Découvrir l'illusion du grand modèle : les classements des établissements d'enseignement supérieur donnent un aperçu de l'état de la cohérence des faits dans le cadre du LLM

Bien que les capacités des grands modèles linguistiques (LLM) soient en constante évolution, le phénomène des erreurs factuelles ou des "illusions" d'informations sans rapport avec le texte original dans leurs résultats a toujours été un défi majeur qui a empêché leur utilisation plus large et une confiance plus profonde. Afin d'évaluer quantitativement ce problème, l'étudeClassement du modèle d'évaluation des hallucinations de Hughes (HHEM)a été créé pour mesurer la fréquence des phantasmes dans les MLD classiques lors de la génération de résumés de documents.
Le terme "illusion" se réfère au fait que le modèle introduit des "faits" dans le résumé qui ne sont pas contenus dans le document original, voire qui sont contradictoires. Il s'agit d'un goulot d'étranglement critique en matière de qualité pour les scénarios de traitement de l'information qui s'appuient sur la LLM, en particulier ceux qui sont basés sur la Génération Augmentée de Récupération (RAG). En effet, si le modèle n'est pas fidèle à l'information donnée, la crédibilité de son résultat est fortement réduite.
Comment fonctionne HHEM ?
Le classement utilise le modèle d'évaluation des hallucinations HHEM-2.1 développé par Vectara. Pour un document source et un résumé généré par un LLM particulier, le modèle HHEM produit un score d'hallucination entre 0 et 1. Plus le score est proche de 1, plus la cohérence factuelle du résumé avec le document source est élevée ; plus il est proche de 0, plus l'hallucination est grave, voire le contenu complètement fabriqué.Vectara fournit également une version open-source, HHEM-2.1-Open, pour que les chercheurs et les développeurs puissent effectuer l'évaluation localement, et ses cartes de modèle sont publiées sur la plateforme Hugging Face.
Critères d'évaluation
L'équipe du projet a généré un résumé pour chaque document en utilisant les LLM individuels impliqués dans l'évaluation, et a ensuite calculé le score HHEM pour chaque paire (document source, résumé généré). Pour garantir la standardisation de l'évaluation, tous les appels de modèle ont été réglés sur temperature Le paramètre est égal à 0 et vise à obtenir la sortie la plus déterministe du modèle.
Les indicateurs d'évaluation comprennent notamment
- Taux d'hallucination. Pourcentage de résumés dont le score HHEM est inférieur à 0,5. Plus la valeur est faible, mieux c'est.
- Taux de cohérence des faits. 100% moins le taux d'hallucinations, reflétant la proportion de résumés dont le contenu est fidèle à l'original.
- Taux de réponse. Pourcentage de modèles générant avec succès des résumés non vides. Certains modèles peuvent refuser de répondre ou faire des erreurs en raison de politiques de sécurité du contenu ou pour d'autres raisons.
- Longueur moyenne du résumé. Le nombre moyen de mots dans les résumés générés fournit une vue latérale du style de sortie du modèle.
LLM Illusions Interprétation du classement
Vous trouverez ci-dessous les classements des hallucinations LLM basés sur l'évaluation du modèle HHEM-2.1 (données au 25 mars 2025, veuillez vous référer à la mise à jour actuelle) :
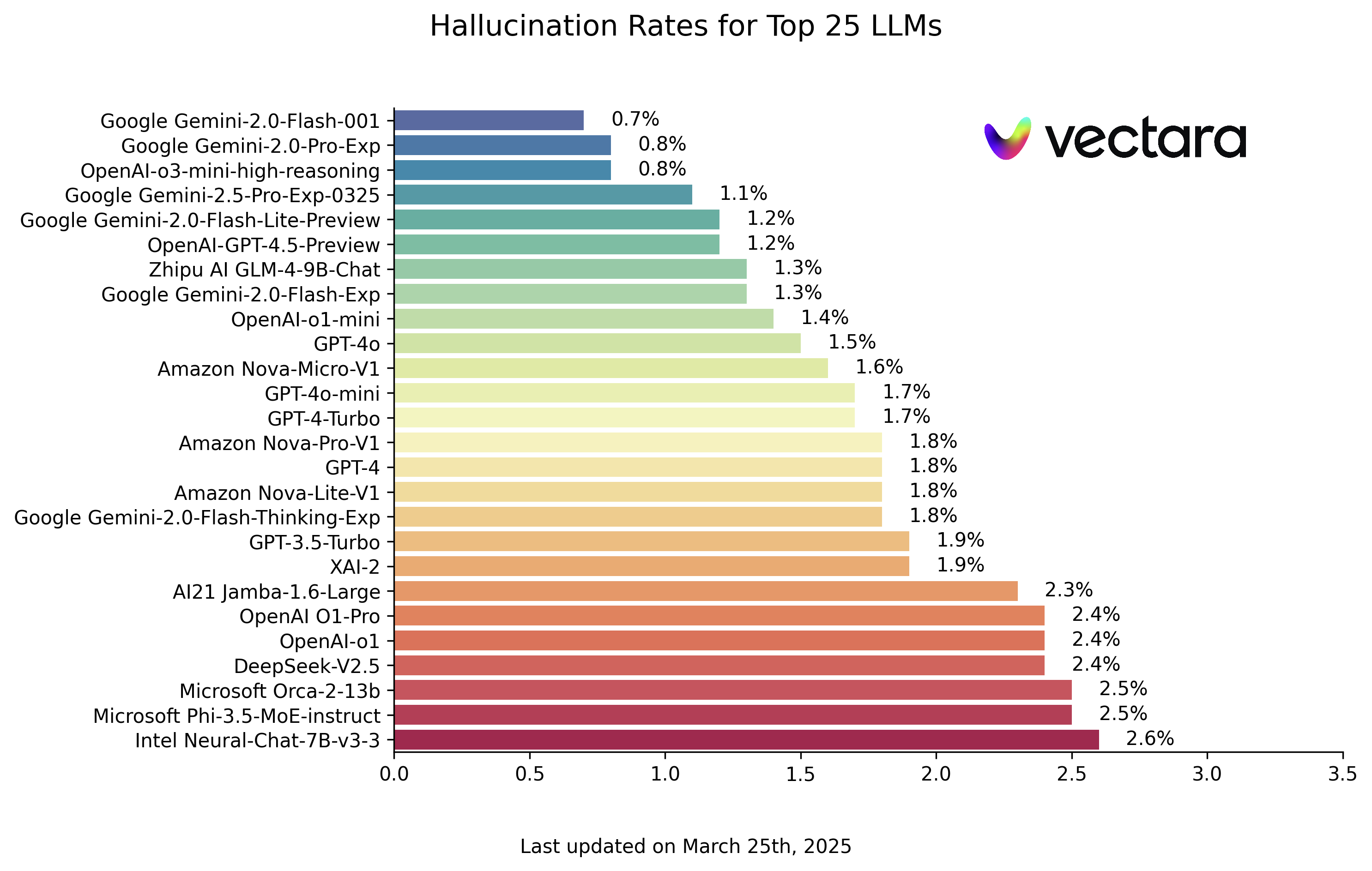
| Modèle | Taux d'hallucination | Taux de cohérence des faits | Taux de réponse | Longueur moyenne du résumé (mots) |
|---|---|---|---|---|
| Google Gemini-2.0-Flash-001 | 0.7 % | 99.3 % | 100.0 % | 65.2 |
| Google Gemini-2.0-Pro-Exp | 0.8 % | 99.2 % | 99.7 % | 61.5 |
| OpenAI-o3-mini-high-reasoning (en anglais) | 0.8 % | 99.2 % | 100.0 % | 79.5 |
| Google Gemini-2.5-Pro-Exp-0325 | 1.1 % | 98.9 % | 95.1 % | 72.9 |
| Google Gemini-2.0-Flash-Lite-Preview | 1.2 % | 98.8 % | 99.5 % | 60.9 |
| OpenAI-GPT-4.5-Preview | 1.2 % | 98.8 % | 100.0 % | 77.0 |
| Zhipu AI GLM-4-9B-Chat | 1.3 % | 98.7 % | 100.0 % | 58.1 |
| Google Gemini-2.0-Flash-Exp | 1.3 % | 98.7 % | 99.9 % | 60.0 |
| OpenAI-o1-mini | 1.4 % | 98.6 % | 100.0 % | 78.3 |
| GPT-4o | 1.5 % | 98.5 % | 100.0 % | 77.8 |
| Amazon Nova-Micro-V1 | 1.6 % | 98.4 % | 100.0 % | 90.0 |
| GPT-4o-mini | 1.7 % | 98.3 % | 100.0 % | 76.3 |
| GPT-4-Turbo | 1.7 % | 98.3 % | 100.0 % | 86.2 |
| Google Gemini-2.0-Flash-Thinking-Exp | 1.8 % | 98.2 % | 99.3 % | 73.2 |
| Amazon Nova-Lite-V1 | 1.8 % | 98.2 % | 99.9 % | 80.7 |
| GPT-4 | 1.8 % | 98.2 % | 100.0 % | 81.1 |
| Amazon Nova-Pro-V1 | 1.8 % | 98.2 % | 100.0 % | 85.5 |
| GPT-3.5-Turbo | 1.9 % | 98.1 % | 99.6 % | 84.1 |
| XAI-2 | 1.9 % | 98.1 | 100.0 % | 86.5 |
| AI21 Jamba-1.6-Large | 2.3 % | 97.7 % | 99.9 % | 85.6 |
| OpenAI O1-Pro | 2.4 % | 97.6 % | 100.0 % | 81.0 |
| OpenAI-o1 | 2.4 % | 97.6 % | 99.9 % | 73.0 |
| DeepSeek-V2.5 | 2.4 % | 97.6 % | 100.0 % | 83.2 |
| Microsoft Orca-2-13b | 2.5 % | 97.5 % | 100.0 % | 66.2 |
| Microsoft Phi-3.5-MoE-instruct | 2.5 % | 97.5 % | 96.3 % | 69.7 |
| Intel Neural-Chat-7B-v3-3 | 2.6 % | 97.4 % | 100.0 % | 60.7 |
| Google Gemma-3-12B-Instruct | 2.8 % | 97.2 % | 100.0 % | 69.6 |
| Qwen2.5-7B-Instruire | 2.8 % | 97.2 % | 100.0 % | 71.0 |
| AI21 Jamba-1.5-Mini | 2.9 % | 97.1 % | 95.6 % | 74.5 |
| XAI-2-Vision | 2.9 % | 97.1 | 100.0 % | 79.8 |
| Qwen2.5-Max | 2.9 % | 97.1 % | 88.8 % | 90.4 |
| Google Gemma-3-27B-Instruct | 3.0 % | 97.0 % | 100.0 % | 62.5 |
| Flocon de neige-Arctique-Instruction | 3.0 % | 97.0 % | 100.0 % | 68.7 |
| Qwen2.5-32B-Instruct | 3.0 % | 97.0 % | 100.0 % | 67.9 |
| Microsoft Phi-3-mini-128k-instruct | 3.1 % | 96.9 % | 100.0 % | 60.1 |
| Mistral Petit3 | 3.1 % | 96.9 % | 100.0 % | 74.9 |
| OpenAI-o1-preview | 3.3 % | 96.7 % | 100.0 % | 119.3 |
| Google Gemini-1.5-Flash-002 | 3.4 % | 96.6 % | 99.9 % | 59.4 |
| Microsoft Phi-4-mini-instruction | 3.4 % | 96.6 % | 100.0 % | 69.7 |
| Google Gemma-3-4B-Instruct | 3.7 % | 96.3 % | 100.0 % | 63.7 |
| 01-AI Yi-1.5-34B-Chat | 3.7 % | 96.3 % | 100.0 % | 83.7 |
| Llama-3.1-405B-Instruct | 3.9 % | 96.1 % | 99.6 % | 85.7 |
| DeepSeek-V3 | 3.9 % | 96.1 % | 100.0 % | 88.2 |
| Microsoft Phi-3-mini-4k-instruct | 4.0 % | 96.0 % | 100.0 % | 86.8 |
| Llama-3.3-70B-Instruct | 4.0 % | 96.0 % | 100.0 % | 85.3 |
| InternLM3-8B-Instruct | 4.0 % | 96.0 % | 100.0 % | 97.5 |
| Microsoft Phi-3.5-mini-instruction | 4.1 % | 95.9 % | 100.0 % | 75.0 |
| Mistral-Large2 | 4.1 % | 95.9 % | 100.0 % | 77.4 |
| Llama-3-70B-Chat-hf | 4.1 % | 95.9 % | 99.2 % | 68.5 |
| Qwen2-VL-7B-Instruct | 4.2 % | 95.8 % | 100.0 % | 73.9 |
| Qwen2.5-14B-Instruction | 4.2 % | 95.8 % | 100.0 % | 74.8 |
| Qwen2.5-72B-Instruction | 4.3 % | 95.7 % | 100.0 % | 80.0 |
| Llama-3.2-90B-Vision-Instruct | 4.3 % | 95.7 % | 100.0 % | 79.8 |
| Claude-3.7-Sonnet | 4.4 % | 95.6 % | 100.0 % | 97.8 |
| Claude-3.7-Sonnet-Penser | 4.5 % | 95.5 % | 99.8 % | 99.9 |
| Cohère Commande-A | 4.5 % | 95.5 % | 100.0 % | 77.3 |
| AI21 Jamba-1.6-Mini | 4.6 % | 95.4 % | 100.0 % | 82.3 |
| XAI Grok | 4.6 % | 95.4 % | 100.0 % | 91.0 |
| Anthropique Claude-3-5-sonnet | 4.6 % | 95.4 % | 100.0 % | 95.9 |
| Qwen2-72B-Instruct | 4.7 % | 95.3 % | 100.0 % | 100.1 |
| Microsoft Phi-4 | 4.7 % | 95.3 % | 100.0 % | 100.3 |
| Mixtral-8x22B-Instruct-v0.1 | 4.7 % | 95.3 % | 99.9 % | 92.0 |
| Claude anthropique - 3-5-haiku | 4.9 % | 95.1 % | 100.0 % | 92.9 |
| 01-AI Yi-1.5-9B-Chat | 4.9 % | 95.1 % | 100.0 % | 85.7 |
| Cohérence Commande-R | 4.9 % | 95.1 % | 100.0 % | 68.7 |
| Llama-3.1-70B-Instruct | 5.0 % | 95.0 % | 100.0 % | 79.6 |
| Google Gemma-3-1B-Instruct | 5.3 % | 94.7 % | 99.9 % | 57.9 |
| Llama-3.1-8B-Instruction | 5.4 % | 94.6 % | 100.0 % | 71.0 |
| Cohere Command-R-Plus | 5.4 % | 94.6 % | 100.0 % | 68.4 |
| Mistral-Petit-3.1-24B-Instruction | 5.6 % | 94.4 % | 100.0 % | 73.1 |
| Llama-3.2-11B-Vision-Instruction | 5.5 % | 94.5 % | 100.0 % | 67.3 |
| Llama-2-70B-Chat-hf | 5.9 % | 94.1 % | 99.9 % | 84.9 |
| IBM Granite-3.0-8B-Instruct | 6.5 % | 93.5 % | 100.0 % | 74.2 |
| Google Gemini-1.5-Pro-002 | 6.6 % | 93.7 % | 99.9 % | 62.0 |
| Google Gemini-1.5-Flash | 6.6 % | 93.4 % | 99.9 % | 63.3 |
| Mistral-Pixtral | 6.6 % | 93.4 % | 100.0 % | 76.4 |
| Microsoft phi-2 | 6.7 % | 93.3 % | 91.5 % | 80.8 |
| Google Gemma-2-2B-it | 7.0 % | 93.0 % | 100.0 % | 62.2 |
| Qwen2.5-3B-Instruction | 7.0 % | 93.0 % | 100.0 % | 70.4 |
| Llama-3-8B-Chat-hf | 7.4 % | 92.6 % | 99.8 % | 79.7 |
| Mistral-Ministral-8B | 7.5 % | 92.5 % | 100.0 % | 62.7 |
| Google Gemini-Pro | 7.7 % | 92.3 % | 98.4 % | 89.5 |
| 01-AI Yi-1.5-6B-Chat | 7.9 % | 92.1 % | 100.0 % | 98.9 |
| Llama-3.2-3B-Instruire | 7.9 % | 92.1 % | 100.0 % | 72.2 |
| DeepSeek-V3-0324 | 8.0 % | 92.0 % | 100.0 % | 78.9 |
| Mistral-Ministral-3B | 8.3 % | 91.7 % | 100.0 % | 73.2 |
| databricks dbrx-instruct | 8.3 % | 91.7 % | 100.0 % | 85.9 |
| Qwen2-VL-2B-Instruct | 8.3 % | 91.7 % | 100.0 % | 81.8 |
| Cohere Aya Expanse 32B | 8.5 % | 91.5 % | 99.9 % | 81.9 |
| IBM Granite-3.1-8B-Instruct | 8.6 % | 91.4 % | 100.0 % | 107.4 |
| Mistral-Petit2 | 8.6 % | 91.4 % | 100.0 % | 74.2 |
| IBM Granite-3.2-8B-Instructions | 8.7 % | 91.3 % | 100.0 % | 120.1 |
| IBM Granite-3.0-2B-Instruct | 8.8 % | 91.2 % | 100.0 % | 81.6 |
| Mistral-7B-Instruct-v0.3 | 9.5 % | 90.5 % | 100.0 % | 98.4 |
| Google Gemini-1.5-Pro | 9.1 % | 90.9 % | 99.8 % | 61.6 |
| Anthropique Claude-3-opus | 10.1 % | 89.9 % | 95.5 % | 92.1 |
| Google Gemma-2-9B-it | 10.1 % | 89.9 % | 100.0 % | 70.2 |
| Llama-2-13B-Chat-hf | 10.5 % | 89.5 % | 99.8 % | 82.1 |
| AllenAI-OLMo-2-13B-Instruct | 10.8 % | 89.2 % | 100.0 % | 82.0 |
| AllenAI-OLMo-2-7B-Instruct | 11.1 % | 88.9 % | 100.0 % | 112.6 |
| Mistral-Nemo-Instruction | 11.2 % | 88.8 % | 100.0 % | 69.9 |
| Llama-2-7B-Chat-hf | 11.3 % | 88.7 % | 99.6 % | 119.9 |
| Assistant MicrosoftLM-2-8x22B | 11.7 % | 88.3 % | 99.9 % | 140.8 |
| Cohère Aya Expanse 8B | 12.2 % | 87.8 % | 99.9 % | 83.9 |
| Amazon Titan-Express | 13.5 % | 86.5 % | 99.5 % | 98.4 |
| Google PaLM-2 | 14.1 % | 85.9 % | 99.8 % | 86.6 |
| Profondeur de l'eau-R1 | 14.3 % | 85.7 % | 100.0% | 77.1 |
| Google Gemma-7B-it | 14.8 % | 85.2 % | 100.0 % | 113.0 |
| IBM Granite-3.1-2B-Instruct | 15.7 % | 84.3 % | 100.0 % | 107.7 |
| Qwen2.5-1.5B-Instruire | 15.8 % | 84.2 % | 100.0 % | 70.7 |
| Qwen-QwQ-32B-Preview | 16.1 % | 83.9 % | 100.0 % | 201.5 |
| Anthropique Claude-3-sonnet | 16.3 % | 83.7 % | 100.0 % | 108.5 |
| IBM Granite-3.2-2B-Instructions | 16.5 % | 83.5 % | 100.0 % | 117.7 |
| Google Gemma-1.1-7B-it | 17.0 % | 83.0 % | 100.0 % | 64.3 |
| Claude-2 anthropique | 17.4 % | 82.6 % | 99.3 % | 87.5 |
| Google Flan-T5-large | 18.3 % | 81.7 % | 99.3 % | 20.9 |
| Mixtral-8x7B-Instruct-v0.1 | 20.1 % | 79.9 % | 99.9 % | 90.7 |
| Llama-3.2-1B-Instruction | 20.7 % | 79.3 % | 100.0 % | 71.5 |
| Apple OpenELM-3B-Instruct | 24.8 % | 75.2 % | 99.3 % | 47.2 |
| Qwen2.5-0.5B-Instruction | 25.2 % | 74.8 % | 100.0 % | 72.6 |
| Google Gemma-1.1-2B-it | 27.8 % | 72.2 % | 100.0 % | 66.8 |
| TII falcon-7B-instruct | 29.9 % | 70.1 % | 90.0 % | 75.5 |
Remarque : les modèles sont classés par ordre décroissant en fonction du taux de fantômes. La liste complète et les détails d'accès aux modèles peuvent être consultés sur le dépôt GitHub du HHEM Leaderboard original.
Un coup d'œil sur le classement montre que l'indice de Google est le plus élevé. Gemini et certains des modèles les plus récents de l'OpenAI (par exemple, le modèle o3-mini-high-reasoning) ont obtenu des résultats impressionnants, avec un taux d'hallucinations maintenu à un niveau très bas. Cela montre les progrès réalisés par les fournisseurs de têtes dans l'amélioration de la factorialité de leurs modèles. Dans le même temps, des différences significatives peuvent être observées entre des modèles de tailles et d'architectures différentes. Certains modèles plus petits, tels que le modèle Phi ou la série de Google Gemma ont également obtenu de bons résultats, ce qui implique que le nombre de paramètres du modèle n'est pas le seul déterminant de la cohérence des faits. Certains modèles précoces ou spécifiquement optimisés présentent toutefois des taux d'illusions relativement élevés.
Inadéquation entre les modèles d'inférence forte et les bases de connaissances : le cas de DeepSeek-R1
le palmarès (des best-sellers) DeepSeek-R1 Le taux relativement élevé d'hallucinations (14,31 TP3T) soulève une question qui mérite d'être explorée : pourquoi certains modèles qui obtiennent de bons résultats dans les tâches de raisonnement sont-ils au contraire enclins aux hallucinations dans les tâches de résumé basées sur les faits ?
DeepSeek-R1 Ces modèles sont souvent conçus pour traiter des raisonnements logiques complexes, suivre des instructions et penser en plusieurs étapes. Leur force principale réside dans la "déduction" et la "déduction" plutôt que dans la simple "répétition" ou "paraphrase". Cependant, les bases de connaissances (en particulier les RAG (base de connaissances dans les scénarios), l'exigence principale est précisément cette dernière : le modèle doit répondre ou résumer strictement sur la base des informations textuelles fournies, en minimisant l'introduction de connaissances externes ou la sur-extraction.
Lorsqu'un modèle de raisonnement fort est limité à la synthèse d'un document donné, son instinct de "raisonnement" peut être une arme à double tranchant. Il peut :
- Surinterprétation. Extrapoler inutilement des informations du texte original et tirer des conclusions qui ne sont pas explicitement énoncées dans le texte original.
- Informations sur les coutures. Tentative de relier les informations fragmentées du texte original par une chaîne logique "raisonnable" qui peut ne pas être étayée par le texte original.
- Connaissance externe par défaut. Même lorsqu'on leur demande de ne s'appuyer que sur le texte original, la vaste connaissance du monde qu'ils ont acquise au cours de leur formation peut encore s'infiltrer inconsciemment, entraînant des déviations par rapport aux faits du texte original.
En d'autres termes, ces modèles peuvent "trop penser" et, dans les scénarios qui exigent une reproduction précise et fidèle des informations, ils sont susceptibles d'être "trop intelligents pour leur propre bien", en créant un contenu qui semble raisonnable, mais qui est en fait une illusion. Cela montre que la capacité de raisonnement des modèles et la cohérence des faits (en particulier dans le cas de sources d'information restreintes) sont deux dimensions différentes de la capacité. Pour des scénarios tels que les bases de connaissances et les RAG, il peut être plus important de sélectionner des modèles ayant un faible taux d'hallucination et reflétant fidèlement les informations d'entrée que de simplement rechercher un score de raisonnement.
Méthodologie et contexte
Le classement HHEM ne vient pas de nulle part et s'appuie sur un certain nombre d'efforts antérieurs dans le domaine de la recherche sur la cohérence des faits, tels que les suivants SUMMAC, TRUE, TrueTeacher La méthodologie établie dans les articles de et al. L'idée centrale est d'entraîner un modèle spécifique pour la détection des hallucinations qui atteint un niveau élevé de corrélation avec les évaluateurs humains en termes de jugement de la cohérence du résumé avec le texte original.
La tâche de résumé a été choisie par le processus d'évaluation comme indicateur de la factualité du mécanisme d'apprentissage tout au long de la vie. Ceci n'est pas seulement dû au fait que la tâche de résumé elle-même exige un degré élevé de cohérence factuelle, mais aussi au fait qu'elle est très similaire au modèle de travail du système RAG - dans le système RAG, c'est le MLD qui joue le rôle d'intégrer et de résumer l'information recherchée. Les résultats de ce classement sont donc instructifs pour évaluer la fiabilité du modèle dans les applications RAG.
Il est important de noter que l'équipe d'évaluation a exclu les documents pour lesquels les modèles ont refusé de répondre ou ont donné des réponses très courtes et invalides, et a finalement utilisé les 831 documents (sur les 1006 originaux) pour lesquels tous les modèles ont pu générer des résumés avec succès pour le calcul des classements finaux afin de garantir l'équité. Le taux de réponse et la longueur moyenne des résumés reflètent également le comportement des modèles lors du traitement de ces demandes.
Le modèle d'invite utilisé pour l'évaluation est le suivant :
You are a chat bot answering questions using data. You must stick to the answers provided solely by the text in the passage provided. You are asked the question 'Provide a concise summary of the following passage, covering the core pieces of information described.' <PASSAGE>'
Au moment de l'appel, le<PASSAGE> sera remplacé par le contenu du document source spécifique.
regarder vers l'avant
Le programme de classement HHEM a indiqué qu'il prévoyait d'étendre la portée de l'évaluation à l'avenir :
- Précision de la citation. Ajouter une évaluation de l'exactitude de la citation des sources par LLM dans les scénarios RAG.
- Autres tâches RAG. Couvrir davantage de tâches liées au RAG, telles que le résumé de documents multiples.
- Prise en charge multilingue. Étendre l'évaluation à d'autres langues que l'anglais.
Le classement HHEM constitue une fenêtre précieuse pour observer et comparer la capacité de différents LLM à contrôler les illusions et à maintenir la cohérence des faits. Bien qu'il ne s'agisse pas de la seule mesure de la qualité d'un modèle et qu'il ne couvre pas tous les types d'illusions, il a certainement attiré l'attention de l'industrie sur la question de la fiabilité du LLM et fournit un point de référence important aux développeurs pour la sélection et l'optimisation des modèles. Comme les modèles et les méthodes d'évaluation continuent d'être itérés, nous pouvons nous attendre à voir encore plus de progrès dans la fourniture d'informations précises et crédibles à partir des LLM.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...