OneFileLLM : Intégration de plusieurs sources de données dans un seul fichier texte
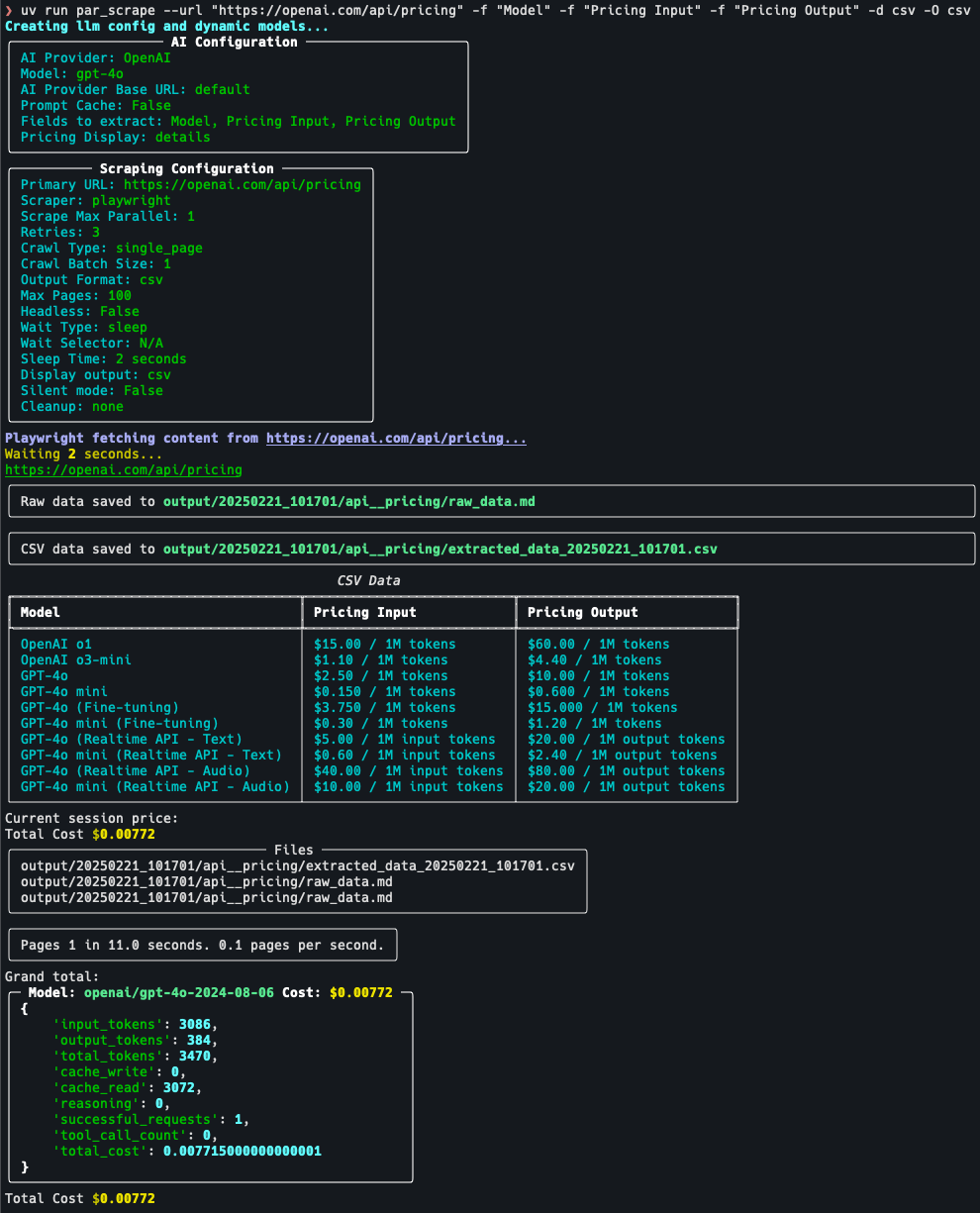
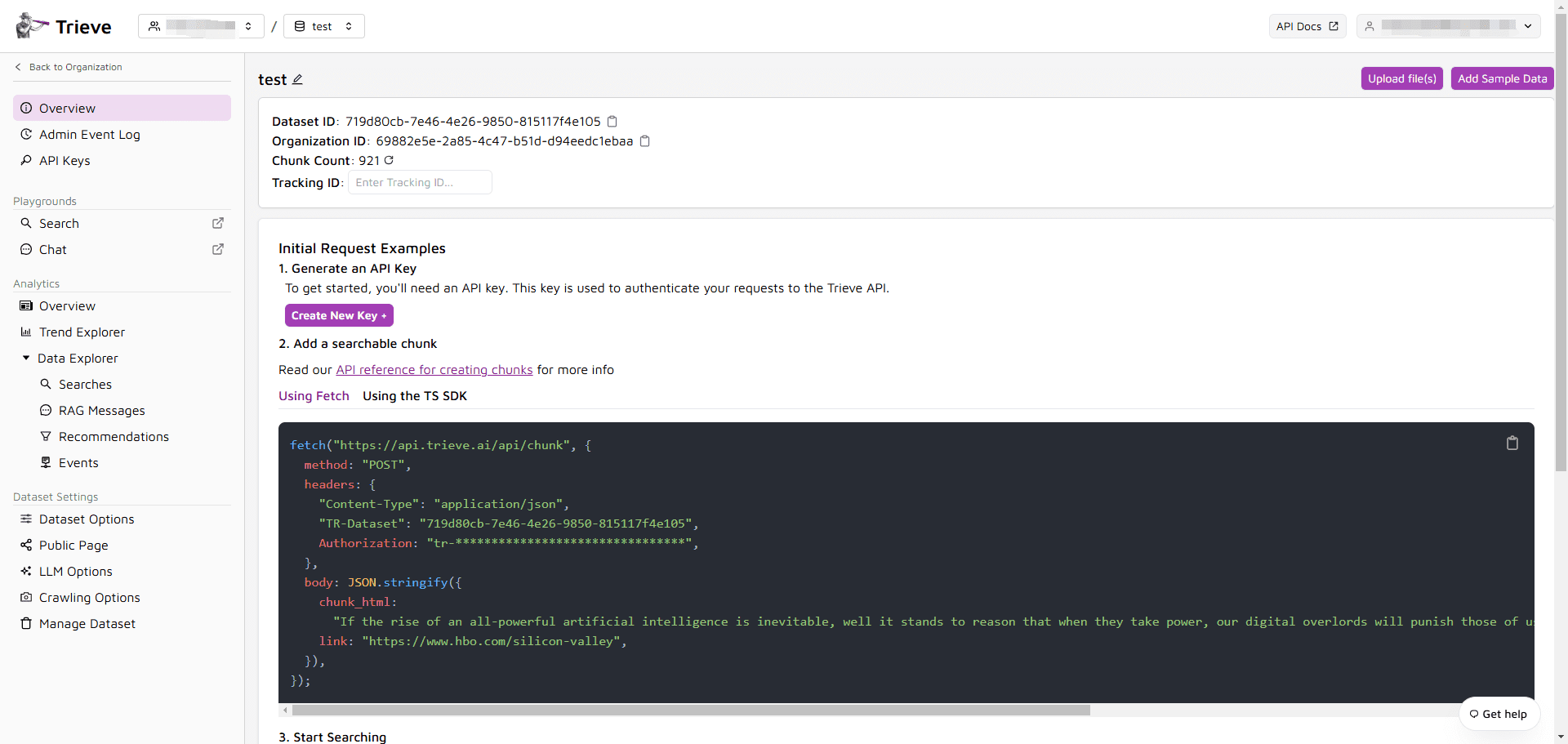
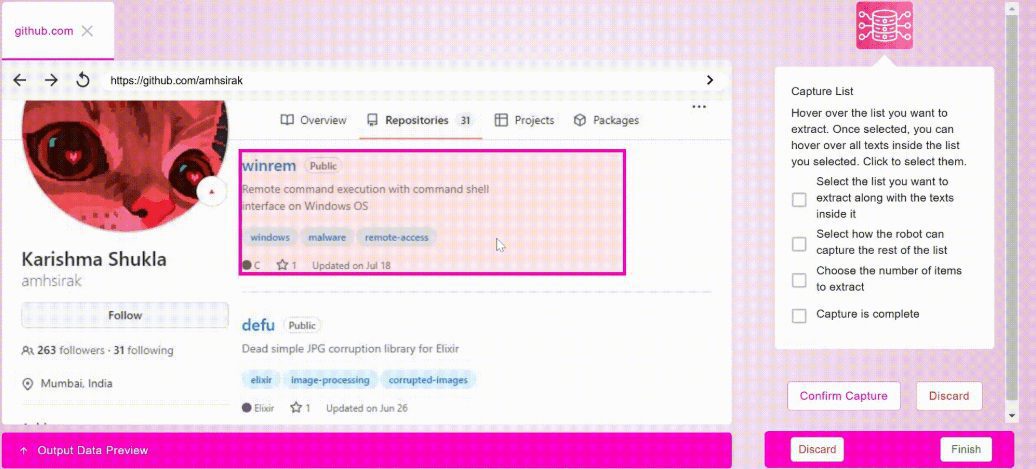
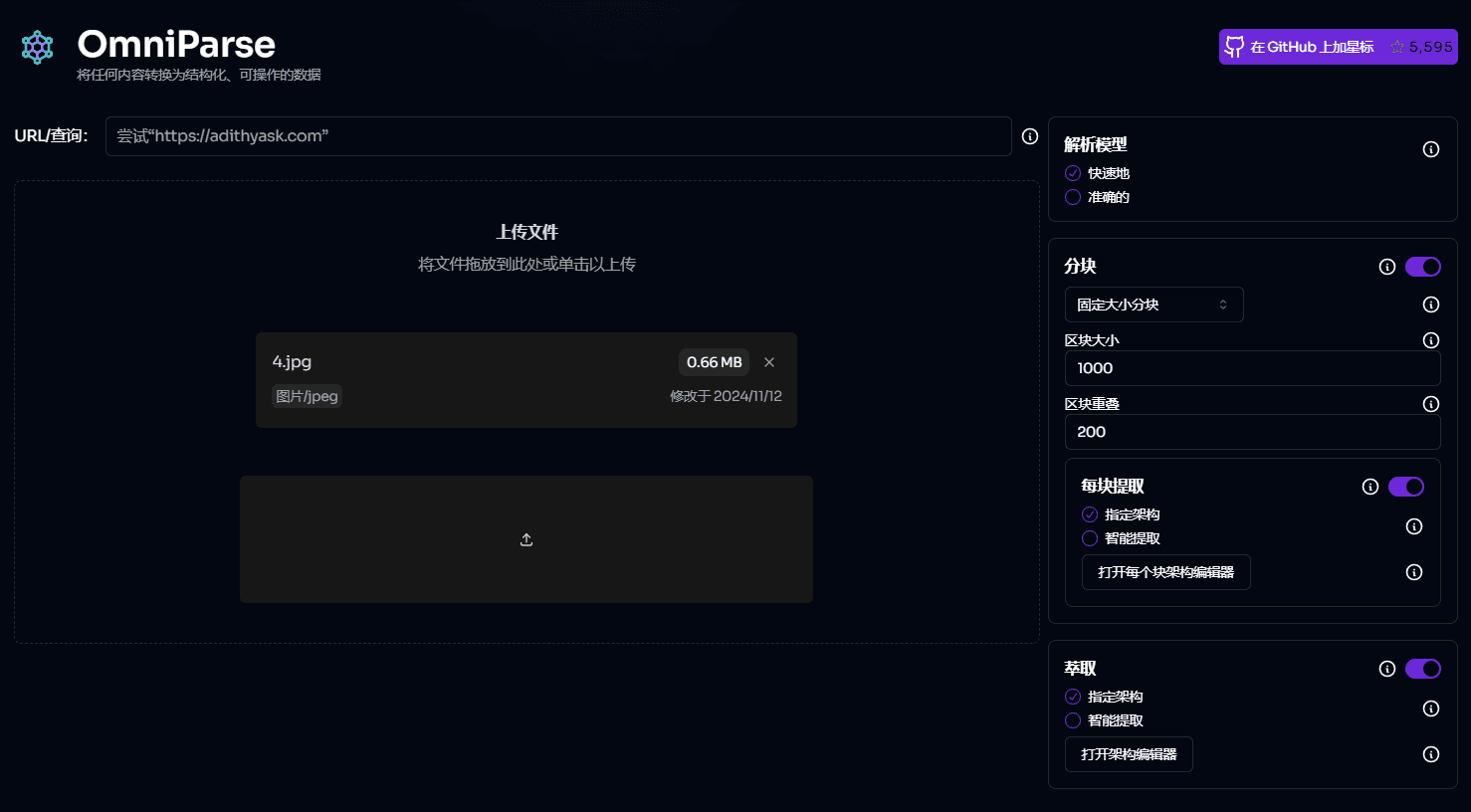
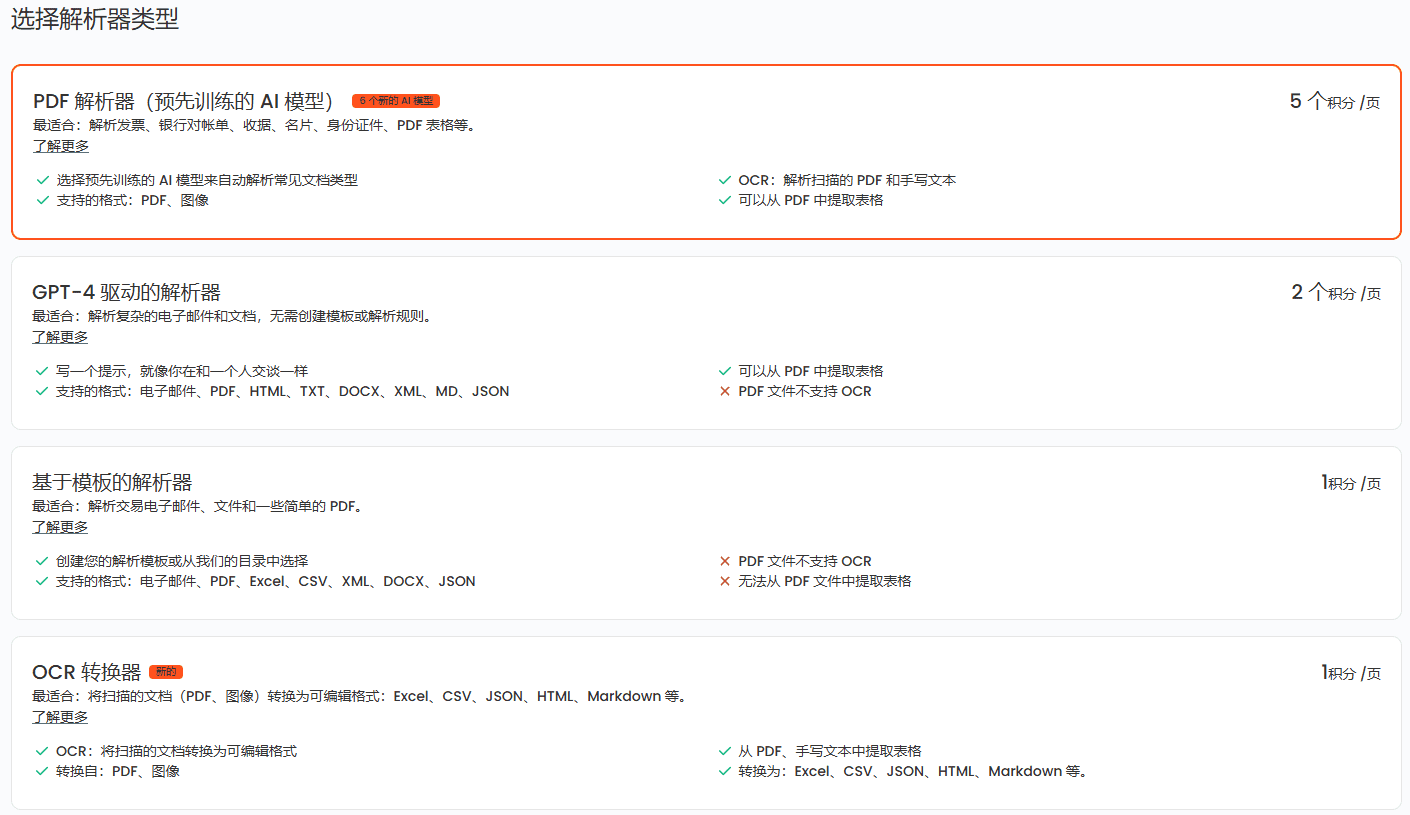
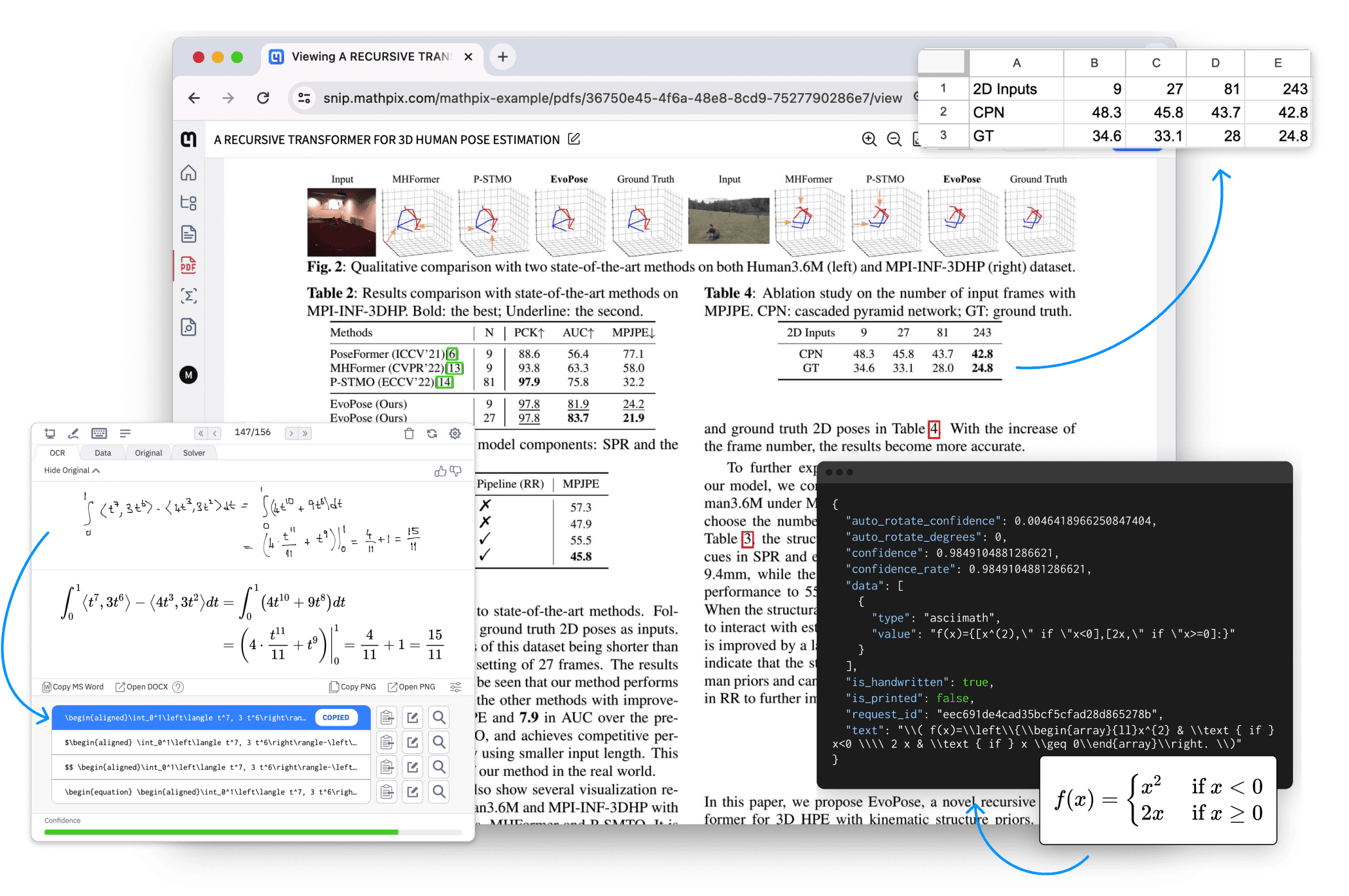
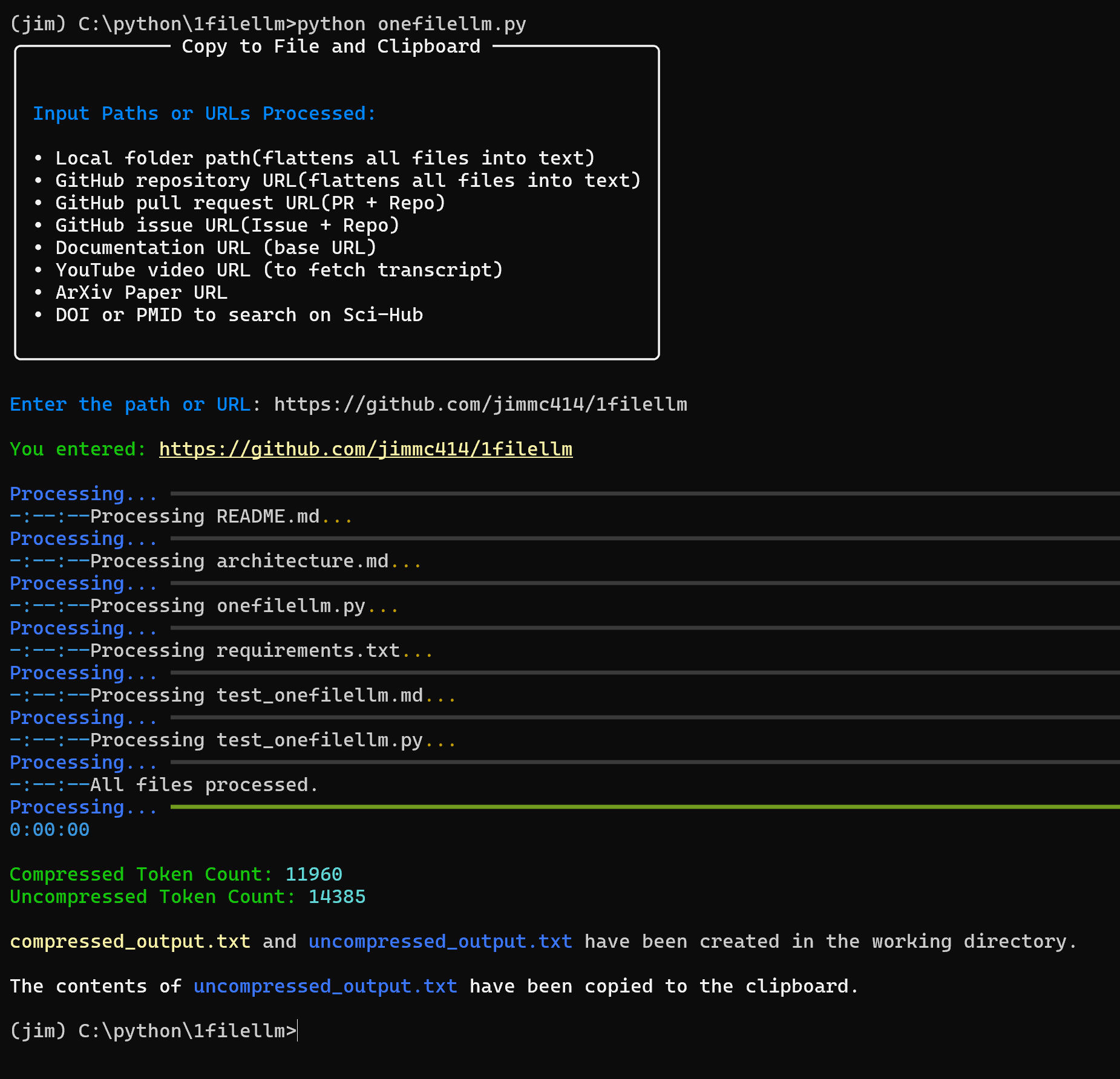
Introduction OneFileLLM est un outil de ligne de commande open source conçu pour consolider plusieurs sources de données en un seul fichier texte afin de faciliter l'entrée dans les grands modèles de langage (LLM). Il permet de traiter les dépôts GitHub, les articles ArXiv, les transcriptions de vidéos YouTube, les...