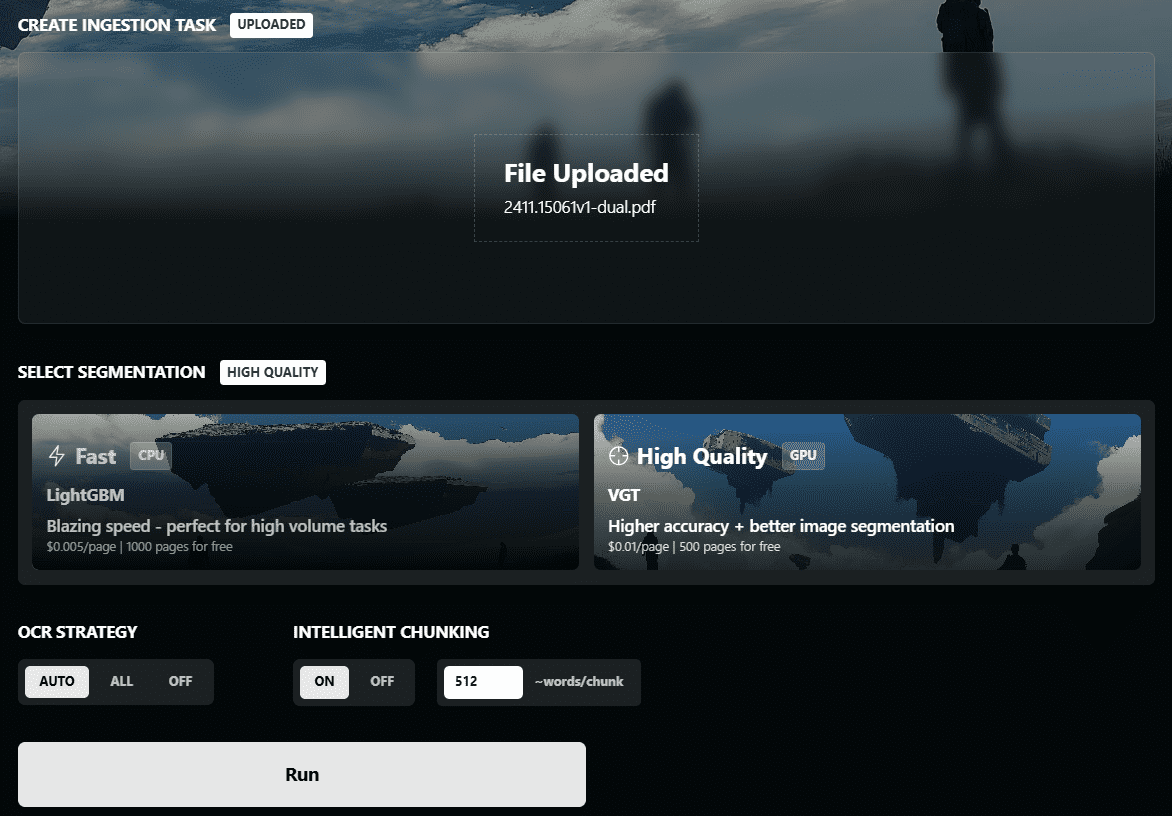
MiniMind-V : 1 heure d'entraînement de 26M modèles paramétriques de langage visuel

Introduction générale
MiniMind-V est un projet open source, hébergé sur GitHub, conçu pour aider les utilisateurs à former un modèle de langage visuel léger (VLM) avec seulement 26 millions de paramètres en moins d'une heure. Il est basé sur le modèle de langage MiniMind, le nouveau codeur visuel et le module de projection de caractéristiques, le support pour le traitement conjoint d'images et de textes. Le projet fournit un code complet, du nettoyage des données à l'inférence du modèle, avec un coût d'apprentissage aussi bas que ~RMB1.3 pour un seul GPU (par exemple, NVIDIA 3090). MiniMind-V met l'accent sur la simplicité et la facilité d'utilisation, avec moins de 50 lignes de code modifiées, ce qui en fait un outil approprié pour les développeurs afin d'expérimenter et d'apprendre le processus de construction d'un modèle de langage visuel.

Liste des fonctions
- Fournit un code d'entraînement complet pour 26 millions de modèles de langage visuel, permettant un entraînement rapide sur un seul GPU.
- À l'aide du codeur visuel CLIP, une image de 224x224 pixels a été traitée pour générer 196 jetons visuels.
- Prise en charge de la saisie d'une ou de plusieurs images, combinée à du texte pour le dialogue, la description de l'image ou les questions-réponses.
- Contient des scripts de processus complets pour le nettoyage des ensembles de données, le pré-entraînement et le réglage fin supervisé (SFT).
- Fournit une implémentation native de PyTorch, supporte l'accélération multi-cartes et est hautement compatible.
- Inclut le téléchargement des poids des modèles et prend en charge les plateformes Hugging Face et ModelScope.
- Fournit une interface web et un raisonnement en ligne de commande pour tester facilement les effets du modèle.
- Soutien à l'outil wandb pour enregistrer les pertes et les performances au cours de la formation.
Utiliser l'aide
Le processus d'utilisation de MiniMind-V comprend la configuration de l'environnement, la préparation des données, l'apprentissage du modèle et le test des effets. Chaque étape est décrite en détail ci-dessous pour aider les utilisateurs à démarrer rapidement.
Configuration de l'environnement
MiniMind-V nécessite un environnement Python et un support GPU. Voici les étapes de l'installation :
- Clonage du code
Exécutez la commande suivante dans le terminal pour télécharger le code du projet :git clone https://github.com/jingyaogong/minimind-v cd minimind-v - Installation des dépendances
Offres de projetsrequirements.txtcontenant les bibliothèques requises. Exécutez la commande suivante :pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simplePython 3.9 ou supérieur est recommandé. Assurez-vous que PyTorch supporte CUDA (si vous avez un GPU). Cela peut être vérifié en exécutant le code suivant :
import torch print(torch.cuda.is_available())exportations
TrueIndique que le GPU est disponible. - Télécharger les modèles CLIP
MiniMind-V utilise le modèle CLIP (clip-vit-base-patch16) en tant que codeur visuel. Exécutez la commande suivante pour télécharger et placer le fichier./model/vision_model: :git clone https://huggingface.co/openai/clip-vit-base-patch16 ./model/vision_modelÉgalement disponible en téléchargement sur ModelScope :
git clone https://www.modelscope.cn/models/openai-mirror/clip-vit-base-patch16 ./model/vision_model - Télécharger les poids du modèle linguistique de base
MiniMind-V est basé sur le modèle de langage MiniMind, ce qui nécessite le téléchargement des poids du modèle de langage sur le serveur./outCatalogue. Exemple :wget https://huggingface.co/jingyaogong/MiniMind2-V-PyTorch/blob/main/lm_512.pth -P ./outou télécharger
lm_768.pthselon la configuration du modèle.
Préparation des données
MiniMind-V utilise environ 570 000 images de pré-entraînement et 300 000 données de mise au point de commande avec environ 5 Go d'espace de stockage. la procédure est la suivante :
- Création d'un catalogue de données
Dans le répertoire racine du projet, créez le fichier./datasetDossier :mkdir dataset - Télécharger la base de données
Téléchargez un jeu de données de Hugging Face ou ModelScope contenant les éléments suivants*.jsonlDonnées des questions-réponses et*imagesDonnées d'image :- Visage d'étreinte : https://huggingface.co/datasets/jingyaogong/minimind-v_dataset
- Champ d'application du modèle : https://www.modelscope.cn/datasets/gongjy/minimind-v_dataset
Téléchargez et décompressez les données de l'image vers./dataset: :
unzip pretrain_images.zip -d ./dataset unzip sft_images.zip -d ./dataset - Ensemble de données de validation
sécurisé./datasetContient les fichiers suivants :pretrain_vlm_data.jsonlDonnées de préformation, environ 570 000 entrées.sft_vlm_data.jsonlDonnées de mise au point d'un seul chiffre, environ 300 000 entrées.sft_vlm_data_multi.jsonlDonnées de réglage fin des cartes multiples, environ 13 600 entrées.- Dossier Image : contient des fichiers d'images pour le pré-entraînement et le réglage fin.
formation au modèle
La formation MiniMind-V est divisée en préformation et en mise au point supervisée, et prend en charge l'accélération d'une ou de plusieurs cartes.
- Paramètres de configuration
compilateur./model/LMConfig.py, définir les paramètres du modèle. Exemple :- Les figurines :
dim=512,n_layers=8 - Modèle moyen :
dim=768,n_layers=16
Ces paramètres déterminent la taille et les performances du modèle.
- Les figurines :
- préformation
Exécuter des scripts de pré-entraînement pour apprendre les capacités de description des images :python train_pretrain_vlm.py --epochs 4Les poids de sortie sont enregistrés sous la forme
./out/pretrain_vlm_512.pth(ou768.pthLe modèle CLIP est gelé). Une seule NVIDIA 3090 prend environ 1 heure pour compléter 1 époque. gèle le modèle CLIP et n'entraîne que la couche de projection et la dernière couche du modèle de langage. - Réglage fin supervisé (SFT)
Ajustement fin à l'aide de poids pré-entraînés afin d'optimiser les capacités de dialogue :python train_sft_vlm.py --epochs 4Les poids de sortie sont enregistrés sous la forme
./out/sft_vlm_512.pth. Cette étape permet d'entraîner la couche de projection et le modèle linguistique avec tous les paramètres. - Formation Doka (facultatif)
Si vous avez N cartes graphiques, utilisez la commande suivante pour accélérer :torchrun --nproc_per_node N train_pretrain_vlm.py --epochs 4l'interchangeabilité
train_pretrain_vlm.pyPour les autres scripts de formation (par ex.train_sft_vlm.py). - Contrôler la formation
Les pertes de formation peuvent être enregistrées à l'aide de wandb :python train_pretrain_vlm.py --epochs 4 --use_wandbConsultez les données en temps réel sur le site officiel de wandb.
Test d'efficacité
Une fois la formation terminée, le modèle peut être testé pour vérifier ses capacités de dialogue d'images.
- raisonnement en ligne de commande
Exécutez la commande suivante pour charger le modèle :python eval_vlm.py --load 1 --model_mode 1--load 1: Charger le modèle de format des transformateurs à partir de Hugging Face.--load 0: A partir de./outCharger les poids PyTorch.--model_mode 1: Test de modèles finement ajustés ;0Test des modèles pré-entraînés.
- Test de l'interface web
Lancer l'interface web :python web_demo_vlm.pyentretiens
http://localhost:8000Téléchargez une image et entrez le texte à tester. - format d'entrée
MiniMind-V utilise 196@@@Les espaces réservés représentent une image. Exemple :@@@...@@@\n这张图片是什么内容?Exemple de saisie d'images multiples :
@@@...@@@\n第一张图是什么?\n@@@...@@@\n第二张图是什么? - Télécharger les poids de pré-entraînement
Si vous ne vous entraînez pas, vous pouvez télécharger directement les poids officiels :- Format PyTorch :https://huggingface.co/jingyaogong/MiniMind2-V-PyTorch
- Format Transformers :https://huggingface.co/collections/jingyaogong/minimind-v-67000833fb60b3a2e1f3597d
mise en garde
- Mémoire vidéo recommandée 24GB (par exemple RTX 3090). Si la mémoire vidéo est insuffisante, réduisez la taille du lot (
batch_size). - S'assurer que le chemin d'accès au jeu de données est correct.
*.jsonlet les fichiers images doivent être placés dans le répertoire./dataset. - Le gel des modèles CLIP pendant la formation réduit les exigences arithmétiques.
- Les dialogues à images multiples ont une efficacité limitée et il est recommandé de tester en priorité des scénarios à image unique.
scénario d'application
- Apprentissage algorithmique de l'IA
MiniMind-V fournit un code de modélisation en langage visuel concis qui permet aux étudiants de comprendre les principes de la modélisation multimodale. Les utilisateurs peuvent modifier le code pour expérimenter avec différents paramètres ou ensembles de données. - Prototypage rapide
Les développeurs peuvent prototyper des applications de dialogue d'images basées sur MiniMind-V. Léger et efficace, il convient aux appareils à faible puissance de calcul tels que les PC ou les systèmes embarqués. Léger et efficace, il convient aux appareils à faible puissance de calcul tels que les PC ou les systèmes embarqués. - Outils d'éducation et de formation
Les collèges et les universités peuvent utiliser MiniMind-V dans les cours d'intelligence artificielle pour montrer l'ensemble du processus de formation des modèles. Le code est clairement commenté et adapté à la pratique en classe. - Expériences à faible coût
Le coût de formation du projet est faible, ce qui convient aux équipes disposant d'un budget limité pour tester l'effet des modèles multimodaux sans avoir besoin de serveurs très performants.
QA
- Quelle est la taille des images prises en charge par MiniMind-V ?
Le traitement par défaut est celui des images de 224x224 pixels, limité par le modèle CLIP. Les images des ensembles de données peuvent être compressées à 128x128 pour économiser de l'espace. Des modèles CLIP à plus haute résolution pourront être testés à l'avenir. - Quelle est la durée de la formation ?
Sur un seul NVIDIA 3090, 1 époque de pré-entraînement prend environ 1 heure, avec un réglage fin un peu plus rapide. La durée exacte varie en fonction du matériel et de la quantité de données. - Puis-je l'affiner sans formation préalable ?
Peut. Téléchargez directement les poids officiels de pré-entraînement et exécutez...train_sft_vlm.pyAjustement minutieux. - Quelles sont les langues prises en charge ?
Prend principalement en charge le chinois et l'anglais, l'effet dépend de l'ensemble de données. Les utilisateurs peuvent étendre le champ d'application à d'autres langues en procédant à un réglage fin. - Le dialogue multi-images fonctionne-t-il bien ?
La capacité actuelle de dialogue multi-images est limitée et il est recommandé d'utiliser de préférence des scénarios à image unique. Des améliorations pourront être apportées à l'avenir avec des modèles et des ensembles de données plus importants.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...