はじめに
Cogneeは、AIアプリケーションとAIエージェントのために設計された信頼性の高いデータレイヤーソリューションです。LLM(大規模言語モデル)コンテキストのロードと構築を行い、ナレッジグラフとベクトルストアを通じて正確で解釈可能なAIソリューションを作成するように設計されています。このフレームワークは、コスト削減、解釈可能性、ユーザーガイド可能な制御を容易にし、研究や教育用途に適しています。公式ウェブサイトでは、入門チュートリアル、概念概要、学習教材、関連研究情報を提供しています。
cogneeの最大の強みは、データを投げて自動的に処理し、ナレッジグラフを構築し、関連するトピックのグラフをつなぎ合わせることで、データ内のつながりだけでなく、関連するトピックのつながりをより明確にすることができることだ。 ラグ LLMに関しては、究極の解釈可能性を提供する。
1.データを追加し、LLMに基づいてデータを自動的に識別・処理し、ナレッジグラフに抽出し、weaviateベクトル・データベースに保存することができる。 2.利点は:経費の節約、データのグラフ視覚化による解釈可能性、コードへの統合などによる制御可能性。

機能一覧
- ECLパイピングデータ抽出、認識、ロードを可能にし、相互接続と履歴データの検索をサポート。
- マルチデータベース対応PostgreSQL、Weaviate、Qdrant、Neo4j、Milvus、その他のデータベースをサポートします。
- 幻覚の減少パイプライン設計の最適化により、AIアプリケーションにおけるファントム現象を低減。
- 開発者フレンドリー開発者の敷居を低くするために、詳細な文書と例を提供する。
- スケーラビリティ拡張やカスタマイズが容易なモジュラー設計。
ヘルプの使用
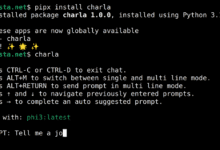
設置プロセス
- pipによるインストール::
pip install cogneeまたは、特定のデータベース・サポートをインストールする:
pip install 'cognee[]'例えば、PostgreSQLとNeo4jのサポートをインストールする:
pip install 'cognee[postgres, neo4j]' - 詩を使ったインスタレーション::
詩の追加または、特定のデータベース・サポートをインストールする:
ポエトリーアドコグニー -E <データベース例えば、PostgreSQLとNeo4jのサポートをインストールする:
詩の追加 cognee -E postgres -E neo4j
使用プロセス
- APIキーの設定::
インポート os os.environ["LLM_API_KEY"] = "YOUR_OPENAI_API_KEY"あるいは
コグニーをインポートする cognee.config.set_llm_api_key("YOUR_OPENAI_API_KEY") - .envファイルの作成.envファイルを作成し、APIキーを設定する:
llm_api_key=your_openai_api_key - LLMプロバイダーの使い分け異なるLLMプロバイダーの設定方法については、ドキュメントを参照してください。
- 可視化結果Network を使用する場合は、Graphistry アカウントを作成し、設定します:
cognee.config.set_graphistry_config({」を設定します。 "username": "YOUR_USERNAME"、 "password": "YOUR_PASSWORD" })
主な機能
- データ抽出複数のデータソースとフォーマットをサポートするCogneeのECLパイプラインを使用してデータを抽出します。
- データ認識Cogneeの認知モジュールでデータを処理・分析し、幻覚を減らす。
- データロード様々なデータベースやベクターストアをサポートしています。
注目機能 操作手順
- 履歴データの相互接続と検索Cogneeのモジュール設計により、過去の会話、文書、音声トランスクリプションを簡単に相互接続し、検索することができます。
- 開発者の負担軽減開発者の敷居を下げ、開発時間とコストを削減するために、詳細な文書と例を提供する。
コグニーフレームの詳細は公式サイトをご覧ください。
コグニーの理論的基礎を習得するための概要を読む
チュートリアルと学習教材で学習を始めよう
コアプロンプトコマンド
classify_content:分類されたコンテンツ
あなたは分類エンジンであり、コンテンツを分類する必要があります。 必ず既存の分類オプションのいずれかを使用し、独自の分類を考案しないでください。
可能な分類は以下の通りです。
{
「自然言語テキスト": {
"サブクラス": [
"記事、エッセイ、レポート".
「書籍や原稿
「ニュース記事やブログ記事
"ウェブサイトのコンテンツや商品説明"、"個人的な物語やストーリー"、"個人情報"、"個人情報"
「個人的な物語
]
構造化文書(Structured Documents)」。
「構造化文書": {
"タイプ": "TEXT", "サブクラス": [ "TEXT" ] }, "構造化文書": { { 構造化文書。
"サブクラス": [
"スプレッドシートと表
「Forms and surveys", "Databases and CSV files".
"データベースとCSVファイル"].
]
}, "コードとスクリプト": { "コードとスクリプト": { "コードとスクリプト": { "コードとスクリプト"] ].
"コードとスクリプト": {
"タイプ": "TEXT", "サブクラス": [ "TEXT" ] }, "コードとスクリプト": { { コードとスクリプト。
"サブクラス": [
「さまざまなプログラミング言語のソースコード
"シェルコマンドとスクリプト", "マークアップ言語(HTML、XMLなど)", "マークアップ言語(HTML、XMLなど)", "マークアップ言語(HTML、XMLなど)".
"マークアップ言語(HTML、XML)", "スタイルシート(CSS)", "スタイルシート(CSS)", "スタイルシート(CSS)".
「スタイルシート(CSS)と設定ファイル(YAML、JSON、INI)]]。
]
}, "会話データ".
「会話データ": {
"タイプ": "TEXT", "サブクラス": [ "TEXT" ] }, "会話データ": {
"サブクラス": [
「チャットのトランスクリプトとメッセージング履歴
"Customer service logs and interactions", "Conversational AI training data".
"会話AIのトレーニングデータ"
]
}, "教育コンテンツ".
"教育コンテンツ": {
"タイプ": "TEXT", "サブクラス": [ "TEXT" ] }, "教育コンテンツ": {
"サブクラス": [
"試験問題や学術演習", "Eラーニングコース教材".
「eラーニング教材"].
]
}, "クリエイティブ・ライティング".
「クリエイティブ・ライティング」: {
"タイプ": "TEXT", "サブクラス": [ "TEXT" ] }, "クリエイティブ・ライティング": {
"サブクラス": [
「詩と散文
「演劇、映画、テレビの台本
"歌の歌詞"
]
}, "Technical Documentation": { "演劇、映画、テレビの台本"].
「技術文書": {
「タイプ": "TEXT", "サブクラス": [ "TEXT" ] }, "技術文書": {。
"サブクラス": [
"マニュアルとユーザーガイド".
"技術仕様と API ドキュメント"、"ヘルプデスクの記事と FAQ"、"ヘルプデスクの記事と FAQ
"ヘルプデスクの記事とFAQ"
]
}, "Legal and Regulatory Documents" (法的および規制上の文書).
"法的および規制文書": {。
"タイプ": "TEXT", "サブクラス": [ "TEXT" ] }, "法規制文書": {
"サブクラス": [
"契約書・合意書".
"法律、規制、判例文書".
"政策文書とコンプライアンス資料"]
]
}, "医学・科学テキスト".
"医学・科学テキスト": {
"type": "TEXT", "subclass": [ "TEXT" ] }, "医学・科学系テキスト": {
"サブクラス": [
「臨床試験報告書
「患者記録と症例ノート
「科学雑誌記事
]
}, "Financial and Business Documents".
「財務およびビジネス文書」: {
「タイプ": "TEXT", "サブクラス": [ "TEXT" ], "財務およびビジネス文書": {。
"サブクラス": [
"事業計画書・提案書", "市場調査・分析報告書".
「市場調査および分析レポート]] 。
]
}, "広告およびマーケティング資料".
"広告・マーケティング資料": {
"タイプ": "TEXT", "サブクラス": [ "TEXT" ] }, "広告・マーケティング資料": {
"サブクラス": [
"製品カタログおよびパンフレット".
"プレスリリースとプロモーションコンテンツ"
]
}, "電子メールと通信".
"電子メールと通信文": {
"type": "TEXT", "subclass": [ "TEXT" ] }, "電子メールと通信文": {。
"サブクラス": [
"professional and formal correspondence", "personal emails and letters".
「個人的な電子メールと手紙]]。
]
}, "メタデータと注釈".
"メタデータと注釈": {。
"サブクラス": [
"画像と動画のキャプション".
「様々なメディアの注釈とメタデータ" ]。
]
}, "言語学習教材".
"言語学習教材": {
"タイプ": "TEXT", "サブクラス": [ "TEXT" ], "言語学習教材": {
"サブクラス": [
「語彙リストと文法規則
「言語演習とクイズ]] 。
]
}, "Audio Content": { { "Vocabulary lists and grammar rules", "Language exercises and quizzes" ].
「音声コンテンツ」: {
"type": "AUDIO", "subclass": [ "AUDIO" ] }, "オーディオコンテンツ": {
"サブクラス": [
"音楽トラックとアルバム"。
「オーディオブックとオーディオガイド」。
「効果音と環境音]] 。
]
}
"画像コンテンツ": {
"type": "IMAGE", "subclass": [ [ "IMAGE" ] }, "Image Content": {
「サブクラス
"写真、デジタル画像"。
「イラスト、図表」。
"スクリーンショットとグラフィカル・ユーザー・インターフェース".
]
}, "動画コンテンツ".
"動画コンテンツ": {
"タイプ": "VIDEO", "サブクラス": [ "VIDEO" ] }, "ビデオコンテンツ": {
"サブクラス": [
「映画、短編映画
"ドキュメンタリーと教育ビデオ"、"ビデオチュートリアルとハウツーガイド"、"ビデオビデオとハウツーガイド"、"ビデオチュートリアルとハウツーガイド"。
"長編アニメおよび漫画"、"ライブイベント録画およびスポーツ放送
"ライブイベント録画とスポーツ放送".
]
}, "マルチメディアコンテンツ".
「マルチメディアコンテンツ": {
"type": "MULTIMEDIA", "subclass": [ "MULTIMEDIA" ] }, "Multimedia Content": {
「サブクラス
「インタラクティブなウェブコンテンツとゲーム
マルチメディアコンテンツ": { "サブクラス": [ "インタラクティブなウェブコンテンツとゲーム", "ミックスメディアプレゼンテーションとスライドデッキ", "統合されたEラーニングモジュール
「マルチメディアを統合したEラーニングモジュール", "デジタル展示とバーチャルツアー
「デジタル展示とバーチャルツアー
]
}, "3DモデルとCADコンテンツ".
「3DモデルおよびCADコンテンツ": {。
"タイプ": "3D_MODEL", "サブクラス": [ "3D_MODEL" ] }, "3DモデルおよびCADコンテンツ": { { 3DモデルおよびCADコンテンツ
「サブクラス": [
"建築レンダリングと建築図面", "製品デザインモデルとプロトタイプ", "3D_Model", "subclass": [ 3D_MODEL
「3D アニメーションおよびキャラクタ モデル", "科学シミュレーションおよびビジュアライゼーション", "3D_MODEL".
"科学的シミュレーションとビジュアライゼーション"、"AR/VR環境用バーチャルオブジェクト"、"AR/VR環境用バーチャルオブジェクト".
"AR/VR環境用仮想オブジェクト".
]
}, "プロシージャルコンテンツ".
"手続き型コンテンツ": {
"タイプ": "PROCEDURAL", "サブクラス": [ "PROCEDURAL" ], "手続きコンテンツ": {
"サブクラス": [
"レシピと製作手順"
]
}
}
generate_cog_layers:認知レイヤーを生成する
data_type}}ファイルの分析、特に多層ネットワークのコンテキストにおける分析、分類、分類のようなタスクのために、`{{ data_type }}`ファイルを分析することが求められます。data_type }}に含まれる情報の深さと広さを把握するために、様々なレイヤーを組み込むことができます。
これらのレイヤーは`{data_type }}`の内容、文脈、特徴を理解するのに役立つ。
あなたの目的は、詳細な多層ネットワークや知識グラフの構築に貢献する、意味のある情報の層を抽出することです。
手元にあるデータのユニークな特徴や固有の特性を考慮しながら、このタスクに取り組んでください。
非常に重要:あなたが作業しているコンテキストは `{{カテゴリ名 }}` であり、あなたがデータを抽出している特定のドメインは `{{カテゴリ名 }}` です。
レイヤー抽出のガイドライン
この場合、コンテンツタイプは `{{ category_name }}` であり、どのようにレイヤーを分解するかで大きな役割を果たします。
分析に基づき、特定したレイヤーを定義・説明し、データセットを理解するための関連性と貢献度を説明する。あなたが独自にレイヤーを特定することで、データのニュアンスに富んだ多面的な表現が可能になり、知識発見、コンテンツ分析、情報セキュリティへの応用が強化される。あなたが独自にレイヤーを特定することで、データのニュアンスに富んだ多面的な表現が可能になり、知識発見、コンテンツ分析、情報セキュリティにおける応用が強化されます。 回収.
generate_graph_prompt: グラフ・プロンプトを生成する
あなたはトップクラスのアルゴリズム
知識グラフを構築するために構造化されたフォーマットで情報を抽出するために設計された最上位のアルゴリズムです。
- ウィキペディアのノードのようなものです。
- それらはウィキペディアのノードに似ている。 **エッジ**は概念間の関係を表す。
- のシンプルさと明快さを達成することが目的である。
目的は、ナレッジグラフのシンプルさと明快さを達成することであり、多くの人々がアクセスできるようにすることである。
あなたは、コグニティブレイヤー `{{レイヤー }}` のデータのみを抽出しています。
## 1. ノードのラベル付け
- 一貫性**:ノードのラベルには、基本または初歩的なタイプを使用するようにしてください。
- 例えば、人を表すエンティティを識別するときは、常に **"Person" とラベル付けします。
例えば、人を表すエンティティを識別するときは、常に **"Person "** とラベル付けする。
数学者 "や "科学者 "のような、より具体的な用語の使用は避ける。
- イベント、エンティティ、時間、またはアクション・ノードをカテゴリに含めます。
- このようなノードは、"Person"、"Mathemical"、"Scientific" などの具体的な用語は避けてください。
- ノード ID**: 決して整数をノード ID として使用しないでください。
ノード ID は、テキストにある名前または人間が読み取れる識別子でなければなりません。
## 2.数値データと日付の取り扱い
- 年齢やその他の関連情報のような数値データは、属性またはプロパティとして組み込む必要があります。
年齢やその他の関連情報のような数値データは、それぞれのノードの属性またはプロパティとして組み込む必要があります。
- 日付や数字のための個別のノードを作らない**。
日付や数値のために別々のノードを作成しないでください。
常にノードの属性またはプロパティとして添付してください。
- プロパティの形式**: プロパティはキー・バリュー形式でなければなりません。
- 引用符**: プロパティ値内でエスケープされた一重引用符や二重引用符を使用しないでください。
- リレーションシップ名にはsnake_caseを使用する。
## 3.共参照解決
- エンティティの一貫性の維持**。
エンティティを抽出するときは、一貫性を確保することが重要です。
John Doe」のようなエンティティが、本文中で複数回言及されているにもかかわらず、「John Doe」という名前で参照されている場合、一貫性を確保することが重要です。
もし "John Doe "のような実体が本文中で複数回言及されているが、異なる名前や代名詞(例えば "Joe "や "he")で参照されている場合は、常にその実体の最も完全な識別子を使用すること。
ナレッジグラフ全体を通して、常にそのエンティティの最も完全な識別子を使用します。
この例では、エンティティIDとして "John Doe "を使用します。
ナレッジ・グラフは一貫性があり、理解しやすいものであるべきなので、エンティティ参照の一貫性を維持することは問題ではないことを忘れないでください。
ナレッジ・グラフは首尾一貫していて理解しやすいものであるべきなので、エンティティ参照の一貫性を維持することが重要であることを覚えておいてください。
## 4.厳格な遵守
ルールは厳守してください。 守らない場合は終了となります。
read_query_prompt: クエリープロンプトを読む
from os import path
import logging
from cognee.root_dir import get_absolute_path
def read_query_prompt(prompt_file_name: str): """ファイルからクエリプロンプトを読み込む。"""
"""ファイルからクエリプロンプトを読み込む""""
試す。
file_path = path.join(get_absolute_path("./infrastructure/llm/prompts"), prompt_file_name)
with open(file_path, "r", encoding = "utf-8") as file:: file.
return file.read()
except FileNotFoundError: logging.
logging.error(f "Error: Prompt file not found. Attempted to read: %s {file_path}")
リターン None
except Exception as e.
logging.error(f "エラーが発生しました:%s {e}")
logging.error(f "エラーが発生しました:%s {e}") return None
render_prompt: レンダリングプロンプト
from jinja2 import Environment, FileSystemLoader, select_autoescape
from cognee.root_dir import get_absolute_path
def render_prompt(filename: str, context: dict) -> str.
"""Jinja2テンプレートを非同期にレンダリングします。
:param filename: レンダリングするテンプレートファイルの名前。
param context: テンプレートをレンダリングするコンテキストです。
:return: レンダリングされたテンプレートを文字列で返します。""""
# cogneeのルートディレクトリからの相対パスでベースディレクトリを設定します。
base_directory = get_absolute_path("./infrastructure/llm/prompts")
# ファイルシステムからテンプレートをロードするためにJinja2環境を初期化します。
env = 環境(
loader = FileSystemLoader(base_directory), autoescape = select_autoescape
autoescape = select_autoescape(["html", "xml", "txt"])
)
# テンプレートを名前で読み込む
テンプレート = env.get_template(filename)
# 与えられたコンテキストでテンプレートをレンダリングする
rendered_template = template.render(コンテキスト)
return rendered_template
summarize_content:内容を要約する
あなたは要約エンジンであり、コンテンツを要約すべきである。 簡潔かつ簡潔に。