
Recommandé 12 logiciels gratuits de gestion du personnel numérique pour un déploiement local

Dans le cadre du développement rapide de l'IA, les humains numériques (Digital Humans) sont arrivés à maturité et peuvent être générés rapidement et à faible coût. En raison du large éventail de scénarios d'application commerciale, il a fait l'objet d'une attention particulière. Que ce soit dans la réalité virtuelle (VR), la réalité augmentée (AR) ou la production cinématographique et télévisuelle, le développement de jeux, la promotion de marques, les humains numériques jouent un rôle important.
D'une manière générale, il existe des personnes numériques modélisées en 3D (y compris la capture de mouvements), des personnes numériques à image statique en 2D (y compris des personnes réelles) et des personnes numériques de type "échange de visages".
Cet article se concentre sur la classe d'image de clonage d'image personnelle de l'homme numérique, qui appartient à l'image statique 2D de l'homme numérique, et contient trois points de fonction de base : l'image réelle, le clonage de la voix et la synchronisation de la bouche.
Note 1 : Certains projets n'incluent pas la partie génération de voix (clonage), ce n'est pas la question, il est possible de la déployer séparément, il y a beaucoup d'excellents marchés.Projet de clonage de la voix par l'IA.
Note 2 : Actuellement, la qualité des figures statiques en 2D varie principalement au niveau de la synchronisation de leurs bouches et du naturel de leurs "mouvements vidéo". Vous pouvez essayer d'optimiser ces aspects séparémentsynchronisation des lèvresNœuds.
Note 3 : Le changement de visage et le clonage de la voix sont également un moyen rapide de générer une personne numérique, qui convient pour maintenir inchangées l'image et la voix des orateurs publics, et n'est pas inclus dans les programmes suivants. La technologie avancée d'échange de visages par vidéo est risquée lorsqu'elle devient populaire, c'est pourquoi elle n'est pas présentée.
AIGCPanel : clone open-source du système d'intégration digital man, déploiement en un clic du client digital man gratuit
AigcPanel est un système de production d'intelligence artificielle pour tous les utilisateurs, développé avec la technologie electron+vue3+typescript, permettant un déploiement en un clic sur le système Windows. Le système est conçu pour être convivial, de sorte que même les utilisateurs ayant de faibles connaissances techniques peuvent facilement le maîtriser. Les principales fonctions comprennent la synthèse humaine vidéo numérique, la synthèse vocale, le clonage de la parole, etc., et offrent des fonctions parfaites de gestion des modèles locaux. Le système prend en charge l'interface multilingue (y compris le chinois simplifié et l'anglais) et intègre MuseTalk, cosyvoice et d'autres packages de démarrage en un clic pour plusieurs modèles matures. Il est particulièrement intéressant de mentionner que le système prend en charge la technologie de correspondance entre les images vidéo et la transcription vocale pour la synthèse vidéo, et qu'il offre de nombreuses options de réglage des paramètres sonores pour la synthèse vocale. En tant que projet open source, AigcPanel est publié sur la base du protocole AGPL-3.0, tout en mettant l'accent sur une utilisation conforme et en interdisant explicitement son utilisation dans toute activité illégale ou illicite.

DUIX : Des personnes numériques intelligentes pour une interaction en temps réel, permettant un déploiement multiplateforme en un seul clic
DUIX (Dialogue User Interface System) est une plateforme d'interaction humaine numérique pilotée par l'IA et créée par Silicon Intelligence. DUIX prend en charge le déploiement en un clic sur de multiples plateformes telles qu'Android et iOS, ce qui permet à chaque développeur de créer facilement des agents humains numériques intelligents et personnalisés qui peuvent être appliqués à diverses industries. Avec un faible coût de déploiement, une faible dépendance au réseau et des fonctionnalités variées, la plateforme est capable de répondre aux besoins de multiples industries telles que la vidéo, les médias, le service client, la finance, la radio et la télévision.

EchoMimic : animation de portraits réalistes pilotée par le son
EchoMimic est un projet open source visant à générer des animations de portraits réalistes à partir de données audio. Développé par la division Terminal Technologies d'Ant Group, le projet utilise des conditions de points de repère modifiables pour générer des vidéos de portraits dynamiques combinant des points de repère audio et faciaux. EchoMimic a été comparé de manière exhaustive à de nombreux ensembles de données publics et propriétaires, démontrant ses performances supérieures dans les évaluations quantitatives et qualitatives.
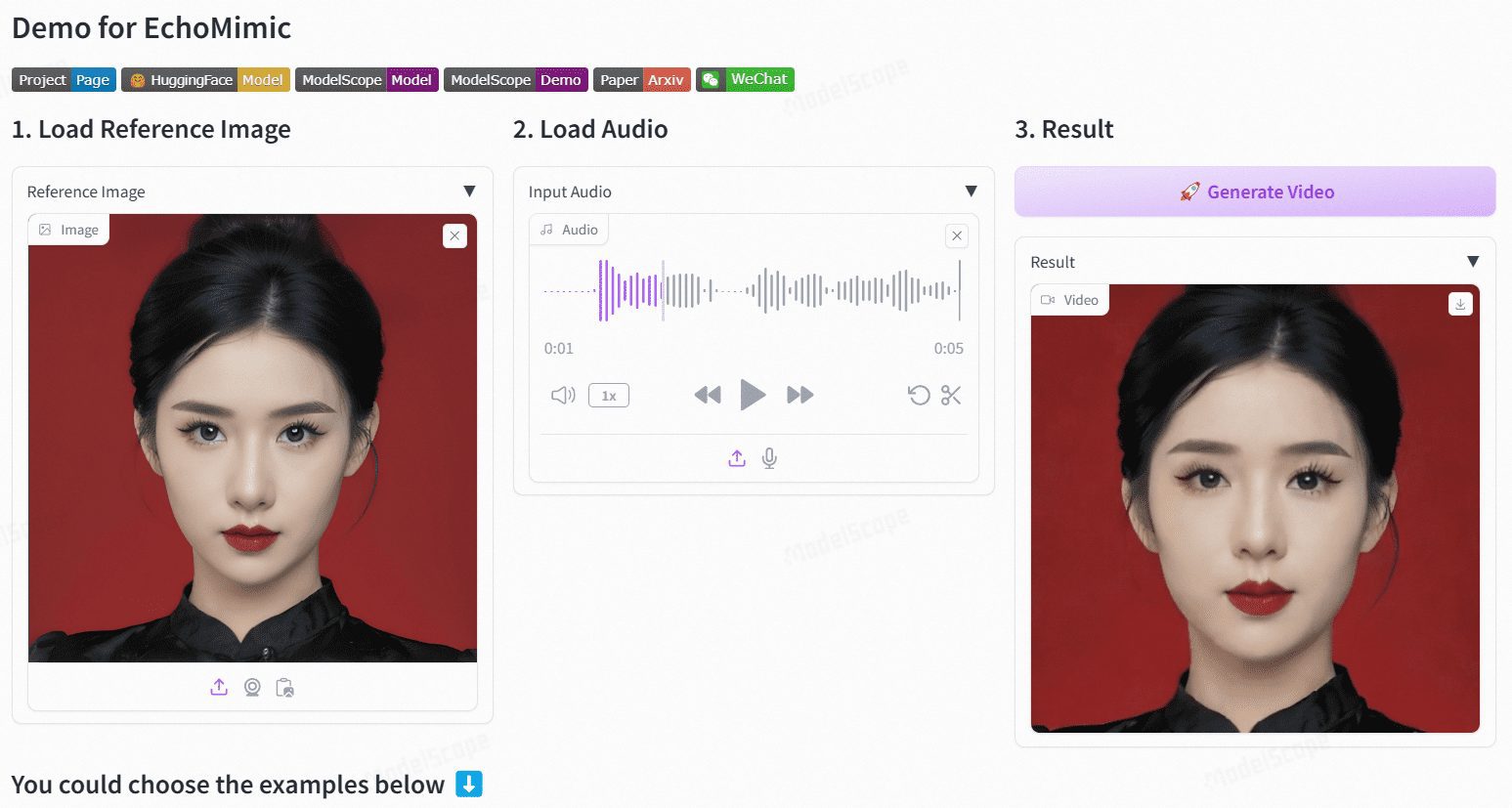
Sonic : une nouvelle solution open source pour les humains numériques, la génération audio d'expressions faciales pour des vidéos de démonstration numériques vivantes
Sonique Sonic est une plateforme innovante axée sur la perception globale de l'audio, conçue pour générer des portraits animés en fonction de l'audio. Développée par une équipe de chercheurs de Tencent et de l'université de Zhejiang, la plateforme utilise les informations audio pour contrôler les expressions faciales et les mouvements de la tête afin de générer des vidéos animées naturelles et fluides. Ces technologies permettent à Sonic de générer des vidéos stables et réalistes avec différents styles d'images et différents types d'entrées audio.
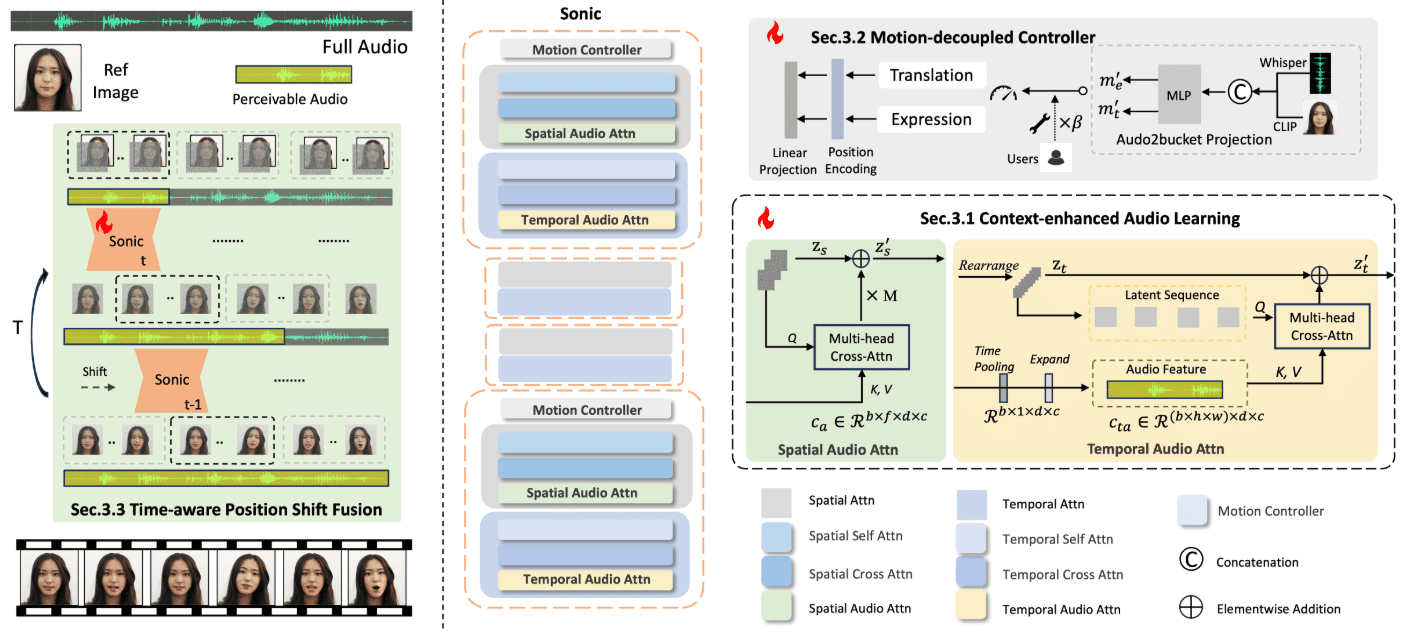
Hallo2 : génération audio de portraits vidéo synchronisés avec les lèvres et l'expression (avec installation Windows en un clic)
Hallo2 est un projet open source développé conjointement par l'Université de Fudan et Baidu pour générer des animations de portraits en haute résolution par le biais de la génération audio. Le projet utilise des réseaux adversoriels génératifs (GAN) avancés et des techniques d'alignement temporel pour atteindre une résolution 4K et générer jusqu'à une heure de vidéo.
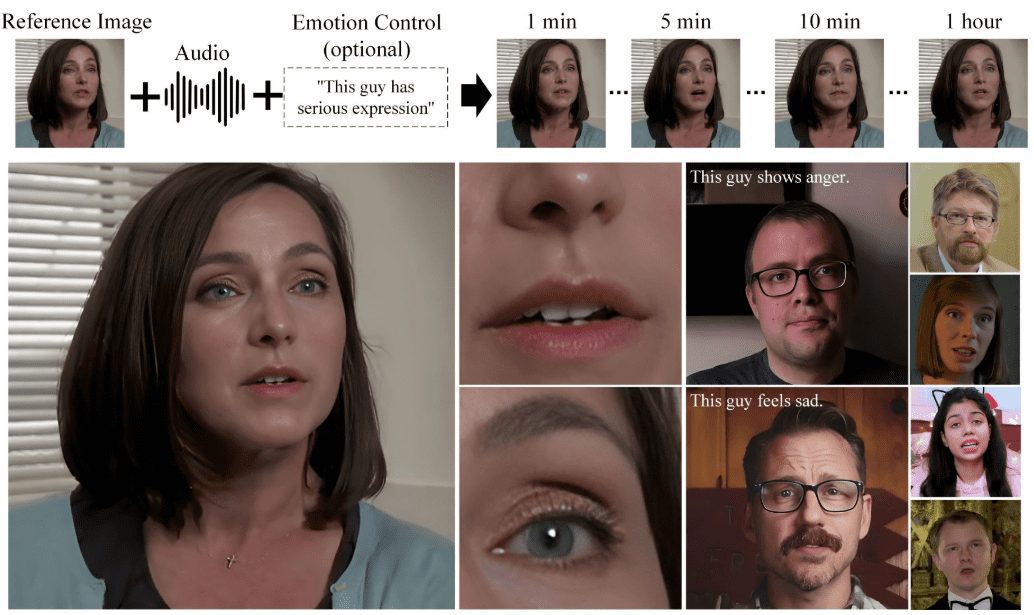
VideoChat : personne numérique interactive vocale en temps réel avec clonage d'images et de tonalités personnalisées, prenant en charge des solutions vocales de bout en bout et des solutions en cascade.
VideoChat est un projet d'interaction vocale en temps réel avec un humain numérique basé sur une technologie open-source, prenant en charge des schémas vocaux de bout en bout (GLM-4-Voice - THG) et des schémas en cascade (ASR-LLM-TTS-THG). Le projet permet aux utilisateurs de personnaliser l'image et le timbre de l'humain numérique, et prend en charge le clonage du timbre et la synchronisation labiale, la sortie vidéo en continu, et une latence du premier paquet aussi faible que 3 secondes. Les utilisateurs peuvent découvrir ses fonctionnalités grâce à des démonstrations en ligne, ou le déployer et l'utiliser localement grâce à une documentation technique détaillée.
TalkingAvatar : plateforme vidéo d'avatars IA pour la création et l'édition d'avatars IA, basée sur l'arithmétique native du client Windows
TalkingAvatar est une plateforme d'avatars d'IA de premier plan qui offre une solution complète de personne numérique d'IA. Elle offre aux utilisateurs un moyen révolutionnaire de créer, d'éditer et de personnaliser du contenu vidéo. Grâce à une technologie d'IA avancée, les utilisateurs peuvent facilement réécrire des vidéos, cloner des voix, synchroniser des lèvres et créer des vidéos personnalisées. Qu'il s'agisse de repiquer une vidéo existante ou de créer une nouvelle histoire à partir de zéro, TalkingAvatar est là pour vous aider.

SadTalker : Faire parler les photos | Audio Synchronisation de la bouche | Vidéo Synchronisation de la bouche synthétisée | Personnes numériques gratuites
SadTalker est un outil open source qui combine une simple photo de portrait avec un fichier audio pour créer des vidéos réalistes de têtes parlantes pour un large éventail de scénarios tels que des messages personnalisés, des contenus éducatifs, etc. L'utilisation révolutionnaire de technologies de modélisation 3D telles que ExpNet et PoseVAE permet de capturer les expressions faciales et les mouvements de tête les plus subtils. Les utilisateurs peuvent utiliser la technologie SadTalker pour des projets personnels et commerciaux tels que la messagerie, l'enseignement ou le marketing.

AniPortrait : image ou mouvement vidéo piloté par l'audio pour générer des vidéos numériques réalistes de la parole humaine
AniPortrait est un cadre innovant permettant de générer des animations de portraits réalistes à partir de données audio. Développé par Huawei, Zechun Yang et Zhisheng Wang du Tencent Game Know Yourself Lab, AniPortrait est capable de générer des animations de haute qualité à partir de données audio et d'images de référence.Fournir une vidéo pour la reconstitution faciale. En utilisant des techniques avancées de représentation intermédiaire en 3D et d'animation faciale en 2D, le cadre est capable de générer des effets d'animation naturels et fluides pour une variété de scénarios d'application tels que la production cinématographique et télévisuelle, les présentateurs virtuels et les personnes numériques.

MuseV+Muse Talk : Cadre complet de génération de vidéos humaines numériques - du portrait à la vidéo - de la pose à la vidéo - de la synchronisation labiale
MuseV est un projet public sur GitHub visant à générer des vidéos d'avatars de longueur illimitée et de haute fidélité. Il est basé sur la technologie de diffusion et offre diverses fonctionnalités telles que Image2Video, Text2Image2Video, Video2Video et bien d'autres. Les détails de la structure du modèle, les cas d'utilisation, le guide de démarrage rapide, les scripts d'inférence et les remerciements sont fournis.

DreamTalk : générez des vidéos parlantes expressives avec une seule image d'avatar !
DreamTalk est un cadre de génération de têtes parlantes expressives basé sur un modèle de diffusion, développé conjointement par l'université de Tsinghua, le groupe Alibaba et l'université des sciences et technologies de Huazhong. Il se compose de trois éléments principaux : un réseau de réduction du bruit, un expert en lèvres sensible au style et un prédicteur de style. Il est capable de générer des têtes parlantes diverses et réalistes sur la base d'entrées audio. Il est capable de générer des têtes parlantes diverses et réalistes sur la base d'une entrée audio. Le cadre est capable de gérer des données audio multilingues et bruyantes, de fournir des mouvements faciaux de haute qualité et une synchronisation précise de la bouche.

Translation Starter : Outil de synchronisation de traduction de contenu vidéo Open Source | Conversion de langue | Lip Sync
Translation Starter est un projet open source développé par Sync Labs pour aider les développeurs à intégrer rapidement la prise en charge multilingue du contenu vidéo. Il fournit les API et la documentation nécessaires aux développeurs pour créer facilement des applications qui nécessitent une traduction vidéo avec synchronisation labiale. Il est basé sur de puissantes technologies d'IA telles que Perfect Lip Sync de Sync Labs, Whisper Translation Technology d'Open AI et Sound Synthesis d'Eleven Labs.

© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes




Pas de commentaires...