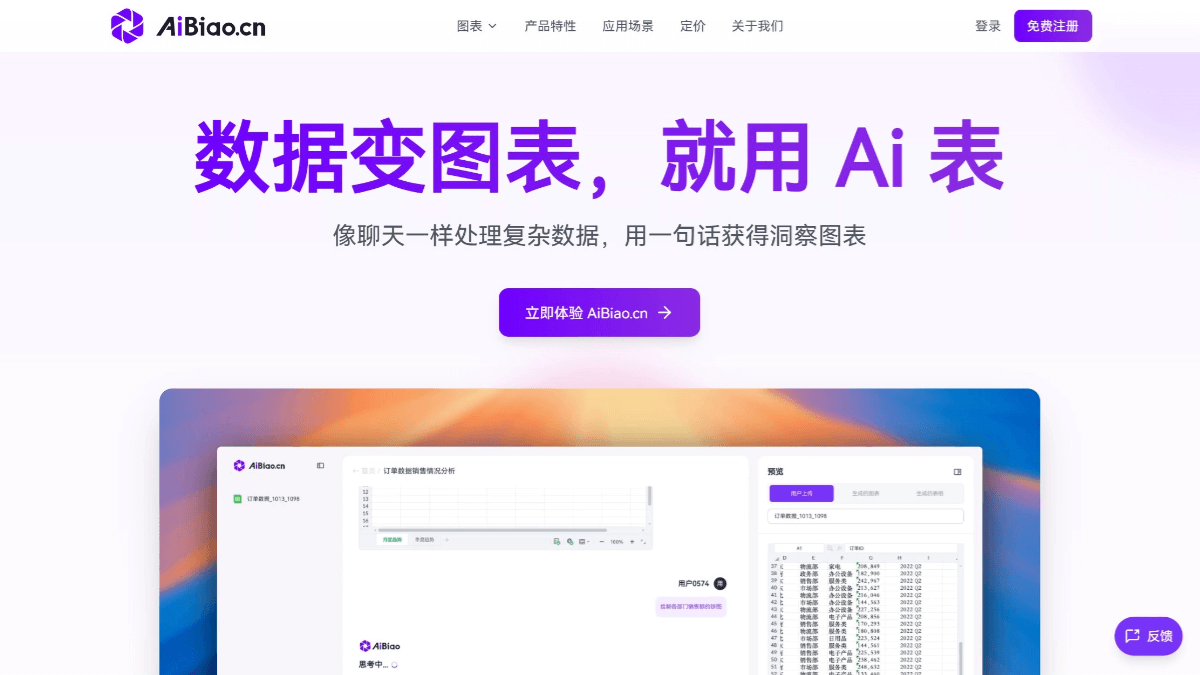
Supametas.AI : Extraction de données non structurées en données hautement disponibles LLM

Introduction générale
Supametas.AI est une plateforme de traitement de données spécialisée dans l'organisation du fouillis de pages web, de documents, de fichiers audio et vidéo en données structurées exploitables par l'intelligence artificielle. Elle permet de collecter des données à partir de sources multiples (liens web, API, fichiers locaux, etc.), puis de les restituer au format JSON ou Markdown. La plateforme ne nécessite aucune expérience en matière de programmation, de sorte que les gens ordinaires peuvent commencer rapidement. Son principal avantage est qu'elle réduit le temps de traitement des données, qui prend traditionnellement des mois, à 30 minutes, ce qui la rend particulièrement adaptée aux entreprises et aux développeurs pour construire des bases de connaissances d'IA (LLM RAGs).

Liste des fonctions
- Collecte de données multi-sourcesLe système d'extraction de données : Il prend en charge l'extraction de données à partir d'URL de pages web, d'interfaces API, de fichiers locaux (PDF, Word, images, audio, vidéo).
- Sortie structuréeLes données non ordonnées sont converties en JSON ou en Markdown pour s'adapter aux modèles d'intelligence artificielle.
- Intégration de la base de connaissancesLes données peuvent être stockées dans le système de stockage OpenAI, dans des ensembles de données Dify ou être intégrées de manière personnalisée via l'API.
- l'extraction du langage naturel (ELN)Les champs extraits sont demandés dans un langage simple, par exemple : "Saisir le titre et le corps du texte".
- Recherche complexe sur le webGestion des pages de liste, de la pagination et des pages multicouches, et prise en charge des mises à jour temporaires.
- Traitement de fichiers volumineuxPrise en charge de fichiers de plusieurs centaines de Mo, tels que des documents longs ou des vidéos HD.
- Traitement audio et vidéoExtraire la chronologie, les sous-titres, les dialogues, etc.
- interface no-codeLe système est facile à utiliser, aucune connaissance technique n'est requise.
- confidentialité des données: offre des services de cloud et des options de déploiement privé de Docker.
Utiliser l'aide
Supametas.AI ne nécessite pas l'installation d'un logiciel complexe et fonctionne directement sur le web. Vous trouverez ci-dessous une description détaillée de l'utilisation de ses principales fonctionnalités afin d'aider les utilisateurs à démarrer rapidement.
S'inscrire et se connecter
- spectacle (un billet)
https://supametas.ai/zhCliquez sur "Get Started". - Inscrivez-vous avec votre adresse e-mail ou choisissez un compte Google pour vous connecter.
- En vous inscrivant, vous accédez à un mode d'essai gratuit qui comprend les fonctionnalités de base et quelques ressources.
Collecte et traitement des données
robot d'exploration
- Après vous être connecté, cliquez sur New Dataset.
- Sélectionnez la source de données "URL" et saisissez la page web cible, par exemple
https://example.com/blog. - Définir les paramètres de l'exploration :
- "Depth Value" (valeur de profondeur) : la valeur 3 permet d'explorer trois niveaux de pages.
- "Loop Time Value" : Régler sur 24 pour des mises à jour quotidiennes.
- Cliquez sur "Démarrer le traitement" et le système extrait automatiquement le titre, le corps du texte, etc.
- Lorsque le processus est terminé, cliquez sur Exporter et choisissez JSON ou Markdown à télécharger.
Traitement local des documents
- Dans l'écran Nouveau jeu de données, sélectionnez Fichier local.
- Cliquez sur "Télécharger un fichier" pour glisser-déposer ou sélectionner des fichiers.
- Les formats pris en charge sont les suivants :
- Documentation :
.docx,.pdf,.txt - Image :
.jpg,.png - Vidéo audio :
.mp3,.mp4,.mov
- Documentation :
- Après le téléchargement, le système extrait automatiquement le contenu. Par exemple, le PDF extrait les paragraphes et le MP3 transcrit le texte.
- Vérifiez les résultats et cliquez sur "Exporter" pour sauvegarder.
Extraction de données API
- Sélectionnez la source de données "API".
- Saisissez la configuration de l'API, par exemple :
{
"contentUrl": "https://api.example.com/data",
"getDemandFormat": "json",
"customKeys": [{"key": "category", "desc": "分类"}]
}
- Cliquez sur "Test" pour vous assurer que les données sont renvoyées correctement.
- Une fois le test réussi, cliquez sur "Démarrer le traitement" pour générer des données structurées.
base de connaissances intégrée
- Après avoir traité les données, cliquez sur Intégrer.
- Sélectionnez une plate-forme cible, telle que OpenAI Storage ou Dify Jeux de données.
- Saisissez la clé API de la plateforme (générée sur la plateforme cible).
- Cliquez sur "Connecter" et les données sont automatiquement téléchargées.
- Lorsque vous personnalisez l'intégration, copiez le code API fourni par la plateforme dans votre projet.
Mise en place d'une tâche chronométrée
- Sur la page Dataset, cliquez sur Settings.
- Sélectionnez Planifier la mise à jour et réglez-la sur Toutes les 24 heures.
- Après l'enregistrement, le système capture et traite automatiquement les données en arrière-plan.
Fonction en vedette Fonctionnement
Extraction audio et vidéo
- télécharger
.mp4Documentation. - Le système génère une chronologie et un texte de dialogue tel que "00:01 - Bonjour".
- Prévisualisez les résultats et exportez-les, pour les personnes numériques ou le traitement des données de podcast.
extraction de champs en langage naturel
- Dans les paramètres d'extraction, saisissez une invite, telle que "Extraire le titre et la date de l'article".
- Le système identifie et rassemble automatiquement les champs en fonction des invites.
Traitement de fichiers volumineux
- Téléchargez des centaines de Mo de PDF ou de vidéos.
- Le système est traité par segments et fournit des données entièrement structurées une fois terminé.
mise en garde
- La version gratuite limite le nombre d'ensembles de données et la capacité de traitement, tandis que la version payante permet d'accéder à davantage de ressources.
- Les fichiers volumineux ou les tâches complexes peuvent nécessiter plus de jetons, qui peuvent être liés à un modèle externe (par exemple, OpenAI).
- Vous pouvez voir l'état d'avancement d'une tâche ou l'interrompre dans le gestionnaire des tâches.
- Une version de déploiement privé (Docker) est en cours de développement pour les entreprises.
Supametas.AI dispose d'une interface conviviale avec des guides pour chaque étape. Il est recommandé d'essayer d'abord la version gratuite et de la mettre à jour si nécessaire une fois que vous vous êtes familiarisé avec elle.
scénario d'application
- Construction d'une base de connaissances d'entreprise
Les entreprises financières peuvent l'utiliser pour explorer les pages web et les PDF réglementaires, les rassembler en données structurées et les transmettre à l'IA pour analyse. - Développement humain numérique
Téléchargez des clips audio et vidéo, extrayez les dialogues et la chronologie, et générez un ensemble de données de formation. - Gestion des données du commerce électronique
Saisir régulièrement les listes et les détails des produits, les rassembler en JSON et optimiser l'analyse de l'inventaire.
QA
- Quelles sont les limites de la version gratuite ?
La version gratuite n'est pas limitée dans le temps, mais le nombre d'ensembles de données et la capacité de traitement sont limités, ce qui la rend adaptée aux essais. - Quelle est la taille des fichiers pris en charge ?
Gère des fichiers de plusieurs centaines de mégaoctets, tels que des documents longs ou des vidéos HD. - Comment garantissez-vous la confidentialité des données ?
Les services en nuage chiffrent la transmission, et Docker Private Deployment Edition rend les données entièrement localisées.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...