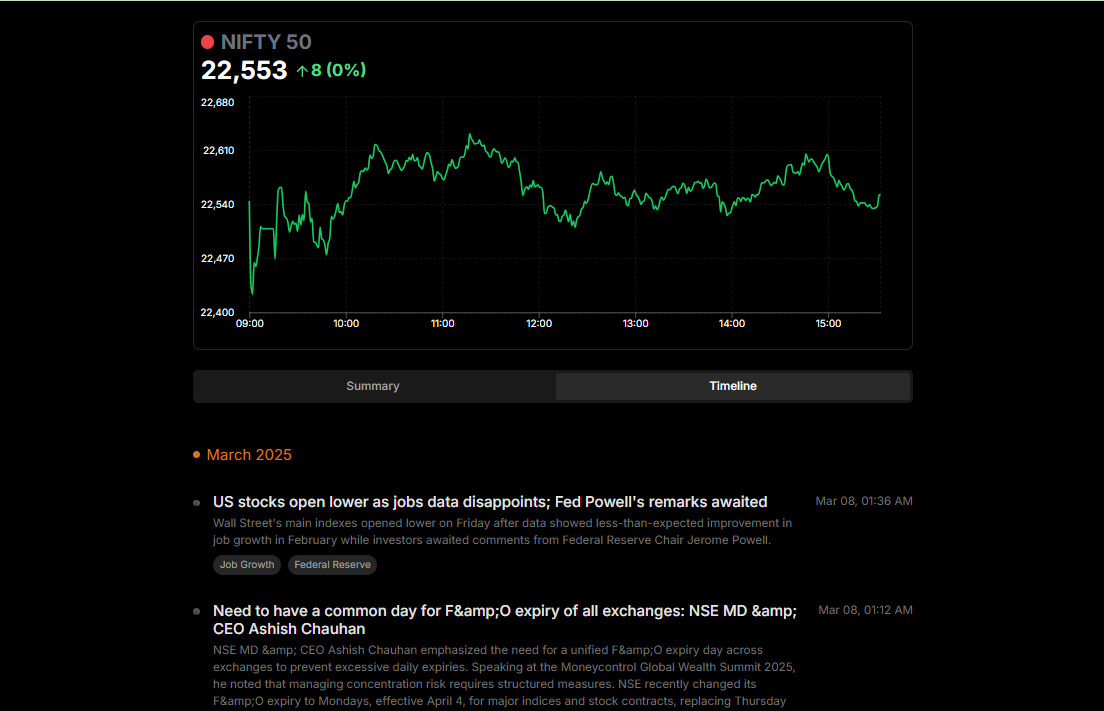
Flying Paddle PP-TableMagic : Extraction d'informations structurées pour les tableaux complexes

L'objectif de la reconnaissance de tableaux est d'analyser les tableaux dans les images, d'identifier avec précision les structures des tableaux et l'emplacement des cellules, et de les réduire à des formats de tableaux structurés (par exemple, HTML). À l'ère de l'information, un grand nombre de données de tableaux importantes existent encore à l'état non structuré (par exemple, des images de tableaux de statistiques d'information dans des documents scannés, des tableaux de statistiques de données dans des états financiers au format PDF, etc. C'est pourquoi la reconnaissance des formes est devenue une technologie clé dans les scénarios d'application de la compréhension intelligente des documents et de l'analyse automatique des données. Les solutions de reconnaissance de formulaires hautement performantes ont une valeur d'application importante dans les domaines du traitement des états financiers, de l'analyse des données de la recherche scientifique, de la comptabilité des réclamations d'assurance, etc. Toutefois, face à la complexité des formats de formulaires dans différents scénarios d'application, les modèles traditionnels de reconnaissance de formulaires à usage général sont souvent difficiles à adapter. C'est pourquoi Flying Paddle a lancé une nouvelle solution de reconnaissance de tableaux, PP-TableMagic.

PP-TableEffet magique




PP-TableMagic Analyse technique
Déficiences de la technologie actuelle
Actuellement, les solutions courantes de reconnaissance de tableaux adoptent généralement le cadre suivant : l'utilisateur saisit une image de tableau et le modèle prédit à la fois la structure HTML et la position des cellules du tableau dans l'image, puis la réduit à un tableau HTML complet. Cette solution permet d'obtenir de bonnes performances de prédiction dans des scénarios de tableaux simples et courants, mais souffre de deux problèmes :
- Le nombre de paramètres du modèle de reconnaissance des tableaux est généralement faible, et les deux tâches, la prédiction de la structure du tableau et la prédiction de la position des cellules, ont des objectifs très différents et des hiérarchies sémantiques de caractéristiques dépendantes, et il existe une limite supérieure de performance pour l'optimisation conjointe.
- Lorsque les utilisateurs affinent le modèle dans un scénario particulier, l'affinement de certains types de données tabulaires peut entraîner un "double creux" dans les performances du modèle, c'est-à-dire que les performances des catégories tabulaires affinées augmentent, mais que les performances d'autres catégories diminuent, et que les performances globales peuvent diminuer au lieu d'augmenter.

PP-TableMagic Solutions et principes techniques
Afin de tirer pleinement parti des performances du modèle léger de reconnaissance des tableaux et de permettre à l'utilisateur d'affiner tout type de données de tableau, PP-TableMagic adopte la structure décrite dans la figure ci-dessous :

PP-TableMagic adopte une architecture à double flux pour diviser les tableaux en tableaux câblés et sans fil. Ensuite, la tâche de reconnaissance des tables de bout en bout est divisée en deux sous-tâches : la détection des cellules et la reconnaissance de la structure des tables. Enfin, le résultat complet de la prédiction des tables HTML est obtenu par l'algorithme de fusion des résultats auto-optimisants. Spécifiquement :
- L'équipe de Flying Paddle étudie son propre modèle de classification des tables légères PP-LCNet_x1_0_table_cls afin d'obtenir une classification très précise des tables avec ou sans fil.
- L'équipe R&D a lancé le premier modèle open source de détection de cellules de table RT-DETR-L_table_cell_det, qui comprend des poids de pré-entraînement pour la détection de cellules de table câblées RT-DETR-L_wired_table_cell_det et des poids de pré-entraînement pour la détection de cellules de table sans fil RT-DETR-L_wireless_table afin d'obtenir un positionnement précis des différents types de cellules de table.
- Flying Paddle introduit un nouveau modèle de reconnaissance des structures de tableaux, SLANeXt, qui permet une meilleure analyse des structures de tableaux que SLANet et SLANet_plus, ce qui se traduit par des structures HTML de tableaux plus précises.
Dans le cadre de PP-TableMagic, SLANeXt, un nouveau modèle de reconnaissance de la structure des tableaux développé par FeiPaddle, est particulièrement important. La reconnaissance de la structure des tableaux est l'aspect le plus critique de la reconnaissance des tableaux, et la prédiction des images de tableaux en expressions HTML repose sur des caractéristiques de haut niveau dans les images. Par conséquent, SLANeXt utilise Vary-ViT-B, qui est plus apte à représenter les caractéristiques, comme codeur visuel et introduit les caractéristiques extraites dans SLAHead pour obtenir une reconnaissance de structure plus précise. Outre l'amélioration de la structure du modèle, la stratégie de formation a également été améliorée. Sur la base de l'ensemble de données en volume complet auto-construit de Flying Paddle et de l'ensemble de données de haute qualité finement ajusté, les poids de reconnaissance de la structure de la table câblée et de la table sans fil sont obtenus respectivement par une nouvelle stratégie de pré-entraînement en trois étapes.
Afin d'évaluer la capacité de reconnaissance de formes de SLANeXt, l'équipe de R&D a effectué un certain nombre de tests basés sur différents types d'ensembles de données. Les résultats de ces expériences sont les suivants :
Sur la base d'un ensemble d'examens internes de haut niveau sur la reconnaissance des formes :

Basé sur les données commerciales réelles des partenaires :

Les résultats expérimentaux montrent que SLANeXt améliore considérablement les performances par rapport à SLANet_plus.
Applications algorithmiques
Lorsque vous utilisez PP-TableMagic, vous pouvez non seulement tirer parti de ses excellentes capacités de prédiction de tableaux HTML pour travailler directement avec des tableaux, mais vous pouvez également tirer pleinement parti de sa structure pour permettre l'affinement personnalisé du modèle.
Lorsqu'il s'agit d'affiner d'autres modèles de reconnaissance de formulaires de bout en bout pour les mauvais cas, il est souvent difficile de constituer de grands ensembles d'entraînement lorsque seul ce type de données peut être collecté, ce qui entraîne un phénomène de "l'un contre l'autre" où les performances du modèle diminuent plutôt qu'elles n'augmentent.

En outre, le réglage fin du modèle de reconnaissance des tableaux de bout en bout nécessite l'annotation simultanée de la structure du tableau et des positions des cellules dans les données d'apprentissage, ce qui prend beaucoup de temps et demande beaucoup de travail dans la plupart des scénarios d'application.
Grâce à l'architecture du réseau multi-modèle de PP-TableMagic, lorsqu'il est nécessaire d'améliorer les performances d'un certain type de tableau, seul le ou les modèles les plus critiques doivent être affinés, ce qui minimise l'impact sur les performances de reconnaissance des autres types de tableaux.

Par conséquent, lorsque PP-TableMagic est affiné dans des scénarios réels, non seulement les performances de reconnaissance de chaque type de tableau ont peu d'influence les unes sur les autres, mais l'annotation des données n'a besoin que d'être étiquetée avec la catégorie correspondante, ce qui permet d'économiser beaucoup de main-d'œuvre.
Pour les développeurs ayant de solides compétences en matière de codage, l'architecture de PP-TableMagic peut être ajustée directement au niveau de la branche. Comme le montre la figure ci-dessous, lorsqu'un certain type de données de tableau est jugé très important, une branche distincte peut être mise en place pour le traitement, ce qui peut améliorer considérablement la capacité globale de reconnaissance des tableaux.

PP-TableMagic offre d'excellentes performances et permet une personnalisation poussée ainsi qu'un degré élevé de liberté dans l'ajustement du modèle ciblé afin d'obtenir les meilleures performances en matière de reconnaissance de tables dans divers scénarios d'application. Il s'agit de la première solution open-source pour la reconnaissance de tables qui permet une personnalisation poussée dans tous les scénarios.
Pour commencer
montage
Installer PaddlePaddle :
# CPU 版本
python -m pip install paddlepaddle==3.0.0rc0 -i https://www.paddlepaddle.org.cn/packages/stable/cpu/
# GPU 版本,需显卡驱动程序版本 ≥450.80.02(Linux)或 ≥452.39(Windows)
python -m pip install paddlepaddle-gpu==3.0.0rc0 -i https://www.paddlepaddle.org.cn/packages/stable/cu118/
# GPU 版本,需显卡驱动程序版本 ≥545.23.06(Linux)或 ≥545.84(Windows)
python -m pip install paddlepaddle-gpu==3.0.0rc0 -i https://www.paddlepaddle.org.cn/packages/stable/cu123/
Installer l'ensemble PaddleX Wheel :
pip install https://paddle-model-ecology.bj.bcebos.com/paddlex/whl/paddlex-3.0.0rc0-py3-none-any.whl
Expérience rapide
PP-TableMagic peut être appelé directement.
PaddleX fournit une API Python facile à utiliser pour expérimenter les prédictions des modèles avec seulement quelques lignes de code.
Télécharger les images test :
https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/table_recognition_v2.jpg
PaddleX permet d'appeler PP-TableMagic à partir de la ligne de commande ou de scripts Python (représentés dans PaddleX par la ligne de sortie table_recognition_v2).
Méthode de la ligne de commande :
paddlex --pipeline table_recognition_v2
--use_doc_orientation_classify=False
--use_doc_unwarping=False
--input table_recognition.jpg
--save_path ./output
--device gpu:0
Méthode de script Python :
from paddlex import create_pipeline
pipeline = create_pipeline(pipeline="table_recognition_v2")
output = pipeline.predict(
input="table_recognition.jpg",
use_doc_orientation_classify=False,
use_doc_unwarping=False,
)
for res in output:
res.print()
res.save_to_img("./output/")
res.save_to_xlsx("./output/")
res.save_to_html("./output/")
res.save_to_json("./output/")
Après utilisation, les résultats de la reconnaissance seront enregistrés sous le chemin spécifié.
développement secondaire
Si vous êtes satisfait de l'effet de PP-TableMagic, vous pouvez directement effectuer un raisonnement de haute performance, un déploiement de services ou un déploiement côté final sur la ligne de production. Si le scénario de la table est particulièrement vertical et qu'il y a encore de la place pour l'optimisation, vous pouvez également utiliser PaddleX pour effectuer un développement secondaire ciblé d'un ou de plusieurs modèles dans PP-TableMagic sur la base des données de votre propre scénario, en tirant pleinement parti des avantages de la mise au point personnalisée de PP-TableMagic. Grâce à la capacité de développement secondaire de PaddleX, la vérification des données, l'entraînement du modèle et l'inférence de l'évaluation peuvent être réalisés à l'aide de commandes unifiées, sans qu'il soit nécessaire de comprendre les principes sous-jacents de l'apprentissage profond, de préparer les données de la scène en fonction des exigences et d'exécuter simplement les commandes pour compléter l'itération du modèle. Nous présentons ici le processus de développement secondaire du modèle de détection de cellules de table sans fil RT-DETR-L_wireless_table_cell_det :
python main.py -c paddlex/configs/modules/table_cells_detection/RT-DETR-L_wireless_table_cell_det.yaml
-o Global.mode=train
-o Global.dataset_dir=./path_to_your_datasets
Tous les autres modèles prennent en charge le développement secondaire, veuillez vous référer aux détails :
https://github.com/PaddlePaddle/PaddleX/blob/release/3.0-rc/docs/pipeline_usage/tutorials/ocr_pipelines/table_recognition_v2.md#4-%E4%BA%8C%E6%AC%A1%E5%BC%80%E5%8F%91
Déploiement orienté services
PaddleX fournit également une capacité de déploiement pour PP-TableMagic, en encapsulant les capacités de raisonnement de la reconnaissance des tables sous forme de services et en permettant aux clients d'accéder à ces services par le biais de requêtes web pour les résultats du raisonnement des tables.
PaddleX propose deux types de déploiement de servitisation : le déploiement de servitisation de base et le déploiement de servitisation à haute stabilité. Le déploiement de servitisation de base est une solution de déploiement de servitisation simple et facile à utiliser, avec de faibles coûts de développement, qui permet aux utilisateurs de déployer et de déboguer rapidement les résultats. Le déploiement assisté à haute stabilité est basé sur le serveur d'inférence NVIDIA Triton, qui offre une plus grande stabilité et permet de meilleures performances.
Pour plus d'informations sur PP-TableMagic, voir la documentation officielle de la ligne de production PaddleX :
https://github.com/PaddlePaddle/PaddleX/blob/release/3.0-rc/docs/pipeline_usage/tutorials/ocr_pipelines/table_recognition_v2.md
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...