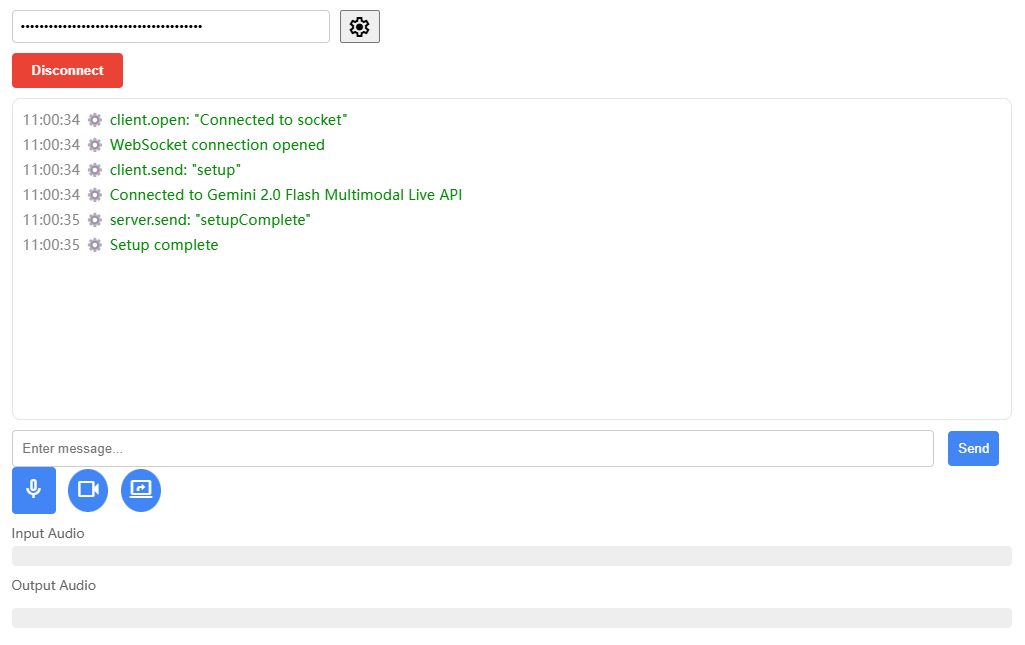
Zonos : Outils de synthèse vocale et de clonage de la parole de haute qualité

Introduction générale
Zonos est un outil open source de synthèse et de clonage de la parole développé par Zyphra. La version Zonos-v0.1 utilise des fonctions avancées de synthèse et de clonage de la parole. Transformateur La fonction de clonage de la parole de Zonos génère une sortie vocale de haute qualité après seulement quelques secondes d'audio de référence. L'outil prend en charge plusieurs langues, dont l'anglais, le japonais, le chinois, le français et l'allemand, et offre un contrôle précis de la qualité audio et de l'émotion. La fonction de clonage de la parole de Zonos génère une parole d'apparence très naturelle après avoir fourni seulement quelques secondes d'audio de référence. Les utilisateurs peuvent obtenir les poids des modèles et des exemples de code via GitHub et les essayer sur Huggingface.

Liste des fonctions
- Clonage de discours TTS à échantillonnage zéroLa parole : Un texte d'entrée et un échantillon de 10 à 30 secondes du locuteur permettent de générer une parole de haute qualité.
- Entrée du préfixe audioAjout de préfixes textuels et audio pour une meilleure correspondance avec le locuteur.
- Prise en charge multilingueLes langues suivantes sont prises en charge : l'anglais, le japonais, le chinois, le français et l'allemand.
- Qualité audio et contrôle des émotionsContrôle de la qualité : permet de contrôler finement de nombreux aspects du son généré, notamment la vitesse d'élocution, les variations de hauteur, la qualité audio et les émotions (joie, peur, tristesse et colère, par exemple).
- Génération de la parole en temps réelLa technologie de l'information est un atout majeur : elle permet la génération en temps réel d'un discours de haute fidélité.
Utiliser l'aide
Processus d'installation
- projet de clonageLe projet Zonos : Exécutez la commande suivante dans un terminal pour cloner le projet Zonos :
bash
git clone https://github.com/Zyphra/Zonos.git
cd Zonos - Installation des dépendancesPour installer les dépendances Python requises, utilisez la commande suivante :
bash
pip install -r requirements.txt - Télécharger le modèle de poidsTélécharger les poids de modèle nécessaires depuis Huggingface et les placer dans le répertoire du projet.
Utilisation
- Modèles de chargementChargement du modèle Zonos dans l'environnement Python :
import torch import torchaudio from zonos.model import Zonos from zonos.conditioning import make_cond_dict model = Zonos.from_pretrained("Zyphra/Zonos-v0.1-transformer", device="cuda") - Générer un discoursLa production vocale : Fournir du texte et des échantillons de locuteurs pour générer des sorties vocales :
python
wav, sampling_rate = torchaudio.load("assets/exampleaudio.mp3")
speaker = model.make_speaker_embedding(wav, sampling_rate)
cond_dict = make_cond_dict(text="Hello, world!", speaker=speaker, language="en-us")
conditioning = model.prepare_conditioning(cond_dict)
codes = model.generate(conditioning)
wavs = model.autoencoder.decode(codes).cpu()
torchaudio.save("sample.wav", wavs[0], model.autoencoder.sampling_rate) - Utilisation de l'interface GradioL'interface Gradio est recommandée pour la génération de la parole :
bashCela génère un
uv run gradio_interface.py
# 或者
python gradio_interface.pysample.wavenregistré dans le répertoire racine du projet.
Fonction détaillée du déroulement des opérations
- Clonage de discours TTS à échantillonnage zéro: :
- En saisissant le texte requis et un échantillon de locuteur de 10 à 30 secondes, le modèle génère une sortie vocale de haute qualité.
- Entrée du préfixe audio: :
- Ajoutez des préfixes textuels et audio pour enrichir la correspondance avec le locuteur. Par exemple, les préfixes audio de chuchotement peuvent être utilisés pour générer des effets de chuchotement.
- Prise en charge multilingue: :
- Sélectionnez la langue souhaitée (par exemple, l'anglais, le japonais, le chinois, le français ou l'allemand) et le modèle génère une sortie vocale dans la langue correspondante.
- Qualité audio et contrôle des émotions: :
- Utilisez la fonction Paramètres conditionnels du modèle pour contrôler minutieusement tous les aspects de l'audio généré, y compris la vitesse d'élocution, la variation de hauteur, la qualité audio et l'émotion (par exemple, la joie, la peur, la tristesse et la colère).
- Génération de la parole en temps réel: :
- Utilisez l'interface Gradio ou d'autres méthodes de génération en temps réel pour générer rapidement un discours de haute fidélité.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...