークテストにおけるモデルのオーバーフィッティングの問題を指摘する可能性がある。
- 質問と回答我々は、Adversarial SQuAD(Jia and Liang, 2017)とDynabench SQuAD(Kiela et al, 2021)を使用した。
- 数学的推論GSM-Plus(Liら、2024c)を使用した。
- 文の書き換えテストの側面我々はPAWS(Zhang et al.)
図15は、敵対的ベンチマークテストにおけるLlama 3 8B、70B、405Bのスコアを、非敵対的ベンチマークテストにおけるパフォーマンスの関数として示している。我々が使用する非敵対的ベンチマークテストは、質問と回答のSQuAD(Rajpurkar et al.、2016)、数学的推論のGSM8K、文の書き換え検出のQQP(Wang et al.、2017)である。各データポイントは、敵対的データセットと非敵対的データセットのペア(例えば、QQPとPAWSのペア)を表し、カテゴリ内で可能な全てのペアを示す。対角線上の黒い線は、敵対的データセットと非敵対的データセットの間のパリティを示し、この線は敵対的・非敵対的の区別なくモデルが同様の性能を持つことを示す。
文の韻律検出に関しては、事前学習済みモデルも事後学習済みモデルも、PAWS構成要素の敵対的性質の影響を受けていないようであり、これは前世代のモデルに比べて大きな改善である。この結果は、Weberら(2023a)の発見を裏付けるものであり、彼らは、いくつかの敵対的なデータセットにおいて、大規模な言語モデルの方が偽の相関に対する感度が低いことも発見している。しかし、数学的推論と質問応答では、敵対的な性能は非敵対的な性能よりも著しく低い。このパターンは、訓練前モデルと訓練後モデルの両方に当てはまる。
5.1.4 汚染分析
ベンチマークスコアが事前学習コーパスの評価データの汚染によってどの程度影響を受けるかを推定するために汚染分析を行った。Singhら(2024)による研究を参照されたい。その結果、私たちの事前訓練された言語モデルは、多肢選択問題のラベリングのばらつきや、サンプルの少ない手がかりラベルの構造のばらつき(2024で概説)に対して非常に頑健であることが示されました。偽陽性や偽陰性はどのようなアプローチでも起こりうるため、どのように汚染分析を行うのがベストなのかは、まだ未解決の研究分野である。ここでは、主にSinghら(2024)の推奨に従っている。


方法:具体的には、Singh et al. (2024)は、「クリーン」なデータセットとデータセット全体との間で、どの手法が最大の差をもたらすかに基づいて、汚染検出手法を経験的に選択することを提案している。全ての評価データセットにおいて、Singhら(2024)が多くのデータセットで正確であることを発見した8-gram overlapに基づいてスコアリングを行った。データセットDのラベル付けTD そのうちの何割かは、事前学習コーパスに少なくとも1回は出現する。各データセットごとにTDどの値が(3つのモデルサイズにわたって)最大の推定性能向上を示すかによる。
結果表15は、すべての主要ベンチマークについて、上述のように推定性能ゲインを最大にするために汚染されていると考えられる評価データの割合を示している。この表から、清浄または汚染されていないプールサンプルが少なすぎる、または観測された性能向上推定値が極端に不安定な挙動を示すなど、結果が有意でないベンチマークの数値は除外した。
表15を見ると、汚染が大きな影響を与えるデータセットもあれば、そうでないデータセットもあることがわかる。たとえば、PiQAとHellaSwagでは、汚染推定値とパフォーマンス向上推定値の両方が高い。一方、Natural Questionsでは、推定された52%の汚染はパフォーマンスにほとんど影響を与えないようです。SQuADとMATHでは、低いしきい値は高いレベルのコンタミネーションをもたらしますが、パフォーマンスの向上は見られません。このことから、これらのデータセットでは、コンタミネーションは役に立たないか、より良い推定値を得るためにはより大きなnが必要であることが示唆される。最後に、MBPP、HumanEval、MMLU、およびMMLU-Proについては、他の汚染検出方法が必要かもしれない:高いしきい値でも、8-gramの重複は汚染スコアが高く、性能向上の良い推定値が得られない。
5.2 言語モデルの微調整
異なる能力を持つベンチマークテストでのトレーニング後のLlama 3モデルの結果を示します。事前学習と同様に、Huggingface(ここにリンクを挿入)で見つけることができる一般に利用可能なベンチマークに、評価の一部として生成されたデータを公開します。私たちの評価セットアップに関するより詳細な情報は、ここ(ここにリンクを挿入)にあります。
ベンチマーキングと指標。表16は、すべてのベンチマークテストを能力別にまとめたものである。各ベンチマークテストのキューと完全に一致させることで、トレーニング後のデータを除染する。標準的なアカデミックベンチマークテストに加えて、さまざまな能力について広範な手動評価も行った。詳細はセクション5.3を参照。
実験セットアップ。事前学習段階と同様の実験セットアップを使用し、同等のサイズと能力を持つ他のモデルと比較してラマ3を分析する。可能であれば、他のモデルのパフォーマンスを私たち自身で評価し、その結果を報告された数値と比較して、最良のスコアを選択します。私たちの評価セットアップに関するより詳細な情報は、こちらをご覧ください(リンクはこちらに挿入されています)。

表16 訓練後のカテゴリー別ベンチマークテスト。トレーニング後のLlama 3モデルを評価するために使用したすべてのベンチマークテストの概要を、能力別に分類した。
5.2.1 一般的な知識と指導のコンプライアンス・ベンチマーク
私たちは、表2に示したベンチマークを使用して、一般的な知識と指示の順守という観点からラマ3の能力を評価した。
一般常識: MMLU (Hendrycks et al., 2021a)とMMLU-Pro (Wang et al., 2024b)を使って、ラマ3の知識ベースの質問能力を評価しました。MMLU-ProはMMLUの拡張版で、より難しい推論に焦点を当てた問題を含み、ノイジーな問題を排除し、選択肢の範囲を4つから10つに広げています。MMLU-Proは複雑な推論に重点を置いているため、MMLU-ProのCoTの例を5つ報告する。 全てのタスクはsimple-evals (OpenAI, 2024)に似た生成タスクとしてフォーマットされている。
表2に示すように、我々の8Bと70BのLlama 3亜種は、両方の一般知識タスクにおいて、他の同様のサイズのモデルを上回った。私たちの405BモデルはGPT-4とNemotron 4 340Bを上回り、Claude 3.5 Sonnetはより大きなモデルでリードしています。
指示に従ってください: IFEvalは、ヒューリスティックスを用いて検証可能な、「400語以上で書け」といった「検証可能な指示」約500個で構成されている。IFEvalには、ヒューリスティックスを用いて検証可能な「400語以上で書け」といった「検証可能な指示」が約500個含まれている。厳密な制約と緩い制約の下でのプロンプトレベルと命令レベルの精度の平均を表2に報告する。すべてのLlama 3は、IFEvalにおいて同等のモデルを凌駕している。
5.2.2 コンピテンシー試験
次に、もともと人間をテストするために設計された一連の適性テストで、我々のモデルを評価する。いくつかの試験については、それぞれの適性検査の結果として、異なる試験セット間の平均点を報告する。具体的には、平均点を算出する:
- GRE:Educational Testing Serviceが提供する公式のGRE模擬試験1および2;
- LSAT:公式プレテスト71点、73点、80点、93点;
- SAT:『The Official SAT Study Guide, 2018 Edition』の8つの試験;
- AP:1科目につき1回の公式模擬試験;
- GMAT: GMAT公式オンラインテスト。
これらの試験の問題には、多肢選択問題と生成問題が含まれます。画像が添付されている問題は除外します。複数の正しい選択肢を含むGREの問題については、モデルがすべての正しい選択肢を選択した場合のみ、出力を正しいと認定します。複数の試験セットがある場合、評価には少数のヒントを使用します。130-170の範囲(GREの場合)にスコアを調整し、他のすべての試験の精度を報告します。

その結果を表17に示す。我々のLlama 3 405Bモデルは、次のような結果となった。 クロード 3.5ソネットはGPT-4 4oによく似ている。一方、私たちの70Bモデルは、さらに素晴らしい性能を示しています。GPT-3.5ターボを大幅に上回り、多くのテストでネモトロン4 340Bを上回る。
5.2.3 コーディング・ベンチマーク
Llama3のコード生成能力を、Pythonと多言語プログラミングのベンチマークで評価する。機能的に正しいコードを生成するモデルの有効性を測定するために、N世代のセットに対する単体テストの合格率を評価するpass@Nメトリックを使用する。pass@1の結果を報告する。


Pythonコード生成。 HumanEval (Chen et al., 2021)とMBPP (Austin et al., 2021)は、比較的単純で自己完結的な機能に焦点を当てた、人気のあるPythonコード生成ベンチマークです。MBPP EvalPlusベンチマークバージョン(v0.2.0)は、オリジナルのMBPP(トレーニングおよびテスト)データセットに含まれる974の初期問題のうち、378のよくフォーマットされた問題(Liu et al.これらのベンチマークテストの結果を表18に示す。これらのPythonの亜種のベンチマークでは、Llama 3 8Bと70Bは同じサイズのモデルで同様のパフォーマンスをするモデルを上回った。最も大きなモデルでは、Llama 3 405B、Claude 3.5 Sonnet、GPT-4o が同程度の性能を示し、GPT-4o が最も強い結果を示しました。
モデル ラマ3を同サイズの他のモデルと比較した。最も大きなモデルであるLlama 3 405B、Claude 3.5 Sonnet、GPT-4oは同様のパフォーマンスを示し、GPT-4oが最も良い結果を示した。
マルチプログラミング言語のコード生成: Python以外の言語のコード生成能力を評価するために、HumanEvalとMBPPの問題の翻訳に基づくMultiPL-E(Cassano et al.、2023)ベンチマークの結果を報告します。表19は、一般的なプログラミング言語を選択した場合の結果です。
表18では、Pythonと比較してパフォーマンスが大幅に低下していることに注意してください。
5.2.4 多言語ベンチマーク
Llama 3は、英語、ドイツ語、フランス語、イタリア語、ポルトガル語、ヒンディー語、スペイン語、タイ語の8言語をサポートしているが、ベースモデルはより多くの言語セットを使って学習された。表20に、多言語MMLU (Hendrycks et al., 2021a)と多言語初等数学(MGSM) (Shi et al., 2022)ベンチマークにおけるLlama 3の評価結果を示す。
- 多言語MMLUMMLUの問題、短い例題、解答を異なる言語に翻訳するためにGoogle翻訳を使用した。タスクの説明は英語にしておき、5ショットの設定で評価した。
- MGSM(Shi et al.)私たちのLlama 3モデルでは、MGSMの0ショットCoT結果を報告しています。多言語MMLUは、MMLU (Hendrycks et al., 2021a)の質問と回答を7つの言語に翻訳する内部ベンチマークです。
MGSM (Shi et al., 2022)では、simple-evals (OpenAI, 2024)と同じネイティブのプロンプトを使用し、0ショットのCoT環境でモデルをテストした。表 20 では、MGSM ベンチマークに含まれる全言語の平均結果を示す。

MGSMでは、Llama 3 405Bが平均91.61TP3 Tと他のほとんどのモデルを上回った。MMLUでは、Llama 3 405BがGPT-4oに21TP3 T遅れをとった。両タスクで
5.2.5 数学と推論のベンチマーク
Llama3の8Bモデルは、GSM8K、MATH、GPQAにおいて、同じサイズの他のモデルを凌駕している。Llama3の70Bモデルは、すべてのベンチマークテストにおいて、他のモデルを大きく上回っています。最後に、Llama 3 405Bモデルは、GSM8KとARC-Cでは同カテゴリーの中で最も優れたモデルであり、MATHでは2番目に優れたモデルです。GPQAでは、GPT-4 4oと良い競争をしており、クロード3.5ソネットは大差をつけてトップである。
5.2.6 ロングコンテキストベンチマーク
我々は様々なドメインとテキストタイプにわたる様々なタスクを検討する。以下のベンチマークでは、偏りのない評価プロトコルを使用するサブタスク、つまりn-gramオーバーラップメトリクスではなく、精度に基づいたメトリクスを使用するサブタスクに焦点を当てる。また、分散が少ないタスクに優先順位をつける。
- ニードル・イン・ア・ヘイスタック(カムラット、2023年) 長い文書のランダムな部分に隠された情報を検索するモデルの能力を測定する。我々のLlama 3モデルは完璧な針検索性能を示し、全ての文書の深さと文脈の長さにおいて100%の「針」の検索に成功した。また、Needle-in-a-HaystackのバリエーションであるMulti-needle(表21)の性能も測定した。ここでは、4本の「針」を文脈に挿入し、そのうちの2本をモデルが検索できるかどうかをテストした。我々のLlama 3モデルはほぼ完璧な検索結果を達成した。
- ZeroSCROLLS(シャハムら、2023年)は長文の自然言語理解のためのゼロ標本ベンチマークテストである。真の解答は公開されていないため、検証セットの数値を報告する。我々のLlama 3 405Bと70Bのモデルは、このベンチマークテストの様々なタスクにおいて、他のモデルと同等かそれ以上の結果を出しています。
- InfiniteBench (Zhang et al., 2024) コンテクストウィンドウの長距離依存関係を理解するためにはモデルが必要である。En.QA(小説に関するクイズ)とEn.MC(小説に関する多肢選択クイズ)でLlama 3を評価したところ、我々の405Bモデルが他の全てのモデルを上回った。特にEn.QAで顕著である。

表21 長文のベンチマーク。ZeroSCROLLS (Shaham et al., 2023)については検証セットの結果を報告する。QuALITYでは完全一致、Qasperではf1、SQuALITYではrougeLを報告する。InfiniteBench (Zhang et al., 2024)のEn.QAメトリクスではf1、En.MCでは精度を報告する。Multi-needle(Kamradt,2023)については、コンテキストに4本の針を挿入し、モデルが異なるコンテキスト長の2本の針を検索できるかどうかをテストし、10個のシーケンス長の128kまでの平均リコール量を計算する。
5.2.7 ツールの性能
Nexus(Srinivasan他、2023)、API-Bank(Li他、2023b)、Gorilla API-Bench(Patil他、2023)、Berkeley Function Call Leaderboard (BFCL)(Yan他、2024)がある。結果を表22に示す。
Nexusでは、当社のLlama 3が最高のパフォーマンスを発揮し、同カテゴリーの他モデルを凌駕しています。 API-Bankでは、Llama 3 8Bと70Bがそれぞれのカテゴリーで他のモデルを大きく上回っています。 405Bモデルは、クロード3.5ソネット0.6%の後塵を拝しています。最後に、405Bと70Bモデルは、BFCLで優れた性能を発揮し、それぞれのサイズ・カテゴリーで2位にランクされています。 Llama 3 8Bは、そのカテゴリーで最高のパフォーマンスだった。
また、コード実行タスクに焦点を当て、モデルのツール使用能力をテストするための手動評価も実施した。 コード実行に関連する 2000 件のユーザープロンプト、図面生成、ファイルアップロードを収集した(図面やファイルアップロードは含まれない)。これらのプロンプトは LMSys データセット(Chiang et al., 2024)、GAIAベンチマーク(Mialon et al., 2023b)、人間のアノテーター、合成生成。OpenAIのAssistants API10 を使って、Llama 3 405BとGPT-4oを比較した。結果を図16に示す。Llama 3 405B は、テキストのみのコード実行タスクと描画生成では GPT-4o を明らかに上回ったが、ファイル・アップロードのユースケースでは GPT-4o に遅れをとった。

5.3 手動評価
標準的なベンチマークデータセットでの評価に加え、一連の人間による評価も行った。これらの評価により、モデルのトーン、冗長性のレベル、ニュアンスや文化的文脈の理解など、モデルのパフォーマンスのより微妙な側面を測定し、最適化することができる。注意深く設計されたレングレン評価は、ユーザーエクスペリエンスと密接に関連しており、モデルが実世界でどのように機能するかについての洞察を提供します。
https://platform.openai.com/docs/assistants/overview
人間による多ラウンド評価では、各キューのラウンド数は2~11の範囲であった。最後のラウンドでモデルの反応を評価した。
チップコレクション. 我々は、幅広いカテゴリーと難易度をカバーする質の高いプロンプトを収集した。そのために、まず、可能な限り多くのモデル能力に関するカテゴリーとサブカテゴリーを含む分類法を作成した。この分類法を使用して、6 つの単一ラウンド能力(英語、推論、コーディング、 ヒンディー語、スペイン語、ポルトガル語)と 3 つの複数ラウンド能力をカバーする約 7,000 のプロンプトを収集した。11 (英語、推論、コーディング)。各カテゴリの中で、プロンプトがサブカテゴリに均等に分散されるようにした。また、各プロンプトを 3 つの難易度のいずれかに分類し、プロンプトセットに約 10% の簡単なプロンプト、30% の中程度の難易度のプロンプト、60% の難易度のプロンプトが含まれるようにした。すべての人間による評価 図 16 描画とファイルアップロードを含むコード実行タスクにおける Llama 3 405B 対 GPT-4o の人間による評価結果。 Llama 3 405B は、コード実行(描画やファイルアップロードを含まない)と描画生成で GPT-4o を上回ったが、ファイルアップロードのユースケースでは遅れをとった。
キューセットは厳格な品質保証プロセスを経ています。偶発的な汚染やテストセットのオーバーフィッティングを防ぐため、モデリングチームは人間の評価キューにアクセスすることはできません。
評価プロセス.2つのモデルの対の人間評価を行うために、(異なるモデルによって生成された)2つのモデルの応答のどちらを好むかを人間のアノテーターに尋ねる。アノテーターは、一方のモデル応答が他方のモデル応答よりはるかに優れているか、優れているか、少し優れているか、または同じくらいかを示すことができる7点スケールを使用します。アノテーターが、あるモデルのレスポンスが他のモデルのレスポンスよりずっと良い、または良いと示した場合、そのモデルの「勝利」と見なします。モデルをペアで比較し、キューセットの各能力の勝率を報告する。
結局. Llama 3 405B と GPT-4 (0125 API バージョン)、GPT-4o (API バージョン)、Claude 3.5 Sonnet (API バージョン)を人間による評価プロセスで比較した。これらの評価結果を図17に示す。Llama 3 405B は GPT-4o および Claude 3.5 Sonnet と比較した場合、GPT-4 の 0125 API バージョンとほぼ同等の性能を発揮し、結果はまちまち(勝ったり負けたり)であることがわかります。ほとんどすべての能力において、Llama 3とGPT-4は誤差の範囲内で勝っている。Llama 3 405Bは、多言語(ヒンディー語、スペイン語、ポルトガル語)のプロンプトではGPT-4を上回ったが、多言語(ヒンディー語、スペイン語、ポルトガル語)のプロンプトでは上回らなかった。Llama 3は、英語のプロンプトではGPT-4と同等の性能を発揮し、多言語のプロンプトではClaude 3.5 Sonnetと同等の性能を発揮し、英語のプロンプトでは1ラウンドと多ラウンドの両方で上回った。しかし、符号化や推論などの分野ではClaude 3.5 Sonnetに及ばない。定性的には、人間による評価におけるモデルの性能は、声のトーン、応答の構造、冗長性のレベルなどの微妙な要因に大きく影響されることがわかった。最適化されている要素Llama 3 405Bは、業界をリードするモデルと非常によく競い合っており、一般に公開されているモデルの中では最高のパフォーマンスとなっています。
制限. すべての人間による評価結果は、厳格なデータ品質保証プロセスを経ている。しかし、モデルの応答に関する客観的な基準を定義することは困難であるため、人間による評価は、アノテーターの個人的なバイアス、背景、嗜好に影響される可能性があり、一貫性のない、または信頼できない結果につながる可能性があります。

図16 コード実行タスク(プロットとファイル・アップロードを含む)におけるLlama 3 405BとGPT-4oの人間による評価結果。 Llama 3 405Bは、コード実行(プロットとファイルアップロードを除く)とプロット生成でGPT-4oを上回っていますが、ファイルアップロードのユースケースでは遅れをとっています。

図17 ラマ3 405Bモデルの手動評価結果。左:GPT-4との比較。中央:GPT-4oとの比較。右:クロード3.5ソネットとの比較。すべての結果は95%信頼区間を含み、同値は含まない。
5.4 セキュリティ
セキュリティー・セクションには機密用語が含まれているので、スキップするかPDFでダウンロードしてください!
6 推論
我々は、Llama 3 405Bモデルの推論効率を向上させるために、(1)パイプライン並列化、(2)FP8量子化の2つの主要な手法を研究している。我々はFP8量子化の実装を公開した。
6.1 パイプライン並列
Llama 3 405Bモデルは、モデルパラメータを表現するためにBF16を使用すると、8つのNvidia H100GPUを搭載した1台のマシンのGPUメモリに収まりません。この問題に対処するため、BF16精度を使用して、2台のマシンの16個のGPU間でモデル推論を並列化しました。各マシン内では、高帯域幅のNVLinkがテンソル並列の使用を可能にします(Shoeybi et al.)しかし、ノード間の接続は帯域幅が低く、レイテンシが高いため、パイプライン並列を使用します(Huang et al.)
バブルは、パイプライン並列を使用した学習時には大きな効率上の問題となる(セクション3.3参照)。しかし、推論ではパイプラインフラッシュを必要とするバックプロパゲーションを伴わないため、推論時には問題とならない。そこで、マイクロバッチングを用いてパイプライン並列推論のスループットを向上させる。
入力トークンが4,096個、出力トークンが256個の推論ワークロードにおいて、推論のキーバリューキャッシュのプレポプレーションフェーズとデコーディングフェーズで、それぞれ2つのマイクロバッチを使用した場合の効果を評価した。図24を参照。これらの改善は、マイクロバッチが両方のフェーズでマイクロバッチを同時実行できることに起因する。マイクロバッチングは同期ポイントを増やすため、レイテンシも増加させるが、全体としては、マイクロバッチングの方がスループットとレイテンシのトレードオフを改善する。


6.2 FP8 定量化
H100 GPUに内在するFP8サポートを用いて、低精度推論実験を行った。低精度推論を実現するために、モデル内の行列乗算のほとんどにFP8量子化を適用した。具体的には、推論計算時間の約50%を占めるモデルのフィードフォワードネットワーク層のパラメータと活性化値の大部分を定量化した。我々は精度を向上させるために動的スケーリング係数を利用し(Xiao et al., 2024b)、計算スケーリングオーバーヘッドを削減するためにCUDAカーネル15を最適化した。
我々は、Llama 3 405Bの品質がある種の定量化に敏感であることを発見し、モデル出力の品質を向上させるためにいくつかの追加変更を行った:
- Zhangら(2021)と同様に、我々は最初と最後のトランスフォーマー層を定量化しなかった。
- 高度に整列されたトークン(日付など)は、活性化値が大きくなる可能性があります。その結果、FP8 では動的スケーリング係数が高くなり、無視できない量の浮動小数点アンダー フローが発生してデコーディング・エラーにつながる可能性がある。図 26 に、BF16 および FP8 推論を使用した Llama 3 405B の報酬スコア分布を示す。FP8 の定量化手法は、モデルの応答にほとんど影響を与えません。
この問題を解決するため、ダイナミック・スケーリング・ファクターの上限を1200に設定した。
- パラメータ行列と活性化行列の行をまたぐスケーリング係数を計算するために、行ごとの定量化を用いた(図25参照)。この方法は、テンソルレベルの定量化アプローチよりもうまくいくことがわかった。
エラーの影響を定量化する。標準的なベンチマークの評価では、このような緩和がなくても、FP8推論はBF16推論に匹敵する性能を示すのが一般的である。しかし、このようなベンチマークでは、FP8 の定量化の影響が適切に反映されていないことが判明した。スケーリングファクターに上限がない場合、ベンチマーク性能が高くても、モデルが破損した応答を生成することがある。
定量化による分布の変化を測定するためにベンチマークに頼るのではなく、BF16 と FP8 を使用して生成された 10 万件の回答について、報酬モデルスコアの分布を分析することが可能である。図 26 は、我々の定量化手法によって得られた報酬の分布を示している。この結果から、FP8 の定量化手法がモデル回答に与える影響は非常に限定的であることがわかる。
効率実験評価図27は、Llama 3 405Bを使用し、4,096個の入力トークンと256個の出力トークンを使用して、プリポピュレーションとデコーディングのフェーズでFP8推論を実行した場合のスループットとレイテンシのトレードオフを示している。この図は、FP8推論の効率を、セクション6.1で説明した2マシンBF16推論アプローチと比較したものである。その結果、FP8推論を使用することで、プリポピュレーション段階のスループットが最大50%向上し、デコーディング時のスループットと遅延のトレードオフが大幅に改善されることがわかる。



7 ビジュアル実験
我々は、複合的なアプローチによって視覚認識機能をラマ3に統合するために一連の実験を行った。アプローチは主に2つのフェーズに分かれている:
第一段階。 我々は、事前に訓練された画像エンコーダー(Xu et al.、2023)と事前に訓練された言語モデルを組み合わせ、多数の画像とテキストのペアに対して、クロスアテンションレイヤー(Alayrac et al.、2022)のセットを導入し、訓練した。その結果、図28に示すモデルが得られた。
セカンドステージ。 我々は、ビデオからの時間情報を認識し処理するモデルを学習するために、多数のビデオテキスト対に作用する時間集約層と追加のビデオクロスアテンション層を導入する。
コンビナトリアルアプローチによるベースモデルの構築には、いくつかの利点がある。
(1)視覚的モデリング機能と言語的モデリング機能を並行して開発できる;
(2)視覚データと言語データを共同で事前学習する際に、視覚データのトークン化、モダリティ間の背景の当惑度の違い、モダリティ間の競合などから生じる複雑さを回避できる;
(3) 視覚認識機能の導入が、テキストのみのタスクにおけるモデルの性能に影響を与えないようにする;
(4) クロスアテンションアーキテクチャにより、増え続けるLLMバックボーン(特に各Transformer層のフィードフォワードネットワーク)にフル解像度の画像を渡す必要がなくなり、推論効率が向上する。
なお、我々のマルチモーダルモデルはまだ開発中であり、リリースには至っていない。
第7.6節と第7.7節で実験結果を示す前に、視覚認識能力を訓練するために使用したデータ、視覚コンポーネントのモデル・アーキテクチャ、これらのコンポーネントの訓練を拡張した方法、および訓練前と訓練後のレシピについて説明する。
7.1 データ
画像データとビデオデータを分けて説明する。
7.1.1 画像データ
我々の画像エンコーダーとアダプターは画像とテキストのペアで学習される。このデータセットは、4つの主要な段階からなる複雑なデータ処理パイプラインによって構築される:
(1)品質フィルタリング (2)知覚的ディエンファシス (3)リサンプリング (4)光学式文字認識 .また、さまざまなセキュリティ対策も施している。
- 大量ろ過。 (Radfordら, 2021)によって生成された低いアラインメントスコアのようなヒューリスティックスによって、非英語キャプションや低品質キャプションを除去する品質フィルタを実装した。具体的には、特定のCLIPスコアを下回る画像とテキストのペアをすべて削除する。
- 脱力。 大規模訓練データセットの重複排除は、冗長なデータに対する訓練計算を減らし(Esser et al. 2024; Lee et al. 2021; Abbas et al. 2023)、モデルが記憶されるリスクを減らすため、モデルの性能を向上させる(Carlini et al.)そのため、効率とプライバシーの観点から学習データの重複を排除する。この目的のため、SSCDコピー検出モデル(Pizzi et al.全ての画像について、まずSSCDモデルを用いて512次元の表現を計算する。次にこれらの埋め込みを用いて、コサイン類似度メトリックを用いて、データセットの全画像に対して最近傍(NN)探索を行う。特定の類似度閾値以上の例を重複項と定義する。これらの重複項を連結成分アルゴリズムを用いてグループ化し、各連結成分に対して単一の画像-テキストペアのみを保持する。(1)k-meanクラスタリングを用いてデータを事前にクラスタリングする(2)NN検索とクラスタリングにFAISSを用いる(Johnson et al., 2019)ことで、重複除去パイプラインの効率を向上させる。
- リサンプリング。 Xu et al. (2023); Mahajan et al. (2018); Mikolov et al. (2013)と同様に、画像とテキストのペアの多様性を確保する。まず、高品質のテキストソースを解析してnタプルの文法用語集を構築する。次に、データセット内の各用語集のnタプル文法の頻度を計算する。キャプションのn-タプル文法が用語集の中でT回未満しか出現しない場合、対応する画像-テキストのペアを保持する。そうでなければ、見出しの各n-タプル文法n iを確率T / f iで独立にサンプリングする。ここで、f iはn-タプル文法n iの頻度を表す。この再サンプリングは、低頻度カテゴリや細かい認識タスクの性能向上に役立つ。
- 光学式文字認識。 画像内のテキストを抽出し、キャプションとひもづけることで、画像テキストデータをさらに改良しました。テキストは独自の光学式文字認識(OCR)パイプラインを使用して抽出しました。学習データにOCRデータを追加することで、文書理解などOCR機能を必要とするタスクの性能が大幅に向上することを確認した。
文書理解タスクにおけるモデルのパフォーマンスを向上させるために、文書ページを画像としてレンダリングし、画像とそれぞれのテキストを対にする。文書テキストは、ソースから直接取得するか、文書解析パイプラインを介して取得する。
セキュリティ 私たちの主な焦点は、画像認識の事前学習データセットに、性的虐待素材(CSAM)(Thiel, 2023)のような安全でないコンテンツが含まれていないことを確認することです。私たちは、PhotoDNA(Farid, 2021)のような知覚ハッシュ法、および社内独自の分類器を使用して、すべてのトレーニング画像にCSAMが含まれていないかスキャンします。また、独自のメディアリスク検索パイプラインを使用して、性的または暴力的なコンテンツが含まれているなどの理由でNSFWと考えられる画像とテキストのペアを識別し、削除します。我々は、トレーニングデータセットにおけるそのような素材の有病率を最小化することで、最終モデルの有用性を損なうことなく、安全性と有用性を向上させることができると考えている。最後に、トレーニングセットの全画像に対して顔ぼかしを行う。追加画像を参照する人間が生成したキューに対してモデルをテストした。
アニーリングデータ: 我々は、n-gramを用いて画像キャプションのペアを再サンプリングすることにより、約3億5千万例を含むアニールされたデータセットを作成した。n-gram再サンプリングはより豊かなテキスト記述を好むため、より質の高いデータのサブセットを選択する。さらに、得られたデータを5つの追加ソースからの約1億5千万例で補強した:
-
- 視覚的オリエンテーション。 テキスト中の名詞句を、画像中の境界ボックスまたはマスクに関連付ける。ローカライゼーション情報(バウンディングボックスとマスク)は、以下の2つの方法で画像とテキストのペアで指定される。(1) 画像上にボックスまたはマスクを重ね、マーカーセット(Yang et al., 2023a)と同様に、テキスト内の参照としてマーカーを使用する。(2) 正規化された(x min, y min, x max, y max)座標をテキストに直接挿入し、特別なマーカーで区切る。
- スクリーンショット分析。 HTMLコードからスクリーンショットをレンダリングし、Leeら(2023)と同様に、特定のスクリーンショット要素を生成するコードをモデルに予測させる。関心のある要素は、スクリーンショット内でバウンディングボックスによって示される。
- とのQ&A。 モデルの微調整に使うには多すぎる大量のQ&Aデータを使用できるように、Q&Aペアを含めている。
- 総合的なタイトル この画像には、以前のモデルのバージョンから生成された合成キャプションも含まれている。オリジナルのキャプションと比較すると、合成キャプションの方がより包括的な画像の説明を提供することがわかった。
- 構造化画像の合成 また、図表、フローチャート、数式、テキストデータなど、さまざまな分野の合成生成画像も含まれています。これらの画像には、対応するMarkdownやLaTeX記法などの構造化表現が添えられている。 これらの領域におけるモデルの認識能力を向上させるだけでなく、テキストモデリングを通じて微調整を行うためのQ&Aペアを生成するためにも、このデータが有用であることが分かっています。

図28 本論文で研究したLlama 3にマルチモーダル機能を追加するための複合的アプローチの概略図。 このアプローチでは、言語モデルの事前学習、マルチモーダルエンコーダーの事前学習、視覚アダプターの学習、モデルの微調整、音声アダプターの学習の5段階でマルチモーダルモデルを学習する。
7.1.2 ビデオデータ
ビデオの事前学習には、ビデオとテキストのペアの大規模なデータセットを使用する。このデータセットは多段階のプロセスを経て照合される。 ルールベースのヒューリスティックを用いて、関連するテキストをフィルタリングし、クリーンアップする。次に言語認識モデルを実行し、英語以外のテキストをフィルタリングします。
OCR検出モデルを実行して、テキストが過度に重畳された動画をフィルタリングした。ビデオとテキストのペア間の合理的な整合を確保するために、CLIP(Radford et al.、2021)形式の画像-テキストおよびビデオ-テキスト比較モデルを使用する。 まずビデオからの1フレームを使って画像-テキストの類似度を計算し、類似度の低いペアをフィルタリングし、次にビデオ-テキストのアライメントが悪いペアをフィルタリングする。データの中には静止画や動きの少ない動画も含まれていたため、モーションスコアに基づくフィルタリング(Girdhar et al.)美的スコアや解像度フィルターなど、動画の視覚的品質に対するフィルターは適用していない。
我々のデータセットには中央値16秒、平均21秒の動画が含まれ、99%以上の動画が1分未満である。空間解像度は320pと4Kの間で大きく異なり、70%以上の動画は720ピクセルより大きなショートエッジを持っている。動画のアスペクト比はさまざまで、ほぼすべての動画のアスペクト比は1:2から2:1の間で、中央値は1:1である。
7.2 モデル・アーキテクチャ
私たちの視覚認識モデルは、3つの主要コンポーネントで構成されている:(1)画像エンコーダー、(2)画像アダプター、(3)ビデオアダプター。
画像エンコーダー。
私たちの画像エンコーダは、画像とテキストを整列させるために学習された標準的なVisual Transformer(ViT;Dosovitskiyら(2020))である(Xuら、2023)。 画像エンコーダの入力画像解像度は224×224であり、画像は16×16の等しい大きさのチャンク(すなわち14×14ピクセルのブロックサイズ)に分割される。ViP-Llava(Caiら、2024)などの先行研究で示されたように、テキストに整列されたターゲットを比較して学習した画像エンコーダは、細かい位置情報を保持しないことがわかった。この問題を軽減するために、我々は、最後の層の特徴に加えて、4、8、16、24、31層で特徴を提供する多層特徴抽出アプローチを使用した。
さらに、アライメントに特化した特徴を学習するために、クロスアテンションレイヤーの事前学習の前に、8つのゲーテッドセルフアテンションレイヤー(合計40のTransformerブロック)を挿入した。その結果、画像エンコーダは8億5千万のパラメータと追加レイヤーを持つことになった。 多層の特徴により、画像エンコーダーは生成された16×16=256チャンクのそれぞれについて7680次元の表現を生成する。特にテキスト認識のような分野では、この方が性能が向上することが分かっているため、その後の学習段階では画像エンコーダのパラメータを凍結しない。
画像アダプター。
画像エンコーダーが生成する視覚的マーカー表現と、言語モデルが生成するマーカー表現の間に、クロスアテンションレイヤーを導入する(Alayrac et al.、2022)。クロスアテンションレイヤーは、コア言語モデルの4つ目の自己アテンションレイヤーの後に適用される。 言語モデルそのものと同様に、クロスアテンションレイヤーは一般化されたクエリーアテンション(GQA)を使用して効率を向上させる。
Llama 3 405Bの場合、クロスアテンションレイヤーは約1000億のパラメータを持つ。 画像アダプターの事前訓練は、(1)初期事前訓練と(2)アニーリング*の2段階で行った。 最初の事前トレーニング。 前述の約60億の画像-テキストペアのデータセットで、画像アダプターを事前訓練した。計算効率を向上させるため、全ての画像を最大4つの336×336ピクセルブロックに収まるようにリサイズし、672×672、672×336、1344×336といった異なるアスペクト比をサポートするようにブロックを配置する。 ●画像アダプタは最大4つの336×336ピクセルブロックに収まるように設計されている。 アニーリング。 前述のアニーリングデータセットから約5億枚の画像を用いて画像アダプターの学習を続ける。アニーリングの過程で、インフォグラフィックの理解など、より高解像度の画像を必要とするタスクの性能を向上させるために、各ブロックの画像解像度を上げる。
ビデオアダプター。
我々のモデルは最大64フレーム(完全なビデオから一様にサンプリングされる)の入力を受け入れ、各フレームは画像エンコーダによって処理される。(i)エンコードされたビデオフレームは、32の連続するフレームを1つにまとめる時間的アグリゲータによって1つにまとめられ、(ii)各4番目の画像クロスアテンションレイヤーの前に、追加のビデオクロスアテンションレイヤーが追加される。時間的アグリゲータはパーセプトロン再標本化器(Jaegle et al.) 事前学習では1ビデオあたり16フレーム(1フレームに集約)を使用したが、教師ありの微調整では入力フレーム数を64に増やした。 ビデオアグリゲータとクロスアテンション層のパラメータは、Llama 3 7Bでは0.6億、70Bでは46億である。
7.3 モデルサイズ
Llama 3に視覚認識コンポーネントを追加した後、モデルには自己注意層、交差注意層、ViT画像エンコーダが含まれる。我々は、小規模(パラメータが800億と700億)モデルのアダプタを学習する場合、データ並列性とテンソル並列性の組み合わせが最も効率的であることを発見した。これらのスケールでは、モデルパラメータを収集することが計算を支配するため、モデル並列やパイプライン並列では効率は向上しない。しかし、4,050億パラメータモデルのアダプターをトレーニングする際には、(データ並列とテンソル並列に加えて)パイプライン並列を使用しました。この規模でのトレーニングには、セクション3.3で概説した課題に加えて、モデルの不均一性、データの不均一性、数値的不安定性という3つの新たな課題があります。
モデルの不均一性.あるトークンは他のトークンよりも多くの計算を行うため、モデルの計算は異種混合的である。特に、画像トークンは画像エンコーダーとクロスアテンションレイヤーを通して処理され、テキストトークンは言語バックボーンネットワークを通してのみ処理される。この異種性はパイプラインの並列スケジューリングにおいてボトルネックになる可能性がある。つまり、4つの自己アテンション層と言語バックボーンネットワークの1つのクロスアテンション層である。(4つの自己アテンション層の後にクロスアテンションレイヤーを導入したことを思い出してほしい)。さらに、画像エンコーダを全てのパイプラインステージに複製する。画像とテキストを対にしたデータで学習するため、画像とテキストの計算の負荷バランスをとることができる。
データの不均一性平均して、画像は関連テキストよりもトークンが多いので、データは異種混合である:画像は 2308 個のトークンを持つが、関連テキストは 192 個のトークンしか持たない。平均して、画像は関連付けられたテキストよりも多くのトークンを持つため、データは異種混合です:画像は2308個のトークンを持ちますが、関連付けられたテキストは平均して192個のトークンしか持ちません。その結果、クロスアテンションレイヤーの計算には、セルフアテンションレイヤーの計算よりも時間がかかり、より多くのメモリを必要とする。この問題に対処するため、画像エンコーダにシーケンス並列性を導入し、各GPUがほぼ同じ数のトークンを処理するようにしました。また、平均テキストサイズが比較的小さいため、より大きなマイクロバッチサイズ(1ではなく8)を使用しています。
数値的不安定性.画像エンコーダーをモデルに追加した後、bf16を使った勾配累積が不安定な値になることがわかった。最も可能性の高い説明は、画像マーカーがすべてのクロスアテンションレイヤーを通じて言語バックボーンネットワークに導入されることである。つまり、画像タグ付き表現における数値的な偏差は、誤差が複合化されるため、全体的な計算に不釣り合いな影響を与える。FP32を用いて勾配累積を行うことで、この問題に対処する。
7.4 事前トレーニング
画像の事前トレーニング。 学習済みのテキスト・モデルと視覚コーダーの重みで初期化を開始する。視覚コーダーは凍結を解除し、テキストモデルの重みは前述のように凍結したままである。まず、60億の画像とテキストのペアを用いてモデルを訓練し、各画像は4つの336×336ピクセルのプロットに収まるようにリサイズした。グローバルバッチサイズは16,384、コサイン学習率スキームを用い、初期学習率は10×10 -4、重み減衰は0.01とした。しかし、これらの知見は非常に長い訓練スケジュールにはうまく一般化されないため、損失値が停滞する訓練中に何度か学習率を下げる。基本的な事前学習の後、画像の解像度をさらに上げ、アニールされたデータセットに対して同じ重みで学習を続ける。オプティマイザはウォーミングアップにより2×10 -5の学習率に再初期化され、再びコサインスケジュールに従う。
ビデオによる事前トレーニング。 ビデオの事前学習では、前述の画像の事前学習とアニーリング重みから始める。アーキテクチャで説明したように、ビデオアグリゲータとクロスアテンションレイヤーを追加し、ランダムに初期化する。ビデオ固有のパラメータ(aggregatorとvideo cross-attention)以外の全てのパラメータを凍結し、ビデオの事前学習データで学習する。画像アニーリングフェーズと同じ学習ハイパーパラメータを使用し、学習率は若干異なる。ビデオ全体から16フレームを一様にサンプリングし、各フレームを表現するためにサイズ448×448ピクセルの4ブロックを使用する。テキストマーカーがクロスフォーカスする有効なフレームを得るために、ビデオアグリゲータで16の集約係数を使用する。グローバルバッチサイズ4,096、シーケンス長190トークン、学習率10 -4 で学習する。
7.5 トレーニング後の処理
このセクションでは、ビジュアルアダプターのその後の学習ステップを詳細に説明する。
事前学習後、高度に選択されたマルチモーダル対話データに対してモデルを微調整し、チャット機能を実現した。
さらに、Direct Preference Optimisation (DPO)を実装して手動評価のパフォーマンスを向上させ、拒絶サンプリングを採用してマルチモーダル推論を改善する。
最後に、高品質な対話の非常に小さなデータセットでモデルの微調整を続ける品質調整フェーズを追加し、ベンチマークテストの性能を維持しながら手動評価結果をさらに改善する。
各ステップに関する詳細情報は以下の通り。
7.5.1 微調整データのモニタリング
以下では、画像とビデオそれぞれの機能に対する教師あり微調整(SFT)データについて説明する。
IMAGE 我々は、教師ありの微調整のために、異なるデータセットを混合して使用する。
- アカデミック・データセット:高度にフィルタリングされた既存のアカデミック・データセットを、テンプレートを使用するか、ラージ・ランゲージ・モデリング(LLM)リライトによってQ&Aペアに変換する。LLMリライトは、異なる指示でデータを補強し、回答の言語的質を向上させるように設計されている。
- 手動アノテーション:様々なタスク(自由形式のQ&A、キャプション付け、実世界のユースケースなど)やドメイン(自然画像や構造化画像など)のマルチモーダル対話データを、手動アノテーターを通じて収集する。アノテーターは画像を受け取り、対話の構成を依頼される。
多様性を確保するため、大規模データセットをクラスタ化し、異なるクラスタ間で均等に画像をサンプリングした。さらに、k-最近傍探索を用いてシードを拡張することで、いくつかの特定のドメインについて追加の画像を取得する。アノテーターはまた、既存のモデルの中間チェックポイントを取得し、ループ内のモデルの文体アノテーションを容易にすることで、アノテーターが人間による追加編集を行うための出発点としてモデル生成を使用できるようにする。これは反復プロセスであり、モデルのチェックポイントは定期的に更新され、最新のデータでトレーニングされた、よりパフォーマンスの高いバージョンになります。これにより、手作業によるアノテーションの量と効率が向上すると同時に、品質も向上する。
- 合成データ:画像のテキスト表現とテキスト入力LLMを用いて合成マルチモーダルデータを生成するための様々なアプローチを探求する。基本的な考え方は、テキスト入力LLMの推論機能を利用してテキスト領域のQ&Aペアを生成し、テキスト表現を対応する画像に置き換えて合成マルチモーダルデータを生成することである。例えば、Q&Aデータセットのテキストを画像としてレンダリングしたり、表形式のデータを合成表やグラフ画像としてレンダリングしたりする。さらに、既存の画像のキャプション付けやOCR抽出を利用して、画像に関連する一般的な対話やQ&Aデータを生成する。
ビデオ 画像アダプターと同様に、既存の注釈付き学術データセットを使用して、適切なテキスト指示と目標回答に変換する。目標は、適宜、自由形式の回答や多肢選択式の質問に変換される。人間のアノテーターに、ビデオに質問とそれに対応する回答を追加してもらう。アノテーターには、個々のフレームに基づいて回答できない質問に焦点を当て、理解するのに時間がかかりそうな質問に誘導するよう依頼した。
7.5.2 微調整プログラムの監督
本論文では、画像とビデオそれぞれの能力に対する教師あり微調整(SFT)方式を紹介する:
IMAGE 事前学習済みの画像アダプターからモデルを初期化しますが、事前学習済みの言語モデルの重みは、命令チューニング済みの言語モデルの重みに置き換えます。つまり、視覚コーダーと画像アダプターの重みのみを更新する。
我々の微調整アプローチは、Wortsmanら(2022)と同様である。まず、データの複数のランダムな部分集合、学習率、重み減衰値を用いてハイパーパラメータのスキャンを行う。次に、性能に基づいてモデルをランク付けする。最後に、上位K個のモデルの重みを平均し、最終モデルを得る。Kの値は、平均モデルを評価し、最も性能の高いインスタンスを選択することによって決定された。我々は、平均モデルが、グリッド探索によって発見された最良の個別モデルと比較して、一貫してより良い結果をもたらすことを観察する。さらに、この戦略はハイパーパラメータに対する感度を低減する。
ビデオ ビデオSFTでは、事前に学習した重みを使用してビデオアグリゲータとクロスアテンションレイヤーを初期化する。モデルの残りのパラメータ(画像重みとLLM)は対応するモデルから初期化され、その微調整段階に従う。映像の事前学習と同様に、映像SFTデータの映像パラメータのみを微調整する。この段階では、ビデオの長さを64フレームに増やし、2つの有効なフレームを得るために32の集約係数を使用する。 それに応じてアイヌ・ザマンダ,ブロックの解像度を上げ、対応する画像ハイパーパラメータと一致させる。
7.5.3 プリファレンス
モデル化と直接的な嗜好最適化のために、私たちはマルチモーダルなペア嗜好データセットを構築した。
- 手作業によるラベリング。 手動で注釈を付けた選好データは、2つの異なるモデルの出力の比較で構成され、「選択」と「拒否」とラベル付けされ、7点満点で評価される。回答を生成するために使用されるモデルは、それぞれ異なる特性を持つ、最近の最良のモデルのプールから毎週ランダムにサンプリングされる。嗜好ラベルに加えて、視覚的タスクは不正確さに対して寛容でないため、「選択」回答の不正確さを修正するために、オプションで手動編集を行うようアノテーターに依頼した。実際には量と質のトレードオフがあるため、手動編集はオプションのステップであることに注意。
- 合成データ。 テキストのみのLLM編集を使い、教師付き微調整データセットに意図的にエラーを導入することで、合成嗜好ペアを生成することもできる。我々は対話データを入力とし、LLMを使って微妙だが意味のあるエラー(オブジェクトの変更、属性の変更、計算エラーの追加など)を導入した。これらの編集された応答は否定的な「リジェクト」サンプルとして使用され、「選択された」オリジナルの教師付き微調整データと対にされる。
- サンプリングを拒否する。 さらに、より戦略的なネガティブ・サンプルを作成するために、拒否サンプリングの反復プロセスを利用し、追加の嗜好データを収集する。リジェクト・サンプリングの使用方法については、次のセクションで詳しく説明します。要約すると、棄却サンプリングは、モデルから生成された高品質の結果を反復的にサンプリングするために使用されます。したがって、副産物として、選択されなかったすべての生成結果は、否定的な棄却サンプルとして、また追加の選好データ・ペアとして使うことができます。
7.5.4 報酬モデリング
視覚エンコーダ層と交差注意層は視覚SFTモデルから初期化され、訓練中に凍結解除される一方、自己注意層は言語RMから初期化され、凍結されたままである。言語RMの部分を凍結することで、特にRMがその知識や言語品質に基づいて判断する必要があるタスクにおいて、通常、精度が向上することが確認された。言語RMと同じ訓練目的を使用するが、バッチ平均された報酬ロジットを2乗する重み付き正則化項を追加し、報酬スコアのドリフトを防ぐ。
セクション7.5.3の人間の嗜好アノテーションを視覚的 RMの学習に使用した。言語的嗜好データ(セクション4.2.1)と同じアプロー チに従い、明確なランキング(編集バージョン>選択バージョン>拒否 バージョン)を持つ2つまたは3つのペアを作成した。さらに、画像情報に関連する単語やフレーズ(数字や視覚的テキストなど)をスクランブルすることで、否定的な反応を合成的に強調した。これにより、視覚RMが実際の画像内容に基づいて判断するよう促す。
7.5.5 直接プリファレンス最適化
言語モデル(セクション4.1.4)と同様に、セクション7.5.3で説明した嗜好データを用いて、直接嗜好最適化(DPO; Rafailov et al.ポストトレーニング中の分布バイアスに対抗するため、人間の嗜好アノテーションの最新のバッチのみを保持し、戦略から大きく外れたバッチは破棄した(例えば、基礎となるプレトレーニングモデルが変更された場合)。我々は、参照モデルを常にフリーズさせる代わりに、kステップごとに指数移動平均(EMA)として更新することで、モデルがデータからより多くを学習し、人間の評価においてより良いパフォーマンスにつながることを発見した。全体として、視覚的DPOモデルは、人間による評価において、SFTの出発点を常に上回り、微調整の反復ごとに良好な性能を発揮することが確認された。
7.5.6 サンプリングの拒否
既存のクイズのペアのほとんどは最終的な答えしか含んでおらず、タスクをうまく一般化するモデルについて推論するのに必要な思考の連鎖の説明が欠けている。われわれは、これらの例に欠けている説明を生成するために棄却サンプリングを使用し、それによってモデルの推論を改善する。
クイズのペアが与えられた場合、異なるシステムキューや温度を用いて微調整されたモデルをサンプリングすることにより、複数の答えを生成する。次に、生成された解答をヒューリスティックまたはLLMレフェリーによって真の解答と比較する。最後に、ファインチューニングしたデータに正解を追加することで、モデルを再トレーニングする。問題ごとに複数の正解を保持することが有用であることがわかった。
質の高い例だけをトレーニングに加えるため、以下の2つの安全対策を実施した:
- 最終的な答えが正しいにもかかわらず、間違った説明が含まれている例があることがわかりました。このようなパターンは、生成された解答のごく一部しか正解しない問題でより一般的であることに注意してください。したがって、正解の確率が特定のしきい値以下である問題の解答を破棄しました。
- レビュアーは、言語やスタイルの違いにより、特定の回答を支持します。報酬モデルを使用して、最も質の高いK個の回答を選択し、トレーニングに追加します。
7.5.7 品質チューニング
私たちは、小規模ながら高度に選択されたファインチューニング(SFT)データセットを注意深くキュレーションし、すべてのサンプルが、手作業または私たちの最高のモデルによって、最高水準を満たすように書き換えられ、検証された。 私たちはこのデータを使ってDPOモデルを訓練し、応答品質を向上させており、このプロセスを品質チューニング(QT)と呼んでいる。QTデータセットが幅広いタスクをカバーし、適切な早期停止が適用される場合、QTはベンチマークテスト検証の一般的な性能に影響を与えることなく、人間の評価結果を大幅に改善できることがわかりました。この段階では、能力を維持または向上させるために、ベンチマークテストのみに基づいてチェックポイントを選択する。
7.6 画像認識結果
我々は、自然画像理解、テキスト理解、図理解、マルチモーダル推論をカバーする様々なタスクについて、Llama 3の画像理解能力のパフォーマンスを評価した:
- MMMU (Yue et al., 2024a)は、難易度の高いマルチモーダル推論データセットであり、モデルが画像を理解し、30の異なる分野にわたる大学レベルの問題を解くことが要求される。これには多肢選択問題や自由形式の問題が含まれる。我々は900枚の画像を含む検証セットでモデルを評価する。
- VQAv2 (Antol et al., 2015)は、自然画像に関する一般的な質問に答えるために、画像理解、言語理解、一般知識を組み合わせたモデルの能力をテストする。
- AI2 Diagram (Kembhavi et al., 2016)は、科学的な図を解析し、それに関する質問に答えるモデルの能力を評価する。と同じモデルを使用しました。 ジェミニ x.aiと同じ評価プロトコルで、透明なバウンディングボックスを使用してスコアを報告する。
- ChartQA (Masry et al., 2022)は、チャート理解のための難易度の高いベンチマークテストである。このテストでは、さまざまな種類のチャートを視覚的に理解し、そのロジックに関する質問に答えることが求められる。
- TextVQA (Singh et al., 2019)は、モデルに画像中のテキストを読み取り、それに関するクエリに答える推論を要求する、人気のベンチマークデータセットである。これは自然画像中のOCRを理解するモデルの能力をテストする。
- DocVQA (Mathew et al., 2020)は、文書の解析と認識に焦点を当てたベンチマーク・データセットである。このデータセットには様々な文書の画像が含まれており、OCRを実行するモデルが文書の内容を理解し、推論して、文書に関する質問に答える能力を評価する。
表29に実験結果を示す。表中の結果は、Llama 3に搭載されたビジョンモジュールが、モデル容量の異なる様々な画像認識ベンチマークで競争力を発揮していることを示しています。結果として得られたLlama 3-V 405Bモデルを使用すると、すべてのベンチマークでGPT-4Vを上回りますが、Gemini 1.5 ProとClaude 3.5 Sonnetはわずかに下回ります。Llama 3 405Bは文書理解タスクで特に優れた性能を発揮します。

7.7 ビデオ認識結果
ラマ3のビデオアダプターを3つのベンチマークで評価した:
- PerceptionTest(林ら、2023年)このベンチマークでは、短いビデオクリップを理解し予測するモデルの能力をテストします。オブジェクト、アクション、シーンの認識など、様々なタイプの問題が含まれています。公式に提供されたコードと評価指標(精度)に基づいて結果を報告します。
- TVQA(Lei et al.)このベンチマークでは、空間的・時間的定位、視覚的概念の認識、字幕付き台詞との共同推論を含む複合推論に対するモデルの能力を評価する。データセットは人気のあるテレビ番組から派生しているため、質問に答えるためにこれらのテレビ番組に関する外部知識を使用するモデルの能力もテストされる。このデータセットには15,000以上の有効なQAペアが含まれており、それぞれが平均76秒のビデオクリップに対応している。1問につき5つの選択肢を持つ多肢選択形式を使用しており、過去の研究(OpenAI, 2023b)に基づく検証セットのパフォーマンスを報告する。
- アクティビティネットQA(Yu et al.)このベンチマークは、アクション、空間的関係、時間的関係、カウントなどを理解するために、長いビデオクリップを理解するモデルの能力を評価します。このベンチマークには、800本のビデオからの8,000のテストQAペアが含まれており、それぞれの平均的な長さは3分である。評価については、先行研究(Google, 2023; Lin et al., 2023; Maaz et al., 2024)のプロトコルに従い、モデルが短い単語やフレーズの回答を生成し、GPT-3.5 APIを使って実際の回答と比較し、出力の正しさを評価する。我々はAPIによって計算された平均精度を報告する。
推論過程
推論を行う際には、ビデオクリップ全体から均等にフレームをサンプリングし、短いテキストプロンプトとともにモデルに渡す。ほとんどのベンチマークは多肢選択式の質問に答えるので、以下のプロンプトを使用する:
- 次の選択肢から正しいものを選びなさい。正しい選択肢の文字だけで答え、それ以外は何も書かないでください。
短い回答を生成する必要があるベンチマーク(ActivityNet-QAやNExT-QAなど)については、以下のヒントを使用する:
- 質問に単語またはフレーズで答えてください。
NExT-QAでは、評価指標(WUPS)が長さと使用される特定の単語に敏感であるため、具体的で最も顕著な答えに反応するようモデルにも促しました。".字幕を含むベンチマーク(例:TVQA)については、推論プロセス中にクリップの対応する字幕をキューに含める。
結局
表30は、Llama 3 8Bおよび70Bモデルの性能を示している。2つのGeminiモデルおよび2つのGPT-4モデルの性能と比較する。すべての結果はゼロサンプル結果であることに注意してください。なぜなら、これらのベンチマークのいかなる部分も、トレーニングデータにも微調整データにも含めていないからです。Llama3は、8Bおよび70Bパラメータモデルのみを評価したため、ビデオ認識において特に優れた性能を発揮しました。PerceptionTestでは、Llama 3が最高のパフォーマンスを達成し、このモデルが複雑な時間推論を行う強力な能力を備えていることが実証されました。ActivityNet-QAのような長いクリップのアクティビティ理解タスクにおいて、Llama 3は64フレームまでしか処理しない場合(3分のビデオでは、モデルは3秒に1フレームしか処理しない)でも、強力な結果を達成しています。


8 音声実験
Llama3に音声機能を統合するために、視覚認識で使用したスキームと同様の組み合わせアプローチを調査する実験を行った。入力では、音声信号を処理するためにエンコーダーとアダプターを追加した。私たちは、Llama 3がさまざまな音声理解モードをサポートできるように、(テキスト形式の)システムキューを利用しています。システムのプロンプトが提供されない場合、このモデルは一般的な音声対話モデルとして動作し、Llama 3のテキストのみのバージョンと一貫した方法でユーザーの発話に効果的に応答することができます。対話履歴をキュープレフィックスとして導入することで、多ラウンドの対話体験を向上させることができる。Llama 3の音声インターフェースは、最大34の言語をサポートしています18。また、テキストと音声の交互入力も可能で、高度な音声理解タスクを解くことができます。
また、言語モデルのデコード中に音声波形を動的に生成するストリーミング音声合成(TTS)システムを実装した音声生成アプローチも実験しました。私たちは、独自のTTSシステムに基づいてLlama 3の音声ジェネレーターを設計し、音声生成のための言語モデルの微調整は行いませんでした。その代わりに、推論時にLlama 3の単語埋め込みを利用することで、音声合成の待ち時間、精度、自然さを向上させることに注力しました。音声インターフェースを図28と図29に示す。
8.1 データ
8.1.1 音声理解
学習データは2つのカテゴリーに分けられる。事前学習データは、自己教師ありの方法で音声エンコーダを初期化するために使用される、ラベル付けされていない大量の音声から構成される。教師ありの微調整データには、音声認識、音声翻訳、音声対話のデータが含まれ、これらは大規模な言語モデルと統合する際に特定の能力を引き出すために使用されます。
トレーニング前のデータ。 音声エンコーダの事前学習を行うために、複数の言語にわたる約1500万時間の音声録音を含むデータセットを照合した。 音声データをVAD(Voice Activity Detection)モデルでフィルタリングし、VADの閾値が0.7以上の音声サンプルを選んで事前学習に使用した。 音声の事前学習データでは、個人を特定できる情報(PII)がないことを確認することにも重点を置きました。 このようなPIIを識別するためにPresidio Analyzerを使用しています。
音声認識と翻訳データ。 ASRのトレーニングデータには、34言語、230,000時間の手書き書き起こし音声が含まれています。 ASTの学習データには、33言語から英語、英語から33言語への双方向翻訳が90,000時間分含まれています。これらのデータには、NLLBツールキット(NLLB Team et al., 2022)を使用して生成された教師ありデータと合成データの両方が含まれている。 合成ASTデータを使用することで、低リソース言語のモデルの品質が向上する。 本データに含まれる音声セグメントの最大長は60秒である。
会話データ。 音声対話のための音声アダプ タを微調整するために、言語モデルにプロンプトのトランスクリプションに応答するよう求め ることで、音声プロンプトに対する応答を合成した(Fathullah et al.) この方法で合成データを生成するために、ASRデータセット(60,000時間の発話を含む)のサブセットを使用した。
さらに、Llama 3の微調整に使用したデータのサブセットでVoicebox TTSシステム (Le et al., 2024)を実行し、25,000時間の合成データを作成しました。 音声分布に一致する微調整データのサブセットを選択するために、いくつかのヒューリスティックスを使用しました。これらのヒューリスティクスには、比較的短く単純な構造の手がかりに焦点を当て、非テキスト記号を含めないことが含まれる。
8.1.2 スピーチの生成
语音生成数据集主要包括用于训练文本规范化(TN)模型和韵律模型(PM)的数据集。两种训练数据都通过添加 Llama 3 词嵌入作为额外的输入特征进行增强,以提供上下文信息。
文本规范化数据。我们的 TN 训练数据集包含 5.5 万个样本,涵盖了广泛的符号类别(例如,数字、日期、时间),这些类别需要非平凡的规范化。每个样本由书面形式文本和相应的规范化口语形式文本组成,并包含一个推断的手工制作的 TN 规则序列,用于执行规范化。
声韵模型数据。PM 训练数据包括从一个包含 50,000 小时的 TTS 数据集提取的语言和声韵特征,这些特征与专业配音演员在录音室环境中录制的文字稿件和音频配对。
Llama 3 嵌入。Llama 3 嵌入取自第 16 层解码器输出。我们仅使用 Llama 3 8B 模型,并提取给定文本的嵌入(即 TN 的书面输入文本或 PM 的音频转录),就像它们是由 Llama 3 模型在空用户提示下生成的。在一个样本中,每个 Llama 3 标记序列块都明确地与 TN 或 PM 本地输入序列中的相应块对齐,即 TN 特定的文本标记(由 Unicode 类别区分)或语音速率特征。这允许使用 Llama 3 标记和嵌入的流式输入训练 TN 和 PM 模块。
8.2 モデル・アーキテクチャ
8.2.1 音声理解
入力側の音声モジュールは、音声エンコーダーとアダプターの2つのモジュールから構成される。音声モジュールの出力は、トークン表現として言語モデルに直接入力され、音声とテキスト・トークン間の直接的な相互作用を可能にする。さらに、音声表現のシーケンスを格納するための新しい2つの特別なトークンを導入した。発話モジュールは視覚モジュール(セクション7参照)とは大きく異なり、クロスアテンションレイヤーを介して言語モデルにマルチモーダル情報を入力する。対照的に、発話モジュールによって生成された埋め込みは、テキストトークンにシームレスに統合することができ、発話インターフェースはLlama 3言語モデルのすべての機能を利用することができる。
ボイスエンコーダ:我々の音声エンコーダは10億個のパラメータを持つコンフォーマモデルである(Gulati et al.)このモデルへの入力は80次元のマイヤースペクトログラム特徴からなり、まずステップサイズ4のスタックレイヤーを通して処理され、次に線形射影によって40ミリ秒のフレーム長に縮小される。処理された特徴は、24のコンフォーマー層を含むエンコーダーによって処理される。各コンフォーマー層は1536の潜在的な次元を持ち、4096の次元を持つ2つのマクロンネット型フィードフォワードネットワーク、7のカーネルサイズを持つ畳み込みモジュール、24の注意ヘッドを持つ回転注意モジュールを含む(Su et al.、2024)。
音声アダプター:スピーチアダプターには約1億個のパラメータが含まれている。畳み込み層、回転トランスフォーマー層、線形層で構成される。畳み込み層はカーネルサイズ3、ステップサイズ2で、音声フレーム長を80msに短縮するように設計されている。Transformer層は潜在的な次元が3072であり、フィードフォワードネットワークは4096の次元を持ち、畳み込みによってダウンサンプリングされた音声情報をさらに処理する。最後に、Linear層が言語モデルの埋め込み層に合わせて出力次元をマッピングする。
8.2.2 音声生成
Llama 3 8Bのエンベッディングは、テキスト正規化と計量モデリングという音声生成の2つの重要な要素に使用されている。テキスト正規化(TN)モジュールは、書き言葉を話し言葉に文脈変換することで、意味的な正しさを保証します。韻律モデリング(PM)モジュールは、韻律の特徴を予測するためにこれらの埋め込みを使用することで、自然さと表現力を向上させます。これら2つのコンポーネントが連動することで、正確で自然な音声生成が実現します。
**テキスト正規化**:生成された音声の意味的な正しさを決定する要素として、テキスト正規化(TN)モジュールは、書き言葉から対応する話し言葉への文脈を考慮した変換を行い、最終的に下流のコンポーネントによって音声化される。TNシステムは、ストリーミングLSTMベースのシーケンス・ラベリング・モデルで構成され、TNに使用される桁数を予測する。TNシステムは、ストリーミングLSTMベースのシーケンス・ラベリング・モデルで構成されている。ニューラル・モデルはまた、そこにエンコードされた文脈情報を利用するために、クロスアテンションを介してLlama 3の埋め込みを受け取り、最小限のテキスト・ラベリングの先見性とストリーミング入出力を可能にする。
**韻モデル**:合成音声の自然さと表現力を高めるために、Llama 3の埋め込みを追加入力として使用するTransformerアーキテクチャのみをデコードする韻モデル(PM)(Radford et al.この統合は、Llama 3の言語的能力を活用し、そのテキスト出力と中間埋込み(Devlin et al. 2018; Dong et al. 2019; Raffel et al. 2020; Guo et al. 2023)を使って韻の特徴の予測を補強し、それによってモデルが必要とする先読みを減らします。PMは、包括的な韻予測を生成するために複数の入力コンポーネントを統合します。PMは複数の入力コンポーネントを統合して、包括的な韻律予測を生成します。PMが予測するのは、各音素の対数継続時間、対数基本周波数(F0)平均、音素の継続時間に対する対数パワー平均の3つの主要な韻律特徴です。モデルは単方向トランスフォーマーと6つのアテンションヘッドで構成される。各ブロックは864の隠れ次元を持つクロスアテンション層と二重の完全連結層から構成される。PMの特徴は二重のクロスアテンションメカニズムであり、1つの層は言語入力に、もう1つの層はLlamaエンベッディングに特化している。このセットアップにより、明示的なアライメントを必要とすることなく、異なる入力レートを効果的に管理することができる。
8.3 トレーニング・プログラム
8.3.1 音声理解
音声モジュールのトレーニングは2段階で行われた。第一段階では、言語的・音響的条件に対して強力な汎化能力を示すラベル付けされていないデータを用いて音声エンコーダを学習する。第二段階では、教師ありの微調整が行われ、LLMは固定されたまま、アダプタと事前に訓練されたエンコーダが音声モデルと統合され、音声モデルと協調訓練される。これにより、モデルは音声入力に対応できるようになる。この段階では、音声理解能力に対応するラベル付きデータを使用する。
多言語ASRとASTモデリングは、しばしば言語の混乱/干渉を引き起こし、パフォーマンスを低下させる。一般的な緩和方法は、ソースとターゲットの両方に言語識別(LID)情報を含めることである。これにより、あらかじめ決められた方向への性能向上が期待できるが、汎化の劣化につながる可能性もある。例えば、翻訳システムがソースとターゲットの両方でLID情報を提供することを想定している場合、トレーニングで見られなかった方向でモデルが良好なゼロサンプル性能を示す可能性は低い。したがって、我々の課題は、ある程度のLID情報を許容しつつ、未視聴方向の音声翻訳に十分なモデルの汎用性を保つシステムを設計することである。この問題に対処するため、出力されるテキスト(ターゲット側)のLID情報のみを含むシステムキューを設計した。このキューは、音声入力(ソース側)のLID情報を含まないため、コードスイッチング音声にも対応できる可能性がある。ASRでは、次のようなシステムプロンプトを使用する:{言語}で私の言葉を繰り返してください:ここで、{言語}は34の言語(英語、フランス語など)のうちの1つである。音声翻訳の場合、システム・プロンプトは「次の文を{言語}に翻訳してください。このデザインは、言語モデルが希望する言語で応答するよう促すのに効果的であることが示されている。トレーニング中も推論中も同じシステムプロンプトを使用する。
音声の事前学習には、自己教師付きBEST-RQアルゴリズム(Chiu et al, 2022)を使用する。
编码器采用长度为 32 帧的掩码,对输入 mel 谱图的概率为 2.5%。如果语音话语超过 60 秒,我们将随机裁剪 6K 帧,对应 60 秒的语音。通过堆叠 4 个连续帧、将 320 维向量投影到 16 维空间,并在 8192 个向量的代码库内使用余弦相似度度量进行最近邻搜索,对 mel 谱图特征进行量化。为了稳定预训练,我们采用 16 个不同的代码库。投影矩阵和代码库随机初始化,在模型训练过程中不更新。多软最大损失仅用于掩码帧,以提高效率。编码器经过 50 万步训练,全局批处理大小为 2048 个语音。
监督微调。预训练语音编码器和随机初始化的适配器在监督微调阶段与 Llama 3 联合优化。语言模型在此过程中保持不变。训练数据是 ASR、AST 和对话数据的混合。Llama 3 8B 的语音模型经过 650K 次更新训练,使用全局批大小为 512 个话语和初始学习率为 10。Llama 3 70B 的语音模型经过 600K 次更新训练,使用全局批大小为 768 个话语和初始学习率为 4 × 10。
8.3.2 スピーチ生成
リアルタイム処理をサポートするために、韻律モデルは、固定数の将来の音素位置と可変数の将来のトークンを考慮する先読みメカニズムを採用しています。 これにより、入力テキストの処理中に一貫したルックアヘッドが保証され、これは低遅延の音声合成アプリケーションにとって重要です。
トレーニング 音声合成のストリーミングを容易にするために、因果マスクを利用した動的アライメント戦略を開発する。このストラテジーは、テキスト正規化プロセス(セクション8.1.2)のチャンキングプロセスと同様に、固定数の未来の音素と可変数の未来のトークンに対する韻律モデルのルックアヘッドメカニズムを組み合わせたものである。
各音素について、マーカーのルックアヘッドはブロックサイズで定義された最大数のマーカーで構成され、その結果、可変ルックアヘッドを持つLlamaエンベッディングと固定ルックアヘッドを持つ音素が得られる。
Llama 3 8Bモデルからのエンベッディング。韻モデル学習中は凍結されたまま。入力通話レートの特徴には、言語的要素と話者/スタイル制御可能要素が含まれる。モデルは、バッチサイズ1,024トーン、学習率9×10 -4のAdamWオプティマイザを使用して学習される。モデルは100万回の更新で学習され、最初の3,000回の更新では学習率のウォームアップが行われ、その後コサインスケジューリングが行われる。
理由 推論中、同じルックアヘッドメカニズムと因果マスキング戦略が使用され、学習とリアルタイム処理の一貫性が保たれる。PMは入力されたテキストをストリーミング方式で処理し、フォンレート特徴についてはフォンごとに、ラベル付きレート特徴についてはブロックごとに入力を更新する。新しいブロックの入力は、そのブロックの最初の電話が現在の電話である場合にのみ更新されるため、学習中の整合性と先読みが維持される。
韻のターゲットを予測するために、遅延モードアプローチ(Kharitonov et al.このアプローチは、合成音声の自然さと表現力に貢献し、低遅延と高品質の出力を保証します。
8.4 音声理解結果
我々はLlama 3の音声理解能力を次の3つのタスクで評価した:(1) 自動音声認識 (2) 音声翻訳 (3) 音声Q&A。すべての評価において、Llama 3のトークンを予測するために貪欲探索を使用しました。
音声認識。 多言語LibriSpeech(MLS; Pratap et al., 2020)、LibriSpeech(Panayotov et al., 2015)、VoxPopuli(Wang et al., 2021a)、FLEURS多言語データセットのサブセット(Conneau et al.2023)を英語データセットに適用し、ASR性能を評価した。評価では ウィスパー テキスト正規化手順は、他のモデルで報告された結果との整合性を確保するために、デコード結果を後処理します。すべてのベンチマークにおいて、中国語、日本語、韓国語、タイ語を除き、これらのベンチマークの標準テストセットでLlama 3音声インターフェースの単語エラー率を測定し、文字エラー率を報告しています。
表31にASRの評価結果を示します。この表は、音声認識タスクにおけるLlama 3(およびより一般的なマルチモーダルベースモデル)の強力な性能を示しています。私たちのモデルは、すべてのベンチマークにおいて、Whisper20やSeamlessM4Tなどの音声に特化したモデルを上回っています。MLS英語では、Llama 3はGeminiと同等の性能を示しています。
音声翻訳。 また、非英語の音声を英語のテキストに翻訳する音声翻訳タスクで、モデルの性能を評価した。これらの評価には FLEURS と Covost 2 (Wang et al., 2021b)のデータセットを使用し、翻訳された英語の BLEU スコアを測定した。表32にこれらの実験結果を示す。音声翻訳における我々のモデルの性能は、音声翻訳のようなタスクにおけるマルチモーダルベースモデルの利点を浮き彫りにしている。
声のクイズ ラマ3の音声インターフェースは、驚くべき質問応答能力を示している。このモデルは、そのようなデータに事前に触れることなく、コードスイッチされた音声を難なく理解することができる。特筆すべきは、このモデルは1ラウンドの対話でしか訓練されていないにもかかわらず、拡張された首尾一貫した複数ラウンドの対話セッションが可能であることです。図30は、このような多言語・多ラウンド能力を強調するいくつかの例を示している。
セキュリティ MuTox (Costa-jussà et al., 2023)は、英語とスペイン語の20,000のセグメントと、その他の19言語の4,000のセグメントを含む多言語音声ベースのデータセットであり、各セグメントには毒性タグが付けられている。音声はモデルへの入力として渡され、出力はいくつかの特殊文字を除去した後に毒性について評価される。Gemini 1.5 ProにMuTox分類器(Costa-jussà et al.入力が安全を示唆し、出力が有毒である場合の付加毒性(AT)のパーセンテージと、入力が有毒を示唆し、回答が安全である場合の喪失毒性(LT)のパーセンテージを評価した。表33は英語の結果と、全21言語の平均結果を示している。毒性が追加される割合は非常に低く、我々の音声モデルは英語において毒性が追加される割合が最も低く、11 TP3T未満である。

8.5 音声生成結果
音声生成の文脈では、テキストの正規化と韻律モデリングタスクにLlama 3ベクトルを使用するマーカーベースのストリーミング入力モデルの品質評価に焦点を当てる。この評価では、Llama 3ベクトルを追加入力として使用しないモデルとの比較に重点を置いています。
テキストの正規化。 Llama 3 ベクトルの影響を測定するために、モデルで使用する右側コンテキストの量を変えてみた。3つのテキスト正規化(TN)トークン(Unicodeカテゴリで区切られている)の右側コンテキストを使用してモデルをトレーニングした。このモデルを、Llama 3ベクトルを使用せず、3タグの右側コンテキストまたは完全な双方向コンテキストのいずれかを使用するモデルと比較した。予想通り、表34は、完全な右側コンテキストを使用することで、Llama 3ベクトルを使用しないモデルの性能が向上することを示している。しかし、Llama 3ベクトルを含むモデルは他のすべてのモデルを上回り、入力の長いコンテクストに依存することなく、マークレートの入出力ストリーミングを可能にしている。Llama 3 8Bベクトルを含むモデルと含まないモデルを、異なる右辺コンテキスト値を用いて比較する。
リズミック・モデリング。 Llama 3 8Bを使用した韻律モデル(PM)のパフォーマンスを評価するため、Llama 3ベクトルを使用したモデルと使用しないモデルを比較する2組の人間による評価を行いました。評価者は異なるモデルのサンプルを聞き、好みを示しました。
最終的な音声波形を生成するために、スペクトル特徴を予測するTransformerベースの内部音響モデル(Wu et al, 2021)とWaveRNNニューラルボコーダー(Kalchbrenner et al, 2018)を使用した。
最初のテストでは、Llama 3ベクトルを使用しないストリーミングベンチマークモデルと直接比較します。2つ目のテストでは、Llama 3 8B PMをLlama 3ベクトルを使用しないストリーミングベンチマークモデルと比較しました。表35に示すように、Llama 3 8B PMは60%の時間(ストリーミングベンチマークと比較して)、63.6%の時間(非ストリーミングベンチマークと比較して)優先され、知覚品質が大幅に改善されたことがわかります。 Llama 3 8B PMの主な利点は、マーカーベースのストリーミング機能(セクション8.2.2)であり、推論プロセス中の低レイテンシを維持する。これにより、モデルのルックアヘッド要件が軽減され、ストリーミング機能を持たない ベンチマークモデルと比較して、より応答性の高いリアルタイムの音声合成が可能になります。全体として、Llama 3 8B韻律モデルは一貫してベンチマークモデルを上回っており、合成音声の自然さと表現力を向上させる有効性が実証されています。




9 関連作品
Llama 3の開発は、言語、画像、映像、音声の基本モデルに関する先行研究の膨大な蓄積の上に成り立っている。本論文の範囲では、この研究の包括的な概要は含まれていない。このような概要については、Bordes et al.以下では、Llama 3の開発に直接影響を与えた代表的な研究を簡単に紹介する。
9.1 言語
スコープ Llama 3は、基本モデルの特徴である、単純な手法をどんどん大きなスケールに適用していくという不変の傾向を踏襲している。405Bのモデルは、Llama 2の70Bに比べ、学習前の計算予算がほぼ50倍になっている。我々の最大モデルであるLlama 3は405Bのパラメータを含むが、スケーリング則の理解が進んだため、PALM(Chowdhery et al.他のフロンティアモデルは、Claude 3やGPT 4 (OpenAI, 2023a)のようなサイズで利用可能であり、公開情報は限られているが、全体的な性能は同等である。
小規模モデル。 小規模モデルの開発は、大規模モデルの開発と密接に関係している。より少ないパラメータを持つモデルは、推論コストを大幅に改善し、展開を単純化することができる(Mehta et al.)小型のLlama 3モデルは、計算上最適な学習ポイントをはるかに超えることで、学習計算と推論効率のトレードオフを効果的に行い、これを達成している。もう一つの方法は、Phi(Abdin et al., 2024)のように、より大きなモデルをより小さなモデルに分割することである。
建築。 Llama 2と比較して、Llama 3は最小限のアーキテクチャー変更で済んでいるが、他の最近の基本モデルでは代替設計が検討されている。最も注目すべきは、Mixtral(Jiang et al.Llama 3の性能はこれらのモデルを凌駕しており、高密度のアーキテクチャが制限要因ではないことを示唆しているが、大規模なスケールにおけるモデルの安定性と同様に、学習と推論の効率性という点で、まだ多くのトレードオフが存在する。
オープンソース。 オープンソースのベースモデルはこの1年で急速に進化し、Llama3-405Bは現在のクローズドソースの最先端技術に匹敵するようになった。Mistral (Jiang et al., 2023)、Falcon (Almazrouei et al., 2023)、MPT (Databricks, 2024)、Pythia (Biderman et al., 2023)、Arctic (Snowflake, 2024)など、多くのモデルファミリーが最近開発された、OpenELM(Mehta et al.、2024)、OLMo(Groeneveld et al.、2024)、StableLM(Bellagente et al.、2024)、OpenLLaMA(Geng and Liu、2023)、Qwen(Bai et al.、2023)、Gemma(Team et al.、2024)、Grok(Biderman et al.2024)、Grok(XAI、2024)、Phi(Abdinら、2024)。
トレーニング後 Llama 3の事後学習は、確立された指示アライメント戦略(Chung et al., 2022; Ouyang et al., 2022)に従い、人間のフィードバックによるアライメントが続く(Kaufmann et al., 2023)。軽量なアライメント手順で予想外の結果を示した研究もあるが(Zhou et al., 2024)、Llama 3は、拒絶サンプリング(Bai et al., 2022)、教師ありの微調整(Sanh et al., 2022)、直接的な嗜好最適化(Rafailov et al., 2023)など、事前に訓練されたモデルを改善するために、何百万もの人間の指示と嗜好の判断を使用する。これらの指示と嗜好の例をキュレートするために、我々はフィルタリング(Liu et al.、2024c)、書き換え(Pan et al.、2024)、またはキューと応答を生成する(Liu et al.、2024b)ためにLlama 3の以前のバージョンを展開し、ポストトレーニングの複数のラウンドを通してこれらの技術を適用した。
9.2 マルチモダリティ
我々の Llama 3 マルチモーダル能力実験は、複数のモダリティを共同モデリングするための基本モデルの長期的研究の一環である。我々のLlama 3のアプローチは、Gemini 1.0 Ultra (Google, 2023)やGPT-4 Vision (OpenAI, 2023b)に匹敵する結果を達成するために、多くの論文からのアイデアを組み合わせたものである。
ビデオビデオ入力をサポートする基本モデル(Google, 2023; OpenAI, 2023b)の数が増えているにもかかわらず、ビデオと言語の共同モデリングに関する研究はあまり行われていない。Llama 3と同様に、現在の研究のほとんどは、動画と言語表現を整列させ、動画に関する質問と回答、推論を解明するために、アダプター手法を使用しています(Lin et al.)我々は、このような手法が最先端の手法と遜色のない結果をもたらすことを発見した;セクション7.7を参照。
口語音私たちの研究は、言語モデリングと音声モデリングを組み合わせた、より大規模な研究の流れにも組み込まれています。初期のテキストと音声の結合モデルには、AudioPaLM(Rubensteinら、2023)、VioLA(Wangら、2023b)、VoxtLM Maitiら(2023)、SUTLM(Chouら、2023)、Spirit-LM(Nguyenら、2024)などがある。.私たちの研究は、Fathullah et al.このような先行研究の大部分とは異なり、我々は言語モデル自体を音声タスク用に微調整しないことにした。このような微調整を行わなくても、モデルサイズが大きくなれば、良好な性能を達成できることがわかった;セクション8.4参照。
10 まとめ
高品質なベースモデルの開発は、まだ初期段階にある。Llama 3 の開発における我々の経験から、これらのモデルには将来的な改良の余地が大いにあることが示唆される。Llama 3ファミリーのモデル開発において、私たちは、高品質なデータ、スケール、シンプルさに重点を置くことが、一貫して最良の結果につながることを発見しました。予備実験では、より複雑なモデル・アーキテクチャとトレーニング・シナリオを検討しましたが、これらのアプローチの利点が、モデル開発で生じる複雑さを上回るとは分かりませんでした。
Llama 3のようなフラッグシップのベースモデルを開発するには、多くの深い技術的な問題を克服するだけでなく、十分な情報に基づいた組織的な決断も必要です。例えば、Llama 3が誤って一般的に使用されているベンチマークテストに過剰適合しないように、事前トレーニングデータは、事前トレーニングデータによって外部のベンチマークテストが汚染されないよう、強いインセンティブを与えられた独立チームによって調達され、処理されています。もう1つの例として、モデル開発に関与していない少数の研究者のみがこれらの評価を実行し、アクセスできるようにすることで、人間による評価の信頼性を確保しています。このような組織的な決定が技術論文で議論されることはほとんどありませんが、Llama 3モデル・ファミリーの開発を成功させるためには非常に重要であることがわかりました。
私たちの開発プロセスの詳細は、より広い研究コミュニティがベースモデル開発の重要な要素を理解し、ベースモデルの将来的な開発について、より洞察に満ちた一般的な議論に貢献する助けになると信じている。また、Llama 3にマルチモーダル機能を統合した予備的な実験結果も共有します。これらのモデルはまだ活発に開発中であり、リリースには至っていませんが、私たちの結果を早期に共有することで、この方向での研究が加速することを期待しています。
この論文で詳述した安全性解析の肯定的な結果を受け、私たちはLlama 3言語モデルを一般に公開します。これは、幅広い社会的ユースケースに対応するAIシステムの開発プロセスを加速させ、研究コミュニティが私たちのモデルをレビューし、より良く、より安全にする方法を見つけることができるようにするためです。私たちは、そのようなモデルの責任ある開発には、基礎となるモデルの一般公開が不可欠であると信じており、Llama 3の公開が、業界全体がオープンで責任あるAI開発を受け入れるきっかけになることを願っています。

![エージェントAI:マルチモーダルインタラクションのフロンティアの世界を探る [フェイフェイ・リー - クラシック必読] - チーフAIシェアリングサークル](https://www.aisharenet.com/wp-content/uploads/2025/01/6dbf9ac2da09ee1-220x150.png)