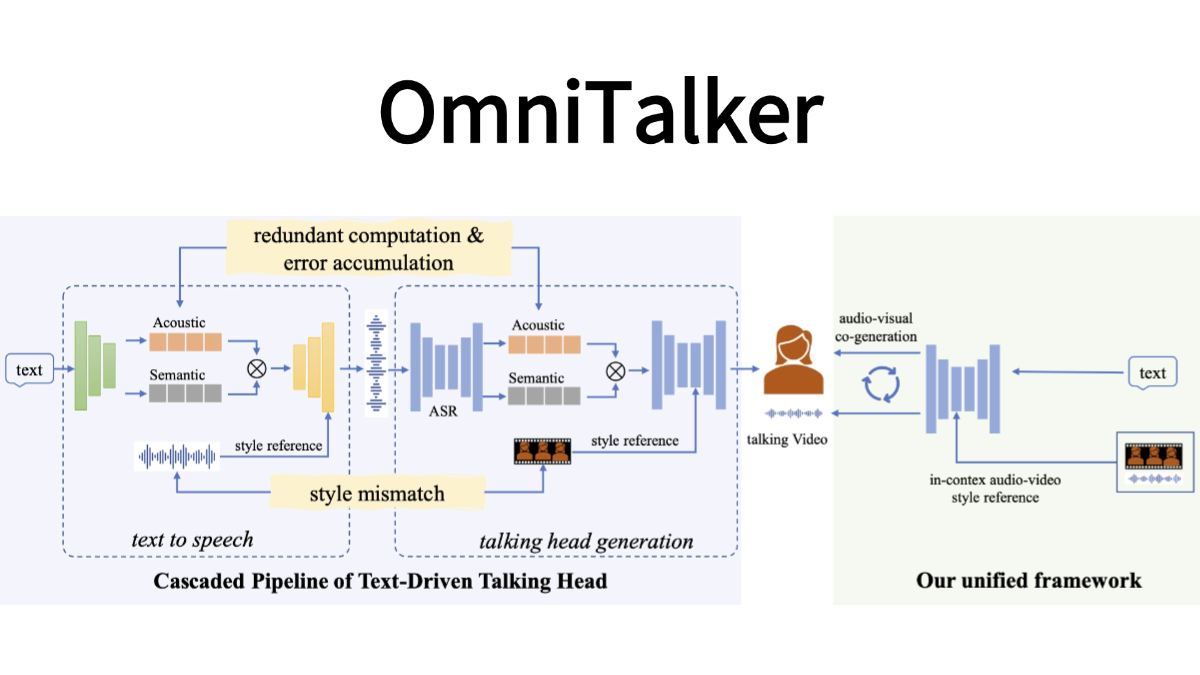
RealtimeVoiceChat : dialogue vocal naturel à faible latence avec l'IA

Introduction générale
RealtimeVoiceChat est un projet open source qui se concentre sur les conversations naturelles en temps réel avec l'intelligence artificielle via la voix. Les utilisateurs utilisent le microphone pour saisir leur voix, le système capture l'audio via le navigateur, le convertit rapidement en texte, un grand modèle de langage (LLM) génère une réponse, puis convertit le texte en sortie vocale, l'ensemble du processus est proche du temps réel. Le projet adopte une architecture client-serveur qui met l'accent sur une faible latence et prend en charge le streaming WebSocket et la gestion dynamique du dialogue. Il permet un déploiement Docker, est recommandé pour fonctionner sur le système Linux et l'environnement NVIDIA GPU, et intègre RealtimeSTT, RealtimeTTS et RealtimeTTS. Ollama et d'autres technologies qui permettent aux développeurs de créer des applications d'interaction vocale.

Liste des fonctions
- interaction vocale en temps réelLes utilisateurs saisissent leur voix par l'intermédiaire du microphone du navigateur, et le système transcrit et génère une réponse vocale en temps réel.
- Traitement à faible latenceOptimiser la latence de la synthèse vocale et de la synthèse vocale à 0,5-1 seconde en diffusant de l'audio à l'aide de WebSocket.
- Synthèse vocale (STT)Les logiciels de conversion de la parole en texte : convertissez rapidement la parole en texte à l'aide de RealtimeSTT (basé sur Whisper), avec une prise en charge de la transcription dynamique.
- Synthèse vocale (TTS)Les fonctions suivantes sont disponibles : Générer une parole naturelle via RealtimeTTS (Coqui, Kokoro, Orpheus pris en charge) avec un choix de styles vocaux.
- Gestion intelligente du dialogueIntégration des modèles linguistiques d'Ollama ou d'OpenAI pour soutenir la génération de dialogues flexibles et la gestion des interruptions.
- Détection dynamique de la voix: à travers
turndetect.pyPermet une détection intelligente des silences et s'adapte au rythme du dialogue. - interface webLe système de gestion de l'information de la Commission européenne (CEI) : il offre une interface de navigateur propre, utilise Vanilla JS et l'API audio Web, et prend en charge le retour d'information en temps réel.
- Déploiement DockerLes nouveautés : installation simplifiée avec Docker Compose, prise en charge de l'accélération GPU et de la gestion des modèles.
- Personnalisation du modèleLes modèles STT, TTS et LLM permettent d'ajuster les paramètres de la parole et du dialogue.
- open source et extensibleLe code est accessible au public et les développeurs sont libres de le modifier ou d'en étendre les fonctionnalités.
Utiliser l'aide
Processus d'installation
RealtimeVoiceChat prend en charge les déploiements Docker (recommandés) et les installations manuelles ; la méthode Docker convient aux systèmes Linux, en particulier aux environnements dotés de GPU NVIDIA ; les installations manuelles conviennent à Windows ou à des scénarios nécessitant davantage de contrôle. Vous trouverez ci-dessous les étapes détaillées :
Déploiement Docker (recommandé)
Nécessite Docker Engine, Docker Compose v2+ et NVIDIA Container Toolkit (pour les utilisateurs de GPU). Les systèmes Linux sont recommandés pour une meilleure prise en charge du GPU.
- entrepôt de clones: :
git clone https://github.com/KoljaB/RealtimeVoiceChat.git cd RealtimeVoiceChat
- Construire une image Docker: :
docker compose buildCette étape télécharge l'image de base, installe les dépendances de Python et de l'apprentissage automatique, et précharge les modèles STT par défaut (Whisper
base.en). Cela prend du temps, assurez-vous donc que votre réseau est stable. - Démarrage des services: :
docker compose up -dDémarrer l'application et le service Ollama avec le conteneur en arrière-plan. Attendez environ 1 à 2 minutes pour que l'initialisation soit terminée.
- Tirer le modèle Ollama: :
docker compose exec ollama ollama pull hf.co/bartowski/huihui-ai_Mistral-Small-24B-Instruct-2501-abliterated-GGUF:Q4_K_MCette commande permet d'extraire le modèle linguistique par défaut. Les utilisateurs peuvent trouver le modèle de langue par défaut dans la base de données
code/server.pymodificationLLM_START_MODELpour utiliser d'autres modèles. - Valider la facilité d'utilisation du modèle: :
docker compose exec ollama ollama listAssurez-vous que le modèle est correctement chargé.
- Arrêter ou redémarrer le service: :
docker compose down # 停止服务 docker compose up -d # 重启服务 - Voir le journal: :
docker compose logs -f app # 查看应用日志 docker compose logs -f ollama # 查看 Ollama 日志
Installation manuelle (Windows/Linux/macOS)
L'installation manuelle nécessite Python 3.9+, CUDA 12.1 (pour les utilisateurs de GPU) et FFmpeg. Les utilisateurs de Windows peuvent utiliser le logiciel fourni. install.bat Les scripts simplifient le processus.
- Installation des dépendances de base: :
- Assurez-vous que Python 3.9+ est installé.
- Les utilisateurs de GPU installent NVIDIA CUDA Toolkit 12.1 et cuDNN.
- Installer FFmpeg :
# Ubuntu/Debian sudo apt update && sudo apt install ffmpeg # Windows (使用 Chocolatey) choco install ffmpeg
- Cloner le référentiel et créer un environnement virtuel: :
git clone https://github.com/KoljaB/RealtimeVoiceChat.git cd RealtimeVoiceChat python -m venv venv # Linux/macOS source venv/bin/activate # Windows .\venv\Scripts\activate - Installation de PyTorch (matériel adapté): :
- GPU (CUDA 12.1) :
pip install torch==2.5.1+cu121 torchaudio==2.5.1+cu121 torchvision --index-url https://download.pytorch.org/whl/cu121 - CPU (performances plus lentes) :
pip install torch torchaudio torchvision
- GPU (CUDA 12.1) :
- Installation de dépendances supplémentaires: :
cd code pip install -r requirements.txtNote : DeepSpeed peut être compliqué à installer, les utilisateurs de Windows peuvent installer DeepSpeed par le biais de l'application
install.batTraitement automatique. - Installer Ollama (utilisateurs non Docker): :
- Se référer à la documentation officielle d'Ollama pour l'installation.
- Tirer le modèle :
ollama pull hf.co/bartowski/huihui-ai_Mistral-Small-24B-Instruct-2501-abliterated-GGUF:Q4_K_M
- Exécution de l'application: :
python server.py
mise en garde
- exigences en matière de matérielLes GPU NVIDIA (au moins 8 Go de RAM) sont recommandés pour garantir une faible latence ; l'utilisation du CPU peut entraîner une dégradation significative des performances.
- Configuration de DockerModification de la loi sur la protection des données
code/*.pypeut-êtredocker-compose.ymlAvant de le faire, vous devez réexécuter le programmedocker compose build. - Conformité des licencesLe moteur TTS (par exemple Coqui XTTSv2) et le modèle LLM font l'objet de licences distinctes et sont soumis à leurs conditions.
flux de travail
- Accès à l'interface Web: :
- Ouvrez votre navigateur et visitez
http://localhost:8000(ou l'IP du serveur distant). - Accordez les privilèges du microphone et cliquez sur "Démarrer" pour commencer la conversation.
- Ouvrez votre navigateur et visitez
- interaction vocale: :
- Parlez dans le microphone et le système capture le son via l'API audio Web.
- L'audio est transféré au backend via WebSocket, RealtimeSTT est converti en texte, Ollama/OpenAI génère une réponse, et RealtimeTTS est converti en parole et diffusé via le navigateur.
- Les délais de dialogue sont généralement de 0,5 à 1 seconde, avec la possibilité d'interrompre et de poursuivre à tout moment.
- Retour d'information en temps réel: :
- L'interface affiche un texte partiellement transcrit et les réponses de l'IA, ce qui permet aux utilisateurs de suivre facilement le dialogue.
- Vous pouvez cliquer sur "Stop" pour mettre fin au dialogue et sur "Reset" pour effacer l'historique.
- Ajustements de la configuration: :
- Moteur TTS: en
code/server.pymettre en placeSTART_ENGINE(par exemplecoqui,kokoro,orpheus), en ajustant le style de la voix. - Modèle LLMModification de la loi sur la protection des données
LLM_START_PROVIDERrépondre en chantantLLM_START_MODELVoici quelques-unes des caractéristiques les plus populaires d'Ollama - Paramètres STT: en
code/transcribe.pyréglage du centre de la scène Chuchotement Modélisation, seuils de langage ou de silence. - Détection du silence: en
code/turndetect.pymodificationsilence_limit_seconds(par défaut 0,2 seconde) pour optimiser le rythme du dialogue.
- Moteur TTS: en
- Débogage et optimisation: :
- Voir le journal :
docker compose logs -f(Docker) ou de consulter le site Web deserver.pySortie. - Problèmes de performances : Assurer l'adéquation de la version CUDA, réduire la consommation d'énergie et les émissions de gaz à effet de serre.
realtime_batch_sizeOu utiliser un modèle léger. - Configuration du réseau : si le protocole HTTPS est requis, définissez le paramètre
USE_SSL = Trueet indiquer le chemin d'accès au certificat (voir la configuration SSL officielle).
- Voir le journal :
Fonction en vedette Fonctionnement
- Traitement en continu à faible latenceLe système d'audio chunking est un système d'audio chunking via WebSocket, combiné avec RealtimeSTT et RealtimeTTS, avec un temps de latence aussi bas que 0,5 seconde. Les utilisateurs peuvent avoir des conversations fluides sans attendre.
- Gestion dynamique du dialogue: :
turndetect.pyDétecte intelligemment la fin du discours et prend en charge les interruptions naturelles. Par exemple, l'utilisateur peut s'interrompre à tout moment et le système se met en pause pour générer et traiter de nouvelles données. - Interaction avec l'interface webL'interface du navigateur utilise Vanilla JS et l'API Web Audio pour assurer la transcription en temps réel et l'affichage des réponses. Les utilisateurs peuvent contrôler le dialogue à l'aide de boutons "Start/Stop/Reset".
- Flexibilité de la modélisationSupport pour changer de moteur TTS (Coqui/Kokoro/Orpheus) et de backends LLM (Ollama/OpenAI). Par exemple, changement de TTS :
START_ENGINE = "kokoro" # 在 code/server.py 中修改 - Gestion de DockerLe service est géré par Docker Compose, et la mise à jour du modèle est seulement nécessaire :
docker compose exec ollama ollama pull <new_model>
scénario d'application
- Recherche sur l'interaction vocale avec l'IA
Les développeurs peuvent tester l'intégration de RealtimeSTT, RealtimeTTS et LLM pour explorer l'optimisation de l'interaction vocale à faible latence. Le code source ouvert prend en charge les paramètres personnalisés et convient à la recherche universitaire. - Prototype de service client intelligent
Les entreprises peuvent développer des systèmes de service à la clientèle vocaux basés sur le projet. Les utilisateurs posent des questions vocales et le système répond en temps réel aux questions courantes, telles que l'assistance technique ou les conseils sur les produits. - Outils d'apprentissage des langues
Les établissements d'enseignement peuvent utiliser la fonctionnalité multilingue TTS pour développer des outils d'entraînement au dialogue vocal. Les étudiants dialoguent avec l'IA pour s'entraîner à la prononciation et à la conversation, et le système leur fournit un retour d'information en temps réel. - Assistants vocaux personnels
Les passionnés de technologie peuvent déployer des projets pour expérimenter l'interaction vocale naturelle avec l'IA, en simulant un assistant intelligent, à des fins de divertissement personnel ou pour de petits projets.
QA
- Quel est le matériel nécessaire ?
Système Linux recommandé avec un GPU NVIDIA (au moins 8 Go de mémoire vidéo) et CUDA 12.1. Le CPU fonctionne de manière faisable mais avec une latence élevée. Configuration minimale : Python 3.9+, 8 Go de RAM. - Comment résoudre les problèmes de déploiement de Docker ?
Assurez-vous que Docker, Docker Compose et NVIDIA Container Toolkit sont correctement installés. Vérifierdocker-compose.ymlde la configuration du GPU pour consulter les journaux :docker compose logs -f. - Comment passer de la voix au modèle ?
modificationscode/server.pya fait moucheSTART_ENGINE(TTS) ouLLM_START_MODEL(LLM), l'utilisateur de Docker doit extraire à nouveau le modèle :docker compose exec ollama ollama pull <model>. - Quelles sont les langues prises en charge ?
RealtimeTTS prend en charge plusieurs langues (par exemple, l'anglais, le chinois, le japonais), qui doivent être définies dans la sectioncode/audio_module.pySpécifiez le modèle de langue et de parole dans le champ
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes

Pas de commentaires...