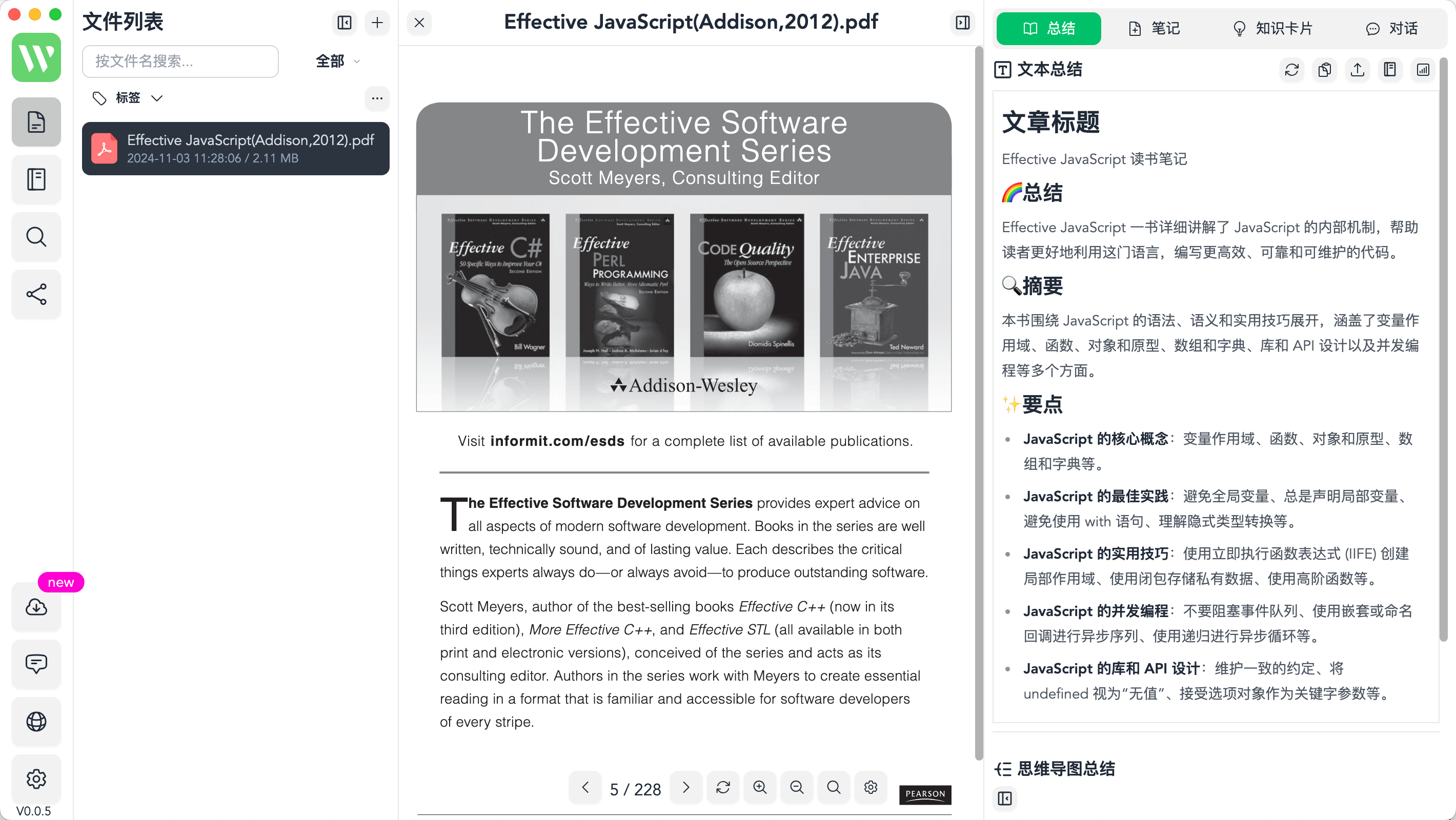
Outil open source pour contrôler les opérations de macOS par la voix et le texte

Introduction générale
MacOS LLM Controller est une application de bureau open source, hébergée sur GitHub, qui permet aux utilisateurs d'exécuter des commandes du système macOS en entrant des commandes en langage naturel par le biais de la voix ou du texte. Elle est basée sur le modèle Llama-3.2-3B-Instruct et utilise LlamaStack pour générer du code Python qui appelle les API du système macOS pour effectuer des tâches. Les utilisateurs peuvent dire "Ouvrir le terminal" ou taper "Nouveau dossier" et l'outil analysera et exécutera automatiquement l'opération. Le projet utilise Réagir Le front-end et le back-end Flask, avec un retour d'état en temps réel et un historique des commandes, sont idéaux pour les utilisateurs de macOS afin d'améliorer l'efficacité opérationnelle, en particulier pour les développeurs ou les personnes ayant des besoins en matière d'accessibilité. Le code est accessible au public et la communauté peut participer à l'optimisation.

Liste des fonctions
- Reconnaissance des commandes vocales : saisissez votre voix dans le microphone et traduisez-la en commandes macOS en temps réel.
- Saisie de commandes textuelles : prend en charge la saisie de texte en langage naturel pour effectuer des opérations sur le système.
- Historique des commandes : affiche l'état de réussite ou d'échec des commandes exécutées.
- Retour d'information en temps réel : l'interface met à jour de manière dynamique l'état des connexions aux services et de l'exécution des commandes.
- Génération de code Python : transforme les instructions en code d'appel d'API macOS exécutable basé sur LlamaStack.
- Fonctionnement localisé : tous les traitements sont effectués localement afin de protéger la vie privée des utilisateurs.
- Security Check : effectue une validation de sécurité de base du code Python généré.
Utiliser l'aide
Processus d'installation
Le contrôleur LLM de MacOS nécessite la configuration d'un environnement sur le système macOS, y compris le front-end, le back-end et le modèle LlamaStack. Vous trouverez ci-dessous les étapes détaillées de l'installation afin de garantir que les utilisateurs puissent l'utiliser sans problème :
1. préparation à l'environnement
Assurez-vous que le système répond aux exigences suivantes :
- système d'exploitationmacOS (le projet est conçu pour macOS et ne prend pas explicitement en charge d'autres systèmes).
- Node.jsLe système de gestion de l'information de la Commission européenne : version 16 ou plus récente, y compris
npmNode.js. Il peut être téléchargé à partir du site web de Node.js. - PythonLe système d'information de la Commission européenne : version 3.8 ou supérieure, comprend les éléments suivants
pipIl peut être téléchargé sur le site web de Python. Il peut être téléchargé à partir du site web de Python. - OllamaLe modèle Llama : Pour l'exécution du modèle Llama. Accès Ollama Site officiel Installation.
- DockerPour exécuter LlamaStack, installez Docker Desktop.
- exigences en matière de matérielPour l'inférence des modèles, il est recommandé de disposer d'au moins 16 Go de mémoire vive et d'un processeur à plusieurs cœurs.
2. clonage des codes de projet
Ouvrez un terminal et exécutez la commande suivante pour cloner le code :
git clone https://github.com/duduyiq2001/llama-desktop-controller.git
cd llama-desktop-controller
3. configuration de LlamaStack
LlamaStack est la dépendance principale du projet pour générer du code Python. Les étapes de configuration sont les suivantes :
Définition des variables d'environnement: :
Exécutez la commande suivante dans le terminal pour spécifier le modèle d'inférence :
export INFERENCE_MODEL="meta-llama/Llama-3.2-3B-Instruct"
export OLLAMA_INFERENCE_MODEL="llama3.2:3b-instruct-fp16"
Démarrer le serveur de raisonnement Ollama: :
Exécutez la commande suivante pour démarrer le modèle et faire en sorte qu'il reste actif pendant 60 minutes :
ollama run $OLLAMA_INFERENCE_MODEL --keepalive 60m
Exécuter LlamaStack avec Docker: :
Définir le port et démarrer le conteneur :
export LLAMA_STACK_PORT=5001
docker run \
-it \
-p $LLAMA_STACK_PORT:$LLAMA_STACK_PORT \
-v ~/.llama:/root/.llama \
llamastack/distribution-ollama \
--port $LLAMA_STACK_PORT \
--env INFERENCE_MODEL=$INFERENCE_MODEL \
--env OLLAMA_URL=http://host.docker.internal:11434
Assurez-vous que le LlamaStack est en http://localhost:5001 Il fonctionne bien.
4) Mise en place du back-end
Le backend est basé sur Flask et est responsable de la gestion des demandes d'API et de la génération de code. Les étapes sont les suivantes :
- Allez dans le répertoire du back-end :
cd backend - Installer les dépendances de Python :
pip install -r ../requirements.txtLes dépendances comprennent
flask,flask-cors,requests,pyobjcrépondre en chantantllama-stack-client. Si l'installation échoue, utilisez un miroir domestique :pip install -r ../requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple - Démarrer le serveur Flask :
python server.py - Confirmer que le backend tourne sur
http://localhost:5066.
5. mise en place du front-end
Le front-end est basé sur React et fournit l'interface utilisateur. Les étapes sont les suivantes :
- Allez dans le répertoire front-end :
cd .. # 返回项目根目录 - Installer la dépendance Node.js :
npm install - Démarrer le serveur de développement :
npm run dev - Vérifier que le front-end tourne sur
http://localhost:5173.
6. l'accès aux applications
Ouvrez votre navigateur et visitez http://localhost:5173. Assurez-vous que le backend et LlamaStack fonctionnent correctement, sinon les fonctionnalités peuvent être limitées.
Guide d'utilisation des fonctions
1. l'utilisation de commandes vocales
La saisie vocale est la fonction principale du projet et convient à une utilisation rapide. Les étapes de l'opération sont les suivantes :
- Activer le mode vocalCliquez sur le bouton "Voice Input" dans l'interface principale (ou utilisez les touches de raccourci, vous devez consulter la documentation pour confirmer).
- Instructions pour l'enregistrementLes commandes : Dites des commandes dans le microphone, telles que "Ouvrir le Finder" ou "Fermer Safari". Veillez à ce que l'environnement soit calme pour améliorer les taux de reconnaissance.
- processus de mise en œuvreL'outil convertit la parole en texte à l'aide de l'API SpeechRecognition, que LlamaStack analyse en code Python qui appelle l'API macOS pour effectuer la tâche.
- Exemples de commandes courantes: :
- "Open Terminal" : lance Terminal.app.
- "Nouveau dossier" : crée un dossier dans le répertoire actuel.
- "Capture d'écran" : déclenche la fonction de capture d'écran de macOS.
- mise en garde: :
- Les privilèges du microphone doivent être autorisés pour la première utilisation.
- Si la reconnaissance échoue, vérifiez les réglages du microphone ou modifiez la saisie de texte.
2. l'utilisation d'instructions textuelles
La saisie de texte permet un contrôle précis. Les étapes de fonctionnement sont les suivantes :
- Ouvrir la boîte de saisie: Trouver la zone de saisie de texte dans l'interface.
- entréeType : Tapez en langage naturel, par exemple "ouvrir le calendrier" ou "régler le volume sur 50%".
- Présentation des instructionsCliquez sur le bouton Exécuter ou appuyez sur Entrée, et l'outil génère et exécute le code Python.
- Utilisation avancéeLlamaStack supporte des commandes complexes telles que "Créer un nouveau dossier sur le bureau appelé 'Projets' et l'ouvrir". LlamaStack décompose les tâches et les exécute de manière séquentielle.
- attirer l'attention sur qqch.La clarté des instructions améliore la réussite, par exemple "Ouvrir Chrome" est préférable à "Ouvrir le navigateur".
3. visualiser l'historique des commandes
L'interface fournit une zone d'historique des commandes qui indique l'état d'exécution de chaque commande :
- état de réussiteUne marque verte indique que la commande a été exécutée correctement.
- état d'erreurLes drapeaux rouges avec des messages d'erreur (par exemple, "permissions insuffisantes").
- gréementVous pouvez cliquer sur Historique pour réexécuter la commande ou afficher le code Python généré.
4. le contrôle de l'état en temps réel
L'état du service est affiché dans le coin supérieur droit de l'interface :
- plus vertLe backend et LlamaStack sont correctement connectés.
- rose: Le service est déconnecté et vous devez vérifier si Flask ou LlamaStack est en cours d'exécution.
- gréementCliquez sur l'icône d'état pour actualiser manuellement la connexion.
5. les inspections de sécurité
effectue une validation de sécurité de base du code Python généré :
- Filtrer les commandes à haut risque (par exemple, supprimer des fichiers système).
- Vérifiez qu'il n'y a pas d'erreurs de syntaxe et que le code est exécutable.
- prendre noteLes commandes provenant de sources inconnues doivent toujours être exécutées avec précaution.
mise en garde
- dépendance à l'égard du modèleLe projet est fixé pour utiliser Llama-3.2-3B-Instruct et ne peut pas remplacer directement d'autres modèles.
- Exigences de performanceL'exécution de LlamaStack nécessite une puissance de calcul élevée, il est donc recommandé de fermer les programmes superflus.
- Méthode de mise en serviceSi le démarrage échoue, vérifiez les journaux du terminal ou accédez à l'application
http://localhost:5066/statusVérifier l'état du backend. - Questions de compétenceCertaines commandes macOS nécessitent une autorisation (par exemple, pour accéder à des fichiers ou contrôler le volume), et la première fois que vous les exécutez, une demande d'autorisation s'affiche.
- Soutien communautaireLes problèmes peuvent être soumis via GitHub Issues avec des journaux d'erreurs pour que les développeurs puissent résoudre les problèmes.
scénario d'application
- Aide à l'accessibilité
Les utilisateurs malvoyants ou à mobilité réduite peuvent utiliser des commandes vocales pour utiliser macOS, comme "Ouvrir Mail" pour lancer rapidement l'application Mail.app, pour une plus grande facilité d'utilisation. - Efficacité du développeur
Les développeurs peuvent rapidement exécuter des commandes telles que "Ouvrir Xcode et créer un nouveau projet", ce qui leur permet de gagner du temps sur les tâches manuelles et de se concentrer sur leurs tâches de développement. - l'automatisation de routine
Les utilisateurs peuvent effectuer des tâches répétitives, telles que "Organiser chaque jour les fichiers du bureau dans des dossiers d'archives", par le biais de commandes textuelles, ce qui convient à un travail de bureau efficace. - Éducation et expérimentation
Les passionnés de programmation peuvent étudier comment LlamaStack transforme le langage naturel en code et apprendre comment l'IA s'intègre aux systèmes.
QA
- Qu'en est-il de l'imprécision de la reconnaissance vocale ?
Assurez-vous que le microphone fonctionne et que l'environnement est exempt de bruit. Si l'échec persiste, passez à la saisie de texte ou vérifiez la configuration de l'API de reconnaissance vocale. - Que se passe-t-il si le backend ne démarre pas ?
Vérifiez que la dépendance Python est complètement installée et que LlamaStack fonctionne sur le serveurhttp://localhost:5001. Voirserver.pyErreur de positionnement du journal. - Prend-il en charge les systèmes non macOS ?
Actuellement, seul macOS est pris en charge, car le code s'appuie sur l'API macOS, mais il pourra être étendu à d'autres plateformes par la communauté à l'avenir. - Comment optimiser les performances ?
Augmentez la mémoire ou utilisez un CPU/GPU performant et fermez les autres programmes gourmands en ressources. Essayez également une configuration plus efficace de LlamaStack. - Comment contribuer au code ?
Il est recommandé de lire la documentation du projet et de suivre les directives de contribution.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...