
Qwen2.5-1M : Un modèle Qwen Open Source supportant des contextes de 1 million de tokens

1. introduction
Il y a deux mois, l'équipe de Qwen a mis à jour Qwen2.5-Turbo pour prendre en charge des contextes allant jusqu'à un million de tokens. Aujourd'hui, Qwen a officiellement lancé le modèle open source Qwen2.5-1M et le support du cadre d'inférence correspondant. Voici les points forts de la version :
Modèles Open Source : Deux nouveaux modèles open-source ont été publiés, à savoir Qwen2.5-7B-Instruct-1M répondre en chantant Qwen2.5-14B-Instruct-1MC'est la première fois que Qwen étend le contexte du modèle open source Qwen à une longueur de 1M.
Cadre de raisonnement : Pour aider les développeurs à déployer plus efficacement la famille de modèles Qwen2.5-1M, l'équipe Qwen a entièrement ouvert le modèle Qwen 2.5-1M basé sur le modèle vLLM avec une approche d'attention éparse intégrée, ce qui rend le cadre plus rapide dans le traitement de 1M d'entrées étiquetées par 3x à 7x.
Rapport technique : L'équipe de Qwen a également partagé les détails techniques de la série Qwen2.5-1M, y compris la conception des cadres de formation et d'inférence et les résultats des expériences d'ablation.
Lien vers le modèle :https://www.modelscope.cn/collections/Qwen25-1M-d6cf9fd33f0a40
Rapport technique :https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-1M/Qwen2_5_1M_Technical_Report.pdf
Liens d'expérience :https://modelscope.cn/studios/Qwen/Qwen2.5-1M-Demo
2. la performance du modèle
Tout d'abord, examinons les performances de la famille de modèles Qwen2.5-1M dans les tâches à contexte long et les tâches à texte court.
tâche contextuelle longue
Avec une longueur de contexte de 1 million Jetons Dans la tâche de récupération de clés, la famille de modèles Qwen2.5-1M a récupéré avec précision les informations cachées dans des documents d'une longueur de 1M, avec seulement quelques erreurs dans le modèle 7B.
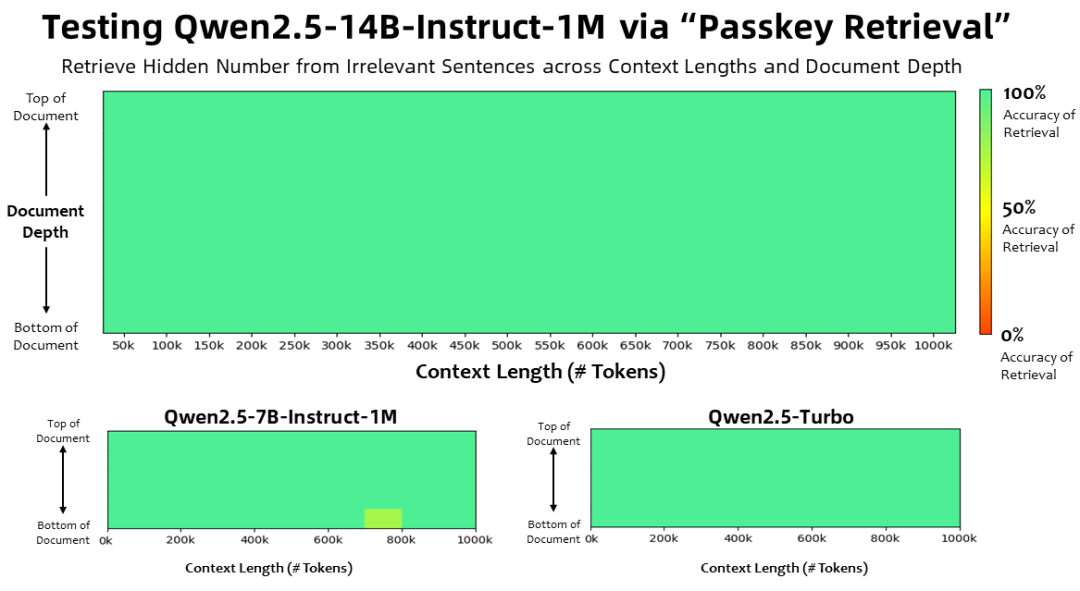
Pour les tâches plus complexes de compréhension de contextes longs, les jeux d'essai RULER, LV-Eval et LongbenchChat ont été choisis.
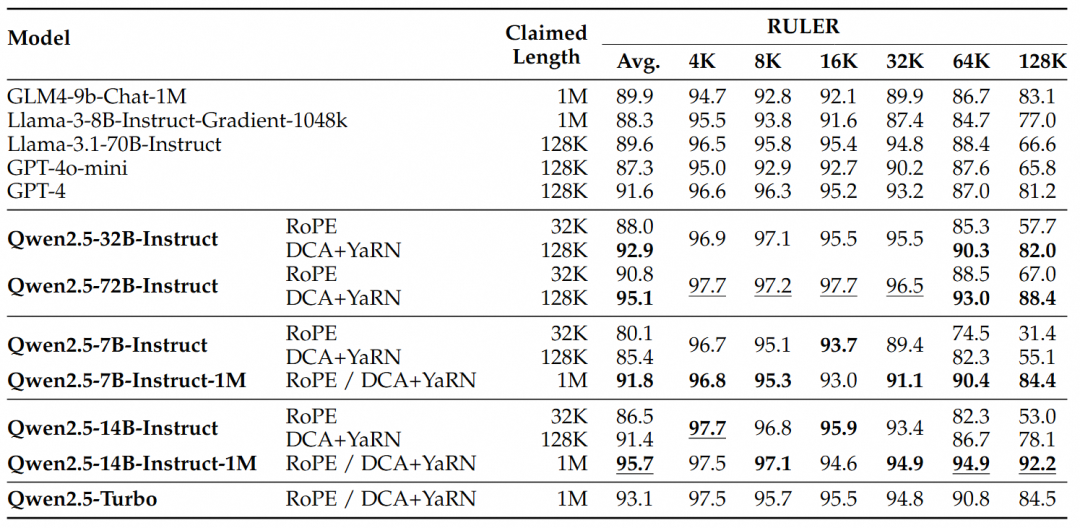
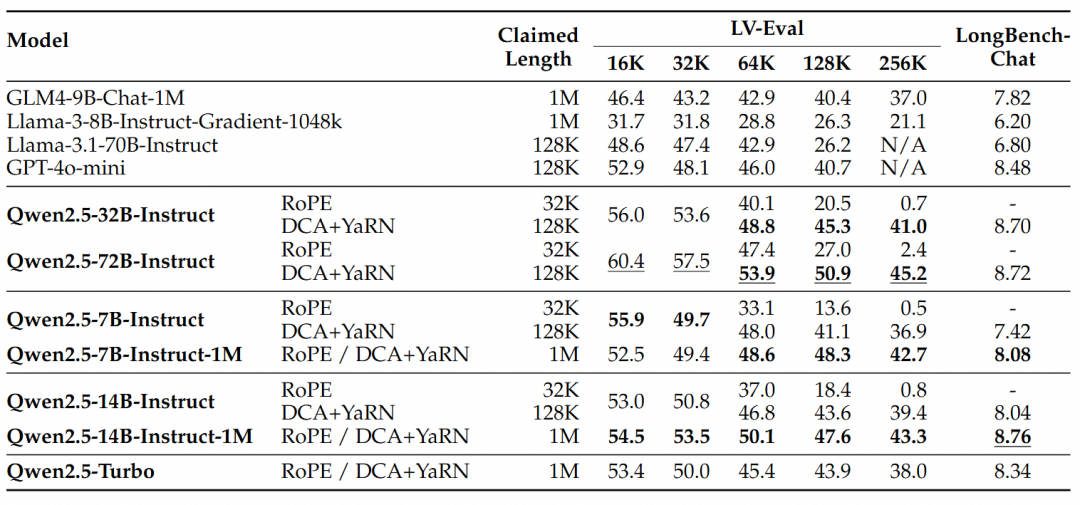
Ces résultats permettent de tirer les conclusions suivantes :
- Performances nettement supérieures à celles de la version 128K :La famille de modèles Qwen2.5-1M est nettement plus performante que la version précédente de 128K pour la plupart des tâches à contexte long, en particulier lorsqu'il s'agit de tâches d'une longueur supérieure à 64K.
- Les avantages en termes de performances sont évidents :Le modèle Qwen2.5-14B-Instruct-1M surpasse non seulement Qwen2.5-Turbo, mais aussi GPT-4o-mini sur plusieurs ensembles de données, ce qui en fait un modèle open-source de choix pour les tâches à contexte long.
tâche séquentielle courte
Outre les performances sur les longues séquences, les performances des modèles sur les courtes séquences sont tout aussi importantes. Les modèles de la série Qwen2.5-1M et les versions précédentes de 128K ont été comparés dans des repères académiques largement utilisés, et le GPT-4o-mini a été ajouté à des fins de comparaison. 
Il peut être trouvé :
- Les performances de Qwen2.5-7B-Instruct-1M et Qwen2.5-14B-Instruct-1M sur le texte court sont comparables à celles de leurs versions 128K, ce qui garantit que les capacités de base n'ont pas été compromises par l'ajout de capacités de traitement de longues séquences.
- Par rapport à GPT-4o-mini, Qwen2.5-14B-Instruct-1M et Qwen2.5-Turbo obtiennent des performances similaires sur la tâche du texte court, alors que la longueur du contexte est huit fois supérieure à celle de GPT-4o-mini.
3. les technologies clés
Formation de longue durée
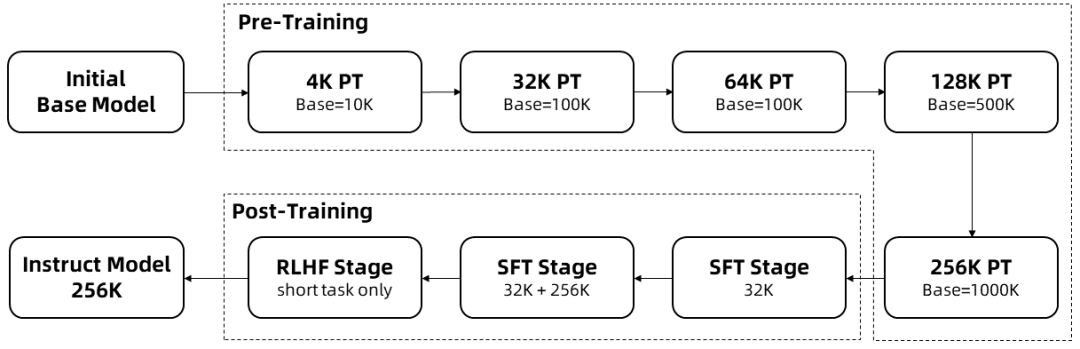
L'apprentissage de longues séquences nécessite beaucoup de ressources informatiques, c'est pourquoi une expansion progressive de la longueur a été utilisée pour étendre la longueur du contexte de Qwen2.5-1M de 4K à 256K en plusieurs étapes :
À partir d'un point de contrôle intermédiaire du Qwen 2.5 pré-entraîné, la longueur du contexte est de 4K à ce stade.
Pendant la phase de pré-entraînementEn outre, la longueur du contexte a été progressivement augmentée de 4K à 256K, tandis que la fréquence de base du RdP a été augmentée de 10 000 à 10 000 000 en utilisant le système de fréquence de base ajustée.
Pendant la phase de mise au point du suiviLe système de gestion de l'information est conçu en deux étapes afin de maintenir les performances sur les séquences courtes :
Phase I : Le réglage fin n'est effectué que sur les instructions courtes (d'une longueur maximale de 32 Ko), pour lesquelles les mêmes données et le même nombre d'étapes sont utilisés que dans la version 128 Ko de Qwen2.5.
Phase II : Un mélange d'instructions courtes (jusqu'à 32K) et longues (jusqu'à 256K) est mis en œuvre pour améliorer les performances des tâches longues tout en maintenant la qualité des tâches courtes.
Dans la phase d'apprentissage intensifqui entraîne le modèle sur des textes courts (jusqu'à 8K tokens). Nous avons constaté que même lorsque le modèle est entraîné sur des manuels courts, l'augmentation de l'alignement préféré par l'homme se généralise bien aux tâches à contexte long. Avec l'entraînement ci-dessus, nous obtenons un modèle Instruct qui peut traiter des séquences d'une longueur allant jusqu'à 256 000 tokens.
Avec l'entraînement ci-dessus, on obtient un modèle de réglage fin des instructions avec une longueur de contexte de 256K.
Extrapolation de la longueur
Dans le processus de formation ci-dessus, la longueur du contexte du modèle n'est que de 256 000 jetons. Afin de l'étendre à 1 million de jetons, une technique d'extrapolation de la longueur est utilisée.
Actuellement, les modèles linguistiques à grande échelle basés sur l'encodage de la position rotationnelle produisent une dégradation des performances dans les tâches à contexte long, ce qui est principalement dû à la grande distance de position relative entre la requête et la clé, qui n'est pas vue pendant le processus d'apprentissage, lors du calcul des poids d'attention. Pour résoudre ce problème, Qwen2.5-1M utilise l'approche Dual Chunk Attention (DCA), qui résout ce problème en prenant les positions relatives excessivement grandes et en les ramenant à des valeurs plus petites.
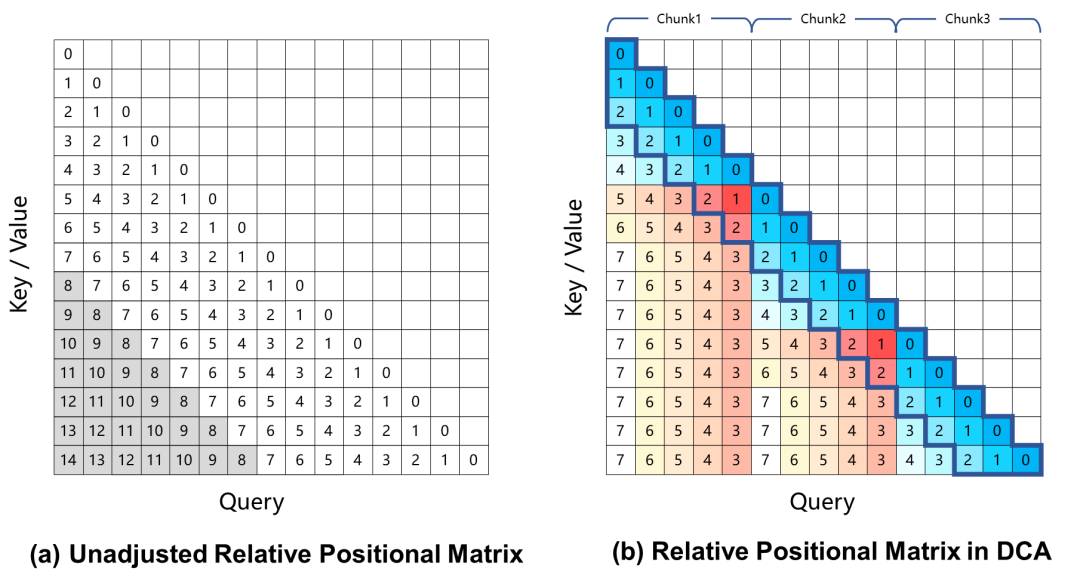
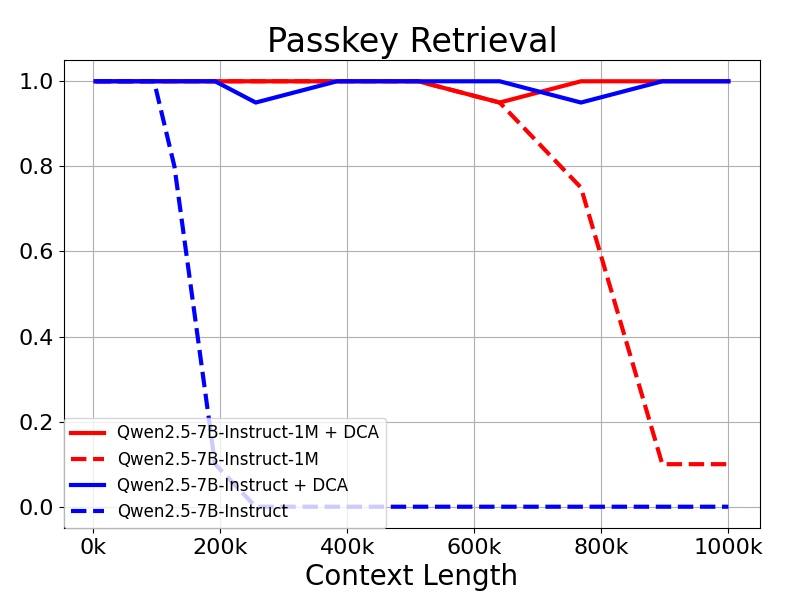
Le modèle Qwen2.5-1M et la version précédente de 128K ont été évalués avec et sans la méthode d'extrapolation de la longueur.
Les résultats montrent que même les modèles formés uniquement sur 32K tokens, tels que Qwen2.5-7B-Instruct, ne parviennent pas à traiter le contexte de 1M tokens de la Passkey. Récupération La tâche atteint également une précision quasi parfaite. Cela démontre la capacité de l'ACD à étendre de manière significative la longueur des contextes pris en charge sans formation supplémentaire.
mécanisme d'attention éparse (en physique des particules)
Pour les modèles linguistiques à contexte long, la vitesse d'inférence est cruciale pour l'expérience de l'utilisateur. Pour accélérer la phase de pré-population, l'équipe de recherche introduit un mécanisme d'attention clairsemée basé sur MInference. En outre, plusieurs améliorations sont proposées :
- Chunked Prefill : si le modèle est utilisé directement pour traiter des séquences d'une longueur maximale de 1 million, les poids d'activation de la couche MLP entraînent une surcharge de mémoire considérable, jusqu'à 71 Go dans le cas de Qwen2-5-7B. En adaptant Chunked Prefill avec Sparse Attention, la séquence d'entrée peut être découpée en morceaux de 32768 longueurs et pré-remplie un par un, et l'utilisation de la mémoire des poids d'activation de la couche MLP peut être réduite de 96,71 TP3T, ce qui réduit considérablement les besoins en mémoire de l'appareil.
- Schéma d'extrapolation de la longueur intégré : nous intégrons également un schéma d'extrapolation de la longueur basé sur l'ACD dans le mécanisme d'attention éparse, ce qui permet à notre cadre d'inférence de bénéficier à la fois d'une efficacité et d'une précision d'inférence accrues pour les tâches portant sur des séquences longues.
- Optimisation de la sparité : la méthode MInference originale nécessite une recherche hors ligne pour déterminer la configuration optimale de la sparsification pour chaque tête d'attention. Cette recherche est généralement effectuée sur des séquences courtes et ne fonctionne pas nécessairement bien avec des séquences plus longues en raison des besoins importants en mémoire des poids d'attention complets. Nous proposons une méthode qui permet d'optimiser la configuration de la sparsification sur des séquences d'une longueur d'un million, réduisant ainsi de manière significative la perte de précision due à l'attention éparse.
- Autres optimisations : nous avons introduit d'autres optimisations, telles que l'optimisation de l'efficacité des opérateurs et le parallélisme dynamique du pipeline, afin d'exploiter tout le potentiel de l'ensemble du cadre.
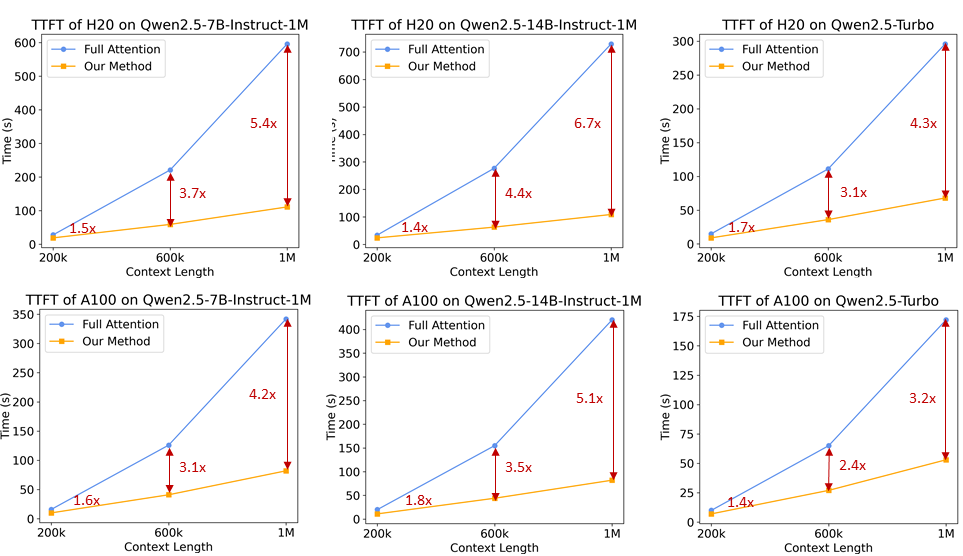
Grâce à ces améliorations, le cadre d'inférence est en mesure de réduire le nombre d'éléments de 1M jeton La vitesse de prépeuplement des séquences de longueur a été multipliée par 3,2 à 6,7.
4. déploiement du modèle
Préparation du système
Pour de meilleures performances, il est recommandé d'utiliser un GPU doté d'une architecture Ampere ou Hopper qui prend en charge des cœurs optimisés.
Veillez à ce que les conditions suivantes soient remplies :
- Version CUDA : 12.1 ou 12.3
- Version de Python : >=3.9 et <=3.12
Besoins en mémoire, pour le traitement de séquences d'une longueur de 1M :
- Qwen2.5-7B-Instruct-1M : nécessite au moins 120 Go de mémoire vidéo (somme multi-GPU).
- Qwen2.5-14B-Instruct-1M : nécessite au moins 320 Go de mémoire vidéo (somme multi-GPU).
Si la mémoire du GPU ne répond pas à ces exigences, vous pouvez toujours utiliser Qwen2.5-1M pour des tâches plus courtes.
Installation des dépendances
Pour l'instant, vous devez cloner le dépôt vLLM à partir d'une branche personnalisée et l'installer manuellement. L'équipe de recherche travaille sur l'intégration de cette branche au projet vLLM.
git clone -b dev/dual-chunk-attn git@github.com:QwenLM/vllm.git cd vllm pip install -e . -v
Démarrer un service API compatible avec OpenAI
Spécifie que le modèle doit être téléchargé à partir de ModelScope
export VLLM_USE_MODELSCOPE=True
Publication de services API compatibles avec l'OpenAI
vllm serve Qwen/Qwen2.5-7B-Instruct-1M \ --tensor-parallel-size 4 \ --max-model-len 1010000 \ --enable-chunked-prefill --max-num-batched-tokens 131072 \ --enforce-eager \ --max-num-seqs 1
Paramètre Description :
--tensor-parallel-size- Le paramètre correspond au nombre de GPU que vous utilisez. Les modèles 7B prennent en charge jusqu'à 4 GPU et les modèles 14B jusqu'à 8 GPU.
--max-model-len- Définit la longueur maximale de la séquence d'entrée. Réduisez cette valeur si vous rencontrez des problèmes de mémoire insuffisante.
--max-num-batched-tokens- Définit la taille du bloc du pré-remplissage groupé. Une valeur plus petite réduit l'utilisation de la mémoire d'activation, mais peut ralentir le raisonnement.
- La valeur recommandée est de 131072 pour des performances optimales.
--max-num-seqs- Limiter le nombre de séquences traitées simultanément.
Interagir avec les modèles
Les méthodes suivantes peuvent être utilisées pour interagir avec le modèle déployé :
Option 1.
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen2.5-7B-Instruct-1M",
"messages": [
{
"role": "user",
"content": "Tell me something about large language models."
}
],
"temperature": 0.7,
"top_p": 0.8,
"repetition_penalty": 1.05,
"max_tokens": 512
}'
Option 2 : Utiliser Python
from openai import OpenAI
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
prompt = (
"""There is an important info hidden inside a lot of irrelevant text.
Find it and memorize them. I will quiz you about the important information there.\n\n
The pass key is 28884. Remember it. 28884 is the pass key.\n"""
+ "The grass is green. The sky is blue. The sun is yellow. Here we go. There and back again. " * 800
+ "\nWhat is the pass key?"
)
# The prompt is 20k long. You can try a longer prompt by replacing 800 with 40000.
chat_response = client.chat.completions.create(
model="Qwen/Qwen2.5-7B-Instruct-1M",
messages=[
{"role": "user", "content": prompt},
],
temperature=0.7,
top_p=0.8,
max_tokens=512,
extra_body={
"repetition_penalty": 1.05,
},
)
print("Chat response:", chat_response)
Vous pouvez également explorer d'autres cadres, tels que Qwen-Agent, pour permettre aux modèles de lire des fichiers PDF, etc.
5. utiliser l'API-Inférence de Magic Hitch pour appeler directement la fonction
L'API-Inférence de la plateforme Magic Match prend également en charge pour la première fois les modèles Qwen2.5-7B-Instruct-1M et Qwen2.5-14B-Instruct-1M. Les utilisateurs de Magic Hitch peuvent utiliser le modèle directement au moyen d'appels API. L'utilisation spécifique de l'API-Inférence peut être décrite sur la page du modèle (par exemple https://modelscope.cn/models/Qwen/Qwen2.5-14B-Instruct-1M ) :

Ou consultez la documentation sur l'inférence API : https://www.modelscope.cn/docs/model-service/API-Inference/intro
Nous remercions la plateforme AliCloud Hundred Refinement Platform pour la prise en charge de l'arithmétique en coulisses.
Utilisation d'Ollama et de llamafile
Afin de faciliter votre utilisation locale, Magic Hitch fournit la version GGUF et la version llamafile du modèle Qwen2.5-7B-Instruct-1M pour la première fois. Il peut être appelé par le cadre Ollama, ou utiliser directement llamafile.
1. appel Ollama
Tout d'abord, configurez ollama sous enable :
ollama serve
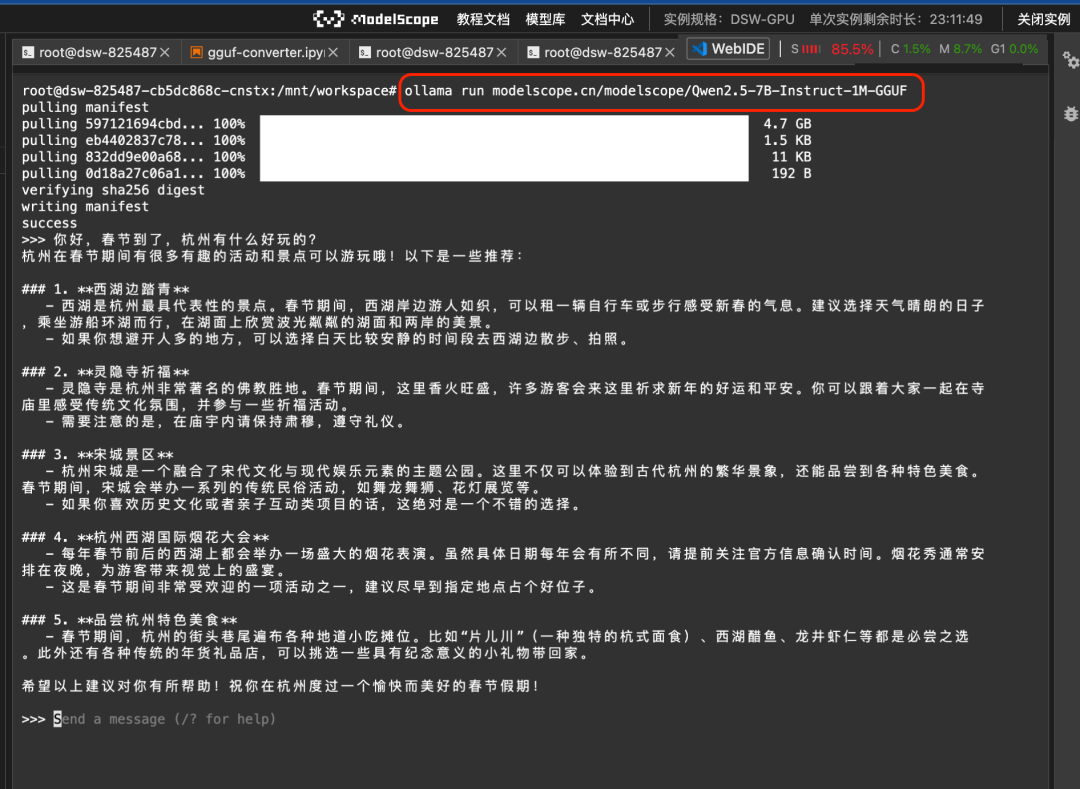
Vous pouvez ensuite exécuter le modèle GGUF sur l'attelage magique directement à l'aide de la commande ollama run :
ollama run modelscope.cn/modelscope/Qwen2.5-7B-Instruct-1M-GGUFRésultats de la course :
2. Modèle llamafile directement pull-up
Llamafile Fournit une solution où le grand modèle et l'environnement d'exécution sont tous encapsulés dans un seul fichier exécutable. Grâce à l'intégration de la ligne de commande Magic Ride et de llamafile, vous pouvez réellement exécuter le grand modèle en un seul clic dans différents systèmes d'exploitation tels que Linux/Mac/Windows :
modelscope llamafile --model Qwen-Llamafile/Qwen2.5-7B-Instruct-1M-llamafileRésultats de la course :
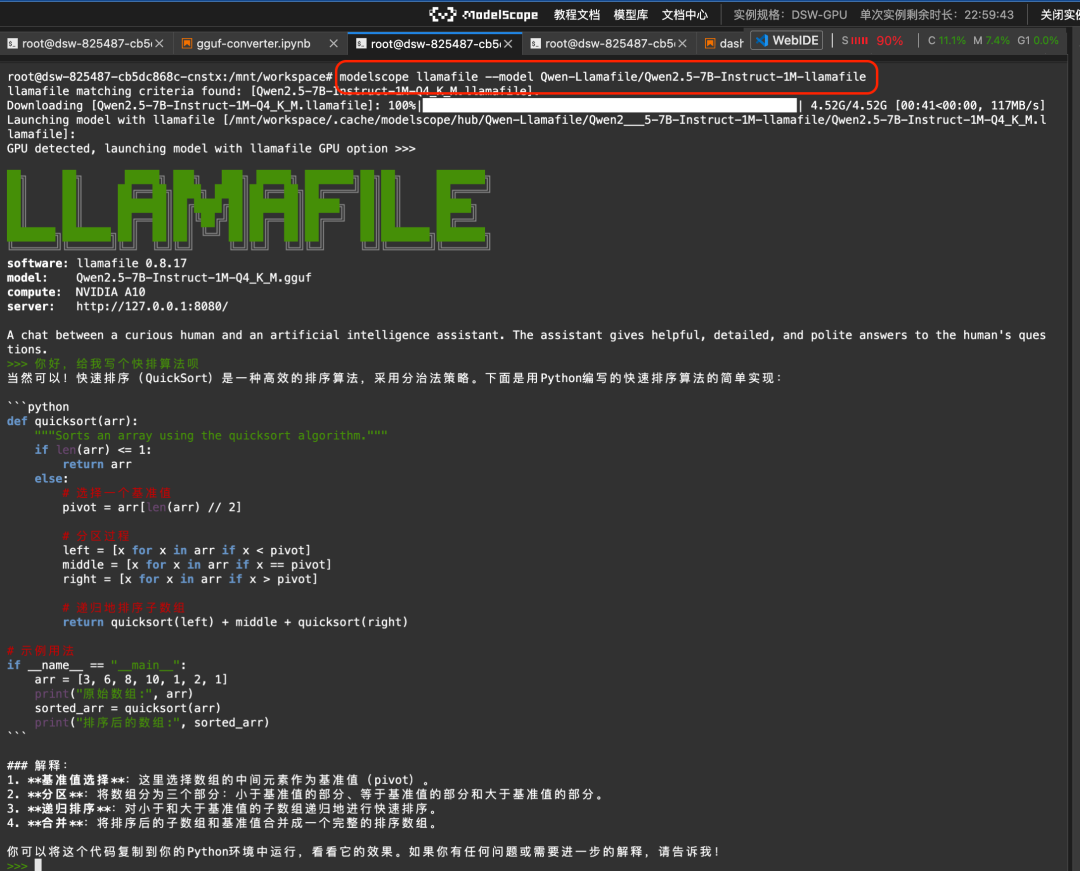
Une documentation plus complète est disponible à l'adresse suivante : https://www.modelscope.cn/docs/models/advanced-usage/llamafile
6. mise au point du modèle
Nous présentons ici la mise au point de Qwen/Qwen2.5-7B-Instruct-1M à l'aide de ms-swift.
Avant de commencer les réglages, assurez-vous que votre environnement est correctement installé :
# 安装ms-swift git clone https://github.com/modelscope/ms-swift.git cd ms-swift pip install -e .
Nous proposons des démonstrations de réglage fin et des styles exécutables pour des ensembles de données personnalisés, et les scripts de réglage fin sont les suivants :
CUDA_VISIBLE_DEVICES=0
swift sft \
--model Qwen/Qwen2.5-7B-Instruct-1M \
--train_type lora \
--dataset 'AI-ModelScope/alpaca-gpt4-data-zh#500' \
'AI-ModelScope/alpaca-gpt4-data-en#500' \
'swift/self-cognition#500' \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--gradient_accumulation_steps 16 \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 5 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4 \
--model_author swift \
--model_name swift-robot
Utilisation de la mémoire des vidéos d'entraînement :

Format de données personnalisé : (il suffit de le spécifier directement en utilisant `--dataset `)
{"messages": [{"role": "user", "content": "<query>"}, {"role": "assistant", "content": "<response>"}, {"role": "user", "content": "<query2>"}, {"role": "assistant", "content": "<response2>"}]}
Script de raisonnement :
CUDA_VISIBLE_DEVICES=0 \
swift infer \
--adapters output/vx-xxx/checkpoint-xxx \
--stream true \
--max_new_tokens 2048
Pousser le modèle vers ModelScope :
CUDA_VISIBLE_DEVICES=0 swift export \
--adapters output/vx-xxx/checkpoint-xxx \
--push_to_hub true \
--hub_model_id '' \
--hub_token ''
7. et ensuite ?
Bien que la famille Qwen2.5-1M offre d'excellentes options open-source pour les tâches de traitement des séquences longues, l'équipe de recherche est pleinement consciente que les modèles de contexte long peuvent encore être améliorés. Notre objectif est de construire des modèles qui excellent à la fois dans les tâches courtes et longues afin de s'assurer qu'ils sont vraiment utiles dans les scénarios d'application du monde réel. À cette fin, l'équipe travaille sur des méthodes d'entraînement, des architectures de modèles et des approches de raisonnement plus efficaces, afin que ces modèles puissent être déployés efficacement et avec des performances optimales, même dans des environnements où les ressources sont limitées. L'équipe est convaincue que ces efforts ouvriront de nouvelles possibilités pour les modèles à contexte long, en élargissant considérablement leur champ d'application et en continuant à repousser les limites du domaine, alors restez à l'écoute !
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...