-2")
Vision is All You Need : Building an Intelligent Document Retrieval System Using Visual Language Models (Vision RAG) (La vision est tout ce dont vous avez besoin : construire un système intelligent de recherche de documents en utilisant des modèles de langage visuel)

Introduction générale
Vision-is-all-you-need est un projet de démonstration d'un système visuel innovant RAG (Retrieval Augmented Generation) qui innove en appliquant la modélisation du langage visuel (VLM) au domaine du traitement des documents. Contrairement aux méthodes traditionnelles de découpage du texte, le système utilise directement le modèle de langage visuel pour traiter les images des pages des fichiers PDF, en les convertissant en format vectoriel pour le stockage. Le système adopte ColPali comme modèle de langage visuel de base, ainsi que la base de données vectorielles QDrant pour une recherche efficace, et intègre le modèle GPT4 ou GPT4-mini pour des questions et réponses intelligentes. Le projet réalise l'ensemble du processus, de l'importation de documents PDF à la récupération intelligente, en passant par la conversion d'images et le stockage vectoriel, et fournit une interface API pratique et une interface frontale conviviale, ce qui constitue une toute nouvelle solution dans le domaine du traitement intelligent des documents.
-1")
Adresse de démonstration : https://softlandia-ltd-prod--vision-is-all-you-need-web.modal.run/
Liste des fonctions
- Intégration de pages PDF: Convertit les pages d'un fichier PDF en images et les incorpore sous forme de vecteurs à l'aide d'un modèle de langage visuel.
- Stockage de la base de données vectorielleQdrant : Utiliser Qdrant comme base de données vectorielles pour stocker les vecteurs des images intégrées.
- Recherche de renseignementsL'utilisateur peut rechercher des vecteurs similaires à l'image incorporée et générer une réponse.
- Interface APIFournir une interface API RESTful pour faciliter les opérations de téléchargement, d'interrogation et d'extraction de fichiers.
- Interaction frontale: à travers Réagir L'interface frontale interagit avec l'API pour offrir une expérience conviviale.
Utiliser l'aide
Processus d'installation
- Installation de Python 3.11 ou plus récent: :
pip install modal
modal setup
- Configuration des variables d'environnement: Créer un
.envet ajouter ce qui suit :
OPENAI_API_KEY=your_openai_api_key
HF_TOKEN=your_huggingface_token
- exemple de fonctionnement: :
modal serve main.py
exemple d'utilisation
- Télécharger des fichiers PDFPour ce faire, ouvrez votre navigateur, allez à l'URL fournie par Modal et ajoutez-y ce qui suit
/docs. Cliquez surPOST /collectionssélectionnerTry it outpour télécharger le fichier PDF et l'exécuter. - Recherche de pages similaires: Utilisation
POST /searchenvoie des images de pages et des requêtes à l'API OpenAI et renvoie une réponse.
développement frontal
- Installation de Node.js: :
cd frontend
npm install
npm run dev
- Configuration de l'environnement frontalModification de la loi sur la protection des données
.env.developmentajoutez l'URL du backend :
VITE_BACKEND_URL=your_backend_url
- Lancement du front-end: :
npm run dev
Procédure d'utilisation détaillée
- Intégration de pages PDF: :
- utiliser
pypdfiumConvertissez des pages PDF en images. - Transmettre l'image à un modèle de langage visuel (par exemple ColPali) pour obtenir le vecteur d'intégration.
- Stocke les vecteurs d'intégration dans la base de données vectorielles Qdrant.
- utiliser
- Recherche de renseignements: :
- L'utilisateur saisit une requête et le vecteur d'intégration de la requête est obtenu à l'aide d'un modèle de langage visuel.
- Recherche de vecteurs d'intégration similaires dans la base de données vectorielle.
- La requête et la meilleure image correspondante sont transmises à un modèle (par exemple GPT4o) pour générer une réponse.
- Utilisation de l'API: :
- Téléchargement de fichiers PDF : via
POST /collectionsLes points d'extrémité téléchargent des fichiers. - Interroger des pages similaires : par
POST /searchLe point d'accès envoie une requête et reçoit une réponse.
- Téléchargement de fichiers PDF : via
- Interaction frontale: :
- Utilisez l'interface frontale React pour interagir avec l'API.
- Fournit des fonctions de téléchargement de fichiers, de saisie de requêtes et d'affichage de résultats.
Article de référence : construire un RAG ? Fatigué du découpage en morceaux ? Peut-être que la vision est tout ce dont vous avez besoin !
Au cœur de la plupart des solutions modernes d'IA générative (GenAI), il y a ce que l'on appelle l'intelligence artificielle. RAG La méthode Retrieval-Augmented Generation (RAG) est souvent appelée "RAG" par les ingénieurs en logiciel dans le domaine de l'IA appliquée. Les ingénieurs en logiciel dans le domaine de l'IA appliquée y font souvent référence sous le nom de "RAG". Avec la méthode RAG, les modèles de langage peuvent répondre à des questions basées sur les données propriétaires d'une organisation.
La première lettre R de RAG signifie Retrieve (Récupérer).récupération), qui fait référence au processus de recherche. Lorsqu'un utilisateur pose une question à un robot GenAI, le moteur de recherche en arrière-plan doit trouver exactement le matériel pertinent pour la question afin de générer une réponse parfaite et sans hallucinations.A et G se réfèrent respectivement à l'entrée des données récupérées dans le modèle de langage et à la génération de la réponse finale.
Dans le présent document, nous nous concentrons sur le processus d'extraction, car il s'agit de la partie la plus critique, la plus longue et la plus difficile de la mise en œuvre d'une architecture RAG. Nous commencerons par explorer le concept général de la recherche, puis nous présenterons le mécanisme traditionnel de recherche RAG basé sur les morceaux. La seconde moitié de l'article est consacrée à une nouvelle approche RAG qui s'appuie sur des données d'image pour la recherche et la génération.
Une brève histoire de la recherche d'information
Depuis des décennies, Google et d'autres grandes sociétés de moteurs de recherche tentent de résoudre le problème de la recherche d'informations - le mot clé étant "tenter". La recherche d'informations n'est toujours pas aussi simple que prévu. L'une des raisons est que les humains traitent l'information différemment des machines. Il n'est pas facile de traduire le langage naturel en requêtes de recherche sensées dans divers ensembles de données. Les utilisateurs avancés de Google peuvent être familiarisés avec toutes les techniques possibles pour manipuler le moteur de recherche. Mais le processus reste fastidieux et les résultats de la recherche peuvent être très insatisfaisants.
Grâce aux progrès réalisés dans le domaine des modèles linguistiques, la recherche d'informations dispose soudain d'une interface en langage naturel. Cependant, les modèles de langage sont peu performants lorsqu'il s'agit de fournir des informations basées sur des faits, car leurs données d'apprentissage reflètent un instantané du monde au moment de l'apprentissage. En outre, la connaissance est comprimée dans le modèle et le problème bien connu de l'illusion est inévitable. Après tout, les modèles de langage ne sont pas des moteurs de recherche, mais des machines à raisonner.
L'avantage d'un modèle linguistique est qu'on peut lui fournir des échantillons de données et des instructions et lui demander de répondre sur la base de ces données. Il s'agit d'un ChatGPT et les cas d'utilisation typiques d'interfaces d'IA conversationnelles similaires. Mais les gens sont paresseux et, avec le même effort, vous auriez pu accomplir la tâche vous-même. C'est pourquoi nous avons besoin de RAG : nous pouvons simplement poser des questions à une solution d'IA appliquée et obtenir des réponses basées sur des informations précises. Du moins, dans un monde où la recherche est parfaite, c'est la situation idéale.
Comment fonctionne l'extraction dans un système RAG traditionnel ?
Les méthodes de recherche RAG sont aussi variées que les implémentations RAG elles-mêmes. La recherche est toujours un problème d'optimisation et il n'existe pas de solution générique applicable à tous les scénarios : l'architecture IA doit être adaptée à chaque solution spécifique, qu'il s'agisse de recherche ou d'autres fonctionnalités.
Néanmoins, la solution de base typique est la technique dite du "chunking". Dans cette approche, les informations stockées dans la base de données (généralement des documents) sont divisées en petits morceaux, de la taille d'un paragraphe environ. Chaque morceau est ensuite converti en un vecteur numérique au moyen d'un modèle d'intégration associé à un modèle linguistique. Les vecteurs numériques générés sont stockés dans une base de données vectorielle dédiée.
Une recherche simple dans une base de données vectorielle est mise en œuvre comme suit :
- L'utilisateur pose une question.
- Générer un vecteur d'intégration à partir du problème.
- Effectuer une recherche sémantique dans une base de données vectorielle.
- Dans la recherche sémantique, la proximité entre les vecteurs de la question et les vecteurs de la base de données est mesurée mathématiquement, en tenant compte du contexte et de la signification du bloc de texte.
- La recherche vectorielle renvoie, par exemple, les 10 blocs de texte les plus correspondants.
Le bloc de texte récupéré est ensuite inséré dans le contexte (cue) du modèle linguistique et il est demandé au modèle de générer la réponse à la question initiale. Ces deux étapes après l'extraction constituent les phases A et G de RAG.
Les techniques de regroupement et autres traitements préalables à l'indexation peuvent avoir un impact significatif sur la qualité de la recherche. Il existe des dizaines de méthodes de prétraitement de ce type, et l'information peut également être organisée ou filtrée (réorganisation) après la recherche. Outre les recherches vectorielles, il est également possible d'utiliser des recherches traditionnelles par mots-clés ou toute autre interface de programmation permettant d'extraire des informations structurées. Il s'agit par exemple des techniques "text-to-SQL" ou "text-to-API" qui permettent de générer de nouvelles requêtes SQL ou API en fonction des questions posées par l'utilisateur. Pour les données non structurées, les techniques d'extraction les plus couramment utilisées sont le découpage (chunking) et la recherche vectorielle.
Le découpage n'est pas sans poser de problèmes. Le traitement de différents formats de fichiers et de données est fastidieux et un code de découpage distinct doit être écrit pour chaque format. Bien qu'il existe des bibliothèques logicielles prêtes à l'emploi, elles ne sont pas parfaites. En outre, il faut tenir compte de la taille des morceaux et des zones de chevauchement. Il faut ensuite relever le défi des images, des graphiques, des tableaux et autres données, pour lesquels la compréhension des informations visuelles et de leur contexte (tels que les titres, la taille des polices et d'autres indices visuels subtils) est cruciale. Et ces indices sont complètement perdus dans les techniques de découpage.
Que se passe-t-il si ce découpage n'est absolument pas nécessaire et que la recherche ressemble à celle d'un être humain parcourant une page entière d'un document ?
Les images conservent les informations visuelles
Les méthodes de recherche basées sur les images sont devenues possibles grâce au développement de modèles multimodaux avancés. La solution de conduite autonome de Tesla, qui repose entièrement sur des caméras, est un exemple de solution d'IA basée sur des données d'images. L'idée sous-jacente à cette approche est que les humains perçoivent leur environnement principalement par la vision.
Le même concept s'applique à la mise en œuvre de RAG. Contrairement au découpage, des pages entières sont indexées directement sous forme d'images, c'est-à-dire dans le même format que celui dans lequel elles seraient visualisées par un être humain. Par exemple, chaque page d'un document PDF est introduite dans un modèle d'IA dédié sous la forme d'une image (par ex. ColPali), le modèle crée des représentations vectorielles basées sur le contenu visuel et le texte. Ces vecteurs sont ensuite ajoutés à la base de données vectorielles. Nous pouvons désigner cette nouvelle architecture RAG par le terme de Récupération visuelle Génération améliorée(Vision Retrieval-Augmented Generation, ou V-RAG).
L'avantage de cette approche peut être une plus grande précision de recherche que les méthodes traditionnelles, car le modèle multimodal génère une représentation vectorielle qui prend en compte à la fois les éléments textuels et visuels. Le résultat de la recherche sera les pages entières du document, qui sont ensuite introduites sous forme d'images dans un puissant modèle multimodal tel que GPT-4. Le modèle peut référencer directement des informations dans des graphiques ou des tableaux.
V-RAG élimine la nécessité d'extraire d'abord des structures complexes (telles que des diagrammes ou des tableaux) en texte, puis de reconstruire ce texte dans un nouveau format, de le stocker dans une base de données vectorielle, de le récupérer, de le réorganiser pour former des indices cohérents et, enfin, de générer des réponses. Il s'agit là d'un avantage considérable lorsqu'il s'agit d'anciens manuels, de documents contenant de nombreux tableaux et de tout format de document centré sur l'homme dont le contenu ne se limite pas à du texte simple. L'indexation est également beaucoup plus rapide que les processus traditionnels de détection de la mise en page et d'OCR.
-3")
Statistiques sur la vitesse d'indexation dans les documents de ColPali
Néanmoins, l'extraction de texte à partir de documents reste précieuse et peut apporter une aide à la recherche d'images. Cependant, le découpage en morceaux sera bientôt l'une des nombreuses options disponibles pour la mise en œuvre d'un système de recherche d'IA.
Vision-RAG en pratique : Paligemma, ColPali et les bases de données vectorielles
Contrairement au RAG traditionnel basé sur le texte, les implémentations V-RAG nécessitent toujours l'accès à des modèles spécialisés et à des calculs GPU. La meilleure mise en œuvre de V-RAG consiste à utiliser des modèles développés spécifiquement à cette fin. ColPali.
ColPali est basé sur l'approche de recherche multi-vectorielle introduite par le modèle ColBERT et le modèle de langage multimodal Paligemma de Google. ColPali est un modèle de recherche multimodal, ce qui signifie qu'il comprend non seulement le contenu textuel, mais aussi les éléments visuels d'un document. En fait, les développeurs de ColPali ont étendu l'approche de recherche textuelle de ColBERT pour couvrir le domaine visuel, en utilisant Paligemma.
Lors de la création d'un embedding, ColPali divise chaque image en une grille de 32 x 32, chaque image comportant environ 1024 morceaux, chacun étant représenté par un vecteur à 128 dimensions. Le nombre total de morceaux est de 1030, car chaque image est également attachée à un jeton de commande "describe image".
La requête textuelle de l'utilisateur est convertie dans le même espace d'intégration afin de comparer les morceaux avec la partie de la requête dans le processus de recherche. Le processus de recherche lui-même est basé sur la méthode dite MaxSim du logiciel cet article Elle est décrite en détail dans. Cette méthode de recherche a été mise en œuvre dans de nombreuses bases de données vectorielles qui prennent en charge la recherche multi-vectorielle.
La vision est tout ce dont vous avez besoin - Démonstration et code V-RAG
Nous avons créé une démo V-RAG et le code est disponible sur le dépôt GitHub de Softlandia ! la vision est tout ce dont vous avez besoin Trouvez-le dans. Vous pouvez également trouver d'autres démonstrations d'Applied AI sous notre compte !
L'exécution de ColPali nécessite un GPU avec beaucoup de mémoire, donc la façon la plus simple de l'exécuter est sur une plateforme cloud qui permet l'utilisation des GPU. Pour cette raison, nous avons choisi l'excellente plateforme Modal, qui rend l'utilisation sans serveur des GPU simple et abordable.
Contrairement à la plupart des présentations académiques en ligne de Jupyter Notebook, notre La vision est tout ce dont vous avez besoin La démo offre une expérience pratique unique. Vous pouvez cloner le référentiel, le déployer vous-même et exécuter le pipeline complet sur des GPU en nuage en quelques minutes et gratuitement. Cet exemple d'ingénierie de l'IA de bout en bout se démarque en offrant une expérience du monde réel que la plupart des autres démos ne peuvent égaler.
Dans cette démo, nous avons également utilisé la fonction Qdrant La version en mémoire de Qdrant. Veuillez noter que lors de l'exécution de la démo, les données indexées disparaissent lorsque le conteneur sous-jacent cesse d'exister. Qdrant supporte la recherche multi-vectorielle depuis la version 1.10.0. La démo ne prend en charge que les fichiers PDF, dont les pages sont converties en images à l'aide de la bibliothèque pypdfium2. En outre, nous avons utilisé la bibliothèque transformers et le moteur colpali-engine créé par les développeurs de ColPali pour exécuter le modèle ColPali. D'autres bibliothèques, telles que opencv-python-headless (qui est mon travail, soit dit en passant), sont également utilisées.
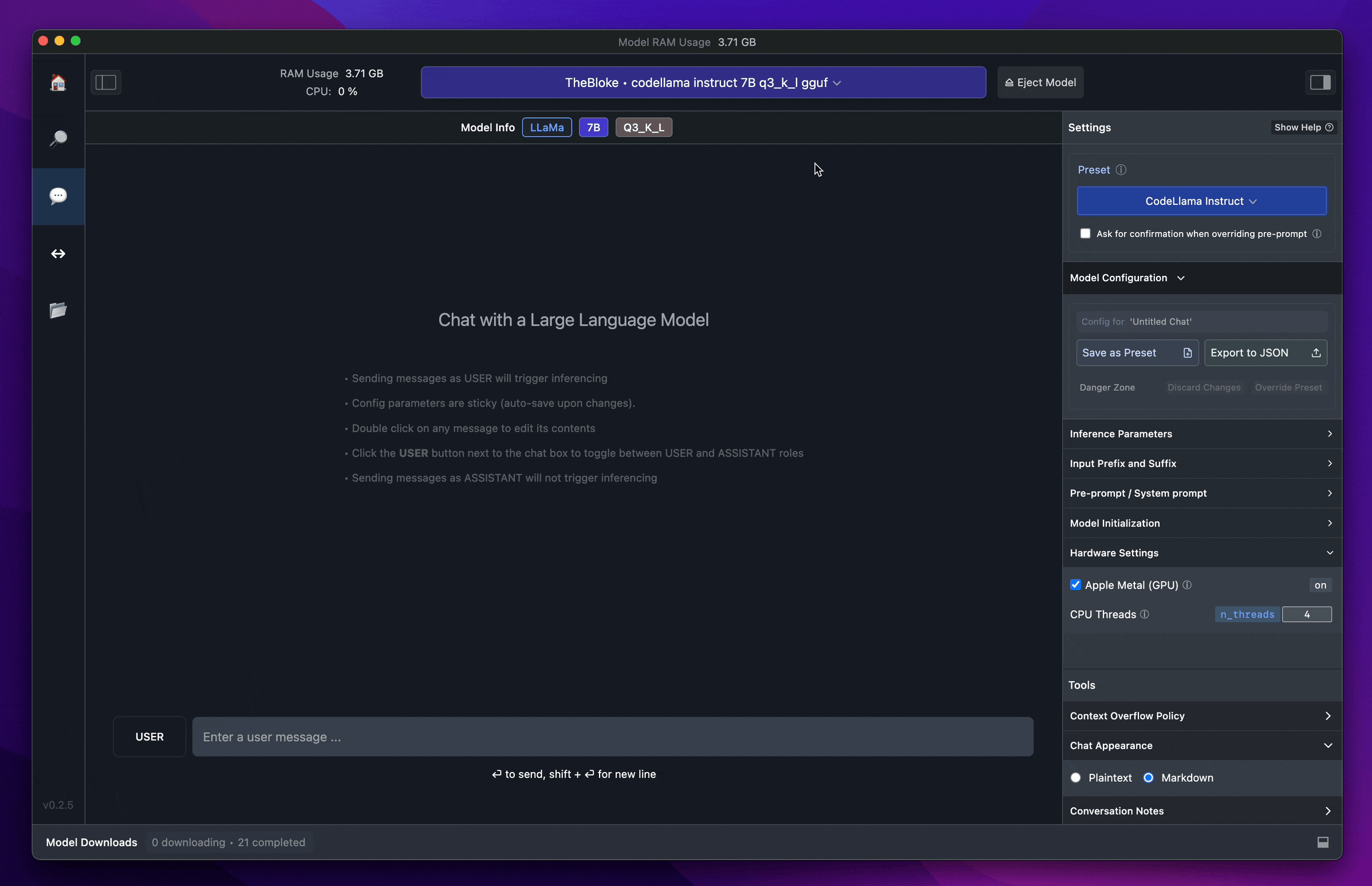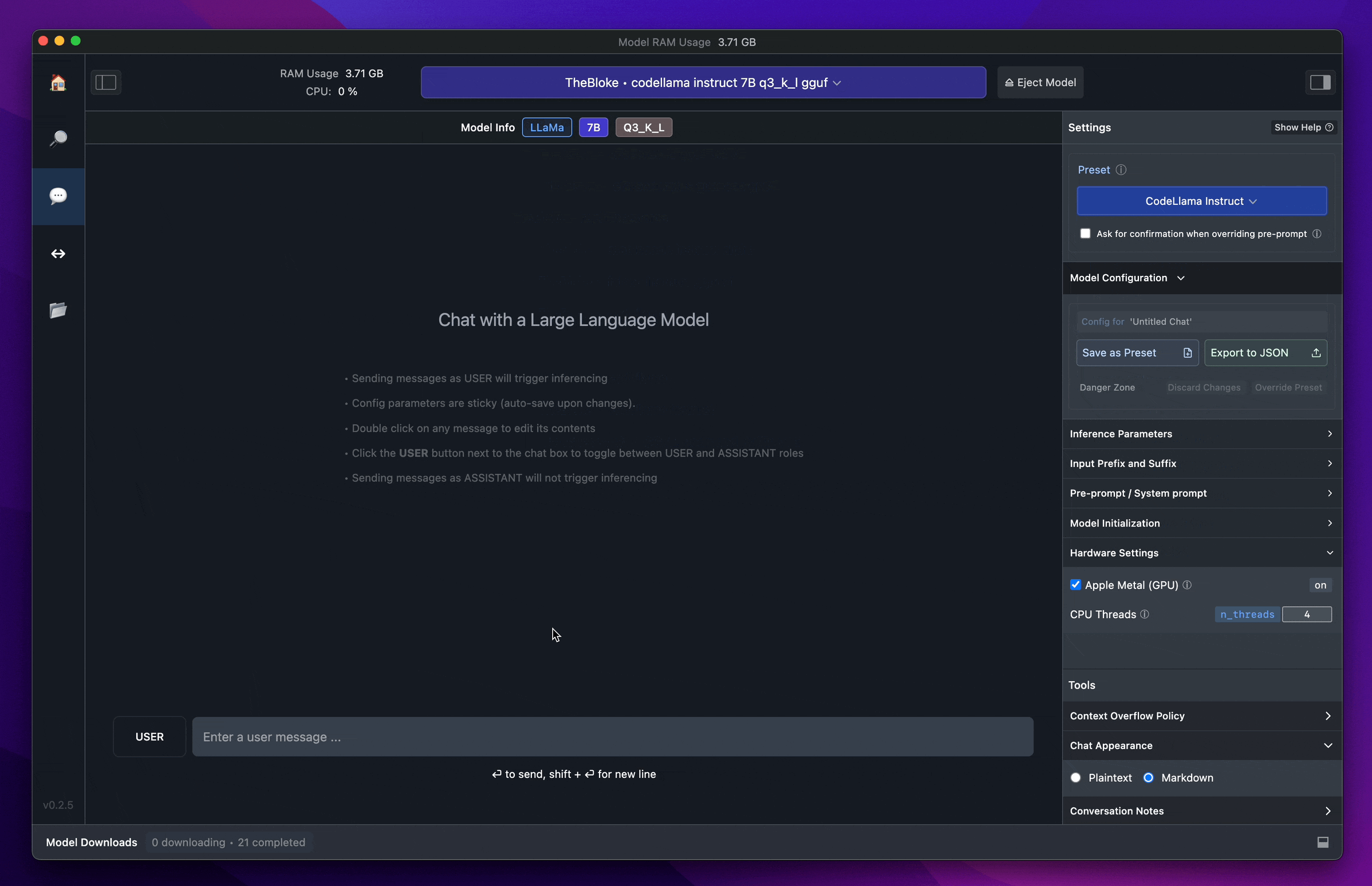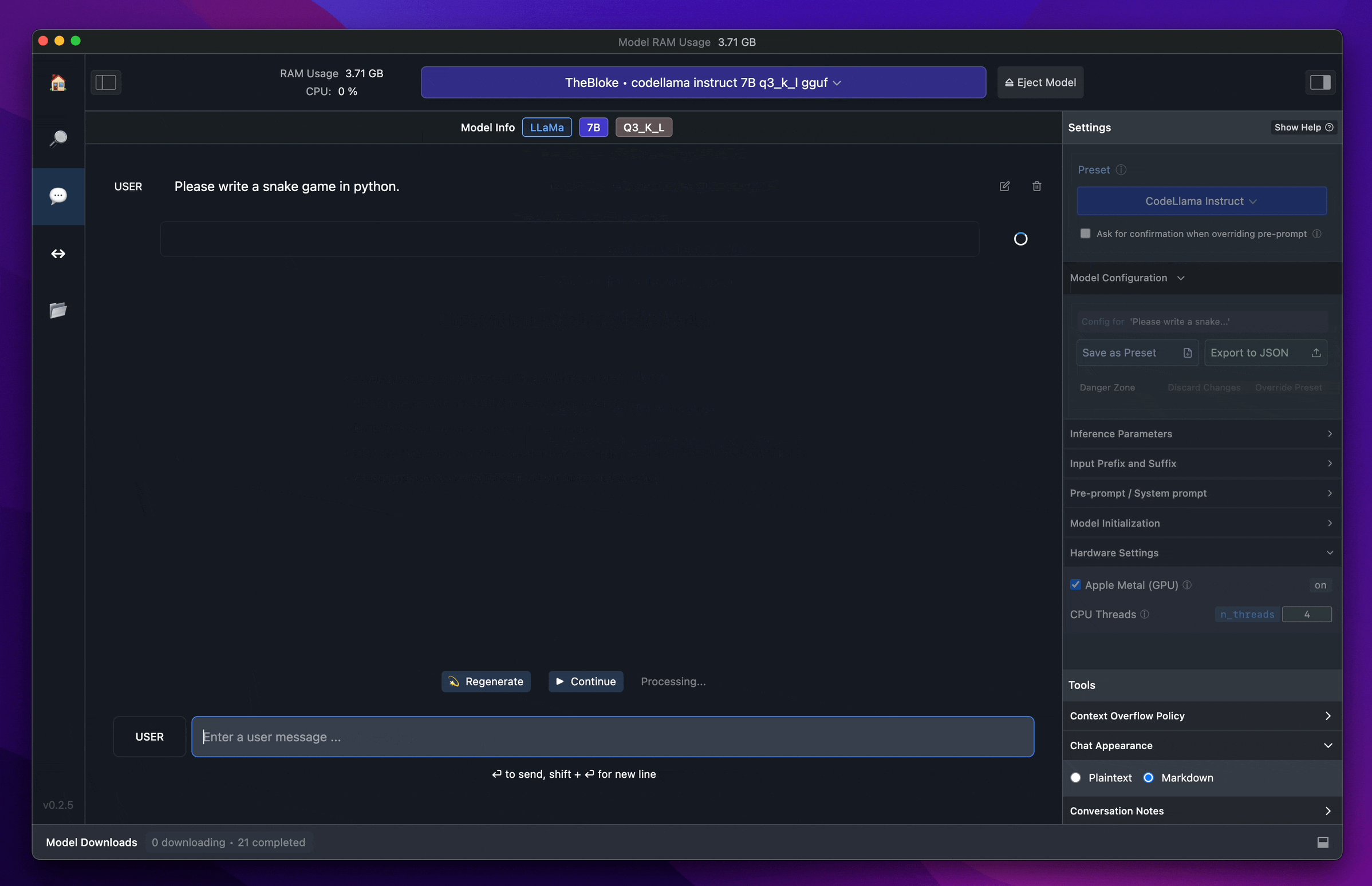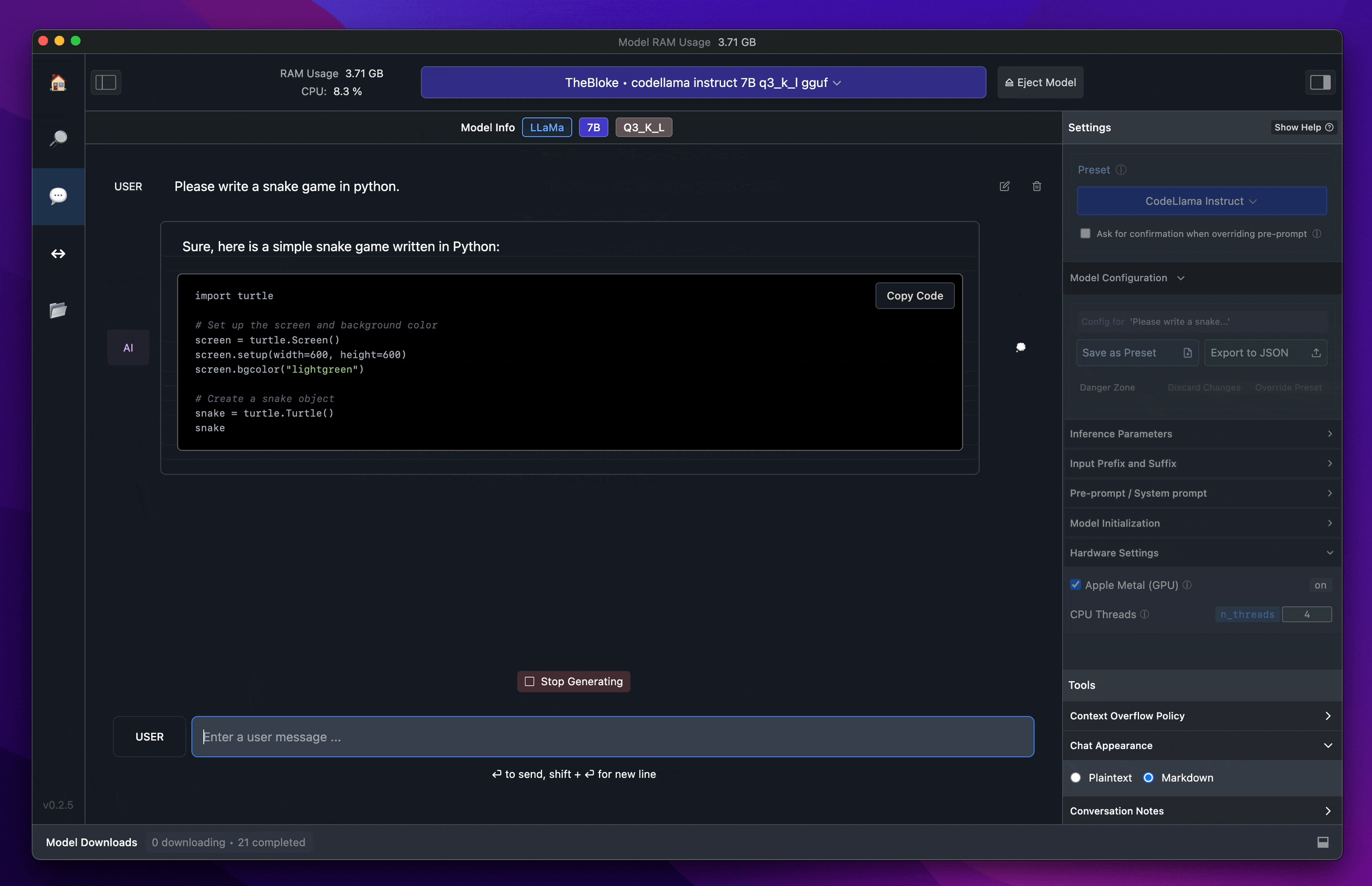
La démo fournit une interface HTTP pour indexer et poser des questions. En plus de cela, nous avons construit une interface utilisateur simple en utilisant React. L'interface utilisateur visualise également chaque Jeton de la carte d'attention, ce qui vous permet de visualiser facilement les parties de l'image que le modèle ColPali considère comme importantes.
-4")
Captures d'écran de la démo Vision is All You Need
La vision est-elle vraiment ce dont vous avez besoin ?
Malgré le titre de la démo, les modèles de recherche comme ColPali ne sont pas encore assez performants, en particulier pour les données multilingues. Ces modèles sont généralement entraînés sur un nombre limité d'exemples, qui sont presque toujours des fichiers PDF d'un type spécifique. Par conséquent, la démo ne prend en charge que les fichiers PDF.
Un autre problème est celui de la taille des données d'image et de l'intégration calculée à partir de ces données. Ces données occupent un espace considérable et les recherches sur de grands ensembles de données consomment beaucoup plus de puissance de calcul que les recherches vectorielles unidimensionnelles traditionnelles. Ce problème peut être partiellement résolu en quantifiant les encastrements dans des formes plus petites (même jusqu'au niveau binaire). Toutefois, cela entraîne une perte d'informations et une légère diminution de la précision de la recherche. Dans notre démo, la quantification n'a pas encore été mise en œuvre, car l'optimisation n'est pas importante pour la démo. En outre, il est important de noter que Qdrant ne supporte pas encore directement les vecteurs binaires.Mais il peut Permettre la quantification dans QdrantQdrant optimisera les vecteurs en interne. Cependant, MaxSim basé sur la distance de Hamming n'est pas encore pris en charge.
Pour cette raison, il est toujours recommandé d'effectuer un filtrage initial en conjonction avec des recherches traditionnelles par mots-clés avant d'utiliser ColPali pour l'extraction finale des pages.
Les modèles de recherche multimodale continueront d'évoluer, tout comme les modèles d'intégration qui génèrent traditionnellement des intégrations de texte. Je suis certain que l'OpenAI ou une organisation similaire publiera bientôt un modèle d'intégration de type ColPali qui portera la précision de la recherche à un niveau supérieur. Cependant, cela bouleversera tous les systèmes actuels basés sur le chunking et les méthodes traditionnelles de recherche vectorielle.
Sans une architecture d'IA flexible, vous resterez à la traîne
Des modèles de langage, des méthodes de recherche et d'autres innovations voient le jour à un rythme accéléré dans le domaine de l'IA. Plus que ces innovations elles-mêmes, c'est la capacité à les adopter rapidement qui importe, ce qui confère un avantage concurrentiel significatif aux entreprises qui sont plus rapides que leurs concurrents.
L'architecture IA de votre logiciel, y compris la fonction de recherche, doit donc être flexible et évolutive afin de pouvoir s'adapter rapidement aux dernières innovations technologiques. Avec l'accélération du développement, il est essentiel que l'architecture de base de votre système ne se limite pas à une solution unique, mais prenne en charge une gamme variée de méthodes de recherche - qu'il s'agisse de la recherche textuelle traditionnelle, de la recherche d'images multimodales ou même de modèles de recherche entièrement nouveaux.
ColPali n'est que la partie émergée de l'iceberg pour l'avenir. Les solutions RAG du futur combineront de multiples sources de données et technologies de recherche, et seule une architecture agile et personnalisable permettra leur intégration transparente.
Pour résoudre ce problème, nous proposons les services suivants :
- Évaluer l'état de votre architecture d'IA existante
- Plongez dans les technologies de l'IA avec vos responsables techniques et vos développeurs, y compris les détails au niveau du code.
- Nous examinons les méthodes de recherche, l'évolutivité, la flexibilité architecturale, la sécurité et la question de savoir si l'IA (générative) est utilisée conformément aux meilleures pratiques.
- Suggère des améliorations et énumère les prochaines étapes spécifiques du développement
- Mettre en œuvre une capacité d'IA ou une plateforme d'IA au sein de votre équipe
- Des ingénieurs spécialisés dans l'application de l'IA veillent à ce que vos projets d'IA ne prennent pas de retard par rapport aux autres tâches de développement.
- Développer des produits d'IA en tant qu'équipe de développement de produits externalisée
- Nous fournissons des solutions complètes basées sur l'IA, du début à la fin.
Nous aidons nos clients à acquérir un avantage concurrentiel significatif en accélérant l'adoption de l'IA et en assurant son intégration transparente. Si vous souhaitez en savoir plus, n'hésitez pas à nous contacter pour discuter de la manière dont nous pouvons aider votre entreprise à rester à la pointe du développement de l'IA.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...