MiniRAG : Cadre de génération amélioré pour la recherche simplifiée, index de graphe d'entité rappelant les blocs de texte pertinents.

Introduction générale
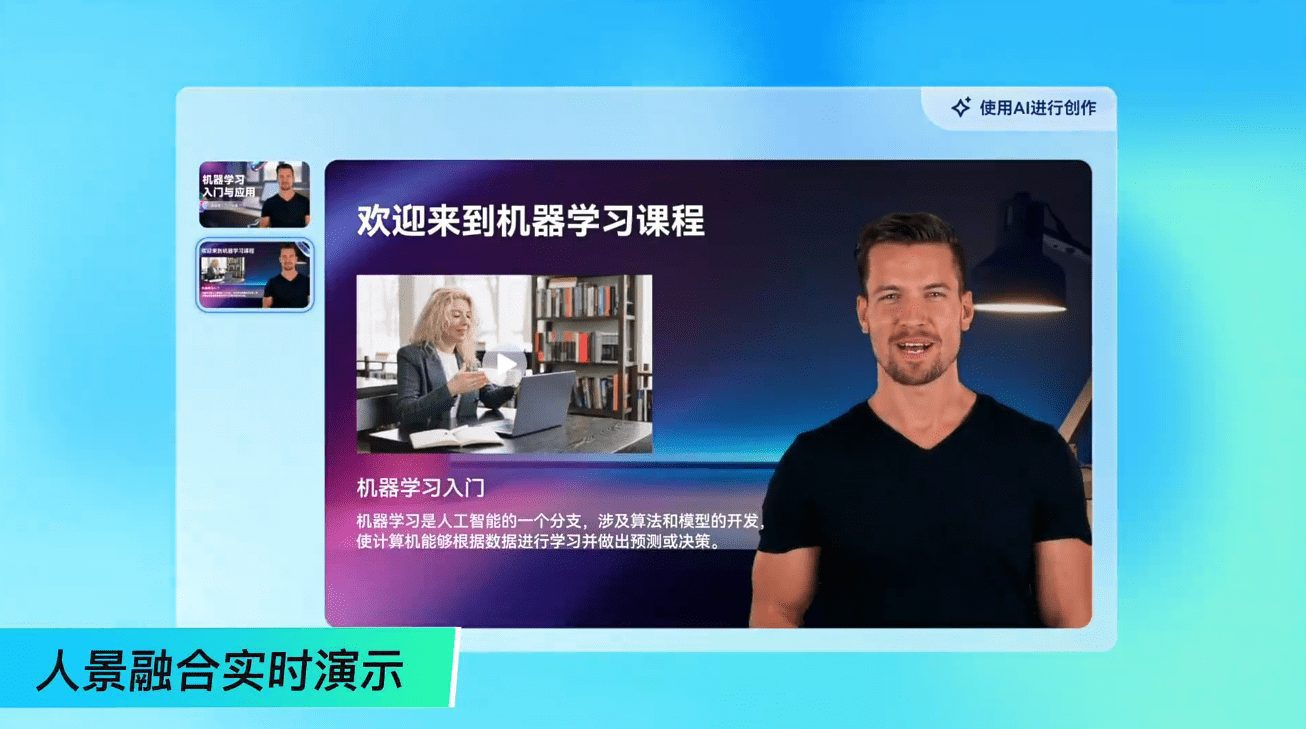
MiniRAG est un cadre extrêmement simple de Génération Augmentée de Récupération (RAG) qui vise à atteindre de bonnes performances RAG même pour les petits modèles grâce à l'indexation de graphes hétérogènes et à la récupération topologique légère. Développé par le Data Science Laboratory de l'Université de Hong Kong (HKUDS), le projet se concentre sur la résolution du problème de dégradation des performances auquel sont confrontés les petits modèles linguistiques (SLM) dans les cadres RAG existants. miniRAG réduit la dépendance à l'égard d'une compréhension sémantique complexe en combinant les morceaux de texte et les entités nommées dans une structure unifiée unique, et exploite les structures de graphe pour une découverte efficace des connaissances. Le cadre atteint des performances comparables avec seulement 251 TP3T de l'espace de stockage de l'approche du grand modèle de langage (LLM).

Liste des fonctions
- Mécanisme d'indexation de graphes hétérogènes : combinaison de blocs de texte et d'entités nommées pour réduire la dépendance à l'égard d'une compréhension sémantique complexe.
- Recherche topologique légère : découverte efficace de connaissances à l'aide de structures graphiques.
- Compatibilité avec les modèles linguistiques de petite taille : performance efficace du RAG dans les scénarios à ressources limitées.
- Ensemble de données de référence complet : l'ensemble de données LiHua-World est fourni pour évaluer les performances des systèmes RAG légers dans le cadre de requêtes complexes.
- Installation facile : permet l'installation à partir du code source et de PyPI.
Utiliser l'aide
Processus d'installation
Installation à partir de la source (recommandée)
- Clonage du dépôt MiniRAG :
git clone https://github.com/HKUDS/MiniRAG.git
cd MiniRAG
- Installer la dépendance :
pip install -e .
Installation à partir de PyPI
MiniRAG est basé sur LightRAG et peut donc être installé directement :
pip install lightrag-hku
Démarrage rapide
- Téléchargez l'ensemble de données requis et placez-le dans le fichier
./datasetcatalogue. Par exemple, l'ensemble de données LiHua-World a été placé dans la section./dataset/LiHua-World/data/Catalogue. - Utilisez la commande suivante pour indexer le jeu de données :
python ./reproduce/Step_0_index.py
- Lancer le module Q&R :
python ./reproduce/Step_1_QA.py
- Il est également possible d'utiliser l'option
./main.pyLe code suivant initialise le MiniRAG.
Principales fonctions
Mécanisme d'indexation hétérogène des graphes
MiniRAG crée des index de graphes hétérogènes en combinant des blocs de texte et des entités nommées dans une structure unifiée. Les utilisateurs peuvent y parvenir en suivant les étapes ci-dessous :
- Préparer le jeu de données et s'assurer qu'il est formaté comme il se doit.
- Exécuter le script d'indexation :
python ./reproduce/Step_0_index.py
- Une fois l'indexation terminée, les données sont stockées dans le répertoire spécifié pour être récupérées ultérieurement.
Recherche améliorée par topologie légère
MiniRAG utilise des structures graphiques pour une découverte efficace des connaissances, qui peuvent être récupérées par l'utilisateur au cours des étapes suivantes :
- Initialiser le MiniRAG :
from minirag import MiniRAG
model = MiniRAG()
- Charger l'ensemble de données et le récupérer :
results = model.retrieve("你的查询")
- Traite les résultats de la recherche et génère une réponse :
response = model.generate(results)
Grâce aux étapes ci-dessus, les utilisateurs peuvent tirer pleinement parti des fonctionnalités de MiniRAG pour générer des améliorations de recherche efficaces.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes

Pas de commentaires...