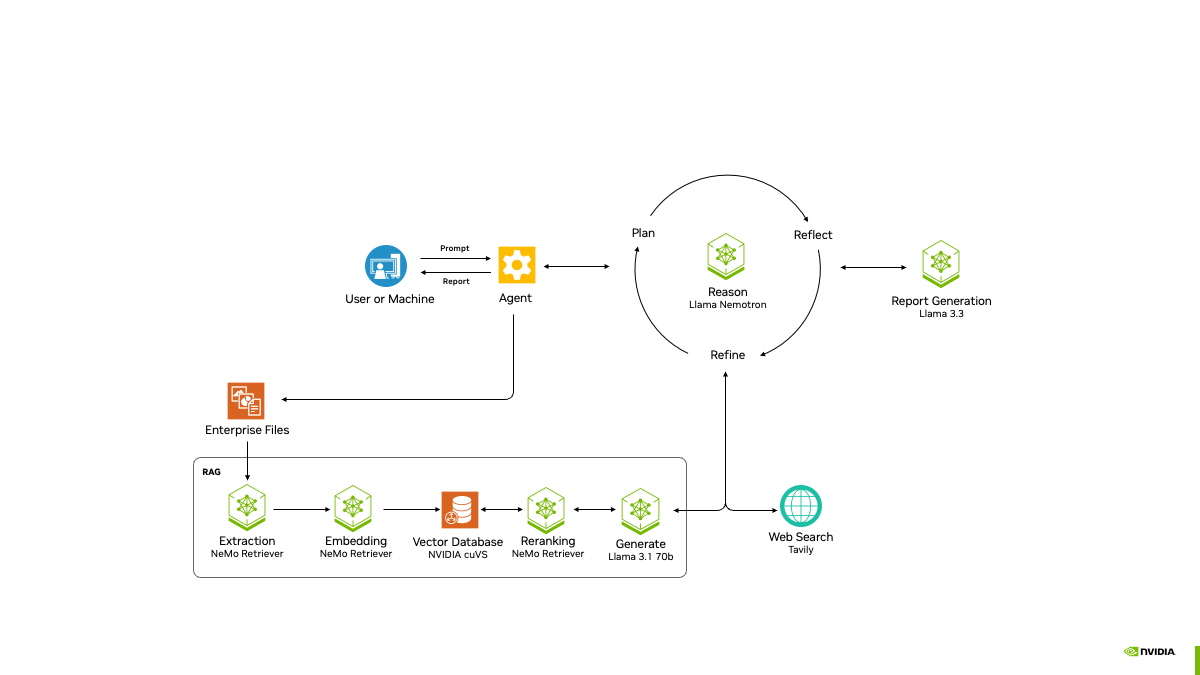
OpenSearch-SQL : un outil open source pour transformer le langage naturel en requêtes SQL

Introduction générale
OpenSearch-SQL est un projet open source qui est un puissant outil Text-to-SQL qui transforme les descriptions en langage naturel d'un utilisateur en instructions de requête SQL, aidant ainsi les personnes qui ne sont pas familières avec les bases de données à accéder facilement aux données. Le projet est développé par l'équipe OpenSearch-AI et est gratuit et ouvert sur la base de la licence Apache 2.0. En août 2024, il a remporté la première place dans les benchmarks BIRD, avec une précision de 69,3% pour l'ensemble de validation et 72,28% pour l'ensemble de test.OpenSearch-SQL peut fonctionner sans formation supplémentaire et prend en charge des modèles tels que GPT OpenSearch-SQL fonctionne sans formation supplémentaire et prend en charge des modèles tels que GPT, DeepSeek, etc. Il convient à l'analyse de données et à l'interrogation de bases de données.

Liste des fonctions
- Convertir des questions en langage naturel en requêtes SQL, telles que "Quel est le plus grand bâtiment ?
SELECT building_name FROM buildings ORDER BY height DESC LIMIT 1. - Méthodologie d'amélioration CoT (Chain of Thought) qui favorise l'auto-apprentissage afin d'améliorer la précision de la génération de requêtes.
- Fournit un langage intermédiaire de type SQL pour optimiser la génération de SQL complexes.
- Inclut l'alignement des entrées-sorties pour réduire les erreurs dans la génération du modèle (problèmes illusoires).
- Il prend en charge cinq modules : prétraitement, extraction, génération, optimisation et alignement, couvrant l'ensemble du processus d'interrogation.
- Open source et gratuit, les utilisateurs peuvent modifier le code selon leurs besoins ou l'intégrer dans leurs propres projets.
Utiliser l'aide
OpenSearch-SQL est un outil en ligne de commande qui doit être installé et configuré pour fonctionner. Vous trouverez ci-dessous les étapes détaillées pour vous aider à démarrer à partir de zéro.
Processus d'installation
- Préparation de l'environnement Python
Assurez-vous que Python 3.8 ou plus est installé sur votre ordinateur. Cela peut être fait en tapantpython --versionVérifiez. Si ce n'est pas le cas, téléchargez et installez le logiciel depuis le site officiel de Python (https://www.python.org/). - Télécharger les fichiers du projet
Ouvrez votre navigateur et allez sur https://github.com/OpenSearch-AI/OpenSearch-SQL. Cliquez sur le bouton "Code" dans le coin supérieur droit et sélectionnez "Download ZIP "et sélectionnez "Télécharger ZIP" pour télécharger le code source, ou le cloner avec la commande Git :
git clone https://github.com/OpenSearch-AI/OpenSearch-SQL.git
Téléchargez et décompressez le fichier localement, par exemple C:\OpenSearch-SQL peut-être /home/user/OpenSearch-SQL.
- Installation des dépendances
Allez dans le dossier du projet, ouvrez un terminal et exécutez la commande suivante pour installer les bibliothèques requises :
pip install -r requirements.txt
Cette opération permet d'installer les paquets Python nécessaires à l'exécution du projet, tels que les bibliothèques pour le traitement des données et l'appel des modèles.
Prétraitement des données
OpenSearch-SQL a besoin d'exemples peu nombreux pour améliorer la précision des requêtes. Les données peuvent être générées à l'aide du script officiel fourni.
- Préparer les données
Le projet fournit un fichier d'exemplebird_dev.jsonSitué àBird/bird_dev.jsonIl est basé sur la méthodologie DAIL-SQL. Il est généré sur la base de la méthodologie DAIL-SQL et contient quelques exemples de requêtes. Si vous disposez de vos propres données, vous pouvez remplacer ce fichier. - Exécution de scripts de prétraitement
Exécutez-le dans le répertoire racine du projet :
sh run/run_preprocess.sh
Ce script traite les données de quelques clichés, les structures des tableaux et d'autres informations. Lorsqu'il est terminé, le terminal affiche la sortie pour chaque répertoire. Si vous êtes un utilisateur Windows, vous pouvez l'exécuter avec Git Bash ou WSL, ou exécuter les commandes du script manuellement.
Exécuter le programme principal
- procédure de déclenchement
Exécutez-le dans le répertoire racine du projet :
sh run/run_main.sh
Ceci appellera le src/runner/database_manager.py pour lancer le traitement de la requête. Le chemin d'accès au programme est défini dans le script.
- Vérifier la sortie
Après l'exécution de l'application principale, celle-ci génère des résultats de requêtes SQL en fonction de la configuration. Le chemin d'accès au fichier de sortie se trouve dans le répertoiresrc/runner/database_manager.py(utilisé comme expression nominale)_set_pathsdéfinie dans la fonction, qui peut être ajustée selon les besoins.
Fonction en vedette Fonctionnement
- Langage naturel vers SQL
Saisissez une question telle que "Quelle est la ville où les ventes sont les plus élevées ?". Le programme la génère :
SELECT city FROM sales ORDER BY amount DESC LIMIT 1
Vous trouverez plus d'informations à ce sujet dans le questions.json Ajoutez vos propres questions au fichier et exécutez-le pour voir les résultats.
- Amélioration du CdT
Le projet fournit des exemples au format Query-CoT-SQL. Par exemple : - Entrée utilisateur : "Quel est l'âge moyen ?"
- Processus CoT : trouver d'abord la colonne des âges, puis calculer la moyenne.
- Sortie :
SELECT AVG(age) FROM users. - fonction d'alignement
Si les résultats sont générés de manière incorrecte, le programme les corrigera automatiquement. Par exemple, si vous entrez "Liste de toutes les notes des étudiants" mais que la base de données comporte plusieurs tables, le programme s'assurera que l'opération JOIN est correcte :
SELECT s.name, sc.score FROM students s JOIN scores sc ON s.id = sc.student_id
mise en garde
- Si vous devez tester l'ensemble de données BIRD, vous pouvez le faire directement à l'aide de la commande
Bird/fewshot/questions.jsonDocumentation. - Le programme prend en charge plusieurs modèles et peut nécessiter une clé API pour la configuration par défaut. Si vous utilisez GPT ou DeepSeek, la clé doit être définie dans le code.
Grâce à ces étapes, vous pouvez facilement transformer le langage naturel en requêtes SQL pour traiter une variété de tâches d'analyse de données.
scénario d'application
- l'analyse des données
Les analystes de données peuvent l'utiliser pour transformer des questions en langage SQL et compter rapidement les données de vente ou le comportement des utilisateurs. - Éducation et formation
Les étudiants peuvent l'utiliser pour apprendre le langage SQL en saisissant des questions et en comparant les requêtes générées. - Rapports automatisés
Les entreprises peuvent l'utiliser pour générer automatiquement des rapports SQL et réduire le temps de rédaction manuelle.
QA
- OpenSearch-SQL nécessite-t-il une connexion Internet ?
Si vous utilisez un modèle local, aucune mise en réseau n'est nécessaire. En revanche, une mise en réseau et des clés API sont nécessaires lors de l'utilisation de modèles en ligne tels que GPT. - Quelles sont les bases de données prises en charge ?
Il s'adresse à toute base de données compatible avec SQL, pour autant que la structure du tableau et les données soient fournies. - BIRD Qu'est-ce que cela signifie d'être numéro un sur la liste ?
Il montre qu'il a la plus grande précision dans les tâches de conversion de texte en SQL et qu'il peut traiter des requêtes complexes, avec un score de 72,28% en août 2024 pour l'ensemble de test.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...