OneFlow Yearly Deal : ebook gratuit de 900 pages "Generative AI and Big Models" (IA générative et grands modèles)

Il est difficile d'imaginer les changements étonnants qui auraient eu lieu dans le domaine de l'IA en 2024 si la loi d'échelle n'avait pas ralenti, mais on peut aussi se réjouir que ce ralentissement de la loi d'échelle permette aux nouveaux venus dans le secteur de rattraper leur retard et à un plus grand nombre de personnes ordinaires de profiter de ce cycle de révolution technologique.
Les changements dans le domaine de l'IA sont très importants. Il y a un an, la communauté de l'IA pensait généralement que la plupart des modèles étaient à une demi-année ou à une année des modèles de l'OpenAI, mais le pré-entraînement des grands modèles devient progressivement moins secret et sa barrière à l'entrée diminue de plusieurs ordres de grandeur. À la grande surprise de la communauté technologique nationale et internationale, l'écart entre les grands modèles open source représentés par DeepSeek et Qwen et le grand modèle fermé GPT 4o s'est considérablement réduit, et les deux modèles proviennent d'équipes d'IA chinoises. Parallèlement, alors que les performances de pré-entraînement des grands modèles plafonnent, l'inférence est considérée comme la "deuxième courbe de croissance" pour l'amélioration continue de la capacité des modèles, et la popularisation de la technologie de l'IA s'accélère encore, permettant aux gens de développer efficacement une application d'IA générative en accédant simplement à des API standardisées, ou simplement en profitant des avantages de la technologie de l'IA. produits intéressants publiés par les explorateurs de produits.
En 2024, OneFlow a publié 80 articles de qualité, comme toujours, documentant et explorant les nombreux changements dans le domaine de l'IA générative et des grands modèles. À la fin de l'année, nous avons sélectionné plus de 60 articles et réalisé un "annuaire" de 900 pages pour chaque lecteur, dans l'espoir de vous aider à comprendre le processus de construction des grands modèles, l'état actuel de l'industrie et les tendances. Cette collection est divisée en huit sections :Vue d'ensemble, principes fondamentaux des grands modèles, pas de secrets pour la formation aux grands modèles, "deuxième courbe de croissance" des grands modèles : inférence, changements dans les puces d'IA, construction de produits d'IA générative, analyse de l'industrie de l'IA générative, défis et avenir de l'AGI.
Merci à chacun des auteurs de partager ouvertement leurs connaissances en matière d'IA et de nous inspirer, vous et moi, ce qui nous motive à continuer à compiler ce contenu approfondi. Nous espérons trouver dans le fouillis d'informations celles qui valent la peine d'être lues et les diffuser au plus grand nombre possible de personnes désireuses d'apprendre et d'explorer l'IA. Si vous voulez vraiment comprendre l'IA, le raccourci le plus court est d'ouvrir ce cadeau et de vous lancer dans sa lecture. 2025, attendez-vous à de nouvelles surprises de la part de l'IA.

I. Vue d'ensemble
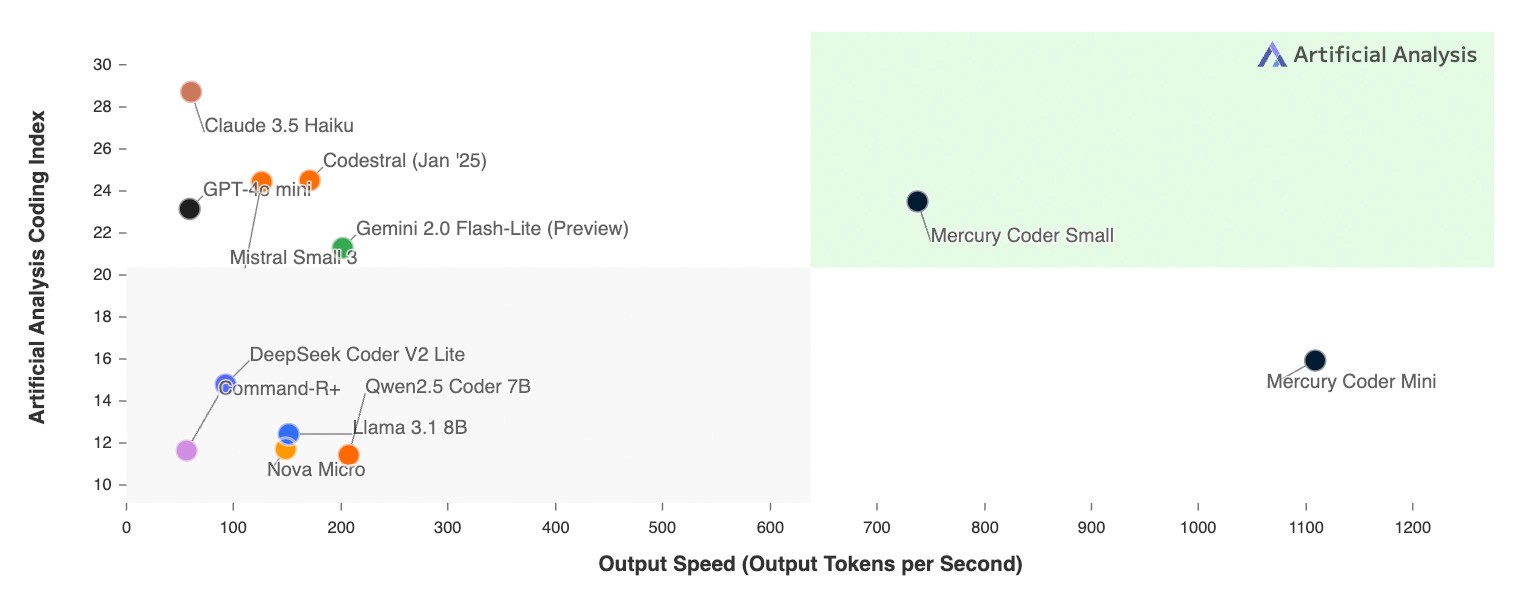
- Inventaire de l'IA 2024 : envolée des investissements, reconfiguration des infrastructures, accélération de l'adoption des technologies /4.
- Les tendances que je perçois derrière 900 outils d'IA open source /36
II. Principes fondamentaux des grands modèles
- Comprendre le fonctionnement du LLM à l'aide des mathématiques du collège /49
- Comprendre et encoder le mécanisme d'auto-attention de LLM à partir de zéro /78
- Révéler le processus d'échantillonnage du LLM /112
- 50 diagrammes pour visualiser et comprendre le grand modèle de l'expert mixte (MoE) /125
- Construire un modèle de diffusion pour la génération de vidéos à partir de zéro /158
- 10 grands modèles de jeux cachés qui changent la vie de tous les jours /174
Troisièmement, il n'y a pas de secret pour la formation de grands modèles
- LLaMA 3 : Un nouveau prologue à la bataille des grands modèles /177
- Extrapolation des besoins en mémoire des GPU pour la formation au LLM /190
- Révéler les stratégies de lots sur le GPU /200
- La vérité sur les performances derrière l'utilisation du GPU /205
- Allocation de points flottants pour LLM /211
- Optimisation des performances de la multiplication matricielle à entrée mixte /219
- Efficacité de calcul accélérée de 10x pour le LLM : multiplication de la matrice par le vide /227
- Le plus grand ensemble de données de premier niveau en libre accès pour créer 15 000 milliards de tokens /240
- 70B Big Model Training Recipe 1 : Création et évaluation de jeux de données /244
- Du métal nu aux grands modèles 70B ② : Configuration de l'infrastructure et création de scripts /270
- 70B Large Model Training Recipe III : Findings from 1000 Hyperparameter Optimisation Experiments /289
- John Schulman, responsable de ChatGPT : Le secret de la mise à niveau des grands modèles /303
Grand modèle "deuxième courbe de croissance" : raisonnement
- Le nouveau champ de bataille de l'IA générative : l'inférence logique et le calcul déductif /318
- Choix de la stratégie d'inférence logique LLM : calcul pendant l'inférence ou calcul pendant l'entraînement /330
- Exploration de l'espace de débit, de latence et de coût du raisonnement LLM /345
- Parvenir à un raisonnement LLM extrême à partir de zéro /363
- Guide du raisonnement LLM pour les débutants 1 : Phases d'initialisation et de décodage de la génération de texte /402
- Guide du raisonnement LLM pour les débutants ② : Analyse approfondie du cache KV /408
- Guide du raisonnement LLM pour les débutants (3) : Profilage de la performance des modèles /429
- Guide d'accélération du raisonnement pour le LLM /442
- LLM Serving Maximisation of Effective Throughput /480
- Comment évaluer de manière précise et interprétable les effets quantitatifs des grands modèles ? /491
- Évaluation de l'efficacité quantitative du LLM : résultats après 500 000 tests empiriques /502
- Diffusion stable XL Guide ultime d'optimisation /510
V. Changements dans les puces d'IA
- Louer un H100 pour 2 dollars de l'heure : la nuit qui précède l'éclatement de la bulle des GPU /585
- Exploration de la technologie ultime d'interconnexion des GPU : la disparition du mur de mémoire /600
- Cerebras : défier Nvidia, la "magie" de la puce d'inférence IA la plus rapide au monde /614
- 20x plus rapide que les GPU ? Analyse prix/performance de l'inférence d-Matrix /624
- Technologie des semi-conducteurs, marchés et avenir de l'IA /630
- Histoire, technologie et acteurs clés des centres de données d'IA /642
VI. construction de produits d'IA générative
- La première année de productisation des grands modèles : tactiques, opérations et stratégie /658
- OpenAI abandonnée, les grands modèles maison sont libres d'utilisation ! Token développeur gratuit mis en place /691
- Mesure de la capacité RAG du LLM en contexte long : gpt-o1 vs. Gémeaux /699
- Comparaison coût-efficacité d'un grand modèle : DeepSeek 2.5 vs. Claude 3.5 Sonnet vs. GPT-4o /712
- Outils de codage efficaces pour les ingénieurs 10x : Cursor x SiliconCloud /718
- Bat Midjourney-v6, fait tourner Kotaku Kolors sans GPU /723
- L'approche de Perplexity en matière de développement de produits /728
- Derrière l'explosion du NotebookLM : perspectives et innovations fondamentales dans les produits natifs de l'IA /739
- Forme organisationnelle de l'OpenAI, mécanismes de décision et construction de produits /750
- Démontage de la plateforme d'IA générative : composants sous-jacents, fonctionnalité et mise en œuvre /761
- Du généraliste à l'expert : l'évolution des systèmes d'IA vers l'IA composite /786
VII. analyse de l'industrie de l'IA générative
- Le code commercial derrière l'IA Open Source /792
- Mystères et flux de capitaux sur le marché de l'IA /805
- Économie de l'industrie de l'IA générative : répartition de la valeur et structure des bénéfices /819
- Dernière enquête sur l'IA générative en entreprise : les dépenses d'IA sont multipliées par 6, les déploiements multi-modèles prévalent /829
- Raisonnement génératif de l'IA Technologies, marchés et avenir /842
- Opportunités de marché, concurrence et avenir de l'activité de raisonnement génératif de l'IA /855
- L'IA n'est pas une nouvelle "bulle internet" /864
- Les trois perspectives de Sequoia Capital en matière d'IA pour 2025 /878
VIII. les défis et l'avenir de l'AGI
- Le mythe de la mise à l'échelle de l'IA /884
- La mise à l'échelle des grands modèles est-elle durable ? /891
- Le "saut critique" de la GenAI : raisonnement et connaissance /904
- Les chaînes du raisonnement logique du LLM et les stratégies pour les briser /924
- Revoir les trois sophismes du raisonnement logique en LLM /930
- Richard Sutton, le père de l'apprentissage par renforcement : le prochain paradigme dans la recherche sur l'AGI /937
- Richard Sutton, le père de l'apprentissage par renforcement : une autre possibilité pour l'AGI /949
https://siliconflow.feishu.cn/file/OSZtbnfYQoa4nBxuQ7Kcwpjwnpf
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...