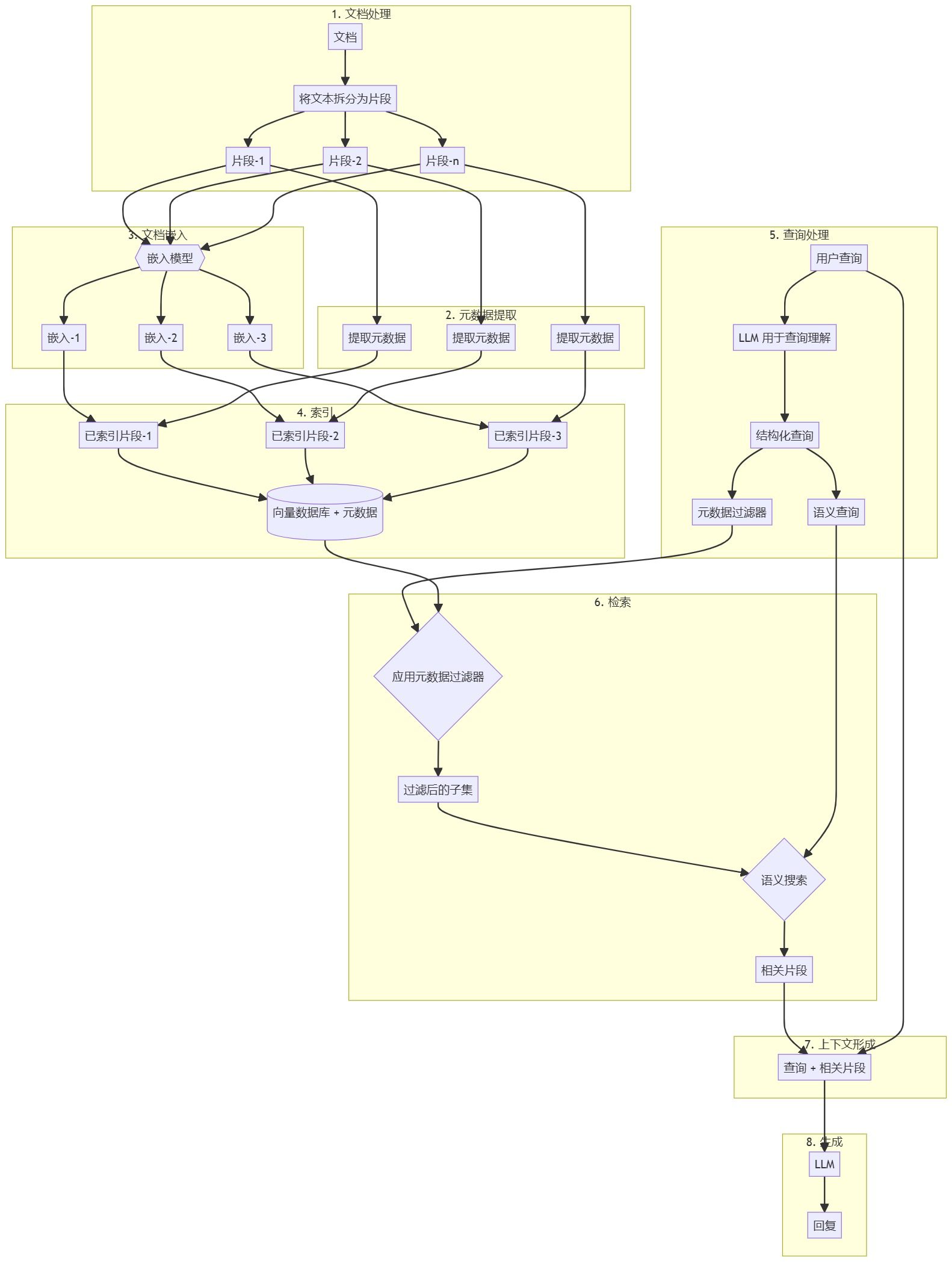
Stratégie d'extraction simple et efficace du RAG : recherche et réarrangement hybrides clairsemés + denses, et utilisation de "cue caching" pour générer un contexte global pertinent pour les morceaux de texte.


Pour qu'un modèle d'IA soit utile dans un scénario particulier, il doit généralement avoir accès à des connaissances de base. Par exemple, un chatbot d'assistance à la clientèle doit comprendre l'activité spécifique qu'il sert, tandis qu'un bot d'analyse juridique doit avoir accès à un grand nombre d'affaires antérieures.
Les développeurs augmentent souvent les connaissances des modèles d'IA à l'aide de la méthode RAG (Retrieval-Augmented Generation), qui consiste à extraire des informations pertinentes d'une base de connaissances et à les associer à des messages-guides de l'utilisateur afin d'améliorer considérablement la réactivité du modèle. Le problème est que les méthodes traditionnelles de RAG Les programmes perdent le contexte lors de l'encodage des informations, ce qui a souvent pour conséquence que le système est incapable de retrouver les informations pertinentes dans la base de connaissances.
Dans cet article, nous décrivons une approche qui peut améliorer de manière significative l'étape de récupération dans RAG. Cette approche est appelée récupération contextuelle et utilise deux sous-techniques : les emboîtements contextuels et le BM25 contextuel. Cette approche réduit le nombre d'échecs de 491 TP3T, et de 671 TP3T lorsqu'elle est combinée avec le reranking. Ces améliorations augmentent considérablement la précision de l'extraction, ce qui se traduit directement par une amélioration des performances sur les tâches en aval.
L'essence est un mélange de résultats sémantiquement similaires et de résultats similaires en termes de fréquence de mots, parfois les résultats sémantiques ne représentent pas l'intention réelle. Lisez le lien fourni à la fin du texte, cela fait deux ans que cette "vieille" stratégie a été publiée, et la méthode est encore rarement utilisée, soit en tombant dans la stratégie RAG extrêmement complexe, soit en utilisant uniquement l'incorporation + le réarrangement.
Cet article est une petite amélioration de l'ancienne stratégie consistant à utiliser des "indices de cache" pour générer un contexte pour les blocs de texte qui correspond au contexte général du document à faible coût. Il s'agit d'un petit changement, mais les résultats sont impressionnants !
Pour ce faire, vous pouvez Notre exemple de code utiliser Claude Déployez votre propre solution de recherche contextuelle.
Note sur l'utilisation simple de pointes plus longues
Parfois, la solution la plus simple est aussi la meilleure. Si votre base de connaissances est inférieure à 200 000 tokens (environ 500 pages), vous pouvez inclure l'ensemble de la base de connaissances directement dans les invites fournies au modèle, sans avoir besoin d'un RAG ou d'une méthode similaire.
Il y a quelques semaines, nous avons publié pour Claude Cache CueOutre la nouvelle API, nous avons considérablement accéléré et réduit le coût de cette approche. Les développeurs peuvent désormais mettre en cache les indices fréquemment utilisés entre les appels à l'API, ce qui réduit la latence de plus de 2 fois et le coût de 90% (vous pouvez voir comment cela fonctionne en lisant notre Exemple de code pour le Hint Cache (Comprendre son fonctionnement).
Cependant, au fur et à mesure que votre base de connaissances s'étoffe, vous aurez besoin de solutions plus évolutives, et c'est là que la recherche contextuelle entre en jeu. Cette mise en contexte étant faite, passons aux choses sérieuses.
RAG Basics : Élargir la base de connaissances
RAG est la solution typique pour les grandes bases de connaissances qui ne tiennent pas dans une fenêtre contextuelle :
- Décomposition de la base de connaissances (corpus de documents) en fragments de texte plus petits, ne dépassant généralement pas quelques centaines de tokens (les blocs de texte trop longs expriment davantage de sens, c'est-à-dire qu'ils sont trop riches sur le plan sémantique).
- Les segments sont convertis en enregistrements vectoriels qui codent le sens à l'aide d'un modèle d'enregistrement ;
- Stocker ces encastrements dans une base de données vectorielle pour effectuer des recherches par similarité sémantique.
Au moment de l'exécution, lorsque l'utilisateur introduit une requête dans le modèle, la base de données vectorielle trouve le fragment le plus pertinent sur la base de la similarité sémantique de la requête. Le fragment le plus pertinent est alors ajouté à l'invite envoyée au modèle génératif (répondant à la question en tant que contexte de la référence du modèle plus large).
Bien que les modèles d'intégration soient efficaces pour capturer les relations sémantiques, ils peuvent manquer des correspondances exactes critiques. BM25 est une fonction de classement qui trouve des correspondances exactes de mots ou de phrases par le biais de la correspondance lexicale. Elle est particulièrement efficace pour les requêtes contenant des identifiants uniques ou des termes techniques.
BM25 Amélioré sur la base du concept de TF-IDF (Word Frequency-Inverse Document Frequency), qui mesure l'importance d'un mot dans une collection de documents. BM25 empêche les mots communs de dominer les résultats en tenant compte de la longueur du document et en appliquant une fonction de saturation à la fréquence des mots.
Voici comment BM25 fonctionne lorsque l'intégration sémantique échoue : supposons qu'un utilisateur interroge la base de données de l'assistance technique sur le "code d'erreur TS-999". (Le modèle d'intégration (vectoriel) peut trouver un contenu générique sur le code d'erreur, mais ne pas trouver la correspondance exacte "TS-999". Au lieu de cela, BM25 recherche cette chaîne de texte spécifique pour identifier le document pertinent.
En combinant les techniques d'intégration et de BM25, le programme RAG peut retrouver les fragments les plus pertinents avec plus de précision, comme suit :
- La base de connaissances (le "corpus" de documents) est décomposée en éléments de texte plus petits, ne dépassant généralement pas quelques centaines de tokens ;
- Créer des encodages TF-IDF et des encastrements sémantiques (vectoriels) pour ces segments ;
- Utilisez BM25 pour trouver le meilleur fragment sur la base d'une correspondance exacte ;
- Utiliser l'intégration (vectorielle) pour trouver les segments présentant la plus grande similarité sémantique ;
- Les résultats des étapes (3) et (4) sont fusionnés et désévalués à l'aide d'une technique de fusion de tri ; par exemple, le modèle de réorganisation spécialisé Rerank 3.5.
- Ajoutez les K premiers segments à l'invite pour générer une réponse.
En combinant les modèles BM25 et d'intégration, les systèmes RAG traditionnels sont en mesure de trouver un équilibre entre une correspondance précise des termes et une compréhension sémantique plus large, afin de fournir des résultats plus complets et plus précis.

Un système RAG (Retrieval Augmentation Generation) standard qui combine l'incorporation et le Best Match 25 (BM25) pour retrouver des informations. Le TF-IDF (Word Frequency-Inverse Document Frequency) mesure l'importance des mots et constitue la base du BM25.
Cette approche vous permet d'évoluer vers une base de connaissances beaucoup plus importante que celle que peut contenir une seule invite, et ce à moindre coût. Toutefois, ces systèmes RAG traditionnels présentent une limite importante : ils sont souvent hors contexte.
En ce qui concerne la conception raisonnable du système de recherche, il n'a pas encore été question du bloc de texte tronqué, qui doit exprimer le même contenu et ne doit jamais être tronqué, mais du système RAG susmentionné.Inévitablement, le contexte est tronqué. Il s'agit d'un problème à la fois simple et complexe. Venons-en à l'objet de cet article.
Difficultés contextuelles dans le cadre du système RAG traditionnel
Dans les RAG traditionnels, les documents sont souvent divisés en petits morceaux pour une recherche efficace. Cette approche convient à de nombreux scénarios d'application, mais peut poser des problèmes lorsque les morceaux individuels ne sont pas suffisamment contextualisés.
Supposons, par exemple, que vous disposiez d'informations financières intégrées dans votre base de connaissances (par exemple, un rapport de la SEC des États-Unis) et que vous receviez la question suivante :"Quelle est la croissance du chiffre d'affaires d'ACME Corporation au deuxième trimestre 2023 ?
Un bloc connexe peut contenir le texte suivant :"Les revenus de l'entreprise ont augmenté de 3% par rapport au trimestre précédent. Toutefois, le bloc lui-même ne mentionne pas explicitement les entreprises spécifiques ou les périodes concernées, ce qui rend difficile la recherche des informations correctes ou leur utilisation efficace.
Introduction de la recherche contextuelle
La recherche contextuelle est effectuée en ajoutant un bloc spécifique à chaque bloc avant d'incorporer le contenu de la base de données.Contexte interprétatif("Context Embedding") et la création d'un index BM25 ("Context BM25") résolvent ce problème.
Revenons à l'exemple de la collecte des déclarations SEC. Voici un exemple de conversion d'un bloc :
original_chunk = "该公司的收入比上一季度增长了 3%。"
contextualized_chunk = "该块来自一份关于 ACME 公司 2023 年第二季度表现的 SEC 报告;上一季度的收入为 3.14 亿美元。该公司的收入比上一季度增长了 3%。"
Il convient de noter qu'un certain nombre d'autres moyens d'utiliser le contexte pour améliorer la recherche ont été proposés par le passé. D'autres suggestions ont été faites, notammentAjouter un résumé générique à un bloc(Nous avons expérimenté et constaté que le gain était très limité),Intégration de documents hypothétiques répondre en chantant Indexation basée sur les abstractions(Nous l'avons évaluée et avons constaté que ses performances étaient faibles). Ces méthodes sont différentes de celle proposée dans le présent document.
De nombreuses méthodes d'amélioration de la qualité du contexte se sont révélées expérimentalement peu efficaces, et même les méthodes relativement les meilleures mentionnées ci-dessus restent discutables.L'ajout d'un contexte explicatif à ce processus de conversion entraîne une perte plus ou moins importante d'informations..
Même si l'on découpe un paragraphe complet comme un bloc de texte et que l'on ajoute des titres à plusieurs niveaux au contenu du paragraphe complet, ce paragraphe pris isolément et sans tenir compte du contexte peut ne pas transmettre la connaissance avec précision, comme l'exemple ci-dessus l'a fait rêver.
Cette méthode résout efficacement le problème de l'absence de signification isolée causée par le manque de contexte lorsque le contenu d'un bloc de texte existe seul.
Permettre la recherche contextuelle
Bien entendu, l'annotation manuelle du contexte pour des milliers, voire des millions de blocs dans une base de connaissances représente une charge de travail trop importante. Pour permettre la recherche contextuelle, nous nous sommes tournés vers Claude, et nous avons écrit un indice qui demande au modèle de fournir un contexte concis, spécifique à un bloc, basé sur le contexte de l'ensemble du document. Voici comment nous avons utilisé les indices de Claude 3 Haiku pour générer du contexte pour chaque bloc :
<document>
{{WHOLE_DOCUMENT}}
</document>
这是我们希望置于整个文档中的块
<chunk>
{{CHUNK_CONTENT}}
</chunk>
请提供一个简短且简明的上下文,以便将该块置于整个文档的上下文中,从而改进块的搜索检索。仅回答简洁的上下文,不要包含其他内容。
Le texte contextuel généré est généralement de 50 à 100 tokens et est ajouté au bloc avant l'intégration et avant la création de l'index BM25.
Ce cycle de repères doit faire référence au document complet correspondant au bloc de texte (qui ne devrait pas compter plus de 500 pages, n'est-ce pas ?), en tant que cache de repères, afin de générer avec précision le contexte associé au bloc de texte par rapport au document complet. ), en tant que cache de repères, afin de générer avec précision le contexte associé au bloc de texte par rapport au document complet.
Cela repose sur les capacités de mise en cache de Claude, le document complet comme une invite à mettre en cache l'entrée n'a pas besoin de payer à chaque fois, la mise en cache, il suffit de payer une fois, donc le programme pour atteindre les conditions préalables sont les suivantesLe grand modèle permet la mise en cache de documents de longue duréeDes modèles tels que DeepSeek ont des capacités similaires.
Le processus de prétraitement se déroule comme suit dans la pratique :

La recherche contextuelle est une technique de prétraitement qui améliore la précision de la recherche.
Si vous êtes intéressé par l'utilisation de la recherche contextuelle, vous pouvez consulter notre manuel d'utilisation Début.
Réduction du coût de la recherche contextuelle grâce à la mise en cache des indices
La recherche à travers les contextes de Claude peut être réalisée à faible coût grâce à la fonction spéciale de mise en cache des indices que nous avons mentionnée. Avec la mise en cache des indices, il n'est pas nécessaire de transmettre des documents de référence pour chaque bloc. Il suffit de charger le document dans le cache une fois, puis de faire référence au contenu précédemment mis en cache. En supposant 800 tokens par bloc, 8k tokens par document, 50 tokens par instruction contextuelle et 100 tokens par contexte de bloc, le coût de laLe coût unique de la génération d'un bloc contextualisé est de $1,02 par million de tokens document..
méthodologie
Nous avons mené des expériences dans plusieurs domaines de connaissances (base de code, romans, articles ArXiv, articles scientifiques), modèles d'intégration, stratégies de recherche et mesures d'évaluation. Nous avons mené nos expériences dans les domaines suivants Annexe II Des exemples de questions et de réponses utilisées pour chaque domaine sont présentés dans le tableau ci-dessous.
La figure ci-dessous montre la performance moyenne dans tous les domaines de connaissance lors de l'utilisation de la configuration d'intégration la plus performante (Gemini Text 004) et de l'extraction des 20 premiers extraits. Nous avons utilisé 1 moins rappel@20 comme mesure d'évaluation, qui mesure le pourcentage de documents pertinents qui n'ont pas été retrouvés dans les 20 premiers snippets. Les résultats complets peuvent être consultés dans l'annexe. La contextualisation améliore les performances dans toutes les combinaisons de sources intégrées que nous avons évaluées.
l'amélioration des performances
Nos expériences montrent que :
- L'intégration contextuelle a permis de réduire de 35% le taux d'échec de la recherche pour les 20 premiers fragments.(5,7% → 3,7%).
- La combinaison de l'intégration contextuelle et du BM25 contextuel a permis de réduire le taux d'échec de la recherche pour les 20 premiers fragments de 49%(5,7% → 2,9%).

La combinaison de l'intégration contextuelle et du BM25 contextuel a permis de réduire le taux d'échec de la recherche des 20 premiers fragments de 49%.
Considérations relatives à la mise en œuvre
Les points suivants doivent être gardés à l'esprit lors de la mise en œuvre de la recherche contextuelle :
- Limites des fragments : Réfléchissez à la manière dont le document sera divisé en fragments. Le choix de la taille des fragments, des limites et du chevauchement peut affecter les performances de recherche ^1^.
- Intégrer des modèles : Si la recherche contextuelle améliore les performances de tous les modèles d'intégration que nous avons testés, certains modèles peuvent en bénéficier davantage. Nous avons constaté que Gémeaux répondre en chantant Voyage L'intégration est particulièrement efficace.
- Indices contextuels personnalisés : Bien que les messages génériques que nous fournissons fonctionnent bien, de meilleurs résultats peuvent être obtenus en personnalisant les messages pour des domaines ou des cas d'utilisation spécifiques (par exemple, en incluant un glossaire de termes clés qui peuvent être définis dans d'autres documents de la base de connaissances).
- Nombre de clips : L'ajout de fragments à la fenêtre contextuelle peut améliorer les chances d'inclure des informations pertinentes. Cependant, une trop grande quantité d'informations peut distraire le modèle, c'est pourquoi le nombre doit être contrôlé. Nous avons essayé 5, 10 et 20 fragments et avons constaté que l'utilisation de 20 fragments était la plus performante avec ces options (voir l'annexe pour plus de détails), mais cela vaut la peine d'expérimenter en fonction de votre cas d'utilisation.
Il faut toujours procéder à des évaluations : La génération de réponses peut être améliorée en transmettant des extraits contextualisés et en faisant la distinction entre le contexte et les extraits.
Utiliser le réordonnancement pour améliorer les performances
Dans la dernière étape, nous pouvons combiner la recherche contextuelle avec une autre technique pour améliorer encore les performances. Dans la méthode traditionnelle RAG (Retrieval-Augmented Generation), le système d'IA recherche dans sa base de connaissances des éléments d'information potentiellement pertinents. Pour les grandes bases de connaissances, la recherche initiale renvoie généralement un grand nombre de fragments - parfois jusqu'à des centaines - dont la pertinence et l'importance varient.
La réorganisation est une technique de filtrage courante qui garantit que seuls les éléments les plus pertinents sont transmis au modèle. La réorganisation permet d'obtenir une meilleure réponse tout en réduisant les coûts et le temps de latence, car le modèle traite moins d'informations. Les étapes clés sont les suivantes :
- Une première recherche a été effectuée pour obtenir les segments les plus pertinents (nous avons utilisé les 150 premiers) ;
- Transmettre les N premiers segments et la requête de l'utilisateur au modèle de réorganisation ;
- Un modèle de réorganisation a été utilisé pour évaluer chaque clip en fonction de sa pertinence et de son importance par rapport au repère, puis les K meilleurs clips ont été sélectionnés (nous avons utilisé les 20 premiers) ;
- Les K premiers segments sont transmis au modèle en tant que contexte pour générer le résultat final.
 La combinaison de la recherche contextuelle et de la réorganisation maximise la précision de la recherche.
La combinaison de la recherche contextuelle et de la réorganisation maximise la précision de la recherche.
l'amélioration des performances
Il existe différents modèles de réapprovisionnement sur le marché. Nous utilisons le modèle Reorder Cohere Effectue le test. voyage Un réaménageur est également fournimais nous n'avons pas eu le temps de le tester. Nos expériences montrent que l'ajout d'une étape de réorganisation peut optimiser la recherche dans divers domaines.
Plus précisément, nous constatons que la réorganisation des enchâssements contextuels et du BM25 réduit le taux d'échec de la recherche des 20 premiers fragments de 671 TP3T (5,71 TP3T → 1,91 TP3T).
 La réorganisation des enchâssements contextuels et des BM25 a permis de réduire de 67% le taux d'échec de l'extraction des 20 premiers fragments.
La réorganisation des enchâssements contextuels et des BM25 a permis de réduire de 67% le taux d'échec de l'extraction des 20 premiers fragments.
Considérations relatives aux coûts et aux délais
Une considération importante pour le réordonnancement est l'impact sur la latence et le coût, en particulier lorsqu'il s'agit de réordonner un grand nombre de fragments. Étant donné que le réordonnancement ajoute une étape supplémentaire au moment de l'exécution, il ajoute inévitablement un certain temps de latence, même si le réordonnateur est parallélisé pour évaluer tous les fragments. Il existe un compromis entre le réordonnancement d'un plus grand nombre de fragments pour de meilleures performances et le réordonnancement d'un moins grand nombre de fragments pour une latence et un coût moindres. Nous vous recommandons d'expérimenter différents paramètres pour votre cas d'utilisation spécifique afin de trouver l'équilibre optimal.
rendre un verdict
Nous avons effectué un certain nombre de tests comparant différentes combinaisons de toutes les techniques susmentionnées (modèles d'intégration, utilisation de BM25, utilisation de la recherche contextuelle, utilisation des réordonnateurs et nombre de K premiers résultats récupérés) et mené des expériences sur divers types d'ensembles de données. Voici un résumé de nos conclusions :
- L'incorporation + BM25 est plus efficace que l'incorporation seule ;
- Voyage et Gémeaux est le modèle d'intégration qui a donné les meilleurs résultats lors de nos tests ;
- Il est plus efficace de transmettre les 20 premiers segments au modèle que de ne transmettre que les 10 ou 5 premiers ;
- L'ajout d'un contexte aux segments améliore considérablement la précision de la recherche ;
- Il vaut mieux réorganiser que ne pas réorganiser ;
- Tous ces avantages sont cumulables : Pour optimiser les performances, nous pouvons combiner l'intégration contextuelle (à partir de Voyage ou Gemini), le BM25 contextuel, la réorganisation des étapes et l'ajout de 20 extraits à l'invite.
Nous encourageons tous les développeurs qui utilisent la base de connaissances à utiliser l'option Notre manuel pratique Expérimentez ces méthodes pour atteindre de nouveaux niveaux de performance.
Annexe I
Vous trouverez ci-dessous une ventilation des résultats de Retrievals @ 20 en fonction des ensembles de données, des fournisseurs intégrés, de BM25 utilisé conjointement avec l'intégration, de l'utilisation de la recherche contextuelle et de l'utilisation de la réorganisation.
Pour une ventilation des recherches @ 10 et @ 5 et des exemples de questions et de réponses pour chaque ensemble de données, voir Annexe II.
 1 moins le rappel @ 20 pour l'ensemble de données et les résultats des fournisseurs intégrés.
1 moins le rappel @ 20 pour l'ensemble de données et les résultats des fournisseurs intégrés.
notes de bas de page
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes



Pas de commentaires...