

KAG : Un cadre professionnel de questions-réponses sur les bases de connaissances pour la recherche hybride de graphes de connaissances et de vecteurs

Introduction générale
KAG (Knowledge Augmented Generation) est un cadre de raisonnement et de recherche guidés par la forme logique, basé sur le moteur OpenSPG et les grands modèles de langage (LLM). KAG améliore les LLM et les graphes de connaissances grâce aux forces complémentaires des graphes de connaissances et de la recherche vectorielle de quatre façons dans les deux sens : représentations de connaissances adaptées aux LLM, inter-indexation entre les graphes de connaissances et les fragments de texte brut, résolveur de raisonnement hybride, et résolveur de raisonnement hybride. Le cadre est particulièrement bien adapté à la gestion de l'indexation, des solveurs d'inférence hybrides et des mécanismes d'évaluation de la plausibilité. Le cadre est particulièrement bien adapté pour traiter des problèmes complexes de logique des connaissances tels que le calcul numérique, les relations temporelles et les règles d'expert, fournissant des capacités de réponse aux questions plus précises et plus fiables pour les applications dans les domaines professionnels.

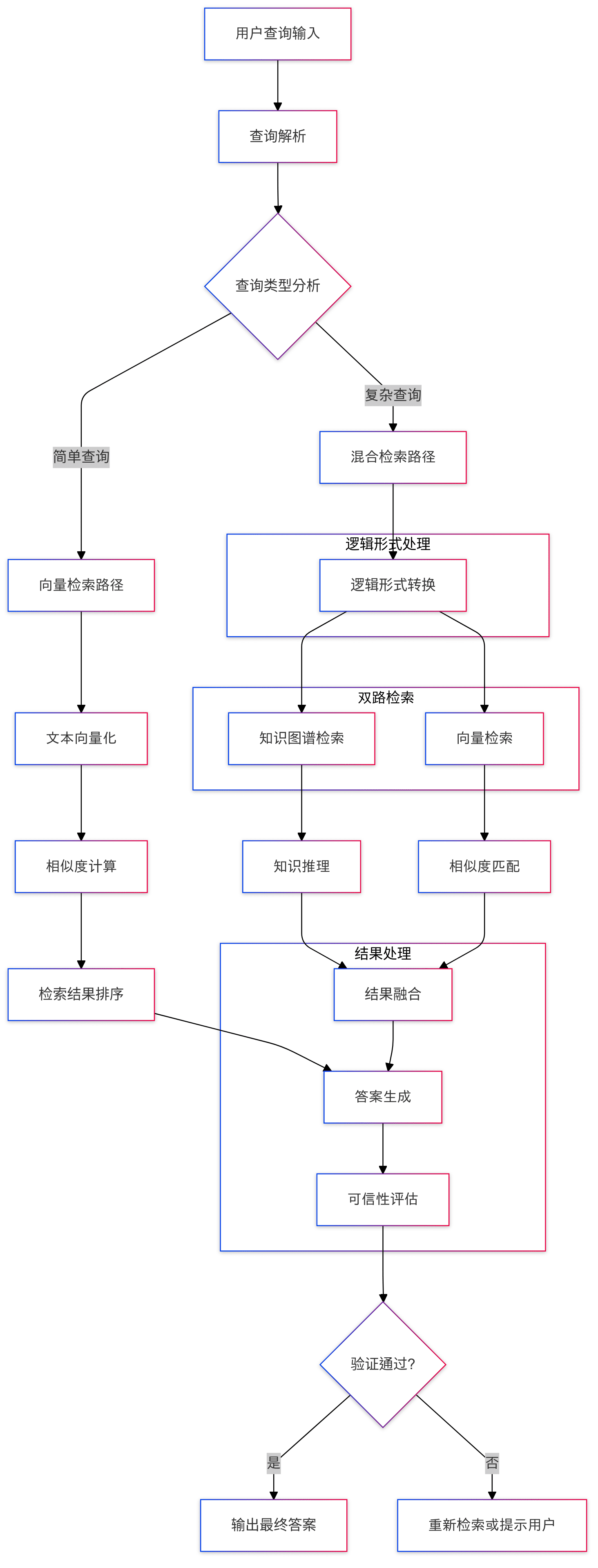
Liste des fonctions
- Capacité à soutenir des formes de raisonnement logiques complexes
- Fournir un mécanisme de recherche hybride de graphe de connaissances et de recherche vectorielle
- Mise en œuvre d'une conversion de la représentation des connaissances adaptée à LLM
- Prise en charge de l'indexation bidirectionnelle des structures de connaissance et des blocs de texte
- Intégration du raisonnement LLM, du raisonnement intellectuel et du raisonnement mathématique et logique
- Fournir des mécanismes d'évaluation et de validation de la crédibilité
- Prise en charge des questions et réponses multi-sauts et du traitement des requêtes complexes
- Fournir des solutions personnalisées pour les bases de connaissances des domaines spécialisés
Utiliser l'aide
1. préparation à l'environnement
La première chose à faire est de vous assurer que votre système répond aux exigences suivantes :
- Python 3.8 ou supérieur
- Environnement du moteur OpenSPG
- Interfaces API prises en charge pour les modèles linguistiques de grande taille
2. les étapes de l'installation
- Clonage de l'entrepôt de projets :
git clone https://github.com/OpenSPG/KAG.git
cd KAG
- Installer les paquets de dépendances :
pip install -r requirements.txt
3. processus d'utilisation du cadre
3.1 Préparation de la base de connaissances
- Importation de données de connaissances spécialisées
- Configuration du modèle de graphe de connaissances
- Mise en place d'un système d'indexation des textes
3.2 Traitement des requêtes
- Entrée de questions : le système reçoit des questions en langage naturel de la part de l'utilisateur.
- Conversion des formes logiques : conversion des problèmes en expressions logiques standardisées
- Récupération mixte :
- Effectuer des recherches dans les graphes de connaissances
- Effectuer une recherche de similarité vectorielle
- Intégration des résultats de recherche
3.3 Processus de raisonnement
- Raisonnement logique : raisonnement en plusieurs étapes avec des résolveurs de raisonnement mixtes
- Fusion des connaissances : combinaison des résultats du raisonnement LLM et du raisonnement par graphe de connaissances
- Génération de réponses : formation de la réponse finale
3.4 Assurance de la crédibilité
- Vérification des réponses
- Raisonnement Traçage du chemin
- évaluation de la confiance (math.)
4. utilisation des fonctions avancées
4.1 Représentation personnalisée des connaissances
Le format de représentation des connaissances peut être personnalisé en fonction des besoins de votre domaine d'expertise, ce qui garantit la compatibilité avec LLM :
# 示例代码
knowledge_config = {
"domain": "your_domain",
"schema": your_schema_definition,
"representation": your_custom_representation
}
4.2 Configuration des règles de raisonnement
Des règles d'inférence spécialisées peuvent être configurées pour gérer la logique propre à un domaine :
# 示例代码
reasoning_rules = {
"numerical": numerical_processing_rules,
"temporal": temporal_reasoning_rules,
"domain_specific": your_domain_rules
}
5. les bonnes pratiques
- Garantir la qualité et l'intégrité des données de la base de connaissances
- Optimiser les stratégies de recherche pour améliorer l'efficacité
- Mise à jour régulière et entretien de la base de connaissances
- Contrôler les performances et la précision du système
- Recueillir les commentaires des utilisateurs en vue d'une amélioration continue
6. la résolution des problèmes courants
- Si vous rencontrez des problèmes d'efficacité d'extraction, vous pouvez ajuster les paramètres de l'index de manière appropriée
- Pour les requêtes complexes, une stratégie de raisonnement par étapes peut être utilisée
- Vérifier la représentation des connaissances et la configuration des règles lorsque les résultats de l'inférence sont inexacts
Présentation du projet KAG
1. introduction
Il y a quelques jours, Ant a officiellement publié un cadre de service de connaissance de domaine professionnel, appelé Knowledge Augmented Generation (KAG : Knowledge Augmented Generation), qui vise à exploiter pleinement les avantages des graphes de connaissance et de la recherche vectorielle pour résoudre le problème des systèmes d'information existants. RAG Quelques difficultés avec la pile technologique.
Depuis les fourmis de ce cadre d'échauffement, j'ai été plus intéressé par certaines des fonctions centrales du KAG, en particulier le raisonnement symbolique logique et l'alignement des connaissances, dans le système RAG dominant existant, ces deux points de discussion ne semblent pas être trop, profiter de cette source ouverte, et se hâter d'étudier une vague.
- Adresse de la thèse de KAG : https://arxiv.org/pdf/2409.13731
- Adresse du projet KAG : https://github.com/OpenSPG/KAG
2. aperçu du cadre
Avant de lire le code, examinons brièvement les objectifs et le positionnement du cadre.
2.1 Quoi et pourquoi ?
En fait, lorsque je vois le cadre KAG, je pense que la première question qui vient à l'esprit de nombreuses personnes est de savoir pourquoi il ne s'appelle pas RAG mais KAG. D'après des articles et des documents connexes, le cadre KAG est principalement conçu pour résoudre certains des défis actuels auxquels sont confrontés les grands modèles dans les services de connaissance des domaines professionnels :
- LLM n'a pas la capacité de penser de manière critique et manque de compétences en matière de raisonnement
- Erreurs de fait, de logique, de précision, incapacité d'utiliser des structures de connaissance du domaine prédéfinies pour limiter le comportement du modèle.
- Les RAG génériques ont également du mal à traiter les illusions du LLM, en particulier les informations trompeuses dissimulées.
- Défis et exigences des services d'expertise, absence de processus décisionnel rigoureux et contrôlé
Par conséquent, l'équipe Fourmi estime qu'un cadre de services de connaissances professionnelles doit présenter les caractéristiques suivantes :
- Il est important de garantir l'exactitude des connaissances, y compris l'intégrité des limites des connaissances et la clarté de la structure et de la sémantique des connaissances ;
- La rigueur logique, la sensibilité au temps et la sensibilité numérique sont nécessaires ;
- Des informations contextuelles complètes sont également nécessaires pour faciliter l'accès à des informations complémentaires complètes lors de la prise de décisions fondées sur la connaissance ;
Le positionnement officiel de KAG par Ant est : Professional Domain Knowledge Augmentation Service Framework, spécifiquement pour la combinaison actuelle de grands modèles de langage et de graphes de connaissances afin d'améliorer les cinq domaines suivants
- Meilleure connaissance de la convivialité du LLM
- Structure d'inter-indexation entre les graphes de connaissances et les fragments de textes originaux
- Moteur de raisonnement hybride guidé par les symboles logiques
- Mécanisme d'alignement des connaissances basé sur le raisonnement sémantique
- Modèle KAG
Cette version open-source couvre les quatre premières fonctionnalités de base dans leur intégralité.
Pour en revenir à la question de la dénomination des KAG, je pense personnellement qu'il s'agit encore de renforcer le concept d'ontologie de la connaissance. D'après la description officielle et la mise en œuvre réelle du code, le cadre KAG, que ce soit au stade de la construction ou du raisonnement, met constamment l'accent sur la connaissance elle-même, pour construire un lien logique complet et rigoureux, afin d'améliorer autant que possible certains des problèmes connus de la pile technologique RAG.
2.2 Qu'est-ce qui est réalisé (comment) ?
Le cadre KAG se compose de trois parties : KAG-Builder, KAG-Solver et KAG-Model :
- KAG-Builder est utilisé pour l'indexation hors ligne et comprend les caractéristiques 1 et 2 mentionnées ci-dessus : amélioration de la représentation des connaissances, structure d'indexation mutuelle.
- Le module KAG-Solver couvre les caractéristiques 3 et 4 : moteur de raisonnement hybride logique-symbolique, mécanisme d'alignement des connaissances.
- KAG-Model tente de construire un modèle KAG de bout en bout.
3. l'analyse du code source
Cette source ouverte comprend principalement deux modules KAG-Builder et KAG-Solver, correspondant directement au code source des deux sous-répertoires builder et solver.
Lors de l'étude proprement dite du code, il est recommandé de commencer par la rubrique examples La première chose à faire est de commencer par un répertoire pour comprendre le fonctionnement de l'ensemble du cadre, puis d'approfondir les modules spécifiques. Les chemins vers les fichiers d'entrée de plusieurs démos sont similaires, comme par exemple kag/examples/medicine/builder/indexer.py aussi kag/examples/medicine/solver/evaForMedicine.pyIl est clair que le constructeur combine différents modules, alors que le véritable point d'entrée du solveur se trouve dans le module kag/solver/logic/solver_pipeline.py.
3.1 KAG-Builder
Commençons par afficher la structure complète du catalogue
❯ tree .
.
├── __init__.py
├── component
│ ├── __init__.py
│ ├── aligner
│ │ ├── __init__.py
│ │ ├── kag_post_processor.py
│ │ └── spg_post_processor.py
│ ├── base.py
│ ├── extractor
│ │ ├── __init__.py
│ │ ├── kag_extractor.py
│ │ ├── spg_extractor.py
│ │ └── user_defined_extractor.py
│ ├── mapping
│ │ ├── __init__.py
│ │ ├── relation_mapping.py
│ │ ├── spg_type_mapping.py
│ │ └── spo_mapping.py
│ ├── reader
│ │ ├── __init__.py
│ │ ├── csv_reader.py
│ │ ├── dataset_reader.py
│ │ ├── docx_reader.py
│ │ ├── json_reader.py
│ │ ├── markdown_reader.py
│ │ ├── pdf_reader.py
│ │ ├── txt_reader.py
│ │ └── yuque_reader.py
│ ├── splitter
│ │ ├── __init__.py
│ │ ├── base_table_splitter.py
│ │ ├── length_splitter.py
│ │ ├── outline_splitter.py
│ │ ├── pattern_splitter.py
│ │ └── semantic_splitter.py
│ ├── vectorizer
│ │ ├── __init__.py
│ │ └── batch_vectorizer.py
│ └── writer
│ ├── __init__.py
│ └── kg_writer.py
├── default_chain.py
├── model
│ ├── __init__.py
│ ├── chunk.py
│ ├── spg_record.py
│ └── sub_graph.py
├── operator
│ ├── __init__.py
│ └── base.py
└── prompt
├── __init__.py
├── analyze_table_prompt.py
├── default
│ ├── __init__.py
│ ├── ner.py
│ ├── std.py
│ └── triple.py
├── medical
│ ├── __init__.py
│ ├── ner.py
│ ├── std.py
│ └── triple.py
├── oneke_prompt.py
├── outline_prompt.py
├── semantic_seg_prompt.py
└── spg_prompt.py
La section Builder couvre un large éventail de fonctionnalités, nous nous contenterons donc d'examiner l'un des composants les plus importants. KAGExtractor L'organigramme de base est présenté ci-dessous :

Il s'agit principalement ici de la création automatique d'un graphe de connaissances à partir d'un texte non structuré vers des connaissances structurées à l'aide d'un grand modèle, avec une brève description de certaines des étapes importantes impliquées.
- Tout d'abord, il y a le module de reconnaissance des entités, dans lequel la reconnaissance des entités spécifiques sera effectuée en premier lieu pour les types de graphes de connaissances prédéfinis, suivie de la reconnaissance des entités nommées génériques. Ce mécanisme d'identification à deux niveaux devrait garantir que les entités spécifiques à un domaine sont capturées et que les entités génériques ne sont pas oubliées.
- Le processus de construction de la cartographie est en fait réalisé par la
assemble_sub_graph_with_spg_recordsCette méthode est spéciale en ce sens que le système convertit les attributs de type non basique en nœuds et en arêtes dans le graphe, au lieu de continuer à les conserver en tant qu'attributs d'origine de l'entité. Ce changement n'est honnêtement pas très bien compris et, dans une certaine mesure, il est censé simplifier la complexité de l'entité, mais dans la pratique, il n'est pas évident de savoir quel avantage cette stratégie apporte, la complexité de la construction a certainement augmenté. - Normalisation des entités par
named_entity_standardizationrépondre en chantantappend_official_nameLes deux approches sont menées de concert. Les noms d'entités sont d'abord normalisés, puis ces noms normalisés sont associés aux informations d'origine sur les entités. Ce processus est similaire à la résolution d'entités.
Dans l'ensemble, la fonctionnalité du module Builder est assez proche de la pile technologique courante de construction de graphes, et les articles et le code associés ne sont pas trop difficiles à comprendre, je ne les répéterai donc pas ici.
3.2 KAG-Solver
La partie solveur du cadre implique un grand nombre de points fonctionnels essentiels, en particulier la logique du contenu lié au raisonnement symbolique, il faut d'abord examiner la structure globale :
❯ tree .
.
├── __init__.py
├── common
│ ├── __init__.py
│ └── base.py
├── implementation
│ ├── __init__.py
│ ├── default_generator.py
│ ├── default_kg_retrieval.py
│ ├── default_lf_planner.py
│ ├── default_memory.py
│ ├── default_reasoner.py
│ ├── default_reflector.py
│ └── lf_chunk_retriever.py
├── logic
│ ├── __init__.py
│ ├── core_modules
│ │ ├── __init__.py
│ │ ├── common
│ │ │ ├── __init__.py
│ │ │ ├── base_model.py
│ │ │ ├── one_hop_graph.py
│ │ │ ├── schema_utils.py
│ │ │ ├── text_sim_by_vector.py
│ │ │ └── utils.py
│ │ ├── config.py
│ │ ├── lf_executor.py
│ │ ├── lf_generator.py
│ │ ├── lf_solver.py
│ │ ├── op_executor
│ │ │ ├── __init__.py
│ │ │ ├── op_deduce
│ │ │ │ ├── __init__.py
│ │ │ │ ├── deduce_executor.py
│ │ │ │ └── module
│ │ │ │ ├── __init__.py
│ │ │ │ ├── choice.py
│ │ │ │ ├── entailment.py
│ │ │ │ ├── judgement.py
│ │ │ │ └── multi_choice.py
│ │ │ ├── op_executor.py
│ │ │ ├── op_math
│ │ │ │ ├── __init__.py
│ │ │ │ └── math_executor.py
│ │ │ ├── op_output
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── get_executor.py
│ │ │ │ └── output_executor.py
│ │ │ ├── op_retrieval
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── get_spo_executor.py
│ │ │ │ │ └── search_s.py
│ │ │ │ └── retrieval_executor.py
│ │ │ └── op_sort
│ │ │ ├── __init__.py
│ │ │ └── sort_executor.py
│ │ ├── parser
│ │ │ ├── __init__.py
│ │ │ └── logic_node_parser.py
│ │ ├── retriver
│ │ │ ├── __init__.py
│ │ │ ├── entity_linker.py
│ │ │ ├── graph_retriver
│ │ │ │ ├── __init__.py
│ │ │ │ ├── dsl_executor.py
│ │ │ │ └── dsl_model.py
│ │ │ ├── retrieval_spo.py
│ │ │ └── schema_std.py
│ │ └── rule_runner
│ │ ├── __init__.py
│ │ └── rule_runner.py
│ └── solver_pipeline.py
├── main_solver.py
├── prompt
│ ├── __init__.py
│ ├── default
│ │ ├── __init__.py
│ │ ├── deduce_choice.py
│ │ ├── deduce_entail.py
│ │ ├── deduce_judge.py
│ │ ├── deduce_multi_choice.py
│ │ ├── logic_form_plan.py
│ │ ├── question_ner.py
│ │ ├── resp_extractor.py
│ │ ├── resp_generator.py
│ │ ├── resp_judge.py
│ │ ├── resp_reflector.py
│ │ ├── resp_verifier.py
│ │ ├── solve_question.py
│ │ ├── solve_question_without_docs.py
│ │ ├── solve_question_without_spo.py
│ │ └── spo_retrieval.py
│ ├── lawbench
│ │ ├── __init__.py
│ │ └── logic_form_plan.py
│ └── medical
│ ├── __init__.py
│ └── question_ner.py
└── tools
├── __init__.py
└── info_processor.py
J'ai déjà mentionné le fichier d'entrée du solveur, je vais donc poster le code correspondant ici :
class SolverPipeline:
def __init__(self, max_run=3, reflector: KagReflectorABC = None, reasoner: KagReasonerABC = None,
generator: KAGGeneratorABC = None, **kwargs):
"""
Initializes the think-and-act loop class.
:param max_run: Maximum number of runs to limit the thinking and acting loop, defaults to 3.
:param reflector: Reflector instance for reflect tasks.
:param reasoner: Reasoner instance for reasoning about tasks.
:param generator: Generator instance for generating actions.
"""
self.max_run = max_run
self.memory = DefaultMemory(**kwargs)
self.reflector = reflector or DefaultReflector(**kwargs)
self.reasoner = reasoner or DefaultReasoner(**kwargs)
self.generator = generator or DefaultGenerator(**kwargs)
self.trace_log = []
def run(self, question):
"""
Executes the core logic of the problem-solving system.
Parameters:
- question (str): The question to be answered.
Returns:
- tuple: answer, trace log
"""
instruction = question
if_finished = False
logger.debug('input instruction:{}'.format(instruction))
present_instruction = instruction
run_cnt = 0
while not if_finished and run_cnt < self.max_run:
run_cnt += 1
logger.debug('present_instruction is:{}'.format(present_instruction))
# Attempt to solve the current instruction and get the answer, supporting facts, and history log
solved_answer, supporting_fact, history_log = self.reasoner.reason(present_instruction)
# Extract evidence from supporting facts
self.memory.save_memory(solved_answer, supporting_fact, instruction)
history_log['present_instruction'] = present_instruction
history_log['present_memory'] = self.memory.serialize_memory()
self.trace_log.append(history_log)
# Reflect the current instruction based on the current memory and instruction
if_finished, present_instruction = self.reflector.reflect_query(self.memory, present_instruction)
response = self.generator.generate(instruction, self.memory)
return response, self.trace_log
total SolverPipeline.run() La méthodologie comprend trois modules principaux :Reasoner, Reflector répondre en chantant GeneratorLa logique générale reste très claire : il faut d'abord essayer de répondre à la question, puis se demander si le problème a été résolu et, si ce n'est pas le cas, continuer à réfléchir en profondeur jusqu'à ce que l'on obtienne une réponse satisfaisante ou que l'on atteigne le nombre maximum de tentatives. Il s'agit essentiellement d'imiter le mode de pensée général de l'être humain lorsqu'il s'agit de résoudre des problèmes complexes.
La section suivante analyse plus en détail les trois modules mentionnés ci-dessus.
3.3 Raisonneur
Le module d'inférence est probablement la partie la plus complexe de l'ensemble du cadre, et son code clé est le suivant :
class DefaultReasoner(KagReasonerABC):
def __init__(self, lf_planner: LFPlannerABC = None, lf_solver: LFSolver = None, **kwargs):
def reason(self, question: str):
"""
Processes a given question by planning and executing logical forms to derive an answer.
Parameters:
- question (str): The input question to be processed.
Returns:
- solved_answer: The final answer derived from solving the logical forms.
- supporting_fact: Supporting facts gathered during the reasoning process.
- history_log: A dictionary containing the history of QA pairs and re-ranked documents.
"""
# logic form planing
lf_nodes: List[LFPlanResult] = self.lf_planner.lf_planing(question)
# logic form execution
solved_answer, sub_qa_pair, recall_docs, history_qa_log = self.lf_solver.solve(question, lf_nodes)
# Generate supporting facts for sub question-answer pair
supporting_fact = '\n'.join(sub_qa_pair)
# Retrieve and rank documents
sub_querys = [lf.query for lf in lf_nodes]
if self.lf_solver.chunk_retriever:
docs = self.lf_solver.chunk_retriever.rerank_docs([question] + sub_querys, recall_docs)
else:
logger.info("DefaultReasoner not enable chunk retriever")
docs = []
history_log = {
'history': history_qa_log,
'rerank_docs': docs
}
if len(docs) > 0:
# Append supporting facts for retrieved chunks
supporting_fact += f"\nPassages:{str(docs)}"
return solved_answer, supporting_fact, history_log
Il en résulte un organigramme global du module de raisonnement : (la logique telle que la gestion des erreurs a été omise).

Il est facile de constater queDefaultReasoner.reason() La méthodologie est divisée en trois étapes :
- Planification des formes logiques (LFP) : il s'agit principalement de
LFPlanner.lf_planing - Exécution de la forme logique (LFE) : il s'agit principalement de
LFSolver.solve - Reranking de documents : il s'agit principalement de
LFSolver.chunk_retriever.rerank_docs
Chacune des trois étapes est analysée en détail ci-dessous.
3.3.1 Planification du formulaire logique
DefaultLFPlanner.lf_planing() est principalement utilisée pour décomposer une requête en une série de formes logiques indépendantes (lf_nodes: List[LFPlanResult]).
lf_nodes: List[LFPlanResult] = self.lf_planner.lf_planing(question)
La logique de mise en œuvre se trouve dans kag/solver/implementation/default_lf_planner.pyL'accent est mis sur llm_output Effectuer une analyse syntaxique régularisée ou appeler LLM pour générer une nouvelle forme logique si elle n'est pas fournie.
Voici ce qu'il faut surveiller kag/solver/prompt/default/logic_form_plan.py questions pertinentes LogicFormPlanPrompt La conception détaillée du projet est axée sur la décomposition d'un problème complexe en plusieurs sous-requêtes et leurs formes logiques correspondantes.
3.3.2 Exécution du formulaire logique
LFSolver.solve() Les méthodes sont utilisées pour résoudre des problèmes de forme logique spécifiques, en renvoyant des réponses, des paires de réponses à des sous-problèmes, des documents de rappel et des historiques associés, etc.
solved_answer, sub_qa_pair, recall_docs, history_qa_log = self.lf_solver.solve(question, lf_nodes)
en profondeurkag/solver/logic/core_modules/lf_solver.pyLa section du code source, qui peut être trouvée LFSolver La classe (Logical Form Solver) est la classe centrale de l'ensemble du processus de raisonnement et est responsable de l'exécution de la forme logique (LF) et de la génération de la réponse :
- Les principales méthodes sont les suivantes
solvequi reçoit une requête et un ensemble de nœuds de forme logique (List[LFPlanResult]). - utiliser
LogicExecutorpour exécuter des formes logiques qui génèrent des réponses, des chemins de graphe de connaissances et des historiques. - Traite les sous-requêtes et les paires de réponses, ainsi que la documentation correspondante.
- Gestion des erreurs et stratégie de repli : si aucune réponse ou documentation pertinente n'est trouvée, on tente d'utiliser la fonction
chunk_retrieverRappeler les documents connexes.
Les principaux processus sont les suivants :

Parmi ceux-ci LogicExecutor est l'une des classes les plus critiques, et le code de base est publié ici :
executor = LogicExecutor(
query, self.project_id, self.schema,
kg_retriever=self.kg_retriever,
chunk_retriever=self.chunk_retriever,
std_schema=self.std_schema,
el=self.el,
text_similarity=self.text_similarity,
dsl_runner=DslRunnerOnGraphStore(...),
generator=self.generator,
report_tool=self.report_tool,
req_id=generate_random_string(10)
)
kg_qa_result, kg_graph, history = executor.execute(lf_nodes, query)
- logique de mise en œuvre
LogicExecutorLe code correspondant à la classe se trouve dans le fichierkag/solver/logic/core_modules/lf_executor.py. sonexecuteLe flux d'exécution principal de la méthode est présenté ci-dessous.
Ce flux d'exécution démontre une double stratégie d'extraction : donner la priorité à l'utilisation de données graphiques structurées pour l'extraction et l'inférence, et revenir à l'extraction d'informations textuelles non structurées lorsque le graphique ne permet pas de répondre.
Le système tente d'abord de répondre à la question à travers le graphe de connaissances, pour chaque nœud d'expression logique, à l'aide de différents actionneurs (impliquant lededuce,math,sort,retrieval,outputetc.) sont traités, et le processus de recherche recueille des triples SPO (sujet-prédicat-objet) pour la génération ultérieure de réponses ; lorsque le graphique ne fournit pas de réponse satisfaisante (en renvoyant "Je ne sais pas"), le système revient à la recherche par bloc de texte : en utilisant les résultats d'entités nommées (NER) obtenus précédemment comme point d'ancrage de la recherche, et en les combinant avec les enregistrements historiques de Q&R pour construire une requête améliorée par le contexte, qui est ensuite passée par le système de recherche par bloc de texte (SPO).chunk_retrieverGénérer à nouveau la réponse sur la base du document récupéré.
L'ensemble du processus peut être considéré comme une élégante stratégie de dégradation et, en combinant des graphes de connaissances structurés avec des données textuelles non structurées, cette recherche hybride est capable de fournir des réponses aussi complètes et contextuellement cohérentes que possible tout en maintenant la précision. - composante essentielle
Outre la logique de mise en œuvre spécifique décrite ci-dessus, il convient de noter que la fonctionLogicExecutorL'initialisation nécessite le passage de plusieurs composants. Par manque de place, nous ne donnons ici qu'une brève description de la fonction principale de chaque composant, l'implémentation spécifique pouvant se référer au code source.- kg_retriever : récupérateur de graphes de connaissances
consultationkag/solver/implementation/default_kg_retrieval.pymilieuKGRetrieverByLlm(KGRetrieverABC)qui met en œuvre la recherche d'entités et de relations, en faisant appel à plusieurs méthodes d'appariement telles que les sous-graphes exacts/fuzzy et les sous-graphes à un seul saut. - chunk_retriever : récupérateur de morceaux de texte
consultationkag/common/retriever/kag_retriever.pymilieuDefaultRetriever(ChunkRetrieverABC)Le code ici mérite d'être étudié, tout d'abord parce qu'il est normalisé en termes de traitement des entités et, en outre, parce que la recherche se réfère ici à HippoRAG, en adoptant une stratégie de recherche hybride combinant DPR (Dense Passage Retrieval) et PPR (Personalized PageRank), puis en se basant sur la fusion des scores DPR et PPR. En outre, une stratégie de recherche hybride combinant DPR (Dense Passage Retrieval) et PPR (Personalised PageRank) est adoptée ici, et la fusion ultérieure des scores basés sur DPR et PPR permet de réaliser l'allocation dynamique des poids des deux méthodes de recherche. - entity_linker (el) : lien de l'entité
consultationkag/solver/logic/core_modules/retriver/entity_linker.pymilieuDefaultEntityLinker(EntityLinkerBase)L'idée de construire des caractéristiques avant de paralléliser le traitement des liens entre entités est utilisée ici. - dsl_runner : interrogateur de base de données de graphes
consultationkag/solver/logic/core_modules/retriver/graph_retriver/dsl_executor.pymilieuDslRunnerOnGraphStore(DslRunner)Il est responsable des informations de requête structurées dans une déclaration de requête de base de données graphique spécifique, ce qui implique la base de données graphique spécifique sous-jacente, les détails de la base de données relativement complexes, mais pas trop impliqués.
- kg_retriever : récupérateur de graphes de connaissances
En parcourant le code et l'organigramme ci-dessus, on constate que l'ensemble de la boucle d'exécution des formulaires logiques (LFE) adopte une architecture de traitement hiérarchique :
- le sommet d'un bâtiment
LFSolverResponsable de l'ensemble du processus - mésosphère
LogicExecutorResponsable de la mise en œuvre de formes logiques spécifiques (LF) - fond (d'une pile)
DSL RunnerResponsable de l'interaction avec la base de données graphique
3.3.3 Reranking des documents
Si le chunk_retrieverLa fonction de réorganisation de l'ordre des documents rappelés est également activée.
if self.lf_solver.chunk_retriever:
docs = self.lf_solver.chunk_retriever.rerank_docs(
[question] + sub_querys, recall_docs
)
3.4 Réflecteur
Reflector implémente principalement la classe _can_answer avec _refine_query Deux méthodes, la première pour déterminer s'il est possible de répondre à une question et la seconde pour optimiser les résultats intermédiaires d'une requête multi-sauts afin de guider la génération de la réponse finale.
Références relatives à la mise en œuvre kag/solver/prompt/default/resp_judge.py avec kag/solver/prompt/default/resp_reflector.py Ces deux fichiers Prompt sont plus faciles à comprendre.
3.5 Générateur
agrafe LFGenerator sélectionne dynamiquement des modèles de mots guides en fonction de différents scénarios (avec ou sans graphes de connaissances, avec ou sans documents, etc.) et génère des réponses aux questions correspondantes.
Les implémentations correspondantes se trouvent dans la base de données kag/solver/logic/core_modules/lf_generator.pyLe code est relativement intuitif et ne sera pas répété.
4. quelques réflexions
Dans ce cadre KAG open source, axé sur les services d'amélioration des connaissances professionnelles, couvrant le raisonnement symbolique, l'alignement des connaissances et une série de points innovants, une étude approfondie, je pense que le cadre est particulièrement adapté à la nécessité de contraintes strictes sur le schéma des connaissances professionnelles du scénario, que ce soit à l'étape de l'indexation ou de l'interrogation, l'ensemble du flux de travail est sans cesse renforcé d'un point de vue : vous devez être à partir des contraintes de la base de connaissances, de construire les graphiques ou de faire le raisonnement logique. graphes ou faire du raisonnement logique. Cet état d'esprit devrait atténuer dans une certaine mesure le problème de la connaissance manquante du domaine ainsi que l'illusion des grands modèles.
Depuis que le cadre GraphRAG de Microsoft a été mis en libre accès, la communauté a davantage réfléchi à l'intégration des graphes de connaissances et à la pile technologique RAG, comme le montrent les travaux récents de LightRAG, StructRAG, etc. qui ont permis de réaliser de nombreuses explorations utiles.KAG, bien qu'il existe certaines différences entre la voie technique et GraphRAG, peut être considéré dans une certaine mesure comme une pratique en direction des services d'amélioration des connaissances dans le domaine professionnel de GraphRAG, en particulier pour combler les lacunes en matière d'alignement et de raisonnement des connaissances. Bien qu'il y ait quelques différences entre KAG et GraphRAG en termes de technologie, KAG peut être considéré comme une pratique de GraphRAG dans le sens des services d'amélioration des connaissances dans les domaines professionnels, en particulier pour combler les lacunes en matière d'alignement des connaissances et de raisonnement. De ce point de vue, je préfère personnellement l'appeler Knowledge constrained GraphRAG.
GraphRAG natif, avec un résumé hiérarchique basé sur différentes communautés, peut répondre à des questions relativement abstraites de haut niveau, mais aussi en raison de l'accent excessif mis sur le résumé axé sur les requêtes (QFS), le cadre peut ne pas être performant sur des questions factuelles à grain fin, et compte tenu de la question du coût, le GraphRAG natif a beaucoup de défis à relever dans le domaine des pendants. GraphRAG présente de nombreux défis dans le domaine des pendants, alors que le cadre KAG a réalisé davantage d'optimisations à partir de l'étape de construction du graphe, comme l'alignement des entités et les opérations de normalisation basées sur un schéma spécifique, et à l'étape de l'interrogation, il introduit également le raisonnement de graphe de connaissances basé sur la logique symbolique, bien que le raisonnement symbolique ait fait l'objet de recherches dans le domaine des graphes depuis un certain temps, mais il n'a pas encore été réellement appliqué aux scénarios de RAG. Le renforcement de la capacité de raisonnement des RAG est une direction de recherche sur laquelle l'auteur est plus optimiste, et il y a quelque temps, Microsoft a résumé les quatre couches de capacité de raisonnement de la pile technologique des RAG :
- Niveau 1 : Faits explicites, Faits explicites
- Niveau 2 Faits implicites, faits cachés
- Raisons d'être interprétables de niveau 3, raisons d'être interprétables (pendants)
- Niveau 4 Raisons cachées, raisons invisibles (domaine suspendu)
Actuellement, la capacité de raisonnement de la plupart des cadres RAG est encore limitée au niveau 1, et les niveaux 3 et 4 ci-dessus soulignent l'importance du raisonnement vertical, et la difficulté réside dans le manque de connaissance des grands modèles dans le domaine vertical, et l'introduction du raisonnement symbolique dans l'étape d'interrogation du cadre KAG peut être considérée comme une exploration de cette direction dans une certaine mesure, et on peut prévoir qu'une vague de nouvelles recherches sera menée dans les années à venir dans le domaine du raisonnement RAG. On peut s'attendre à ce que le raisonnement RAG déclenche une nouvelle vague de recherche, telle que la fusion de la capacité de raisonnement propre au modèle, comme RL ou CoT, etc.
En plus de la session de raisonnement, les références du KAG dans Retrieval HippoRAG L'adoption d'une stratégie de recherche hybride DPR et PPR et l'utilisation efficace du PageRank démontrent les avantages des graphes de connaissances par rapport à la recherche vectorielle traditionnelle, et l'on pense que d'autres algorithmes de recherche de graphes seront intégrés dans la pile technologique RAG à l'avenir.
Bien entendu, on estime que le cadre KAG en est encore au stade de l'itération précoce et rapide, et qu'il y a encore matière à discussion sur la mise en œuvre concrète des fonctions, par exemple pour savoir si la forme logique de planification et la forme logique d'exécution existantes bénéficient d'un soutien théorique complet au niveau de la conception, et s'il n'y aura pas de décomposition insuffisante et d'échec de l'exécution face à des problèmes complexes. S'il y aura une décomposition insuffisante, un échec de l'exécution, mais cette définition des limites et les questions de robustesse sont généralement très difficiles à traiter, mais nécessitent également beaucoup de coûts d'essais et d'erreurs, si l'ensemble de la chaîne de raisonnement est trop complexe, le taux d'échec final peut être plus élevé, après tout, une variété de dégradation de la stratégie n'est qu'un certain degré d'atténuation du problème. En outre, j'ai remarqué que le GraphStore au bas du cadre a en fait réservé une interface de mise à jour incrémentale, mais que l'application de la couche supérieure n'a pas montré les capacités pertinentes, ce qui est également une caractéristique que je comprends personnellement que la communauté GraphRAG demande plus fortement.
Dans l'ensemble, le cadre KAG est considéré comme un travail très important réalisé récemment, contenant de nombreux points innovants, et le code a vraiment été peaufiné, ce qui est considéré comme un élan important pour le processus d'atterrissage de la pile technologique RAG.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...