LocalPdfChatRAG : Outil de chat intelligent pour soutenir les questions-réponses locales sur les documents PDF multi-sources

Introduction générale
LocalePdfChatRAG est un projet open source qui vise à permettre un chat intelligent en combinant des documents PDF locaux avec des modèles RAG (Retrieval Augmented Generation). Le projet permet aux utilisateurs de télécharger des documents PDF et, par le biais de questions en langage naturel, d'obtenir des informations pertinentes à partir du document. localPdfChatRAG utilise une technologie avancée de traitement du langage naturel pour fournir des services efficaces et précis de recherche de contenu documentaire et de questions-réponses pour un large éventail de scénarios, y compris la recherche universitaire et la gestion des documents d'entreprise.

Liste des fonctions
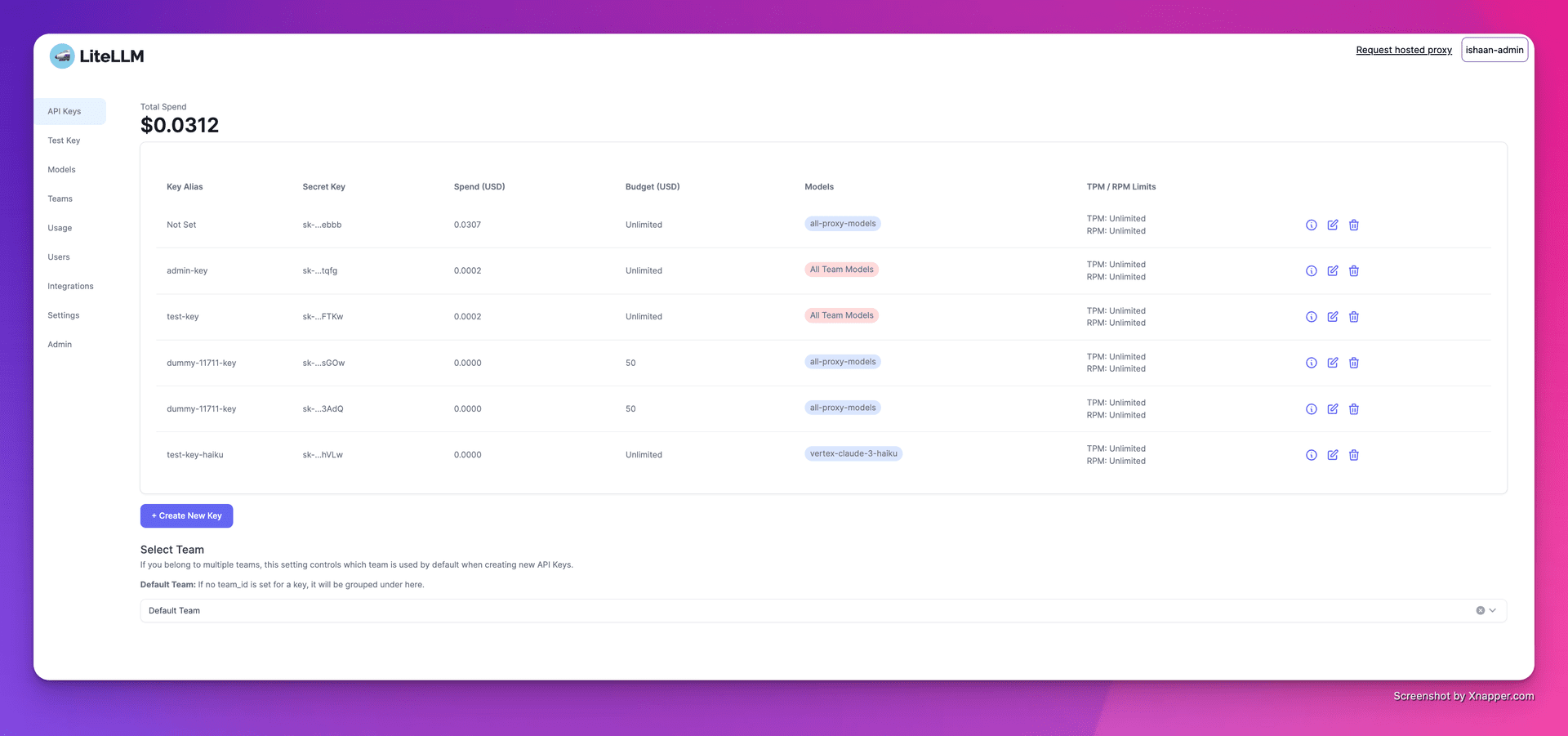
- Téléchargement de documents PDFLes utilisateurs peuvent télécharger des documents PDF locaux, le système analysera et extraira automatiquement le contenu textuel.
- quiz en langage naturelLes utilisateurs peuvent poser des questions en langage naturel et le système récupère les informations pertinentes dans le document PDF téléchargé et génère des réponses.
- l'intégration d'informations multi-sourcesLa recherche de documents PDF locaux et de résultats de recherches sur le web permet d'obtenir des réponses plus complètes.
- vectorisationVectorisation de textes à l'aide de modèles d'intégration pour améliorer la précision de la recherche et des questions-réponses.
- Configuration des variables d'environnementLe système de gestion de l'interface utilisateur (API) permet de configurer les clés d'API et d'autres paramètres via des fichiers .env pour les paramètres définis par l'utilisateur.
Utiliser l'aide
Processus d'installation
- projet de clonageLe code du projet doit être cloné : Exécutez la commande suivante dans le terminal pour cloner le code du projet :
git clone https://github.com/weiwill88/Local_Pdf_Chat_RAG.git
- Installation des dépendancesLe projet doit être installé dans le répertoire du projet et les dépendances nécessaires doivent être installées :
cd Local_Pdf_Chat_RAG
pip install -r requirements.txt
- Configuration des variables d'environnement: Créer un
.envet ajouter ce qui suit :
SERPAPI_KEY=your_serpapi_key
commandant en chef (militaire)your_serpapi_keyRemplacez-la par votre clé SerpAPI.
Processus d'utilisation
- Démarrage des servicesLe service doit être lancé : Exécutez la commande suivante dans le terminal pour démarrer le service :
python rag_demo.py
- Télécharger des documents PDFPour cela, ouvrez votre navigateur pour accéder à l'adresse du service local et téléchargez le document PDF que vous devez traiter.
- poser des questionsLe système récupère les informations pertinentes du document PDF téléchargé et génère une réponse.
Fonctionnement détaillé
- Téléchargement de documents PDFLe système analyse automatiquement le contenu du document et le stocke dans la base de données.
- quiz en langage naturelPour cela, il suffit de saisir une question dans le champ de saisie, par exemple : "Quelles sont les principales conclusions de cet article ? Le système extrait les paragraphes pertinents du document PDF et génère une réponse.
- l'intégration d'informations multi-sourcesLe système ne se contentera pas d'extraire des informations des documents PDF locaux, mais effectuera également des recherches sur le web par l'intermédiaire de SerpAPI, en intégrant de multiples sources d'information pour fournir des réponses plus complètes.
- vectorisationLe système utilise le modèle SentenceTransformer pour vectoriser le texte afin d'assurer une grande précision dans la recherche et les questions-réponses.
- Configuration des variables d'environnementLes utilisateurs peuvent modifier les paramètres du fichier .env pour configurer les clés API, les moteurs de recherche, etc. en fonction de leurs besoins individuels.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes

Pas de commentaires...