
Kimi lance le MoBA : une percée dans la mise en place d'un contexte infini !

Le mélange d'experts et l'attention éparse permettent de créer des contextes virtuellement illimités. Cela permet à l'agent IA RAG de dévorer des bases de code et des documents entiers sans limitations contextuelles.
📌 Le défi de l'attention en contexte long
Les transformateurs sont toujours confrontés à une lourde charge de calcul lorsque les séquences deviennent très grandes. Le modèle d'attention par défaut prend chaque jeton La comparaison avec tous les autres tokens entraîne une augmentation quadratique du coût de calcul. Cette surcharge devient un problème lors de la lecture de bases de codes entières, de documents à plusieurs chapitres ou de grandes quantités de textes juridiques.
📌 MoBA
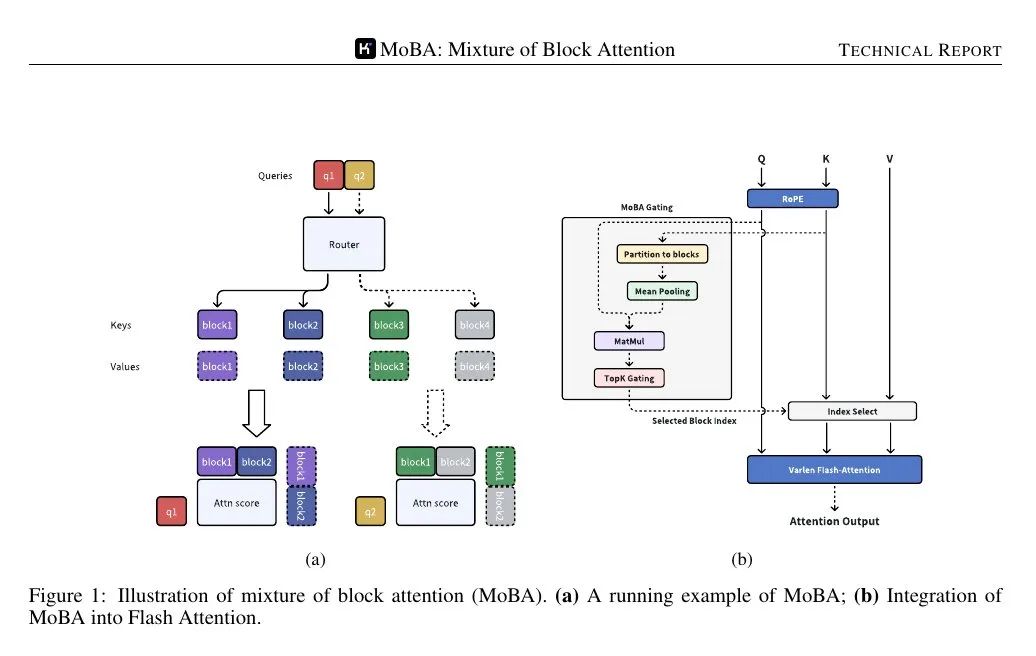
MoBA (Mixture of Block Attention) applique le concept de mélange d'experts au mécanisme d'attention. Le modèle divise la séquence d'entrée en plusieurs blocs, puis une fonction d'entraînement calcule le score de corrélation entre chaque élément de la requête et chaque bloc. Seuls les blocs ayant le score le plus élevé sont utilisés dans le calcul de l'attention, ce qui permet d'éviter de prêter attention à chaque élément de la séquence complète.
Les blocs sont définis en divisant la séquence en travées égales. Chaque jeton d'interrogation examine la représentation agrégée des clés dans chaque bloc (par exemple, à l'aide de la mise en commun des moyennes) et classe ensuite leur importance, en sélectionnant quelques blocs pour un calcul détaillé de l'attention. Le bloc contenant la requête est toujours sélectionné. Le masquage causal garantit que les jetons ne voient pas les informations futures, en maintenant un ordre de génération de gauche à droite.
📌 Passage en douceur d'une attention limitée à une attention totale
MoBA remplace le mécanisme d'attention standard, mais ne modifie pas le nombre de paramètres. Il est similaire au mécanisme d'attention standard Transformateur Les interfaces sont compatibles, de sorte que l'attention éparse et l'attention totale peuvent être commutées entre différentes couches ou phases de formation. Certaines couches peuvent réserver la pleine attention à des tâches spécifiques (par exemple, un réglage fin supervisé), tandis que la plupart des couches utilisent la MoBA pour réduire les coûts de calcul.
📌 Cela s'applique aux piles de transformateurs plus importantes, en remplaçant les appels d'attention standard. Le mécanisme de blocage garantit que chaque requête ne porte que sur un petit nombre de blocs. La causalité est gérée en filtrant les blocs futurs et en appliquant un masque local dans le bloc actuel de la requête.
📌 La figure ci-dessous montre que la requête n'est acheminée que vers quelques blocs "experts" de clés/valeurs, et non vers l'ensemble de la séquence. Le mécanisme de contrôle affecte chaque requête au bloc le plus pertinent, réduisant ainsi la complexité du calcul de l'attention de quadratique à subquadratique.
📌 Le mécanisme de contrôle calcule un score de corrélation entre chaque requête et la représentation cohésive de chaque bloc. Il sélectionne ensuite les k blocs les mieux notés pour chaque requête, quelle que soit leur position dans la séquence.
Étant donné que seuls quelques blocs sont traités par requête, le calcul est toujours subquadratique, mais le modèle peut toujours sauter à des jetons éloignés du bloc en cours si le score d'accès présente une forte corrélation.
Mise en œuvre de PyTorch
Ce pseudo-code divise les clés et les valeurs en blocs, calcule une représentation groupée moyenne de chaque bloc et calcule le score de validation (S) en multipliant la requête (Q) par la représentation groupée.
Il applique ensuite des masques causaux pour s'assurer que les requêtes ne peuvent pas se concentrer sur des blocs futurs, utilise l'opérateur top-k pour sélectionner les blocs les plus pertinents pour chaque requête et organise les données pour un calcul efficace de l'attention.
📌 FlashAttention ont été appliquées au bloc auto-attentif (position actuelle) et au bloc sélectionné par le MoBA, respectivement, et enfin les résultats ont été fusionnés à l'aide de la softmax en ligne.
Le résultat final est un mécanisme d'attention clairsemé qui préserve la structure causale et capture les dépendances à long terme tout en évitant le coût de calcul quadratique de l'attention standard.

Ce code combine la logique du mélange d'experts et l'attention éparse, de sorte que chaque requête ne porte que sur quelques blocs.
Le mécanisme de contrôle évalue chaque bloc et chaque requête et sélectionne les k meilleurs "experts", réduisant ainsi le nombre de comparaisons clé/valeur.
Cela permet de maintenir la charge de calcul de l'attention à un niveau subquadratique, ce qui permet de traiter des entrées extrêmement longues sans augmenter la charge de calcul ou de mémoire.
Dans le même temps, le mécanisme de blocage garantit que la requête peut encore se concentrer sur des éléments distants si nécessaire, préservant ainsi la capacité du transformateur à traiter le contexte global.
Cette stratégie basée sur les blocs et le gating est exactement la façon dont MoBA met en œuvre des contextes quasi-infinis dans LLM.

Observations expérimentales
Les modèles utilisant le MoBA sont presque comparables à l'attention totale en termes de perte de modélisation du langage et de performance des tâches en aval. Les résultats sont cohérents même avec des longueurs de contexte de centaines de milliers ou de millions de tokens. Les expériences évaluées avec des "tokens de queue" confirment que les dépendances importantes à longue distance sont toujours prises en compte lorsque la requête identifie les morceaux pertinents.
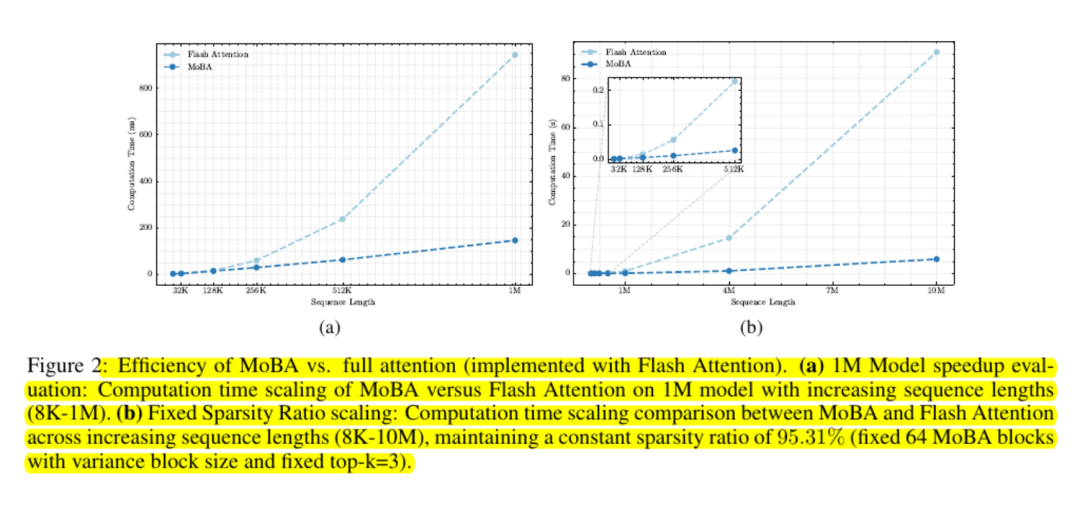
Les tests d'évolutivité montrent que sa courbe de coût est subquadratique. Les chercheurs signalent des accélérations allant jusqu'à six fois pour un million de jetons et des gains plus importants en dehors de cette fourchette.
MoBA préserve la mémoire en évitant l'utilisation de matrices d'attention complètes et en utilisant des noyaux GPU standard pour le calcul par blocs.
Observations finales
MoBA réduit la surcharge d'attention grâce à une idée simple : laisser la requête apprendre quels blocs sont importants et ignorer tous les autres.
Il préserve l'interface d'attention standard basée sur la softmax et évite d'imposer un modèle local rigide. De nombreux modèles linguistiques de grande taille peuvent intégrer ce mécanisme de manière prête à l'emploi.
Le MoBA est donc très intéressant pour les charges de travail qui doivent traiter des contextes extrêmement longs, tels que l'analyse d'une base de code entière ou le résumé de documents volumineux, sans avoir à apporter de modifications majeures aux poids de pré-entraînement ou à consommer beaucoup de frais généraux de réentraînement.

© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes

Pas de commentaires...