Step-Audio-AQAA - Modèle de langue Big Audio de bout en bout de StepFun

Qu'est-ce que Step-Audio-AQAA ?
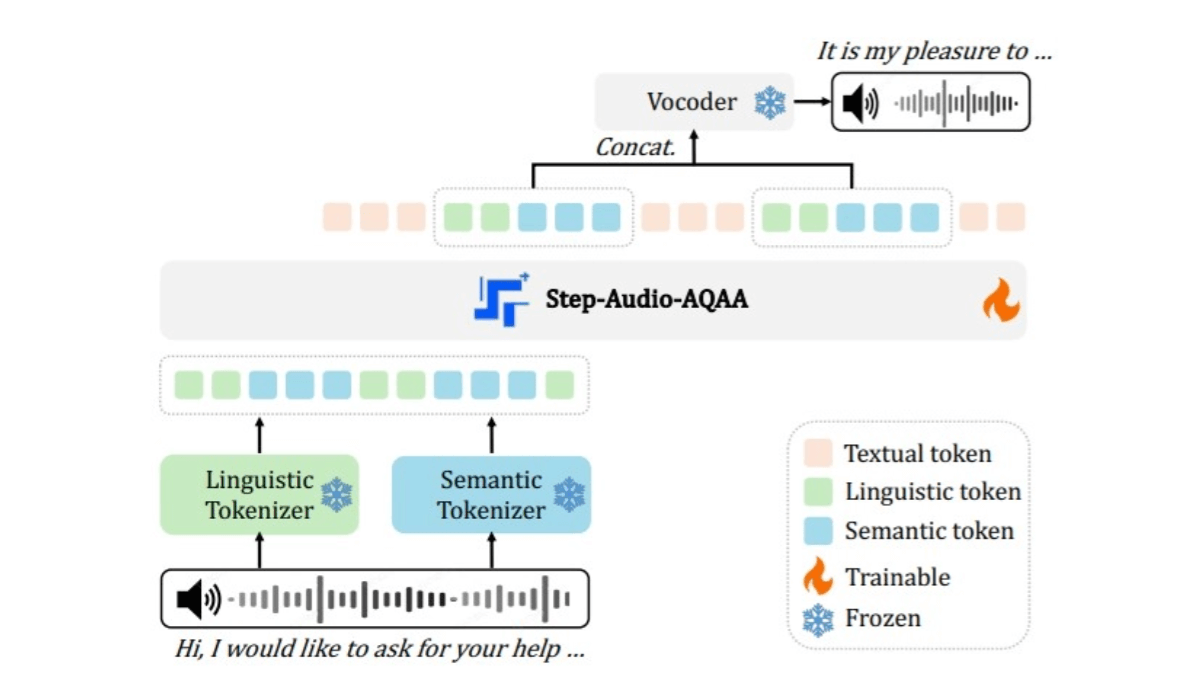
Step-Audio-AQAA est un modèle de langage audio de bout en bout et à grande échelle pour les tâches de questions-réponses audio (AQAA) de l'équipe StepFun. La capacité de traiter l'entrée audio directement pour générer des réponses vocales naturelles et précises sans dépendre des modules traditionnels de reconnaissance automatique de la parole (ASR) et de synthèse vocale (TTS) simplifie l'architecture du système et élimine les erreurs en cascade. Le processus d'apprentissage de Step-Audio-AQAA implique un pré-entraînement multimodal, un réglage fin supervisé (SFT), une optimisation directe des préférences (DPO) et une fusion des modèles. Grâce à ces méthodes, le modèle donne de bons résultats dans des tâches complexes telles que le contrôle des émotions vocales, les jeux de rôle et le raisonnement logique. Dans le benchmark StepEval-Audio-360, Step-Audio-AQAA surpasse les modèles LALM existants sur plusieurs dimensions clés, démontrant un fort potentiel pour l'interaction vocale de bout en bout.
Caractéristiques principales de Step-Audio-AQAA
- Traitement direct des entrées audioLe système de reconnaissance vocale : Il génère des réponses vocales directement à partir d'une entrée audio brute, sans s'appuyer sur les modules traditionnels de reconnaissance automatique de la parole (ASR) et de synthèse vocale (TTS).
- Interaction vocale transparenteLes utilisateurs peuvent poser des questions avec leur voix et le modèle répond directement avec leur voix, ce qui améliore le naturel et la fluidité de l'interaction.
- Ajustement du ton émotionnelLes langues officielles de l'Union européenne sont l'anglais, le français, l'allemand, l'italien et le russe.
- contrôle de la paroleL'utilisateur peut ajuster la vitesse de la réponse vocale pour qu'elle réponde mieux aux besoins du scénario.
- Contrôle de la tonalité et de la hauteurIl peut ajuster le ton et la hauteur de la voix en fonction des commandes de l'utilisateur, s'adaptant ainsi à différents rôles ou scénarios.
- interaction multilingueLes langues utilisées sont le chinois, l'anglais, le japonais et d'autres langues, afin de répondre aux besoins linguistiques des différents utilisateurs.
- Support dialectalLa couverture des dialectes chinois tels que le sichuan et le cantonais afin d'améliorer l'applicabilité du modèle dans des régions spécifiques.
- contrôle des émotions à commande vocaleLa voix peut générer des réponses vocales avec des émotions spécifiques en fonction du contexte et des commandes de l'utilisateur.
- jeu de rôle (jeu)Les élèves ont la possibilité de jouer des rôles spécifiques dans un dialogue, par exemple le service clientèle, l'enseignant, l'ami, etc. et de produire des réponses vocales qui correspondent aux caractéristiques du rôle.
- Quiz sur le raisonnement logique et les connaissances: Peut gérer des tâches de raisonnement logique complexes et des questionnaires de connaissances, en générant des réponses vocales précises.
- Sortie vocale de haute qualitéLes vocodeurs neuronaux permettent de générer des formes d'ondes vocales naturelles, fluides et de haute fidélité afin d'améliorer l'expérience de l'utilisateur.
- cohérence phonétiqueLes élèves sont capables de maintenir la cohérence et l'homogénéité de leur discours dans la production de longues phrases ou de paragraphes, en évitant les interruptions ou les changements abrupts dans le discours.
- Texte entrelacé et sortie vocaleLa version anglaise de l'application : prend en charge le texte entrelacé et la sortie vocale, ce qui permet aux utilisateurs de choisir des réponses vocales ou textuelles en fonction de leurs besoins.
- Compréhension des données multimodalesPeut comprendre des entrées mixtes contenant de la parole et du texte, en produisant des réponses vocales appropriées.
Adresse du projet Step-Audio-AQAA
- Bibliothèque de modèles HuggingFace: : https://huggingface.co/stepfun-ai/Step-Audio-AQAA
- Document technique arXiv: : https://arxiv.org/pdf/2506.08967
Principes techniques de Step-Audio-AQAA
- Séparateur audio à double codeIl convertit le signal audio d'entrée en une séquence structurée de jetons. Il se compose de deux lexiques : un lexique linguistique qui extrait les phonèmes et les attributs linguistiques de la parole, échantillonné à 16,7 Hz avec une taille de codebook de 1024, et un lexique sémantique qui capture les caractéristiques acoustiques de la parole, telles que l'émotion et l'intonation, échantillonné à 25 Hz avec une taille de codebook de 4096, ce qui est une meilleure façon de capturer la complexité de l'information contenue dans la parole.
- Backbone LLMLes données de pré-entraînement couvrent trois modalités : le texte, la parole et l'image. Les jetons audio de texte bicode sont intégrés dans un espace vectoriel uniforme à l'aide d'un système d'apprentissage multiple. Transformateur pour la compréhension sémantique profonde et l'extraction de caractéristiques.
- vocodeur neuronalSynthèse : Synthétise les jetons audio générés en formes d'ondes vocales naturelles et de haute qualité. L'architecture U-Net, combinée à la couche ResNet-1D et au bloc Transformer, convertit efficacement les jetons audio discrets en formes de discours continues.
Step-Audio - Les principaux avantages de l'AQAA
- Interaction audio de bout en boutStep-Audio-AQAA génère des réponses vocales naturelles et fluides directement à partir de l'entrée audio brute, éliminant ainsi la nécessité de recourir aux modules traditionnels de reconnaissance automatique de la parole (ASR) et de synthèse vocale (TTS). La conception de bout en bout évite la distorsion des résultats causée par les erreurs dans la reconnaissance automatique de la parole (ASR) ou la synthèse vocale (TTS) dans les solutions traditionnelles.
- Prise en charge multilingueLe modèle prend en charge plusieurs langues, dont le chinois (y compris le sichuanais et le cantonais), l'anglais, le japonais, etc., ce qui permet de répondre aux besoins linguistiques des différents utilisateurs.
- Contrôle précis des fonctions vocalesStep-Audio-AQAA permet de contrôler finement les caractéristiques de la voix, telles que l'intonation émotionnelle, le débit de parole, etc., afin de générer des réponses vocales plus réactives. Il est particulièrement performant en matière de contrôle des émotions vocales.
A qui s'adresse Step-Audio-AQAA ?
- Utilisateurs d'assistants vocaux intelligentsLes utilisateurs qui souhaitent utiliser des dispositifs d'interaction vocale (par exemple, des haut-parleurs intelligents, des assistants intelligents) pour des opérations quotidiennes (par exemple, vérifier des informations, définir des rappels, jouer de la musique, etc.)
- passionné de jeuxLes joueurs qui aiment interagir avec les PNJ dans le jeu pour une expérience de jeu plus immersive.
- Utilisateurs éducatifsLes étudiants et les parents qui souhaitent apprendre par le biais de l'interaction vocale (par exemple, l'apprentissage des langues, les quiz de connaissances, etc.)
- Personnes âgées et enfantsL'interaction vocale est plus pratique et plus naturelle pour les utilisateurs qui ne maîtrisent pas la saisie de texte.
- créateur de livres audioLes créateurs qui ont besoin de générer du contenu vocal de haute qualité, comme des livres audio, des pièces radiophoniques, etc.
- producteur vidéoLes créateurs qui ont besoin d'une interaction vocale ou de capacités de génération de voix lorsqu'ils produisent du contenu vidéo (par exemple, de courtes vidéos, des flux en direct).
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes




Pas de commentaires...