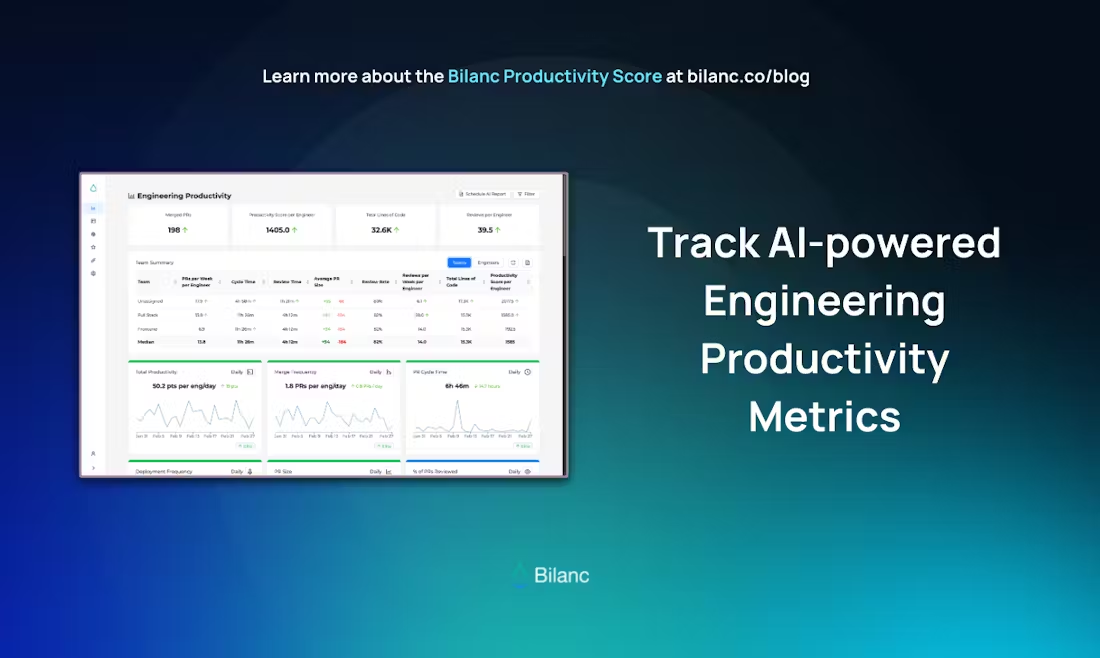
Open-Reasoner-Zero : Plate-forme de formation à l'apprentissage par renforcement du raisonnement à grande échelle (Open Source Large-Scale Reasoning Reinforcement Learning)

Introduction générale
Open-Reasoner-Zero est un projet open source axé sur la recherche en apprentissage par renforcement (RL), développé par l'équipe Open-Reasoner-Zero sur GitHub. Il vise à accélérer le processus de recherche dans le domaine de l'intelligence artificielle (IA), en particulier l'exploration vers l'intelligence artificielle générale (AGI), en fournissant un cadre d'entraînement efficace, évolutif et facile à utiliser. Le projet est basé sur le modèle Qwen2.5 (versions à 7 et 32 paramètres) et combine des technologies telles que OpenRLHF, vLLM, DeepSpeed et Ray pour fournir un code source complet, des données d'entraînement et des poids de modèle. Il se distingue par le fait qu'il atteint un niveau de performance similaire en moins de 1/30e des étapes d'entraînement de DeepSeek-R1-Zero, ce qui démontre son efficacité en matière d'utilisation des ressources. Le projet est placé sous licence MIT et peut être utilisé et modifié gratuitement par les utilisateurs, ce qui en fait un outil idéal pour la collaboration entre chercheurs et développeurs.

Liste des fonctions
- Formation intensive efficaceLa formation et la génération sont prises en charge par un seul contrôleur, ce qui permet de maximiser l'utilisation du GPU.
- une ressource complète en libre accèsLe modèle est un outil simple et facile à utiliser qui fournit 57 000 données d'entraînement de haute qualité, le code source, les paramètres et les poids du modèle.
- Support de modèles de haute performanceBasé sur Qwen2.5-7B et Qwen2.5-32B, il offre d'excellentes performances en matière d'inférence.
- Un cadre de recherche flexibleLa conception modulaire permet aux chercheurs d'adapter et d'étendre facilement leurs expériences.
- Support DockerFournir un fichier Docker pour assurer la reproductibilité de l'environnement de formation.
- Outils d'évaluation des performancesLe site contient des données d'étalonnage et des présentations de résultats d'évaluation, telles que des comparaisons de performances pour le GPQA Diamond.
Utiliser l'aide
Processus d'installation
L'utilisation d'Open-Reasoner-Zero requiert un certain niveau de connaissances techniques. Vous trouverez ci-dessous un guide détaillé d'installation et d'utilisation, adapté à Linux ou aux systèmes de type Unix.
Préparation de l'environnement
- Installation des dépendances de base: :
- Assurez-vous que Git, Python 3.8+ et le pilote GPU NVIDIA (la prise en charge de CUDA est requise) sont installés sur votre système.
- Installer Docker (version recommandée 20.10 ou supérieure) pour un déploiement rapide de l'environnement de formation.
sudo apt update sudo apt install git python3-pip docker.io
- Clonage de l'entrepôt de projets: :
- Exécutez la commande suivante dans le terminal pour télécharger le projet localement :
git clone https://github.com/Open-Reasoner-Zero/Open-Reasoner-Zero.git cd Open-Reasoner-Zero - Configurer votre environnement avec Docker: :
- Le projet fournit un fichier Docker pour faciliter la construction d'environnements de formation.
- Exécutez-le dans le répertoire racine du projet :
docker build -t open-reasoner-zero -f docker/Dockerfile .- Une fois la construction terminée, démarrez le conteneur :
docker run -it --gpus all open-reasoner-zero bash- Cela permet d'entrer dans un environnement de conteneur avec support GPU, préinstallé avec les dépendances nécessaires.
- Installation manuelle des dépendances (facultatif): :
- Si vous n'utilisez pas Docker, vous pouvez installer les dépendances manuellement :
pip install -r requirements.txt- Assurez-vous que OpenRLHF, vLLM, DeepSpeed et Ray sont installés, reportez-vous à la documentation du projet pour les versions spécifiques.
Fonction Opération Déroulement
1. les modèles de formation
- Préparer les données d'entraînement: :
- Le projet est accompagné de 57 000 données de formation de haute qualité, situées dans la base de données des
datadossier. - Si des données personnalisées sont requises, organisez le format conformément aux instructions de la documentation et remplacez-le.
- Le projet est accompagné de 57 000 données de formation de haute qualité, situées dans la base de données des
- formation d'amorçage: :
- Exécutez la commande suivante dans le conteneur ou dans l'environnement local :
python train.py --model Qwen2.5-7B --data-path ./data- Paramètre Description :
--modelSélectionnez le modèle (par exemple Qwen2.5-7B ou Qwen2.5-32B).--data-path: Spécifie le chemin d'accès aux données d'apprentissage.
- Le journal de formation est affiché sur le terminal du nœud maître pour faciliter le suivi des progrès.
2. l'évaluation des performances
- Exécution de tests de référence: :
- Comparez les performances du modèle à l'aide des scripts d'évaluation fournis :
python evaluate.py --model Qwen2.5-32B --benchmark gpqa_diamond- Le résultat montrera la précision du modèle sur des critères de référence tels que GPQA Diamond.
- Voir le rapport d'évaluation: :
- Le projet contient des graphiques (par exemple, la figure 1 et la figure 2) montrant l'échelonnement des performances et du temps d'entraînement, qui peuvent être consultés dans la section
docspour le trouver.
- Le projet contient des graphiques (par exemple, la figure 1 et la figure 2) montrant l'échelonnement des performances et du temps d'entraînement, qui peuvent être consultés dans la section
3) Modifications et extensions
- Paramètres de réglage: :
- compilateur
config.yamlen modifiant les hyperparamètres tels que le taux d'apprentissage, la taille du lot, etc.
learning_rate: 0.0001 batch_size: 16 - compilateur
- Ajouter une nouvelle fonctionnalité: :
- Le projet est conçu de manière modulaire et peut être
srcpour ajouter de nouveaux modules. Par exemple, ajouter un nouveau script de prétraitement des données :
# custom_preprocess.py def preprocess_data(input_file): # 自定义逻辑 pass - Le projet est conçu de manière modulaire et peut être
Précautions de manipulation
- exigences en matière de matérielPour la formation Qwen2.5-32B, il est recommandé d'utiliser un GPU doté d'au moins 24 Go de mémoire vidéo (par exemple, NVIDIA A100).
- Surveillance des journauxLe terminal doit rester allumé pendant la formation et consulter le journal à tout moment pour résoudre les problèmes.
- Soutien communautaireLes questions peuvent être soumises via GitHub Issues ou en contactant l'équipe à l'adresse hanqer@stepfun.com.
Exemples pratiques
Supposons que vous souhaitiez former un modèle basé sur Qwen2.5-7B :
- Entrez dans le conteneur Docker.
- être en mouvement
python train.py --model Qwen2.5-7B --data-path ./data. - Attendre quelques heures (en fonction du matériel) et lancer le programme une fois terminé.
python evaluate.py --model Qwen2.5-7B --benchmark gpqa_diamond. - Affichez le résultat pour confirmer l'amélioration des performances.
Grâce à ces étapes, les utilisateurs peuvent rapidement commencer à utiliser Open-Reasoner-Zero, que ce soit pour reproduire une expérience ou pour développer de nouvelles fonctionnalités, et ce de manière efficace.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...