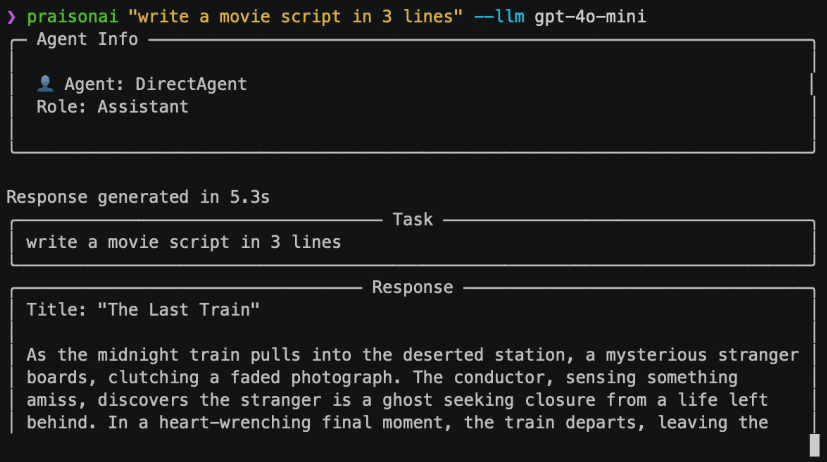
StreamingT2V : Génération dynamique et évolutive de textes vers des vidéos longues

Introduction générale
StreamingT2V est un projet public développé par l'équipe de recherche en IA de Picsart, qui vise à générer des vidéos longues cohérentes, dynamiques et évolutives à partir de descriptions textuelles. Cette technologie utilise une approche autorégressive avancée qui garantit une vidéo temporellement cohérente qui correspond étroitement au texte de la description et maintient une image de haute qualité. Elle est capable de générer des vidéos allant jusqu'à 1 200 images par seconde et d'une durée maximale de deux minutes, avec la possibilité de les étendre à des périodes plus longues. L'efficacité de la technique n'est pas limitée par un modèle Text2Video spécifique, c'est-à-dire que les améliorations apportées au modèle permettront d'améliorer encore la qualité de la vidéo.
StreamingT2V Expérience en ligne

Liste des fonctions
Il permet de générer des vidéos jusqu'à 1200 images par seconde et d'une durée maximale de deux minutes.
Maintien de la cohérence temporelle de la vidéo et des images de haute qualité
Génération dynamique de vidéos correspondant étroitement à la description du texte
Prise en charge de plusieurs applications du modèle de base pour améliorer la qualité des vidéos générées
Prise en charge de la conversion texte-vidéo et image-vidéo
Démonstration en ligne de Gradio
Utiliser l'aide
Cloner le dépôt de projet et installer l'environnement requis
Télécharger les poids et les placer dans le catalogue approprié
Exécuter un exemple de code pour la conversion de texte en vidéo ou d'image en vidéo
Consultez la page du projet pour obtenir des résultats détaillés et des démonstrations.
temps d'inférence
ModelscopeT2V comme modèle de base
| taux de rafraîchissement | Temps d'inférence de l'aperçu plus rapide (256×256) | Temps de raisonnement pour le résultat final (720×720) |
|---|---|---|
| 24 cadres | 40 secondes. | 165 secondes. |
| 56 cadres | 75 secondes | 360 secondes |
| 80 cadres | 110 secondes. | 525 secondes. |
| 240 cadres | 340 secondes. | 1610 secondes (environ 27 minutes) |
| 600 cadres | 860 secondes. | 5128 secondes (environ 85 minutes) |
| 1200 cadres. | 1710 secondes (environ 28 minutes) | 10225 secondes (environ 170 minutes) |
AnimerDiffcomme modèle de base
| taux de rafraîchissement | Temps d'inférence de l'aperçu plus rapide (256×256) | Temps de raisonnement pour le résultat final (720×720) |
|---|---|---|
| 24 cadres | 50 secondes. | 180 secondes. |
| 56 cadres | 85 secondes. | 370 secondes. |
| 80 cadres | 120 secondes. | 535 secondes. |
| 240 cadres | 350 secondes. | 1620 secondes (environ 27 minutes) |
| 600 cadres | 870 secondes. | 5138 secondes (~85 minutes) |
| 1200 cadres. | 1720 secondes (environ 28 minutes) | 10235 secondes (environ 170 minutes) |
SVDComme modèle de base
| taux de rafraîchissement | Temps d'inférence de l'aperçu plus rapide (256×256) | Temps de raisonnement pour le résultat final (720×720) |
|---|---|---|
| 24 cadres | 80 secondes. | 210 secondes. |
| 56 cadres | 115 secondes. | 400 secondes. |
| 80 cadres | 150 secondes. | 565 secondes. |
| 240 cadres | 380 secondes. | 1650 secondes (environ 27 minutes) |
| 600 cadres | 900 secondes. | 5168 secondes (~86 minutes) |
| 1200 cadres. | 1750 secondes (environ 29 minutes) | 10265 secondes (~171 minutes) |
Toutes les mesures ont été prises en utilisant le GPU NVIDIA A100 (80 GB). Lorsque le nombre d'images dépassait 80, un mélange aléatoire était utilisé. Pour le mélange aléatoire, lachunk_sizeet la valeur deoverlap_sizesont fixés respectivement à 112 et 32.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...