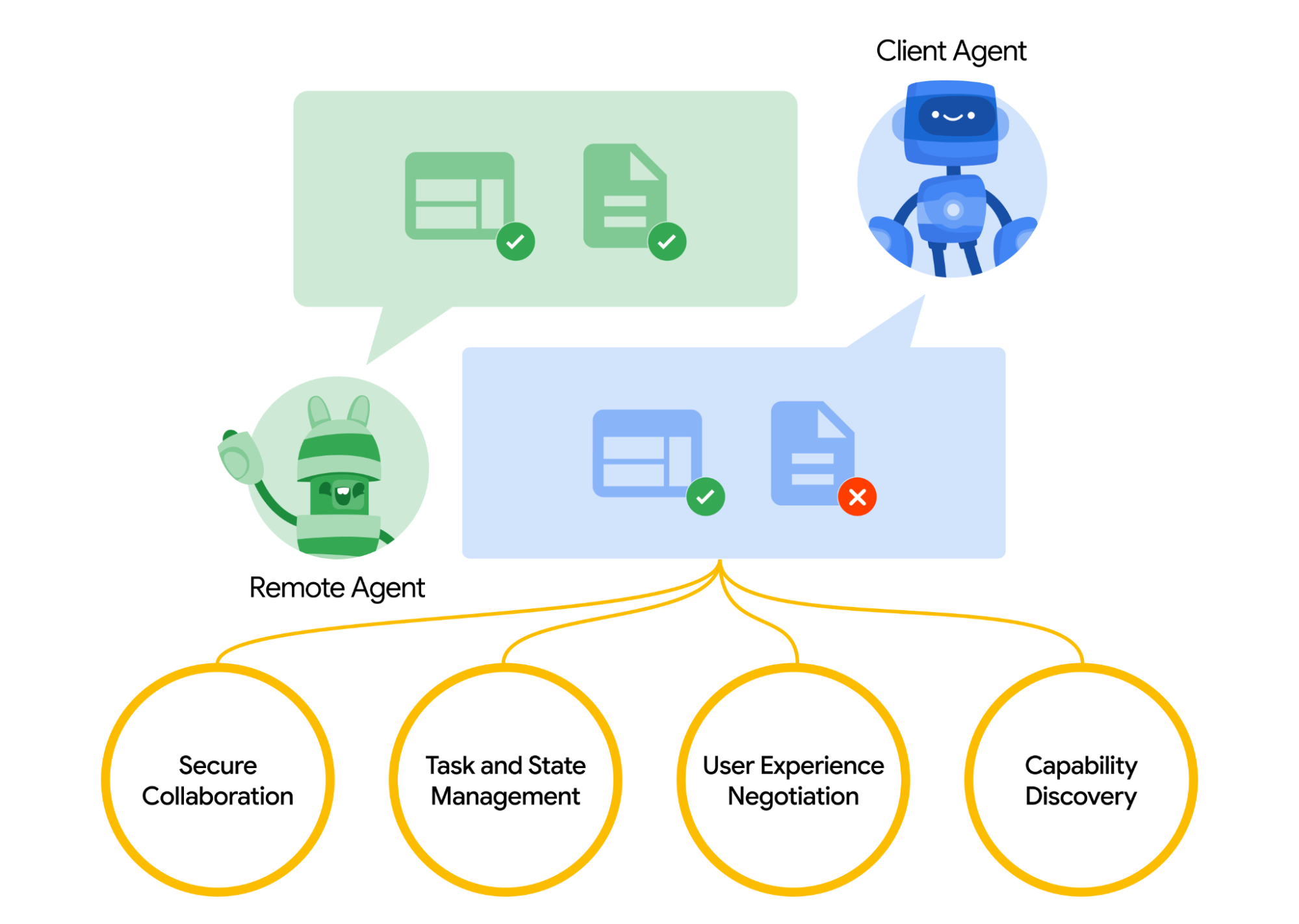
VOP : outil d'OCR pour l'extraction de diagrammes complexes et de formules mathématiques

Introduction générale
Versatile OCR Program est un outil de reconnaissance optique de caractères (OCR) open source conçu pour traiter des documents académiques et éducatifs complexes. Il peut extraire du texte, des tableaux, des formules mathématiques, des graphiques et des schémas à partir de PDF, d'images et d'autres documents, et générer des données structurées adaptées à l'apprentissage automatique. Il prend en charge plusieurs langues, dont l'anglais, le japonais et le coréen, et le format de sortie est JSON ou Markdown, ce qui est pratique pour les développeurs.


Liste des fonctions
- Extraction de textes multilingues, prise en charge de l'anglais, du japonais, du coréen, etc., pouvant être étendue à d'autres langues.
- Reconnaître les formules mathématiques et générer du code LaTeX et des descriptions en langage naturel.
- Analyse les tableaux, préserve la structure des lignes et des colonnes et produit des données structurées.
- Analyser les diagrammes et les schémas pour générer des annotations et des descriptions sémantiques (par exemple, "Ce diagramme montre les quatre étapes de la division cellulaire").
- Traiter des PDF à la mise en page complexe, en identifiant avec précision les paragraphes et les éléments visuels à forte teneur en formules.
- Produit un format JSON ou Markdown contenant un contexte sémantique afin d'optimiser l'apprentissage de l'IA.
- Utilisez DocLayout-YOLO, Google Vision API, MathPix et d'autres technologies pour améliorer la précision de la reconnaissance.
- Fournit une précision élevée de 90-95% pour des ensembles de données universitaires réels (par exemple, EJU Biology, Eastern University Maths).
- Prise en charge du traitement par lots pour traiter plusieurs fichiers.
Utiliser l'aide
Processus d'installation
Pour utiliser Versatile OCR Program, vous devez cloner le dépôt et configurer l'environnement. Voici les étapes détaillées :
- entrepôt de clones
S'exécute dans le terminal :git clone https://github.com/ses4255/Versatile-OCR-Program.git cd Versatile-OCR-Program - Créer un environnement virtuel
Il est recommandé d'utiliser Python 3.8 ou une version plus récente. Créer et activer un environnement virtuel :python -m venv venv source venv/bin/activate # Linux/Mac venv\Scripts\activate # Windows - Installation des dépendances
Installer les bibliothèques nécessaires au projet :pip install -r requirements.txtLes dépendances comprennent
opencv-python,google-cloud-vision,mathpix,pillowetc. Assurez-vous que la connexion au réseau est stable. - Configuration de la clé API
Le projet s'appuie sur des API externes (par exemple Google Vision, MathPix) pour le traitement OCR avancé :- Google Vision API: en
config/pour créer le fichiergoogle_credentials.jsonRemplissez la clé du compte de service. Pour obtenir la clé, veuillez consulter le siteConsole Google Cloud. - API MathPix: en
config/pour créer le fichiermathpix_config.jsonRemplirapp_idrépondre en chantantapp_key. Créez un compte MathPix pour obtenir la clé. - Les modèles de fichiers de configuration sont disponibles dans le projet
README.md.
- Google Vision API: en
- Vérifier l'installation
Exécutez le script de test pour vous assurer que l'environnement est correct :python test_setup.pyS'il n'y a pas d'erreur, l'installation est terminée.
flux de travail
Le programme Versatile OCR fonctionne en deux phases : l'extraction initiale et le traitement sémantique.
1. extraction initiale de l'OCR
être en mouvementocr_stage1.pyExtraire des éléments bruts (textes, tableaux, graphiques, etc.) :
python ocr_stage1.py --input sample.pdf --output temp/
--inputSpécifiez le fichier d'entrée (PDF ou image, par exemple PNG, JPEG).--outputSpécifie le répertoire des résultats intermédiaires contenant les coordonnées, les images recadrées, etc.- Prise en charge du traitement par lots : utiliser
--input_dirSpécifiez le dossier.
2. le traitement sémantique et le résultat final
être en mouvementocr_stage2.pyConvertir les données intermédiaires en sorties structurées :
python ocr_stage2.py --input temp/ --output final/ --format json
--inputSpécifie le répertoire de sortie pour la première étape.--formatSélectionner le format de sortie (jsonpeut-êtremarkdown).- Les résultats contiennent du texte, des descriptions de formules, des données tabulaires et un étiquetage sémantique des graphiques.
Principales fonctions
1. extraction de texte multilingue
Extraction de texte à partir de PDF ou d'images avec prise en charge multilingue :
python ocr_stage1.py --input document.pdf --lang eng+jpn+kor --output temp/
python ocr_stage2.py --input temp/ --output final/ --format markdown
--langSpécifiez la langue au formateng(en anglais),jpn(japonais),kor(coréen), Multi-langues+Connexions.- Le fichier de sortie contient le contenu textuel et le contexte sémantique, enregistrés sous forme de Markdown ou de JSON.
2. identification de la formule mathématique
Identifier les formules et générer des codes et des descriptions LaTeX. Par exemple, la formulex^2 + y = 5Le résultat est "une équation quadratique avec les variables x et y". Opération :
python ocr_stage1.py --input math.pdf --mode math --output temp/
python ocr_stage2.py --input temp/ --output final/ --format json
--mode mathReconnaissance de la formule d'activation.- Le résultat contient du code LaTeX et des descriptions en langage naturel.
3. analyse des tableaux
Extraire le tableau en préservant la structure des lignes et des colonnes :
python ocr_stage1.py --input table.pdf --mode table --output temp/
python ocr_stage2.py --input temp/ --output final/ --format json
--mode tableSpécialisé dans le traitement des formulaires.- La sortie est JSON avec les données des lignes et des colonnes et une description sommaire.
4. analyse graphique et schématique
Analyser des graphiques ou des diagrammes pour générer des annotations sémantiques. Par exemple, un graphique linéaire pourrait produire "Graphique linéaire montrant l'évolution de la température de 2010 à 2020". Action :
python ocr_stage1.py --input diagram.pdf --mode figure --output temp/
python ocr_stage2.py --input temp/ --output final/ --format markdown
--mode figureActiver l'analyse des graphiques.- La sortie contient la description de l'image, l'extraction des points de données et le contexte.
Conseils et astuces
- Amélioration de la précisionLes fichiers à haute résolution (300 DPI recommandés) sont à saisir. Ajouter au moment de l'exécution
--dpi 300Optimiser l'analyse des images. - fichier de lotUtilisation de la
--input_dir data/Traite tous les fichiers du dossier. - langue personnalisée: : Editorial
config/languages.jsonPour ajouter une langue, vous devez installer le modèle OCR correspondant (par exemple, le pack linguistique de Tesseract). - Journal de débogage: Ajouter
--verboseAfficher des informations détaillées sur le fonctionnement de l'appareil. - sortie compriméeUtilisation de la
--compressRéduire la taille du fichier JSON.
mise en garde
- Veillez à ce que les documents d'entrée soient clairs ; des documents de mauvaise qualité peuvent réduire la précision de la reconnaissance.
- Un réseau stable est nécessaire pour l'API externe, et il est recommandé de configurer une clé de secours.
- Le répertoire de sortie doit disposer de suffisamment d'espace disque, les gros PDF pouvant générer des fichiers plus volumineux.
- En vertu de la licence GNU AGPL-3.0, les projets dérivés doivent mettre le code source à la disposition du public.
- Le projet prévoit de publier l'intégration du pipeline d'IA d'ici un mois, alors restez à l'écoute.
Grâce à ces étapes, les utilisateurs peuvent rapidement démarrer, traiter des documents complexes et générer des données d'entraînement à l'IA.
scénario d'application
- Extraction des données de la recherche universitaire
Les chercheurs peuvent extraire des formules, des tableaux et des graphiques des copies d'examen ou des dissertations pour générer des ensembles de données avec des annotations sémantiques. Par exemple, les copies d'examen de mathématiques de l'Université de l'Est ont été converties en JSON pour l'entraînement au modèle géométrique. - Numérisation des ressources éducatives
Les écoles peuvent convertir des manuels ou des épreuves d'examen en format électronique, extraire des textes et des graphiques multilingues et générer des archives consultables. Convient au traitement multilingue des programmes internationaux. - Construction d'ensembles de données pour l'apprentissage automatique
Les développeurs peuvent extraire des données structurées de documents universitaires pour générer des ensembles d'entraînement de haute qualité. Par exemple, l'extraction de diagrammes de division cellulaire à partir d'articles de biologie, l'étiquetage de descriptions d'étapes et l'entraînement de modèles de reconnaissance d'images. - Traitement des documents d'archives
Les bibliothèques peuvent convertir des documents académiques historiques au format numérique, en préservant les formules et les structures des tableaux afin d'améliorer l'efficacité de la recherche. Prise en charge du traitement PDF des mises en page complexes. - Outils d'analyse de l'examen
Les établissements d'enseignement peuvent analyser le contenu des questionnaires, extraire les types de questions et les graphiques, générer des rapports statistiques et optimiser la conception de l'enseignement.
QA
- Quels sont les formats d'entrée pris en charge ?
Les PDF et les images (PNG, JPEG) sont pris en charge. Il est recommandé d'utiliser des PDF à haute résolution pour garantir l'exactitude des données. - Comment puis-je améliorer la précision de la reconnaissance des formulaires ?
Utiliser une documentation claire pour permettre--dpi 300. Pour les tableaux japonais, l'API Google Vision est plus performante que MathPix et peut être utilisée dans l'applicationconfig/Ajustement moyen. - Dois-je utiliser une API payante ?
Les API Google Vision et MathPix nécessitent un compte payant, mais les modules open source tels que DocLayout-YOLO sont gratuits. Il est recommandé de configurer l'API pour obtenir les meilleurs résultats. - Comment ajouter une nouvelle langue ?
compilateurconfig/languages.jsonAjouter le code de la langue et le modèle OCR (par exemple, le pack linguistique Tesseract). Redémarrez le programme pour qu'il prenne effet. - Que faire si le fichier de sortie est trop volumineux ?
dépense ou frais--compressCompresser JSON, ou choisir le format Markdown. Il est également possible de limiter le module de sortie, par exemple pour n'extraire que du texte (--mode text). - Comment puis-je participer à l'amélioration des projets ?
Les Pull Requests peuvent être soumis via GitHub ou en contactant l'auteur à ses425500000@gmail.com. N'hésitez pas à contribuer au code ou à donner votre avis sur les problèmes.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes

Pas de commentaires...