正式な議論の前に、AIクローラ(LLMクローラとも呼ばれる)の概念を明確にする必要がある。大まかに2つのカテゴリに分けることができ、1つは従来のクローラツールで、その結果がLLMのコンテキストで直接使用されることを除けば、厳密に言えばAIとは何の関係もない。もう1つはLLMによって駆動される新しいタイプのクローラプログラムで、ユーザが自然言語を通じてデータ収集のターゲットを指定すると、LLMが自律的にウェブページの構造を分析し、動的データを取得するための対話型操作を策定し、最終的に構造化されたターゲットコンテンツを返す。もう一つは、新しいタイプのLLM駆動型クローラーソリューションで、ユーザーが自然言語でデータ収集対象を指定すると、LLMがウェブページの構造を分析し、クローリング戦略を策定し、動的データを取得するためのインタラクションを実行し、最終的に構造化されたターゲットコンテンツを返す。
LLM主導のクローラー・プログラム
一般的なAI駆動型ウェブクローラーのアイデアと実践については、この記事を詳細に読むことができます、著者はアイデアからソリューションに、その後、チューニングと結果の分析に、非常に詳細な、乾物でいっぱいですが、私は簡単にあなたにこのプロセスを紹介するよう努めています。全体のプロセスは、人間のステップの徹底的なシミュレーションです:
- まず、ウェブページのHTMLコード全体をクロールする。
- 例えば、価格を探す場合、AIは関連キーワード(価格、料金、コストなど)を生成する。
- これらのキーワードに基づいてHTML構造を検索し、関連するノードのリストを見つける。
- AIを使ってノードのリストを分析し、最も関連性の高いものを特定する。
- アプリケーションAIは、ノードとのインタラクション(通常はクリックアクション)が必要かどうかを判断する。
- 最終結果が得られるまで、上記のステップを繰り返す。
スカイバーン
Skyvernは、ワークフロー自動化の効率性と適応性を高めるために設計された、マルチモーダルモデルに基づくブラウザ自動化ツールです。サイト固有のスクリプト、DOM解析、XPathパスに依存することが多く、サイトレイアウトが変更された場合に失敗しがちな従来の自動化アプローチとは異なり、SkyvernはLLMと連携して、ブラウザウィンドウのビジュアル要素をリアルタイムに分析してインタラクションプランを生成します。の変更に強くなります。ブラウザベースのワークフローは、Playwrightなどのブラウザ自動化ライブラリを組み込むことで自動化されます:
- インタラクティブ要素エージェント:ウェブページのHTML構造を解析し、インタラクティブ要素を抽出する。
- ナビゲーションエージェント:ボタンをクリックする、テキストを入力するなど、タスクを完了するために必要なナビゲーションパスを計画する。
- データ抽出エージェント:ウェブページからのデータ抽出を担当し、テーブルやテキストを読み取り、ユーザー定義の構造化フォーマットにデータを出力することができる。
- パスワード・エージェント:ウェブサイトのパスワード・フォームへの入力を担当し、パスワード・マネージャーからユーザー名とパスワードを読み取り、ユーザーのプライバシーを保護しながらフォームに入力することができる。
- 2FAエージェント: 2FAフォームへの入力を担当し、ウェブサイトからの2FAリクエストをインターセプトし、ユーザー定義のAPIを通じて2FAコードを取得するか、ユーザーが手動で入力するのを待つことができる。
- ダイナミックオートコンプリートエージェント:ダイナミックオートコンプリートフォームへの入力を担当し、ユーザー入力とフォームフィードバックに基づいて適切なオプションを選択し、入力を調整することができます。

スクラップグラフAI
ScrapeGraphAIは、ビッグトークモデルとグラフロジックによってクロールパイプラインの構築を自動化することで、手作業によるコーディングの必要性を軽減する。一般人は必要な情報を指定するだけで、ScrapeGraphAIは自動的に単一または複数ページのクロールタスクを処理し、効率的にウェブページをクロールする。XML、HTML、JSON、Markdownなど幅広いドキュメントフォーマットをサポートしており、ScrapeGraphAIは以下のようないくつかのタイプのクローリングを提供している:
- スマートスクレーパーグラフ単一ページのクローリングは、ユーザープロンプトと入力ソースだけで実現できます。
- サーチグラフ検索結果の上位から情報を抽出する複数ページのクローラー。
- スピーチグラフウェブサイトコンテンツをオーディオファイルに変換するワンページグラバー。
- スクリプトクリエーターグラフ抽出されたデータのPythonスクリプトを作成するシングルページグラバー。
- スマートスクレーパー・マルチグラフ1つのプロンプトと様々なソースを介した複数ページのクロール。
- ScriptCreatorMultiGraph複数のページやソースから情報を抽出し、対応するPythonスクリプトを作成するマルチページ・クローラー。
ScrapeGraphAIは、情報要件を提供するだけで、深いプログラミングの知識がなくても、一般の人がスクレイピング作業を自動化できるようにすることで、ウェブスクレイピングのプロセスを簡素化し、様々な規模のデータ抽出タスクに対して、単一ページから複数ページまでのスクレイピングをサポートし、情報抽出、音声生成、スクリプト作成など、様々なスクレイピングニーズに対して異なる用途のパイプラインを提供します。
従来のクローラーツール
このようなツールは、通常のオンライン・ウェブ・コンテンツをクレンジングし、ビッグ・モデルによるより良い理解と処理のためにMarkdown形式に変換することでこれを行う(ビッグ・モデルの回答は、データが構造化されMarkdown形式であるほど質が高くなる)。変換されたコンテンツはLLMのコンテキストとして機能し、モデルがオンライン・リソースと連携して質問に回答できるようにする。
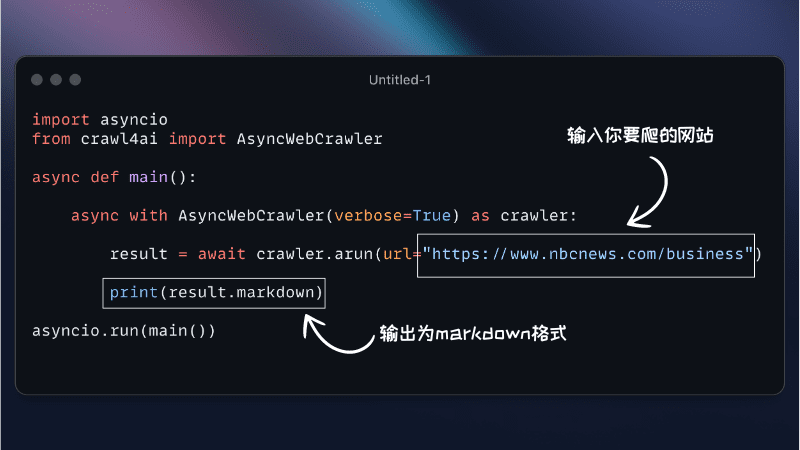
クロール4AI
クロール4AI Crawl4AIは、AIアプリケーションのために設計されたオープンソースのウェブクローラーとデータ抽出フレームワークで、複数のURLを同時にクロールできるため、大規模なデータ収集に必要な時間を大幅に短縮することができる:
- 複数の出力フォーマットJSON、Minimal HTML、Markdownなど複数の出力形式をサポートしています。
- ダイナミック・コンテンツのサポートカスタムJavaScriptコードにより、Crawl4AIは、"次へ "ボタンをクリックして動的コンテンツをロードするようなユーザーの行動をシミュレートすることができます。このアプローチにより、Crawl4AIはページングや無限スクロールのような一般的な動的コンテンツのロードメカニズムを扱うことができます。
- 複数のチャンキング戦略トピック、正規表現、センテンスなど、さまざまなチャンキング戦略をサポート。
- メディア抽出XPathや正規表現などの強力なメソッドを採用し、必要なデータをピンポイントで抽出することができます。画像、音声、動画など、さまざまな種類のメディアを抽出することができ、マルチメディアコンテンツに依存するアプリケーションに特に便利です。
- カスタムフッククローラーの実行開始時に実行されるフックなど、ユーザーはカスタムフックを定義できる。
実行開始フックを使用します。これは、クロールが始まる前に、必要なJavaScriptがすべて実行され、動的コンテンツがページにロードされていることを確認するために使用できる。 - 良好な安定性動的コンテンツのクロールは、ネットワークの問題やJavaScriptの実行エラーによって失敗する可能性があります。Crawl4AIのエラー処理と再試行のメカニズムは、これらの問題が発生した場合でも、データの整合性と正確性を確保するために再試行できることを保証します。
リーダー
Jina AIが開発したウェブコンテンツ・クローリングツール リーダーAPI さらに、ユーザーはURLを入力するだけで、ページのコンテンツをクリーンアップし、プレーンテキストやMarkdown形式で出力することができる。つまり、リッチテキストコンテンツをプレーンテキストに、例えば画像を説明テキストに変換する。

ファイヤークロール
Firecrawlは、Readerよりもエレガントで強力に設計されており、より成熟した製品である。Firecrawlは、ウェブサイトのコンテンツをMarkdown、フォーマットされたデータ、スクリーンショット、凝縮されたHTML、ハイパーリンク、メタデータに変換し、LLMの使用をより良くサポートすることができる。さらにFirecrawlは、プロキシ設定、クローラー対策メカニズム、JavaScriptレンダリングなどの動的コンテンツの処理、出力解析、タスク調整などの複雑なタスクを処理する能力を持っている。開発者は、特定のタグの除外、認証が必要なページのクロール、最大クロール深度の設定など、クローラーの動作をカスタマイズすることができます。その信頼性は、様々な複雑な環境において、必要なデータへの効果的なアクセスを保証します。最新バージョンでは、大量のURLのバッチ処理もサポートしています。
- 複数のプログラミング言語SDKをサポート:Python、Node、Go、Rust
- いくつかのAI開発フレームワークと互換性があります: [Langchain (Python)](https://python.langchain.com/docs/integrations/document_loaders/firecrawl/ "Langchain (Python ")Langchain (Python ")"), [Langchain (JS)](https://js.langchain.com/docs/integrations/document_loaders/web_loaders/firecrawl "Langchain (JS "Langchain (JS)"), LlamaIndex, Crew.ai, Composio, PraisonAI, Superinterface, Vectorize
- ローコードAIプラットフォームのサポート:Dify、Langflow、Flowise AI、Cargo、Pipedream
- 自動化ツールのサポート:Zapier、Pabbly Connect
マークダウナー
最初の2つのツールにお金を払う余裕がない場合、または自分でデプロイするのに多くのリソースを必要とする場合、ウェブサイトのコンテンツをMarkdownフォーマットに変換するMarkdownerの使用を検討しよう。このツールは、自動クロール、LLMフィルタリング、詳細なMarkdownスキーマ、テキストおよびJSONレスポンスフォーマットをサポートしている。技術的には、Markdownerはウェブコンテンツの変換にCloudflare WorkersとTurndownライブラリを利用しています。
その他
同様のクローラには、webscraper、code-html-to-markdown(特にコードブロックを扱うのが得意)、MarkdownDown、gpt-api、web.scraper.workers.dev (コンテンツフィルタリングと有料コンテンツへのアクセスをサポートするツールを、マイナーな修正で常に使用。)、これらのツールは、自己展開後、オンラインコンテンツにアクセスするための大規模モデルのプラグインとして使用することができ、データの前処理段階に属する。
最後に書く
従来のクローラーツールは、LLMが新世代のクローラーツールを生み出し、開発者の経験を大幅に向上させ、必要なコンテンツをクロールするために柔軟にカスタマイズできるAPIを提供し、利便性を大幅に向上させたことを除けば、新しい技術を導入することも、探索することもあまりない。注目すべきは、LLM駆動のクローラー・ソリューションは実は クロード 例えば、マイクロソフトのUFOプロジェクト(Windowsコンピュータの人間による操作のシミュレーション)、スマートスペクトラムのAutoGLM、テンセントのAppAgent(携帯電話の人間による操作のシミュレーション)などは、ブラウザの操作をカバーする可能性のある研究の方向性の一例である。したがって、LLMを利用したクローラーツールは、現時点では一時的な解決策に過ぎず、将来的にはこのような包括的なプロジェクトに取って代わられることになるだろう。

![エージェントAI:マルチモーダルインタラクションのフロンティアの世界を探る [フェイフェイ・リー - クラシック必読] - チーフAIシェアリングサークル](https://www.aisharenet.com/wp-content/uploads/2025/01/6dbf9ac2da09ee1-220x150.png)