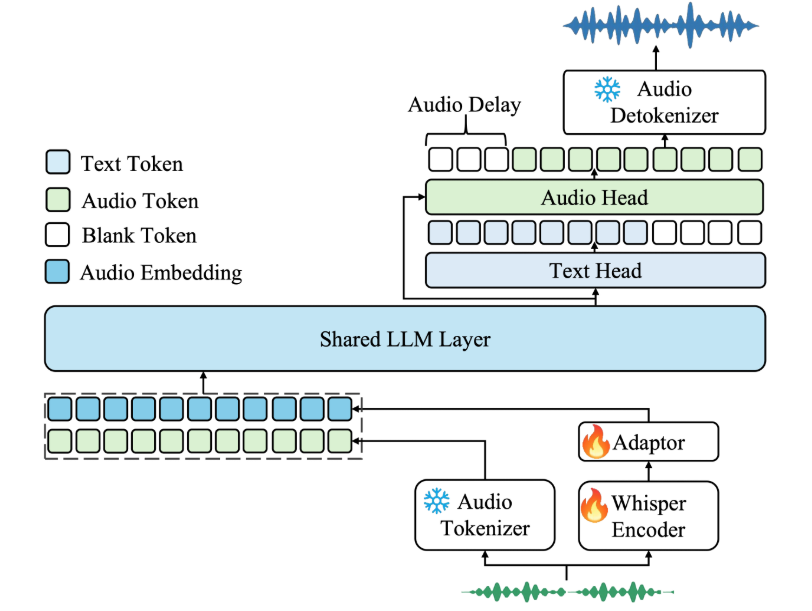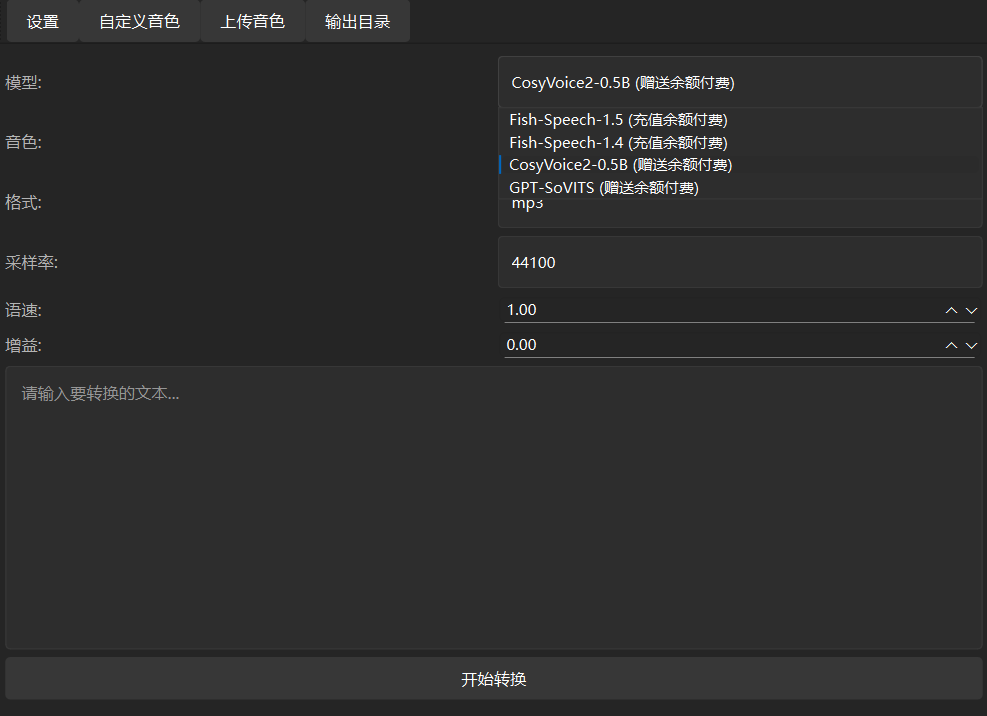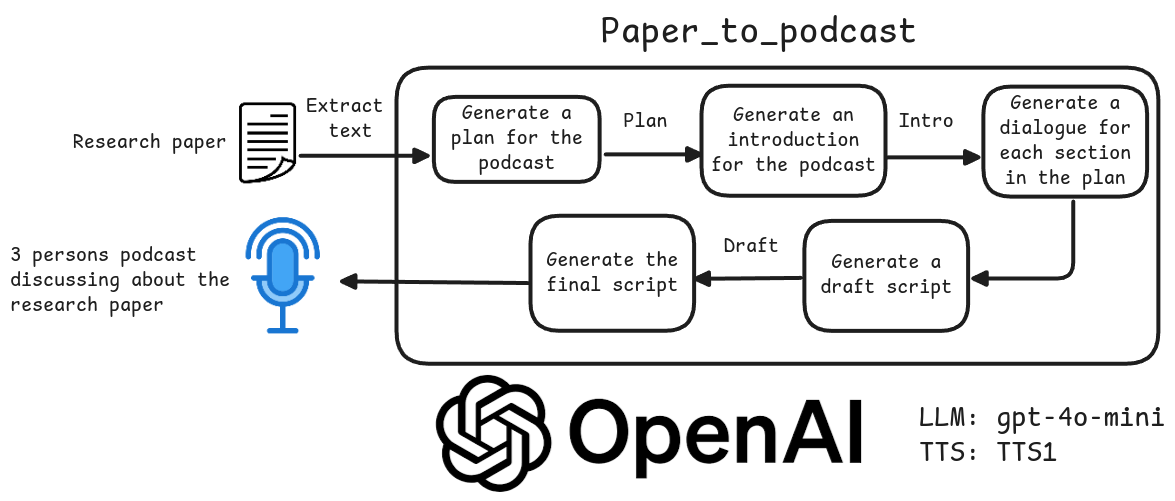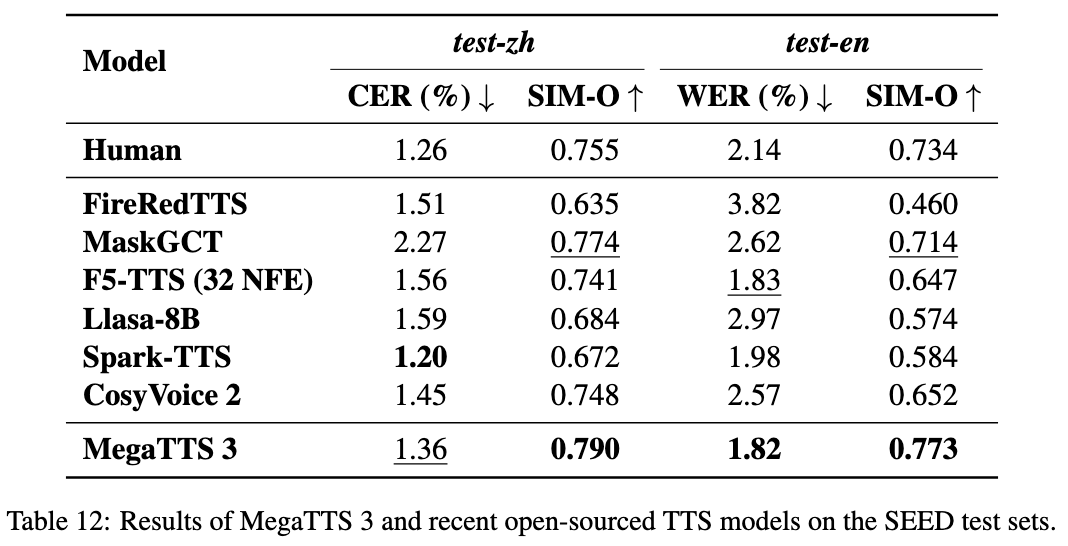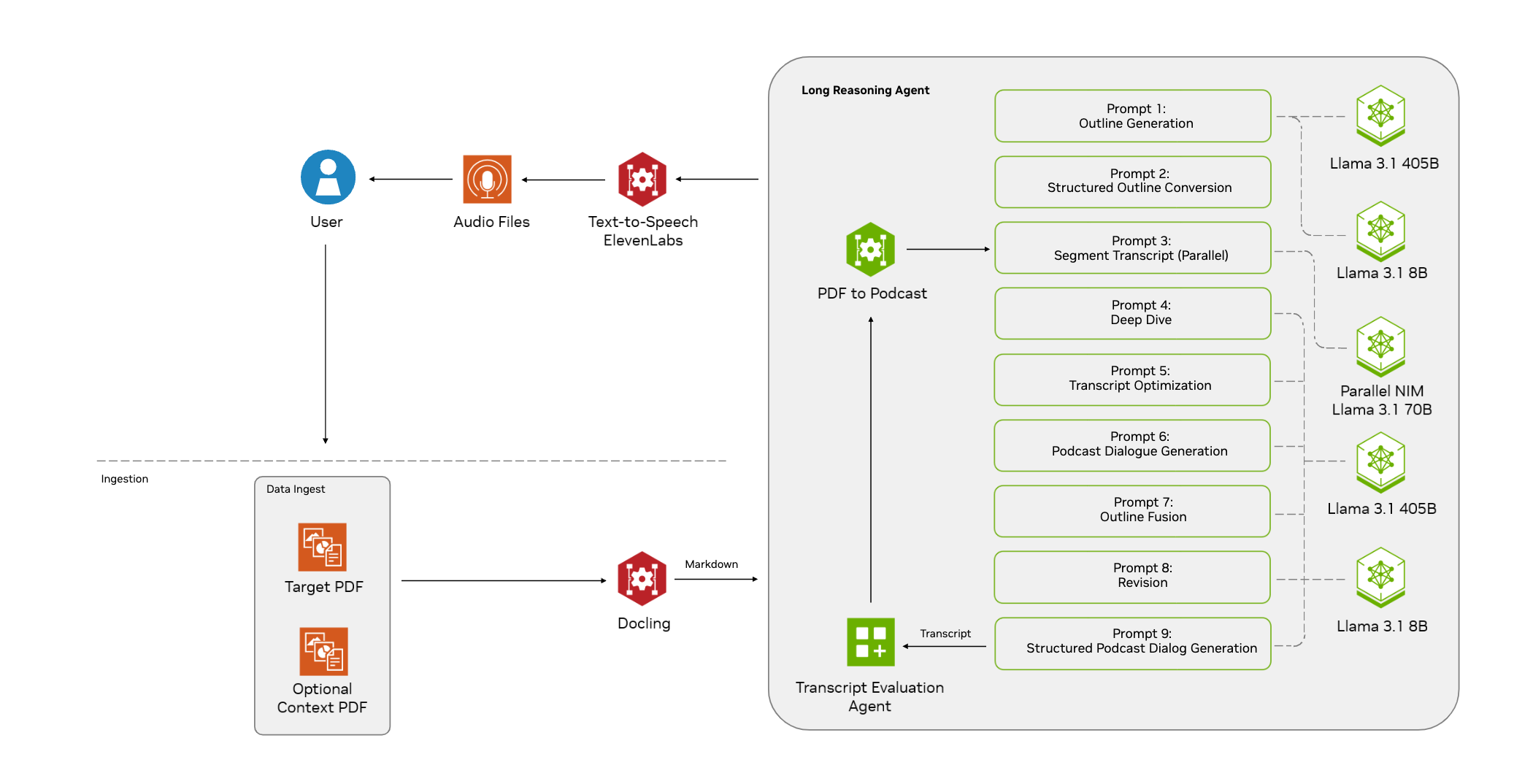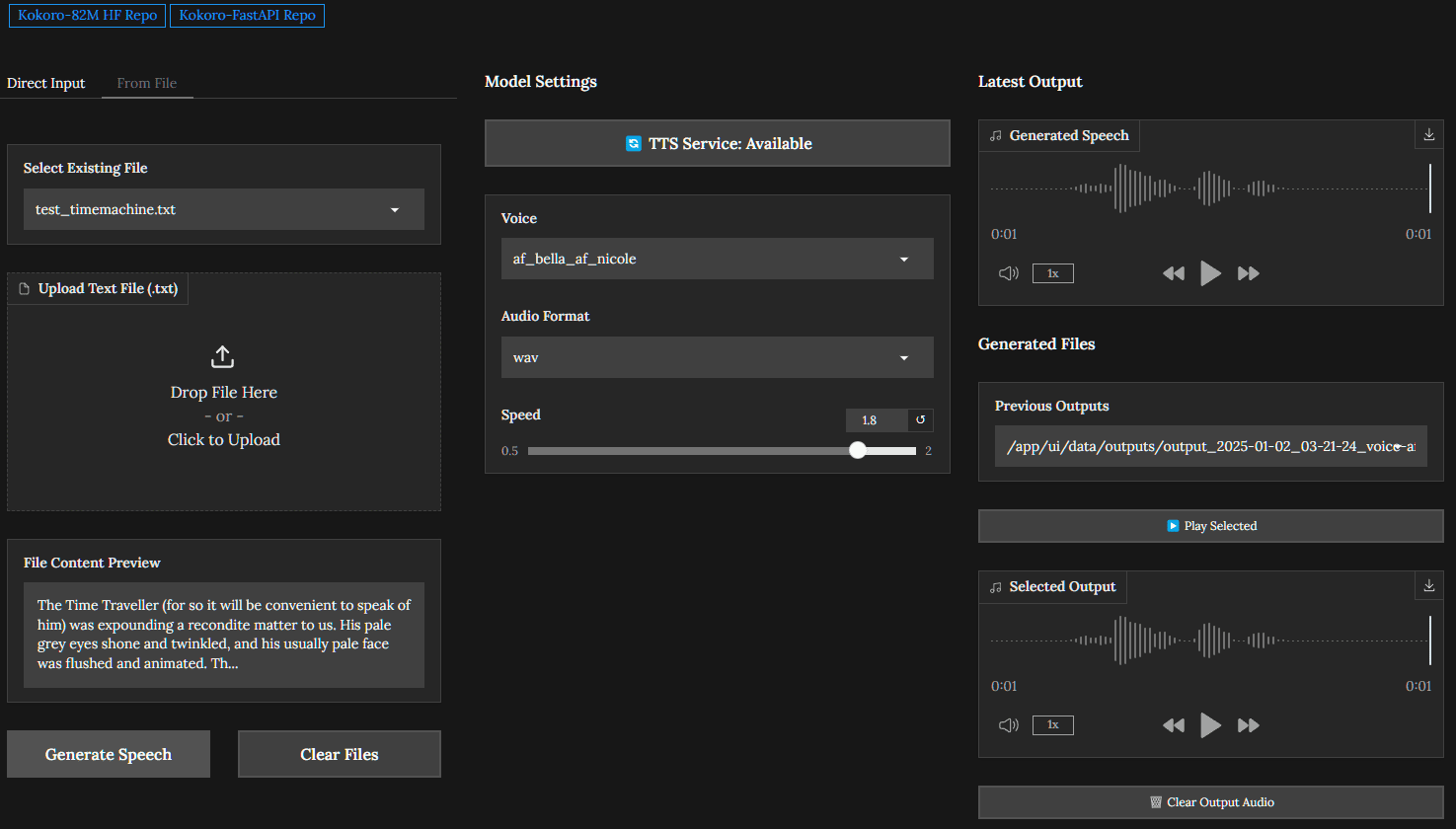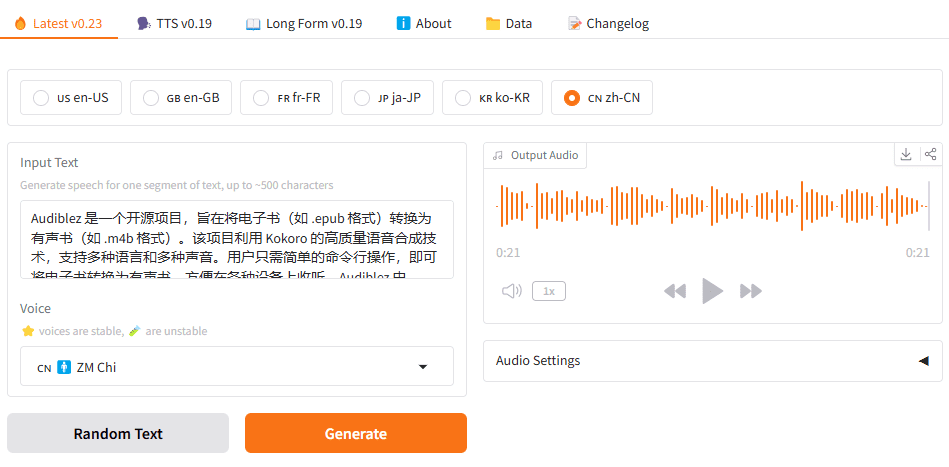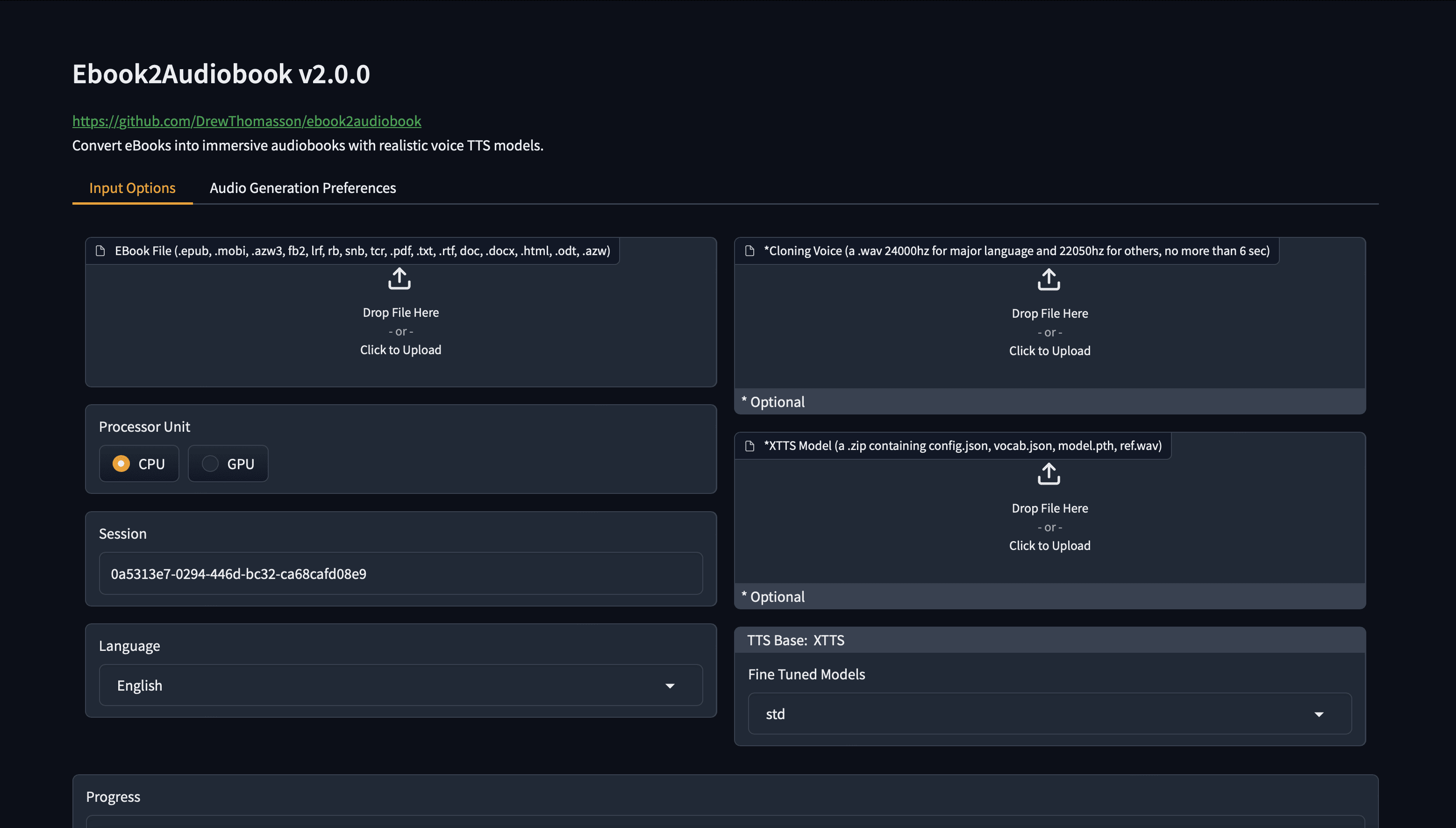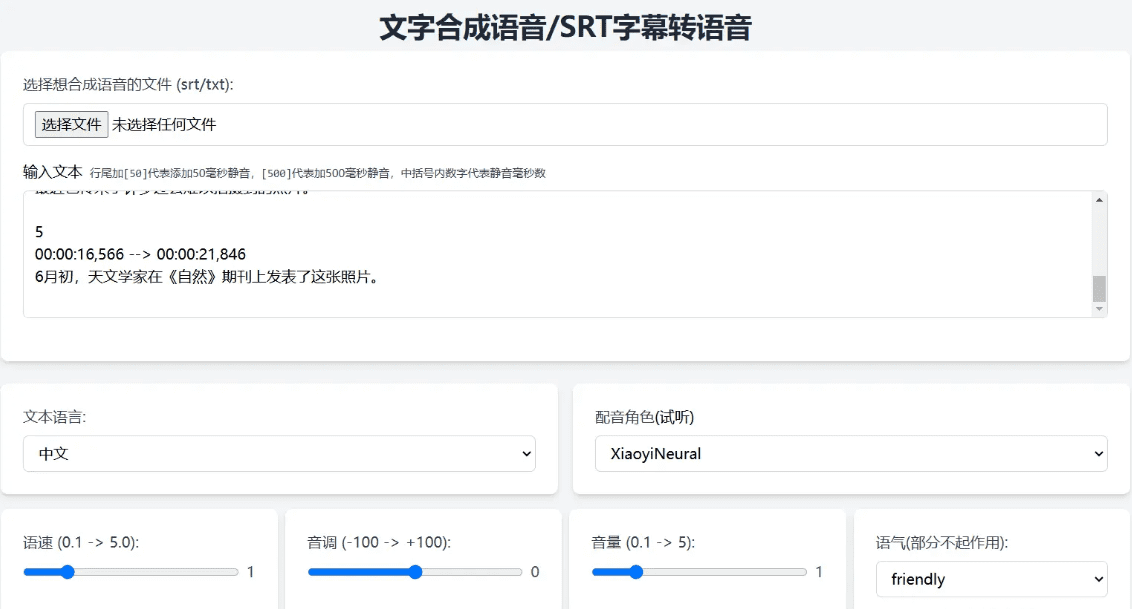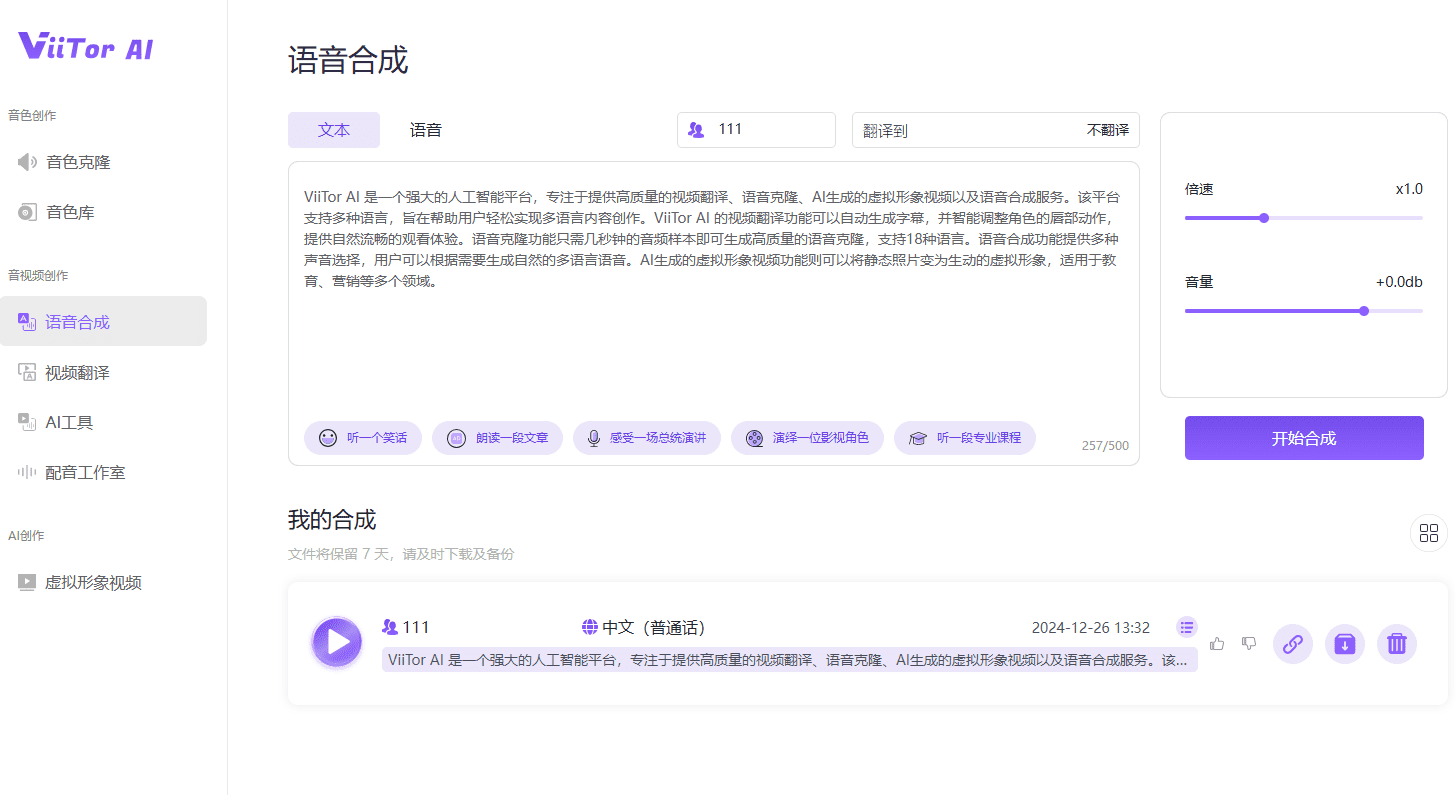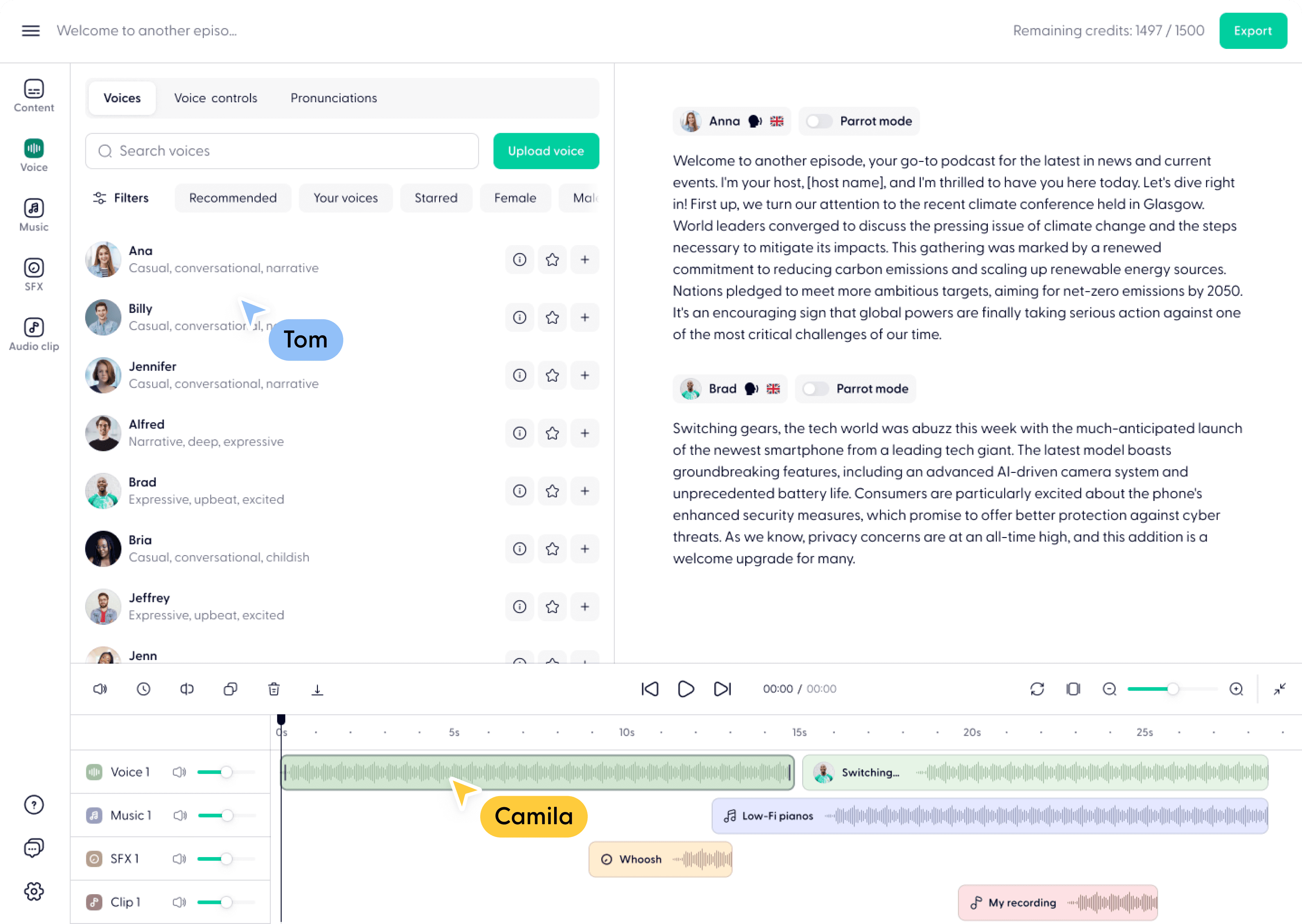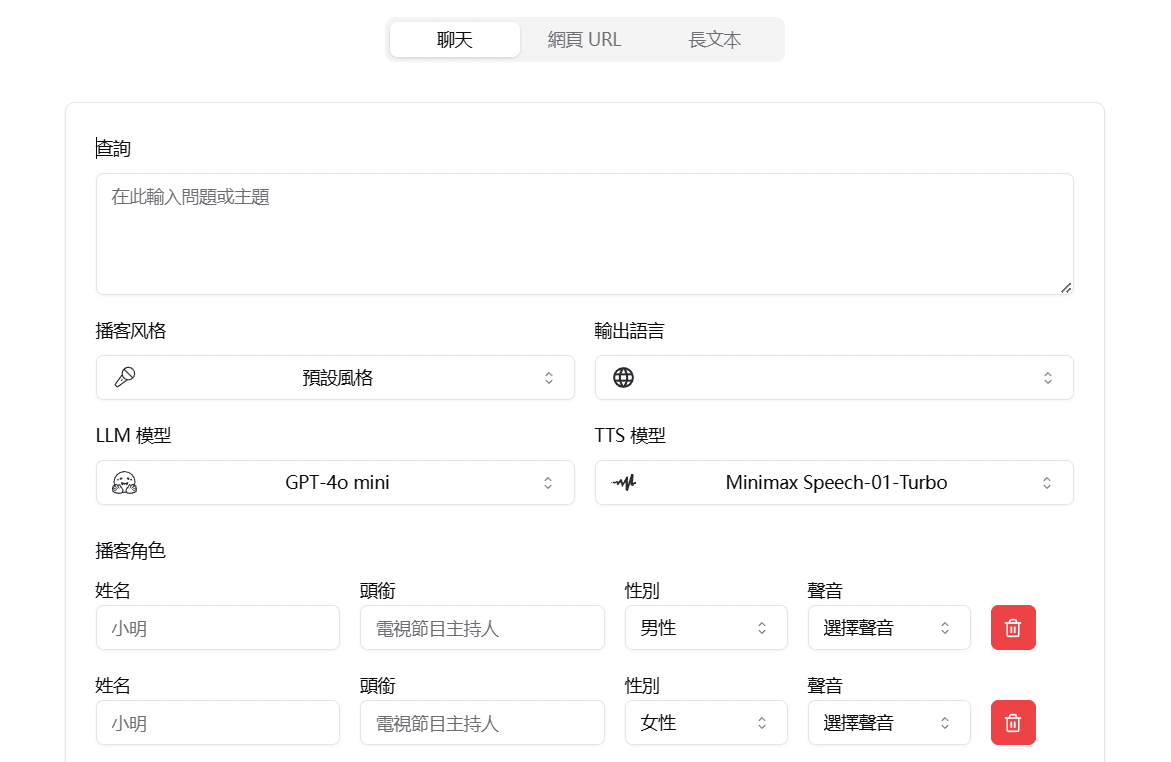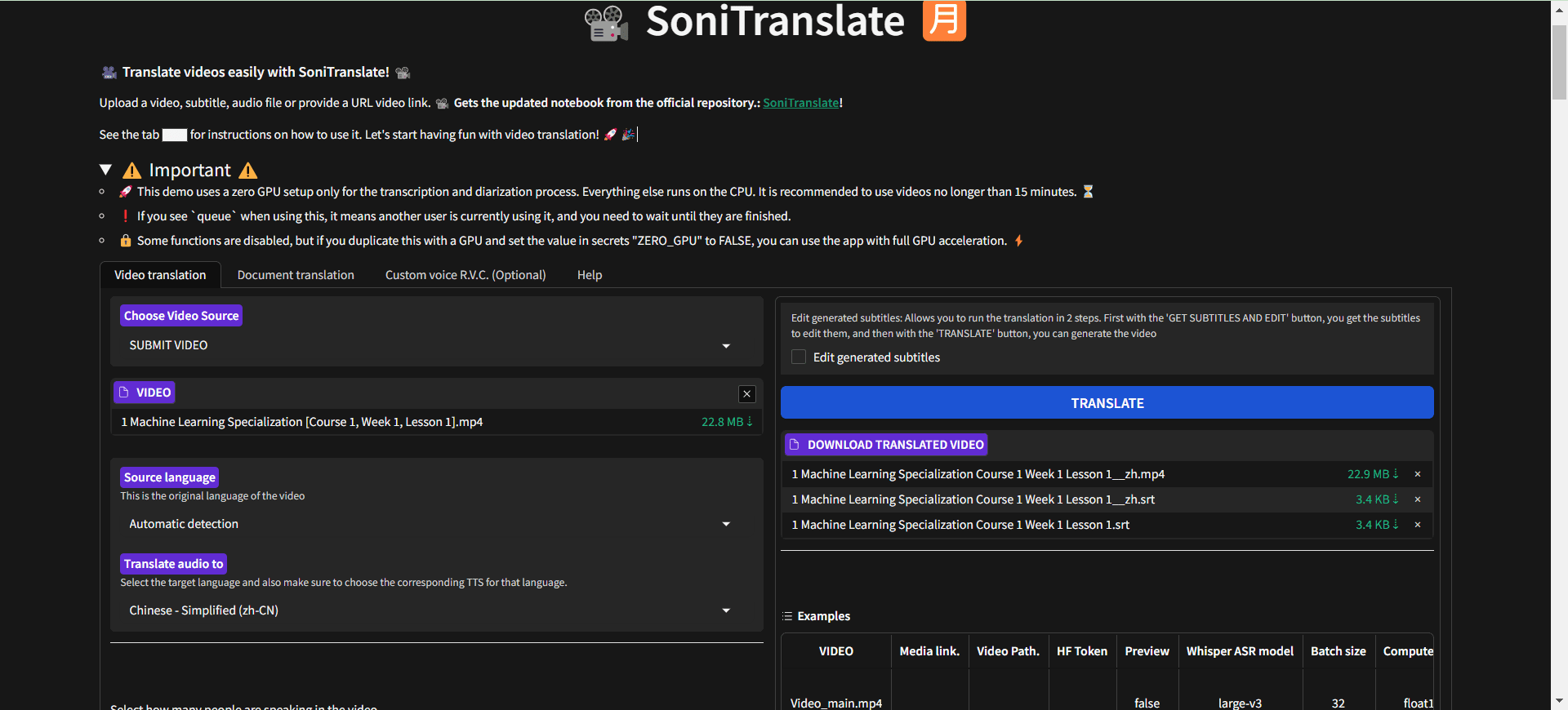
Muyan-TTS : formation et synthèse vocale personnalisée pour podcast
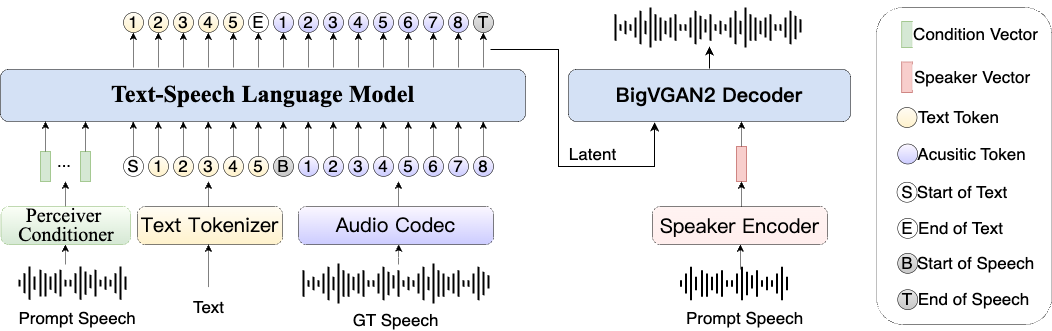
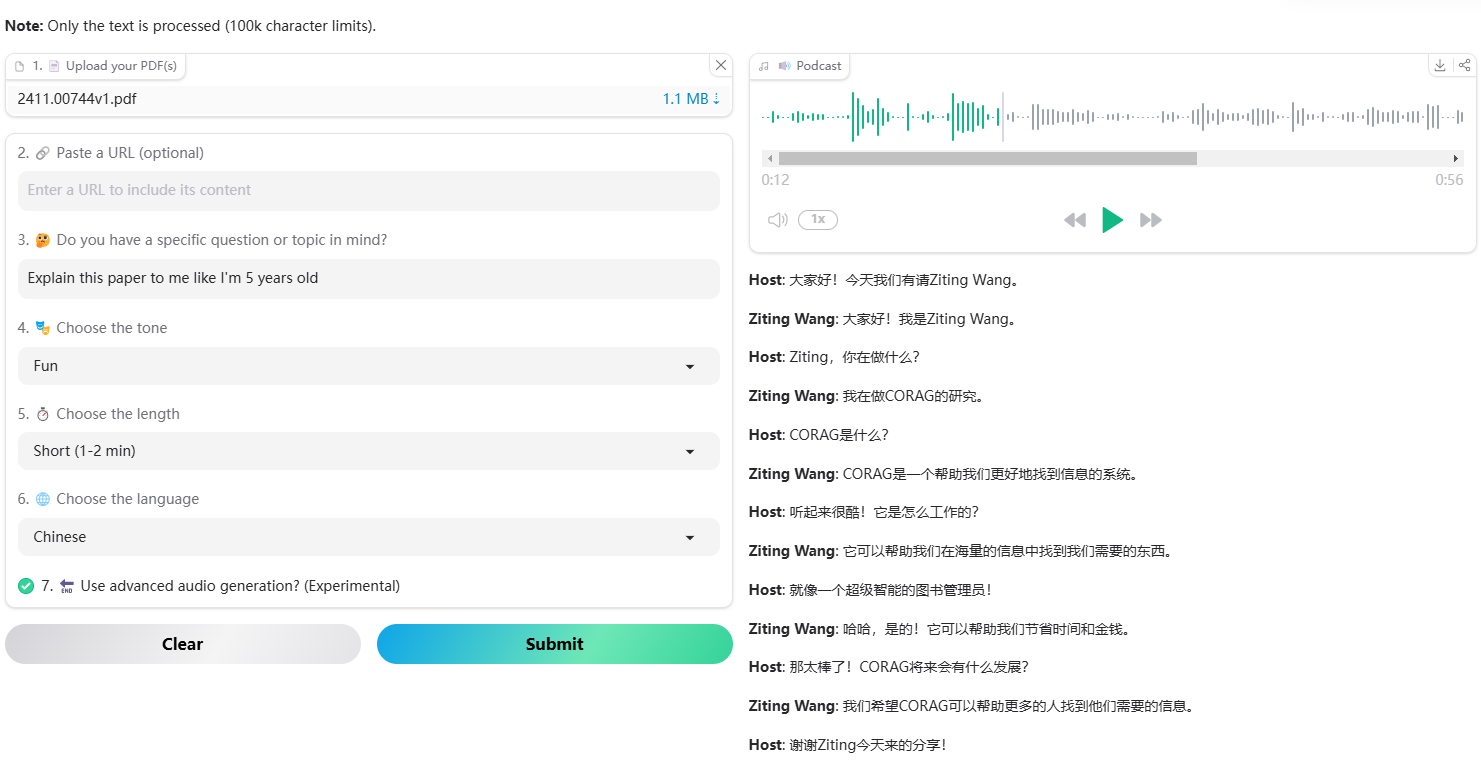
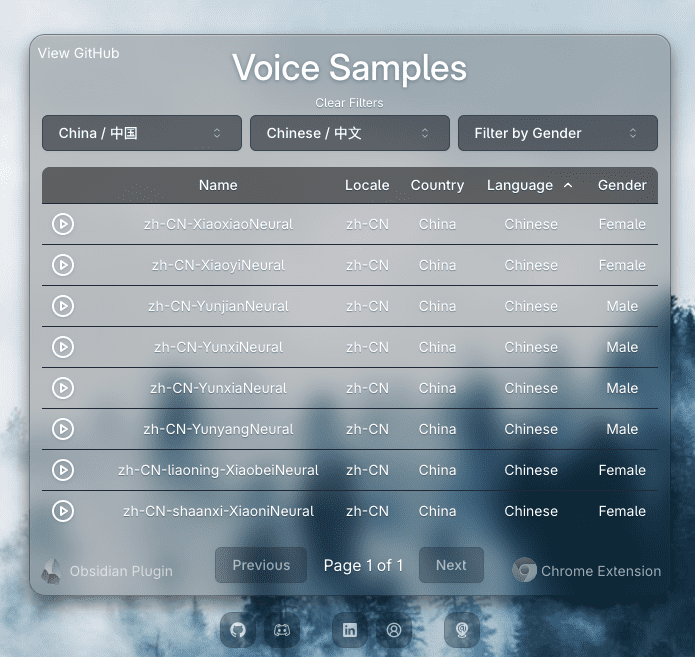
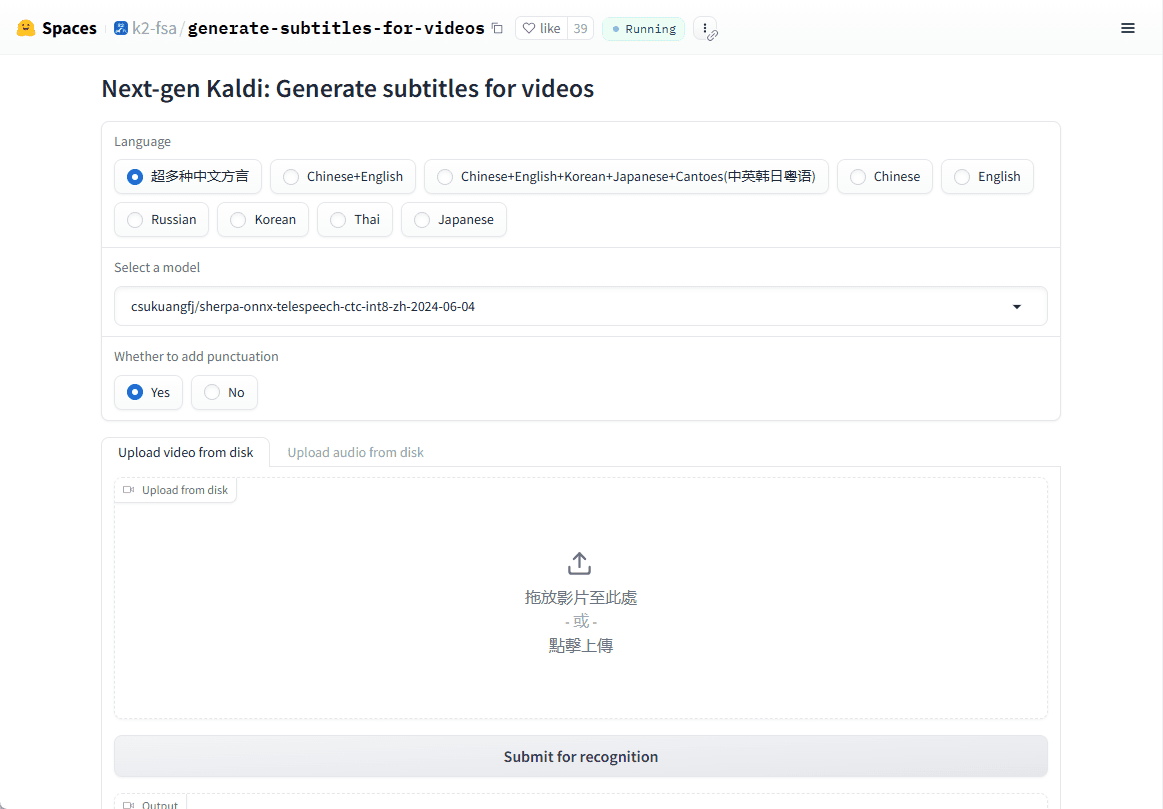
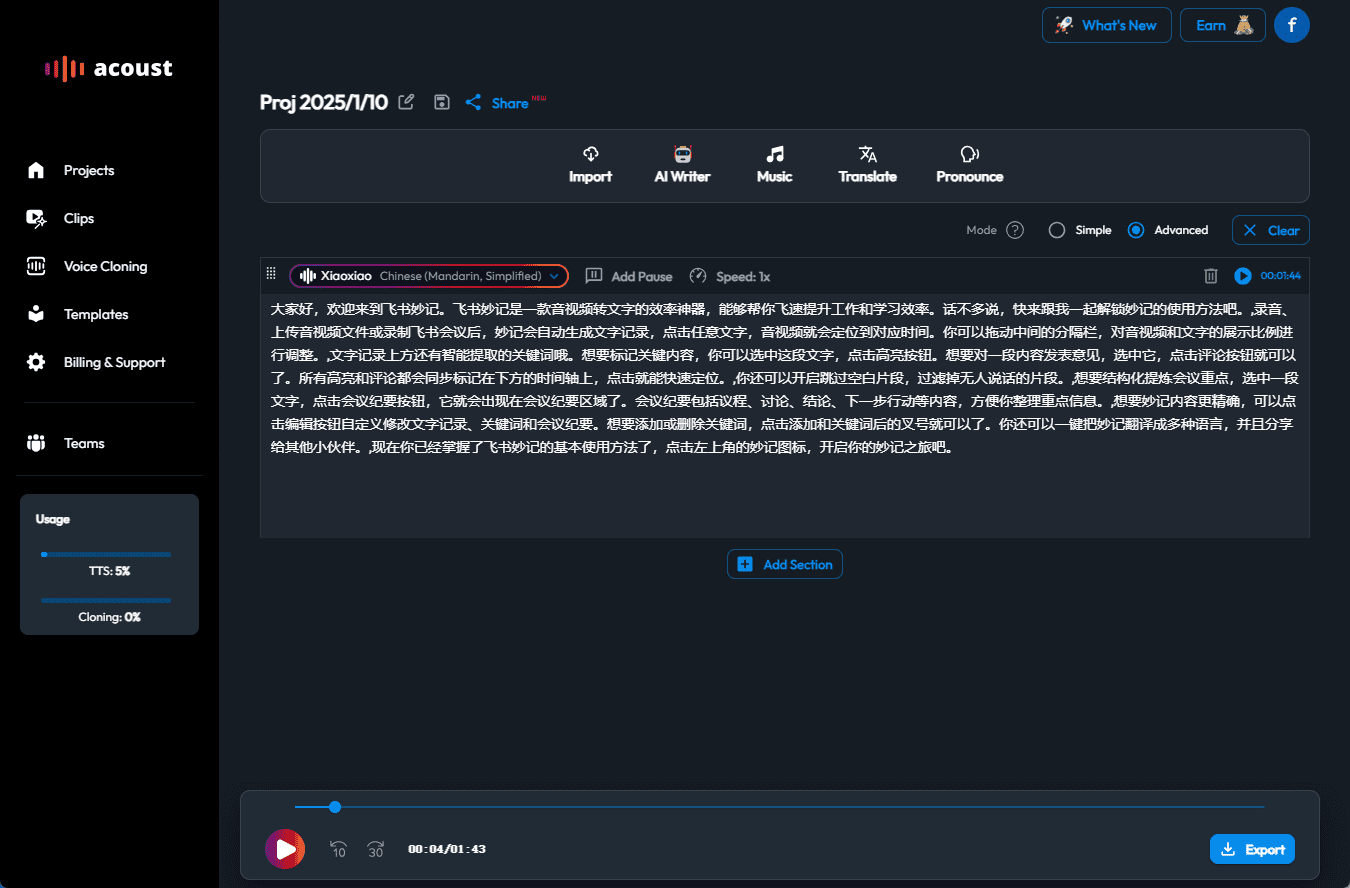
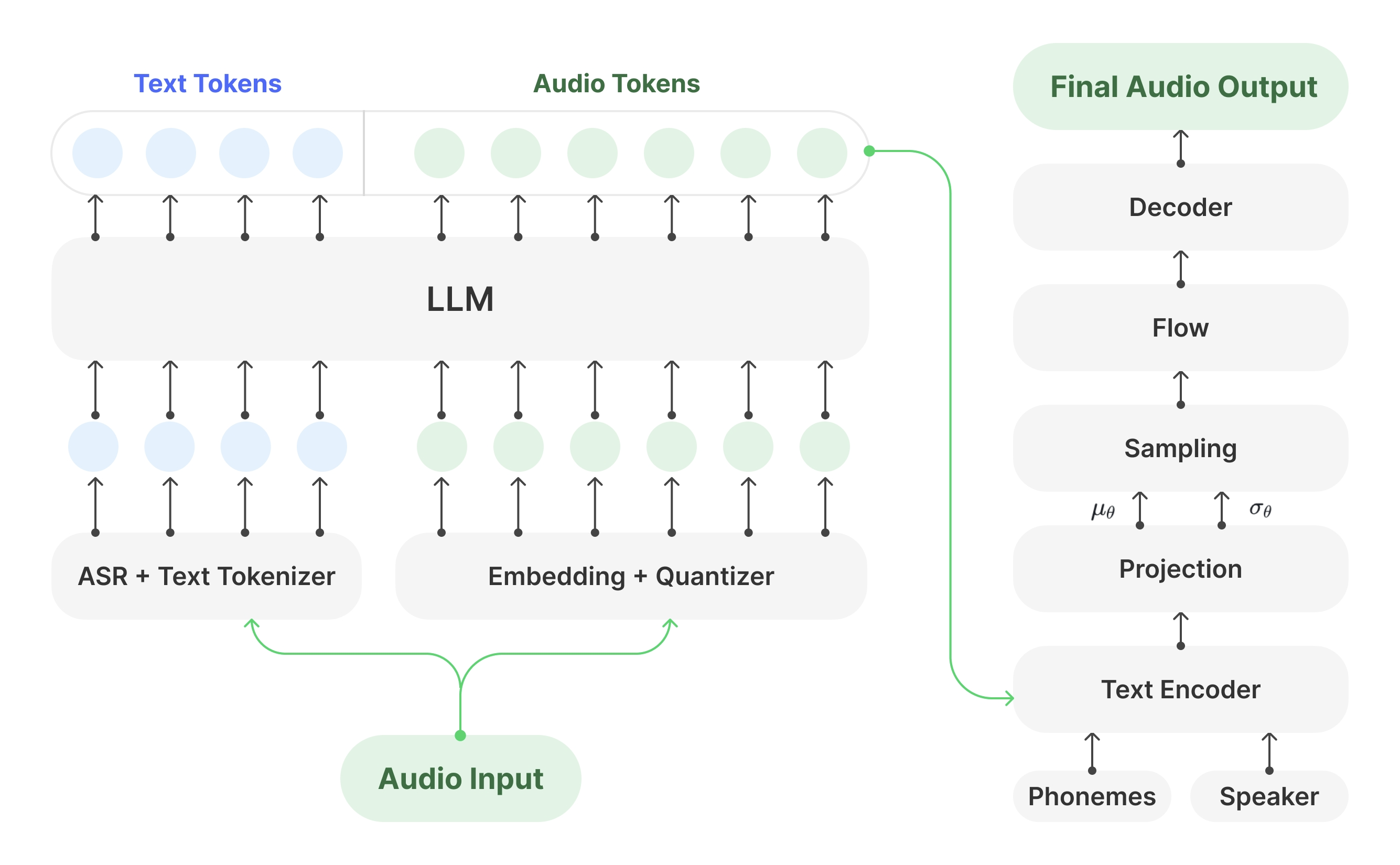
Synthesis Muyan-TTS est un modèle de synthèse vocale open source conçu pour les scénarios de podcasting. Il est pré-entraîné avec plus de 100 000 heures de données audio de podcasts et prend en charge la synthèse vocale sans échantillon pour générer une parole naturelle de haute qualité. Le modèle est basé sur Llama-3.2-3...