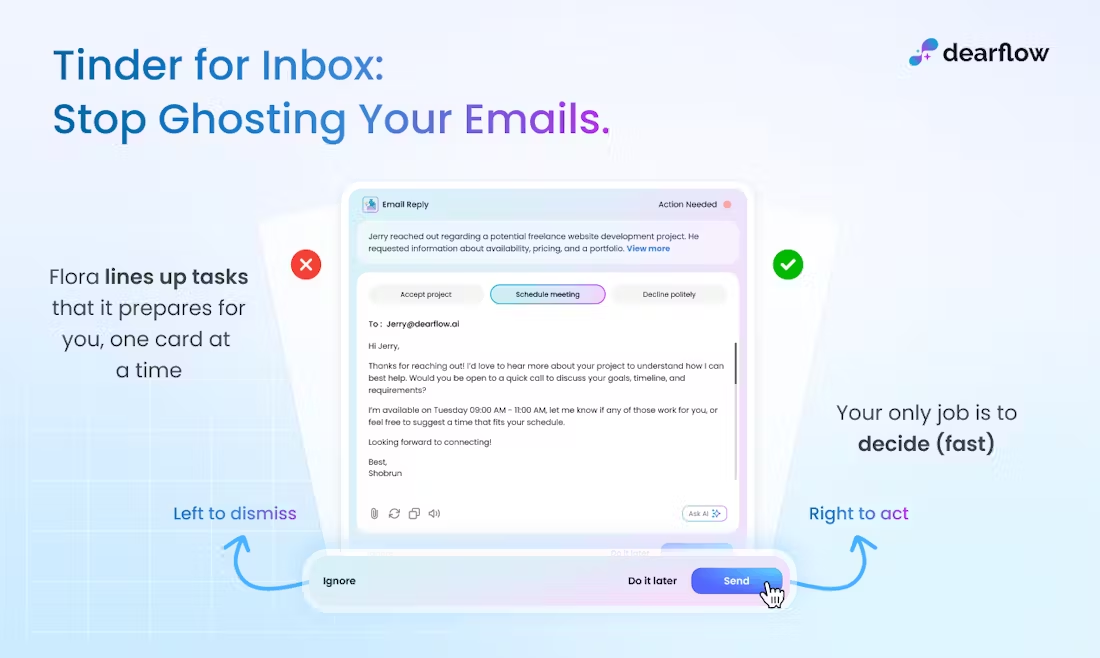
Marker : conversion rapide de PDF en Markdown outils open source

Introduction générale
Marker est un outil de traitement de documents basé sur l'apprentissage profond, conçu pour convertir rapidement et précisément des fichiers PDF au format Markdown. Il prend en charge un large éventail de types de documents et est particulièrement optimisé pour la conversion de livres et de documents scientifiques. Il prend en charge un large éventail de types de documents et est particulièrement optimisé pour la conversion de livres et d'articles scientifiques. Marker est capable de supprimer le contenu redondant tel que les en-têtes et les pieds de page, de formater les tableaux et les blocs de code, ainsi que d'extraire et d'enregistrer les images. Il convertit également la plupart des formules au format LaTeX et prend en charge l'exécution sur GPU, CPU ou MPS.

Liste des fonctions
- Convertir des fichiers PDF au format Markdown
- Prise en charge de plusieurs types de documents, y compris les livres et les articles scientifiques
- Supprimer le contenu excédentaire tel que les en-têtes et les pieds de page
- Formatage des tableaux et des blocs de code
- Extraire et enregistrer des images
- Convertit la plupart des équations au format LaTeX
- Prise en charge du fonctionnement du GPU, du CPU et du MPS
Utiliser l'aide
Processus d'installation
- Installation des dépendancesPython 3.6 et plus : Assurez-vous que Python 3.6 et plus est installé, et que les dépendances suivantes sont installées :
pip install marker-pdf - exemple de fonctionnement: :
marker_single /path/to/file.pdf /path/to/output/folder --batch_multiplier 2 --max_pages 10
Lignes directrices pour l'utilisation
Conversion de fichiers individuels
marker_single /path/to/file.pdf /path/to/output/folder --batch_multiplier 2 --max_pages 10
--batch_multiplierest un multiple de la taille du lot par défaut si vous disposez de VRAM supplémentaire. Les nombres plus élevés utilisent plus de VRAM, mais sont plus rapides à traiter. Le paramètre par défaut est 2. La taille de lot par défaut nécessite environ 3 Go de VRAM.--max_pagesest le nombre maximum de pages à traiter. L'omission de ce point entraînera la conversion de l'ensemble du document.--langsest une liste facultative de langues de documents séparées par des virgules à utiliser pour l'OCR. est facultatif par défaut et doit être fourni si tesseract est utilisé.--ocr_all_pagesest un paramètre optionnel pour forcer l'OCR de toutes les pages du PDF, si ce paramètre ou la variable d'environnement `OCR_ALL_PAGES` est vrai, l'OCR sera forcé.
Une liste des langues supportées par l'OCR de Surya est disponible dans [Voici] trouvée. Si vous avez besoin d'autres langues, vous pouvez utiliser n'importe laquelle des langues prises en charge, il vous suffit de définir l'option OCR_ENGINE fixé à ocrmypdfSi l'OCR n'est pas nécessaire, les marqueurs peuvent prendre en charge n'importe quelle langue. Si l'OCR n'est pas nécessaire, le marqueur peut prendre en charge n'importe quelle langue.
Convertir plusieurs fichiers
marker /path/to/input/folder /path/to/output/folder --workers 4 --max 10 --min_length 10000
--workersest le nombre de PDF convertis simultanément. La valeur par défaut est 1, mais vous pouvez l'augmenter pour accroître le débit au prix d'une utilisation accrue du CPU/GPU. Chaque processus ouvrier utilisera 5 Go de VRAM au maximum et 3,5 Go en moyenne.--maxest le nombre maximum de PDF à convertir. Si vous omettez cet élément, tous les PDF du dossier seront convertis.--min_lengthest la valeur minimale du nombre de caractères à extraire dans un PDF. Seuls les PDF dépassant cette valeur seront pris en compte pour le traitement. Si vous traitez un grand nombre de PDF, il est recommandé de définir cette valeur afin d'éviter l'OCR de PDF constitués principalement d'images (ce qui ralentit le traitement).--metadata_fileest un chemin d'accès facultatif à un fichier JSON contenant des métadonnées sur le PDF. S'il est fourni, ce fichier sera utilisé pour définir la langue de chaque PDF. La définition de la langue est facultative pour Surya (par défaut), mais obligatoire pour Tesseract. Le format est le suivant :
{
"pdf1.pdf": {"languages": ["English"]},
"pdf2.pdf": {"languages": ["Spanish", "Russian"]},
...
}
Vous pouvez utiliser soit le nom de la langue, soit le code. Le code exact dépend du moteur OCR. Pour une liste complète des codes Surya, voir [VoiciPour Tesseract, voir [Voici]
Configuration des variables d'environnement des marqueurs dans FastGPT
Pour activer le service de résolution personnalisée, vous devez configurer les variables d'environnement suivantes dans FastGPT :
CUSTOM_READ_FILE_URL=http://xxxx.com/v1/parse/file
CUSTOM_READ_FILE_EXTENSION=pdf
- CUSTOM_READ_FILE_URL - l'adresse d'accès du service de résolution personnalisé, vous devez remplacer l'hôte par l'adresse du service de résolution que vous avez déployé, et le chemin d'accès reste inchangé.
- CUSTOM_READ_FILE_EXTENSION - Spécifie les suffixes de type de fichier qui sont pris en charge pour l'analyse, les types de fichiers multiples sont séparés par des virgules.
Vérifier l'effet de l'analyse syntaxique
Une fois la configuration terminée, vous pouvez vérifier l'effet de l'analyse en suivant les étapes ci-dessous :
- Télécharger un fichier PDF dans la base de connaissances et confirmer le téléchargement
- Affichez le journal du système (vous devez définir le niveau LOG_LEVEL sur info ou debug).
- Vous constaterez que le fichier PDF analysé par Marker contient des liens vers des images complètes, ce qui indique que l'analyse a réussi.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...