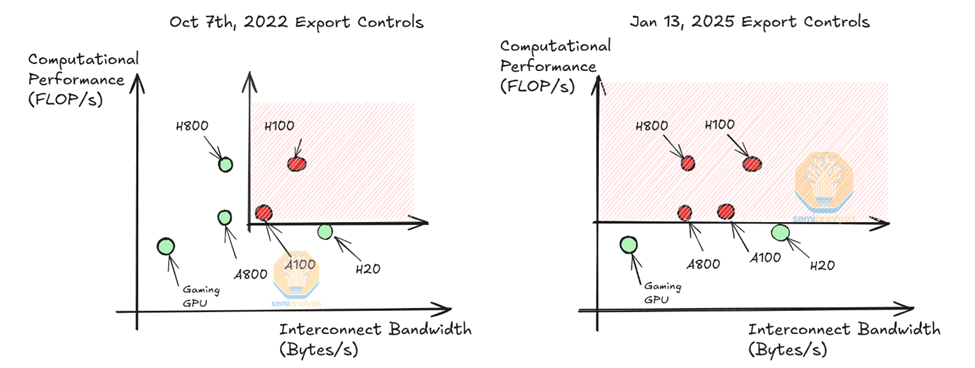
Qwen2.5-Max basé sur l'architecture MoE surpasse complètement DeepSeek V3

Aperçu du modèle
L'équipe de Qwen a récemment publié le modèle Qwen2.5-Max, qui utilise plus de 20 billions de tokens de données de pré-entraînement et un schéma de post-entraînement raffiné, et a réalisé des percées dans l'application à grande échelle de l'architecture MoE. Le modèle a progressé. Le modèle est désormais disponible viaInterface APIpeut-êtreChat Qwenpour l'expérience.

Caractéristiques techniques
1) Innovations dans l'architecture des modèles
- Optimisation d'un système expert hybride: Allocation efficace des ressources informatiques par le biais de mécanismes de routage dynamiques
- Évolutivité multimodaleLe système de gestion des données de l'entreprise : il prend en charge plusieurs types d'entrées et de sorties telles que le texte, les données structurées, etc.
- amélioration de la contextualisationEntrée maximale : 30 720 tokens, peut générer un texte continu jusqu'à 8 192 tokens.
2. matrice fonctionnelle de base
| dimension fonctionnelle | Indicateurs techniques |
|---|---|
| Prise en charge multilingue | Couverture de 29 langues (dont le chinois, l'anglais, le français, l'espagnol, etc.) |
| capacités de calcul | Opérations mathématiques complexes et génération de codes |
| Traitement structuré | Génération et analyse de données JSON/tableau |
| compréhension du contexte | Génération de concaténation de textes longs de 8K tokens |
| aptitude à l'emploi | Systèmes de dialogue/analyse de données/raisonnement basé sur la connaissance |
Évaluation des performances
Comparaison des modèles de commande
Qwen2.5-Max se montre très compétitif dans les tests de référence tels que MMLU-Pro (test de connaissances universitaires), LiveCodeBench (évaluation des capacités de programmation) et Arena-Hard (simulation des préférences humaines) :

Les données de test montrent que le modèle surpasse DeepSeek V3 dans les domaines de la capacité de programmation (LiveCodeBench) et du raisonnement intégré (LiveBench), et atteint le niveau supérieur dans le test de raisonnement de haut niveau GPQA-Diamond.
Comparaison du modèle de base
Par rapport aux principaux modèles open source, Qwen2.5-Max présente des avantages techniques au niveau des capacités de base :

En comparant Llama-3.1 avec une échelle de paramètres de 405B et Qwen2.5-72B avec 720B paramètres, Qwen2.5-Max conserve l'avantage dans la plupart des éléments du test, validant ainsi l'efficacité de l'architecture MoE dans la mise à l'échelle du modèle.
Accès et utilisation
1. accès à l'API du nuage
from openai import OpenAI
import os
client = OpenAI(
api_key=os.getenv("API_KEY"),
base_url="https://dashscale.aliyuncs.com/compatible-mode/v1",
)
response = client.chat.completions.create(
model="qwen-max-2025-01-25",
messages=[
{'role':'system', 'content':'设定AI助手角色'},
{'role':'user', 'content':'输入查询内容'}
]
)
2. l'expérience interactive
- entretiensEspace de démonstration du visage de l'étreinte
- Lancement du bouton Exécuter pour charger le modèle
- Interaction en temps réel par le biais d'une boîte de saisie de texte
3. déploiement en entreprise
- inscriptionCompte Aliyun
- Lancement d'un grand modèle de plateforme de services
- Créer des clés API pour l'intégration du système
Direction de l'évolution technologique
La version actuelle est continuellement optimisée dans les domaines suivants :
- Stratégies d'amélioration de la qualité des données après la formation
- Collaboration multi-experts pour l'optimisation de l'efficacité
- Accélération du raisonnement à faible consommation de ressources
- Développement d'une interface multimodale étendue
perspectives d'avenir
L'amélioration continue de l'échelle des données et de l'échelle des paramètres du modèle peut effectivement améliorer le niveau d'intelligence du modèle. À l'avenir, nous continuerons à explorer, en plus de la mise à l'échelle de la préformation, nous investirons vigoureusement dans la mise à l'échelle de l'apprentissage par renforcement, dans l'espoir d'atteindre une intelligence supérieure à celle des êtres humains et de conduire l'IA à explorer le domaine de l'inconnu.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...