
NVIDIA ouvre le modèle graphique de Vincennes SANA : des images 4K directement à la volée pour des déploiements locaux

Récemment, NVIDIA (NVIDIA), en collaboration avec le Massachusetts Institute of Technology et l'université de Tsinghua, a lancé un modèle de génération d'images open-source appelé SANA, qui est non seulement capable de générer efficacement des images d'une résolution allant jusqu'à 4096 × 4096, mais qui a également une vitesse de génération très rapide.
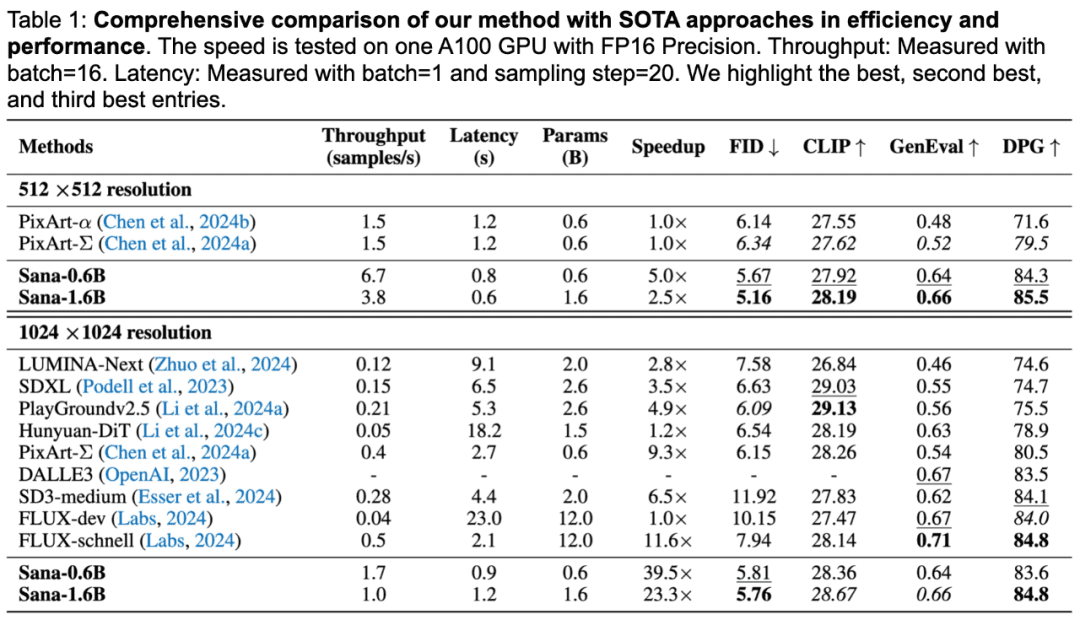
Les performances de SANA
SANA est caractérisé par le mot rapide, SANA-0.6B prend moins d'une seconde pour générer des images de résolution 1024×1024, 25 fois plus rapide que Flux-Dev, et 106 fois plus rapide que Flux-Dev pour générer des images de résolution 4096×4096.

En termes de qualité de génération, SANA obtient des résultats équivalents à ceux de Flux dans le test de référence DPG-Bench et à peine inférieurs à ceux du modèle Flux dans le test GenEval.
La conception de base de SANA
Le succès de SANA est dû à ses quatre conceptions de base :
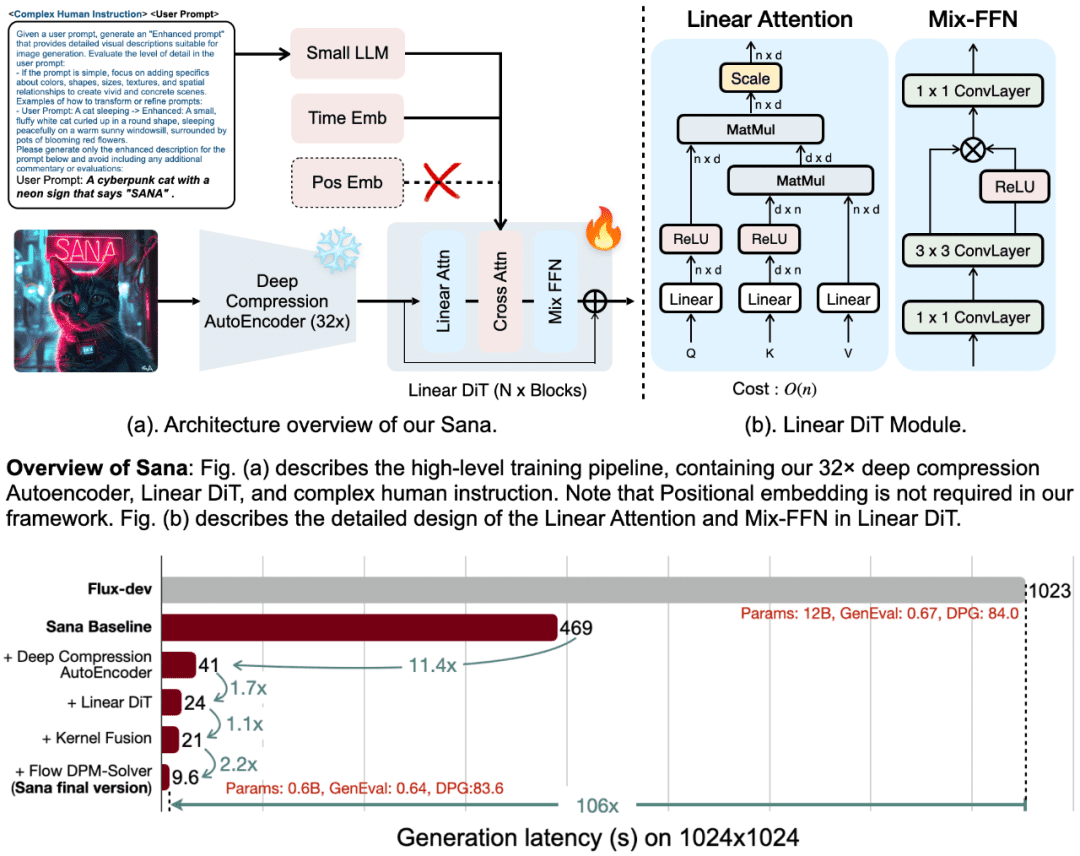
1. autoencodeur de compression profonde (DC-AE)
Alors que les autoencodeurs (AE) conventionnels compressent généralement les images par un facteur de 8, SANA introduit un autoencodeur à compression profonde qui augmente le facteur de compression jusqu'à 32. Cette conception réduit considérablement le nombre de marqueurs potentiels, ce qui permet à SANA de générer efficacement des images à très haute résolution (par exemple, une résolution de 4K) tout en réduisant de manière significative le coût informatique de l'apprentissage et de la génération.
2. le DIT linéaire (transformateur d'images de diffusion)
SANA utilise un nouveau mécanisme d'attention linéaire au lieu du mécanisme d'attention quadratique traditionnel, réduisant la complexité de O(N²) à O(N). Cette amélioration permet non seulement d'accroître l'efficacité de la génération d'images à haute résolution, mais aussi d'éliminer le besoin de codage positionnel, ce qui en fait le premier modèle DIT à ne pas nécessiter d'intégration positionnelle.
3. les petits LLMs décodeurs uniquement comme encodeurs de texte
SANA utilise de petits modèles linguistiques décodeurs tels que Gemma 2 comme encodeurs de texte, en remplacement des modèles traditionnels CLIP ou T5. Gemma possède des capacités supérieures de compréhension de texte et d'adhésion aux instructions, qui, combinées à une conception sophistiquée des instructions manuelles, améliorent de manière significative l'alignement image-texte.
4. des stratégies de formation et de raisonnement efficaces
SANA propose une stratégie d'étiquetage et d'entraînement automatique qui génère différentes re-capitalisations avec plusieurs modèles de langage visuel (VLM) et sélectionne des légendes de haute qualité sur la base de CLIPScore, accélérant ainsi la convergence des modèles et améliorant l'alignement texte-image. En outre, SANA introduit le résolveur Flow-DPM, qui réduit considérablement les étapes d'inférence et améliore encore l'efficacité de la génération.
Déploiement à faible coût et source ouverte
SANA-0.6B peut fonctionner sur un GPU d'ordinateur portable de 16 Go, générant des images d'une résolution de 1024×1024 en moins d'une seconde, et 22 Go de mémoire vidéo peuvent redresser des images d'une résolution de 4096×4096, une caractéristique qui fait que SANA n'est pas seulement adapté aux appareils informatiques haut de gamme, mais peut également fonctionner efficacement sur les ordinateurs portables d'utilisateurs ordinaires. d'utilisateurs ordinaires. De plus, NVIDIA a également annoncé qu'elle publierait le code et le modèle de SANA, afin de promouvoir la popularité et l'application de la technologie de génération de texte à partir d'images.
utiliser
NVIDIA a créé huit interfaces web 3090 que chacun peut essayer gratuitement. Il convient de mentionner que le modèle SANA peut être utilisé directement avec des mots guides chinois.
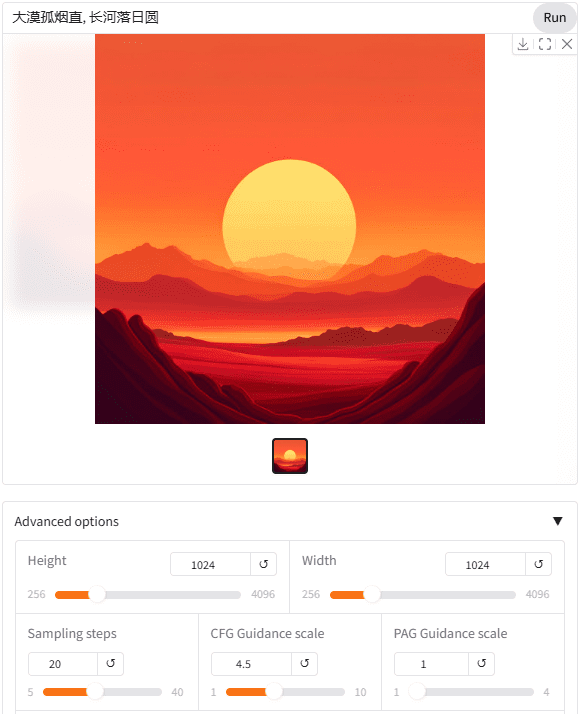
Il est même possible d'utiliser des mots repères avec des symboles iconiques, ce qui devrait bénéficier de l'utilisation du modèle de langage visuel Gemma2 2B en tant que codeur de texte.

Avec le plugin ComfyUI_ExtraModels, il est très facile d'utiliser les modèles SANA sur Comfyui natif également. L'installation du plugin est très simple, il n'est pas nécessaire de configurer ses propres dépendances, l'exécution après l'installation téléchargera automatiquement les fichiers de modèles requis.
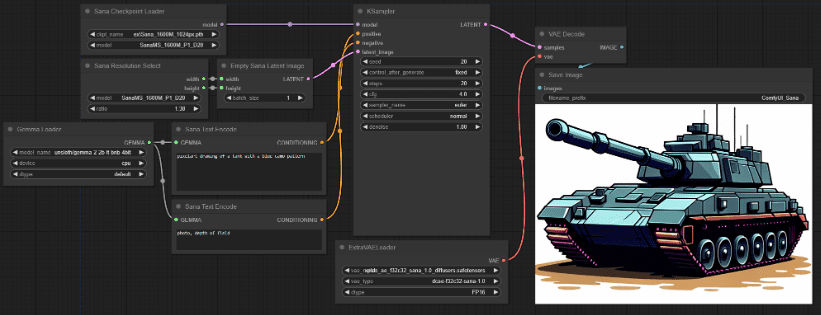
Avec un autoencodeur à compression profonde, un DIT linéaire, un petit LLM pour le décodeur uniquement, et des stratégies d'apprentissage et d'inférence efficaces, SANA est non seulement capable de générer efficacement des images à ultra-haute résolution, mais possède également de solides capacités d'alignement texte-image et des avantages en termes de déploiement à faible coût. Pour ceux qui ont besoin de produire rapidement des images, SANA est encore bon, c'est-à-dire qu'en termes d'écologie, il n'est pas comparable à Flux.

Page du projet :
github.com/NVlabs/Sana
Utilisation sur le web :
nv-sana.mit.edu
Plugin Comfyui :
github.com/Efficient-Large-Model/ComfyUI_ExtraModels
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes



Pas de commentaires...