Ilya Sutskever explose à NeurIPS et déclare : le pré-entraînement va cesser, la compression des données est terminée.

Le raisonnement est imprévisible, nous devons donc commencer par des systèmes d'IA incroyables et imprévisibles.
Ilya s'est enfin montré, et d'emblée, il a quelque chose d'étonnant à dire. Vendredi, Ilya Sutskever, l'ancien directeur scientifique d'OpenAI, a déclaré lors du Global AI Summit que "nous avons atteint la limite des données que nous pouvons obtenir et qu'il n'y en aura pas d'autres". 
Ilya Sutskever, cofondateur et ancien directeur scientifique d'OpenAI, a fait les gros titres lorsqu'il a quitté l'entreprise en mai dernier pour lancer son propre laboratoire d'IA, Safe Superintelligence. Il s'est tenu à l'écart des médias depuis son départ d'OpenAI, mais a fait une rare apparition publique ce vendredi lors de NeurIPS 2024, une conférence sur les systèmes de traitement de l'information neuronale qui se tient à Vancouver.
"La préformation telle que nous la connaissons va sans aucun doute prendre fin", a déclaré Sutskever depuis la scène.
Dans le domaine de l'intelligence artificielle, les modèles de pré-entraînement à grande échelle tels que BERT et GPT ont connu un grand succès ces dernières années et sont devenus un jalon sur la voie du progrès technologique.
En raison de la complexité des objectifs de pré-entraînement et de l'importance des paramètres du modèle, le pré-entraînement à grande échelle peut capturer efficacement des connaissances à partir de grandes quantités de données étiquetées et non étiquetées. En stockant les connaissances dans d'énormes paramètres et en les ajustant avec précision pour une tâche spécifique, les riches connaissances implicitement encodées dans les énormes paramètres peuvent bénéficier à une variété de tâches en aval. Le consensus au sein de la communauté de l'IA est désormais d'adopter le pré-entraînement comme colonne vertébrale des tâches en aval, plutôt que d'apprendre des modèles à partir de zéro. 
Toutefois, dans son exposé au NeurIPS, Ilya Sutskever a déclaré que si les données existantes peuvent encore alimenter l'IA, l'industrie est sur le point de manquer de nouvelles données utilisables. Il a noté que cette tendance obligera finalement l'industrie à changer la façon dont les modèles sont actuellement formés.
M. Sutskever compare la situation à l'épuisement des combustibles fossiles : tout comme le pétrole est une ressource limitée, le contenu généré par l'homme sur l'internet l'est également.
"Nous avons atteint le pic des données et il n'y en aura plus à l'avenir", a déclaré M. Sutskever. "Nous devons utiliser les données disponibles car il n'y a qu'un seul Internet.
Sutskever prédit que la prochaine génération de modèles "fera preuve d'une réelle autonomie". Par ailleurs, le terme "agent" est devenu un mot à la mode dans le domaine de l'IA.
En plus d'être "autonomes", il a également mentionné que les futurs systèmes auront la capacité de raisonner. Contrairement à l'IA d'aujourd'hui, qui s'appuie fortement sur la correspondance des modèles (basée sur ce que le modèle a vu auparavant), les futurs systèmes d'IA seront capables de résoudre les problèmes étape par étape, d'une manière similaire à la "pensée".
Selon M. Sutskever, plus un système est capable de raisonner, plus son comportement devient "imprévisible". Il compare l'imprévisibilité des "systèmes dotés d'un véritable pouvoir de raisonnement" aux performances des IA avancées aux échecs : "même les meilleurs joueurs humains ne peuvent pas prédire leurs mouvements".
Ces systèmes seront capables de comprendre les choses à partir de données limitées et de ne pas s'embrouiller", a-t-il déclaré.
Dans son exposé, il a comparé la mise à l'échelle des systèmes d'IA à la biologie évolutive, en citant la relation entre les ratios cerveau/poids corporel entre les différentes espèces de l'étude. Il a souligné que la plupart des mammifères suivent un modèle spécifique de mise à l'échelle, alors que la famille humaine (les ancêtres de l'homme) présente une tendance très différente de croissance des ratios cerveau/corps sur une échelle logarithmique.
M. Sutskever propose que, tout comme l'évolution a trouvé un nouveau paradigme de mise à l'échelle pour le cerveau scientifique humain, l'IA puisse aller au-delà des méthodes de pré-entraînement existantes et découvrir des voies de mise à l'échelle entièrement nouvelles. Le texte intégral de l'intervention d'Ilya Sutskever est disponible ci-dessous : 
J'aimerais remercier les organisateurs de la conférence d'avoir choisi un article pour ce prix (l'article Seq2Seq d'Ilya Sutskever et al. a été sélectionné pour le prix Time Check de NeurIPS 2024). C'est formidable. J'aimerais également remercier mes incroyables coauteurs Oriol Vinyals et Quoc V. Le, qui se tiennent juste devant vous. 

Vous avez ici une image, une capture d'écran. Il y a eu un exposé similaire au NIPS 2014 à Montréal il y a 10 ans. C'était une époque beaucoup plus innocente. Nous apparaissons ici sur la photo. D'ailleurs, c'était la dernière fois, celle ci-dessous est cette fois-ci.
Aujourd'hui, nous avons plus d'expérience et nous sommes, je l'espère, un peu plus sages. Mais j'aimerais parler un peu de l'exercice lui-même, et peut-être faire un bilan sur 10 ans, parce que beaucoup de choses qui se sont bien passées dans l'exercice étaient bonnes, et certaines ne l'étaient pas tant que ça. Nous pouvons regarder en arrière et voir ce qui s'est passé et comment cela nous a menés là où nous sommes aujourd'hui. Commençons donc à parler de ce que nous avons fait. La première chose que nous allons faire est de montrer des diapositives de la même présentation d'il y a 10 ans. Elle se résume en trois points principaux. Un modèle autorégressif entraîné sur du texte, un grand réseau neuronal, un grand ensemble de données, et c'est tout.
Commençons donc à parler de ce que nous avons fait. La première chose que nous allons faire est de montrer des diapositives de la même présentation d'il y a 10 ans. Elle se résume en trois points principaux. Un modèle autorégressif entraîné sur du texte, un grand réseau neuronal, un grand ensemble de données, et c'est tout.
Entrons maintenant dans les détails. 
Voici une diapositive datant d'il y a dix ans qui semble intéressante : "L'hypothèse de l'apprentissage profond". Ce que nous disons ici, c'est que si vous avez un grand réseau neuronal avec 10 couches, il peut faire tout ce qu'un humain peut faire en une fraction de seconde. Pourquoi mettons-nous l'accent sur "ce que l'homme peut faire en une fraction de seconde" ? Pourquoi cette chose ?
Pourquoi mettons-nous l'accent sur "ce que l'homme peut faire en une fraction de seconde" ? Pourquoi cette chose ?
Eh bien, si vous croyez au dogme de l'apprentissage profond selon lequel les neurones artificiels sont similaires aux neurones biologiques, ou du moins pas trop différents, et si vous croyez que trois vrais neurones sont lents, alors les humains peuvent traiter n'importe quoi rapidement. Je veux même dire s'il n'y avait qu'une seule personne dans le monde. Si une seule personne au monde peut faire quelque chose en une fraction de seconde, alors un réseau neuronal à 10 couches peut le faire, n'est-ce pas ?
Ensuite, il suffit d'intégrer leurs connexions dans un réseau neuronal artificiel.
Tout est une question de motivation. Tout ce qu'un être humain peut faire en une fraction de seconde, un réseau neuronal à 10 couches peut le faire aussi.
Nous nous sommes concentrés sur les réseaux neuronaux à 10 couches parce que c'est ainsi que nous savions former à l'époque, et si vous pouviez dépasser ce nombre de couches, vous pouviez faire plus. Mais à l'époque, nous ne pouvions faire que 10 couches, c'est pourquoi nous avons mis l'accent sur tout ce qu'un humain pouvait faire en une fraction de seconde.
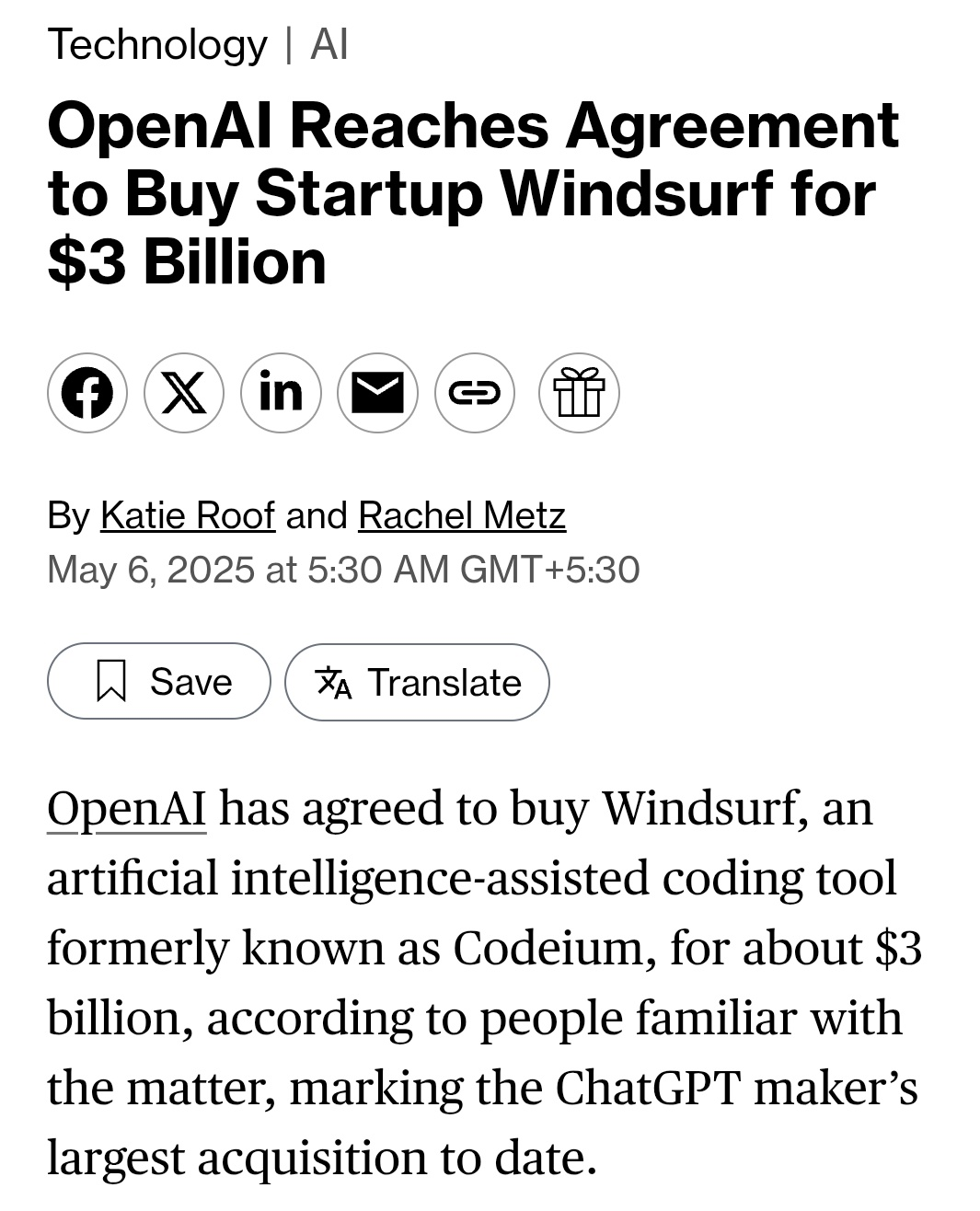
L'autre diapositive de cette année-là illustre notre idée principale, à savoir qu'il est possible d'identifier deux choses, ou au moins une chose, et de déterminer qu'il s'agit d'une autorégression. 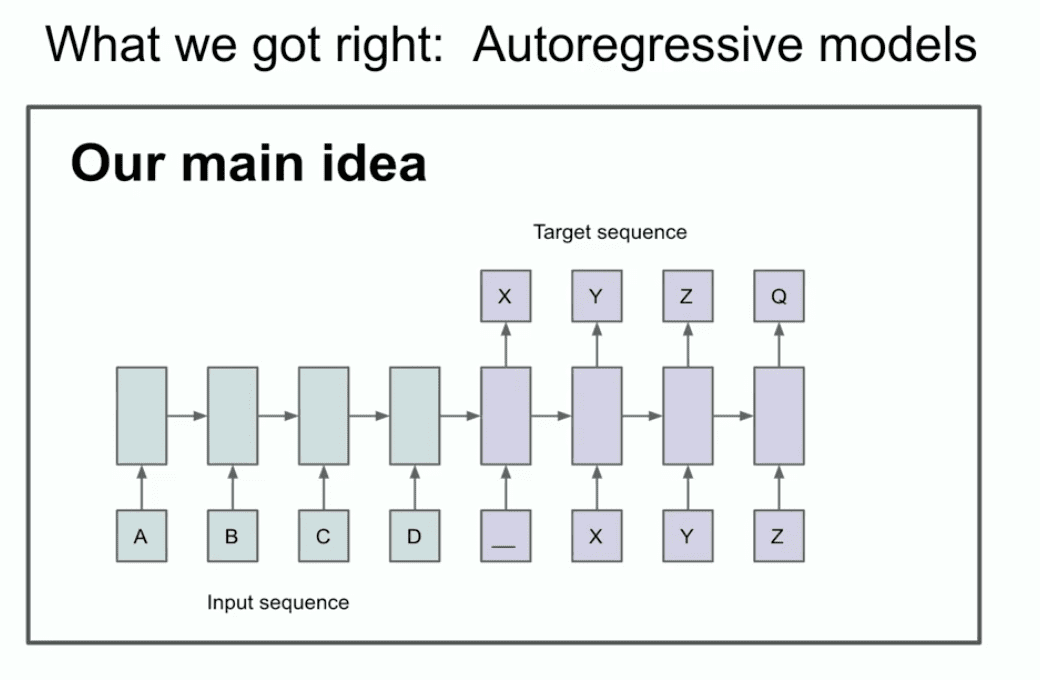
Qu'est-ce que cette diapositive dit ? Que dit cette diapositive ? Cette diapositive dit que si vous avez un modèle autorégressif et qu'il prédit le prochain jeton est suffisamment bonne, elle saisira, capturera et maintiendra la distribution correcte de la séquence suivante.
C'est une chose relativement nouvelle, ce n'est pas le premier réseau autorégressif, mais je pense que c'est le premier réseau neuronal autorégressif. Nous étions convaincus que si vous l'entraîniez bien, vous obtiendriez ce que vous vouliez. Dans notre cas, il s'agissait d'une tâche de traduction automatique qui semble conservatrice aujourd'hui et qui paraissait très audacieuse à l'époque. Je vais maintenant vous montrer une histoire ancienne que beaucoup d'entre vous n'ont probablement jamais vue auparavant, et qui s'appelle le LSTM.
Pour ceux qui ne connaissent pas, la LSTM est le chercheur en apprentissage profond le plus pauvre de l'Union européenne. Transformateur Ce qui a été fait auparavant.
Il s'agit essentiellement d'un ResNet, mais tourné de 90 degrés, donc d'une LSTM. Il s'agit donc d'une LSTM. Une LSTM est comme un ResNet légèrement plus complexe. Vous pouvez voir l'intégrateur, qui est maintenant appelé le flux résiduel. C'est un peu compliqué, mais c'est ce que nous faisons. Voici un ResNet tourné de 90 degrés. 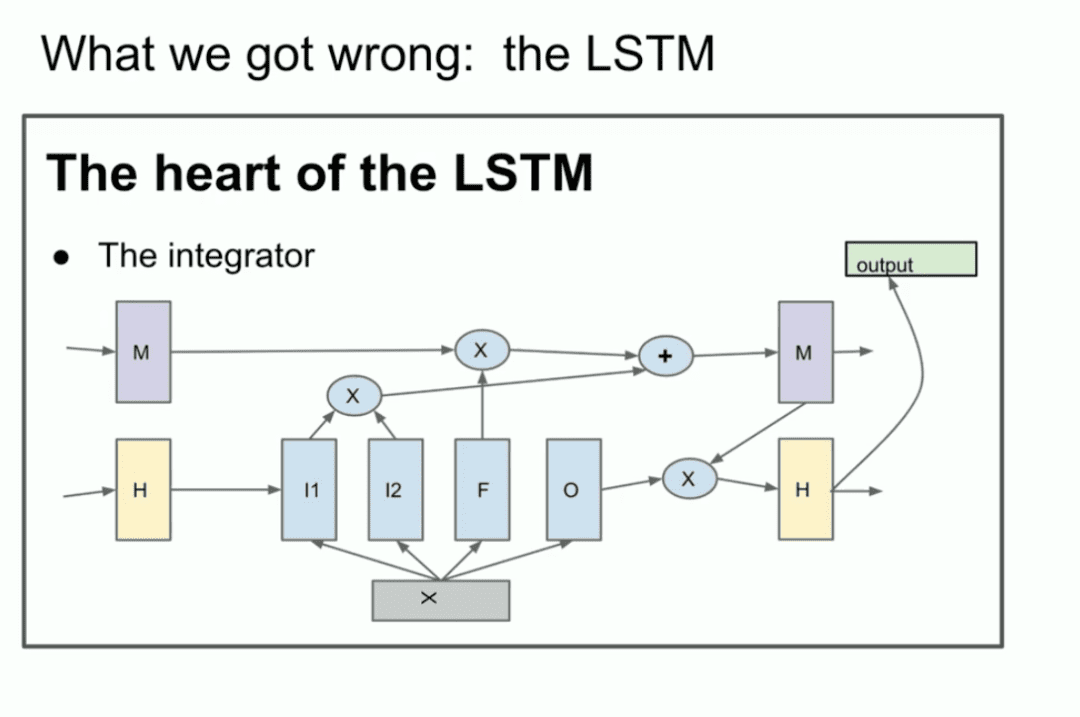
Un autre point clé que je voulais souligner dans cet ancien exposé était que nous utilisions la parallélisation, mais pas seulement.
Nous avons utilisé le pipelining, en allouant un GPU par couche de réseau neuronal, ce qui, comme nous le savons maintenant, n'est pas une stratégie intelligente, mais nous n'étions pas très intelligents à l'époque. Nous l'avons donc utilisée et nous avons obtenu un résultat 3,5 fois plus rapide avec 8 GPU. 
La conclusion finale est la diapositive la plus importante. Elle met en lumière ce qui pourrait être le début des lois de mise à l'échelle. Si vous disposez d'un très grand ensemble de données et que vous entraînez un très grand réseau neuronal, le succès est garanti. On pourrait dire que si l'on est généreux, c'est vraiment ce qui se passe. 
Je voudrais maintenant évoquer une autre idée qui, selon moi, a vraiment résisté à l'épreuve du temps. Il s'agit de l'idée centrale de l'apprentissage profond. Il s'agit de l'idée du connexionnisme. L'idée est que si vous croyez que les neurones artificiels sont un peu comme les neurones biologiques. Si vous croyez que l'un est un peu comme l'autre, alors cela vous donne la confiance nécessaire pour croire aux réseaux neuronaux à grande échelle. Ils n'ont pas besoin d'être à l'échelle d'un cerveau humain, ils peuvent être un peu plus petits, mais vous pouvez les configurer pour qu'ils fassent à peu près tout ce que nous faisons.
Mais il y a encore une différence avec les humains, parce que le cerveau humain trouve comment se reconfigurer, et nous utilisons les meilleurs algorithmes d'apprentissage dont nous disposons, ce qui nécessite autant de points de données que de paramètres. Les humains font un bien meilleur travail dans ce domaine. Tout cela est axé sur ce que j'appellerais l'ère de la préformation.
Tout cela est axé sur ce que j'appellerais l'ère de la préformation.
Nous avons ensuite ce que nous appelons le modèle GPT-2, le modèle GPT-3, les lois d'échelle, et je voudrais mentionner tout particulièrement mon ancien collaborateur Alec Radford, ainsi que Jared Kaplan et Dario Amodei, dont les efforts ont rendu tout ce travail possible.  C'est l'ère du pré-entraînement, et c'est ce qui est à l'origine de toutes les avancées, toutes les avancées que nous voyons aujourd'hui, les méga-réseaux neuronaux, les méga-réseaux neuronaux entraînés sur d'énormes ensembles de données.
C'est l'ère du pré-entraînement, et c'est ce qui est à l'origine de toutes les avancées, toutes les avancées que nous voyons aujourd'hui, les méga-réseaux neuronaux, les méga-réseaux neuronaux entraînés sur d'énormes ensembles de données.
Mais le parcours de préformation tel que nous le connaissons va sans aucun doute prendre fin. Pourquoi ? Parce que les ordinateurs ne cessent de se développer grâce à un meilleur matériel, à de meilleurs algorithmes et à des grappes de logique, et que tous ces éléments continuent d'augmenter votre puissance de calcul, alors que les données n'augmentent pas parce que tout ce que nous avons, c'est un Internet. 
On pourrait même dire que les données sont le carburant fossile de l'IA. C'est comme si elles avaient été créées d'une certaine manière et que maintenant que nous les utilisons, nous avons maximisé l'utilisation des données et cela ne peut pas s'améliorer. Nous déterminons ce que nous devons faire avec les données dont nous disposons maintenant. Je vais continuer à travailler là-dessus, et cela nous permet d'aller assez loin, mais le problème est qu'il n'y a qu'un seul internet.
Je vais donc me risquer à spéculer sur la suite des événements. En fait, je n'ai même pas besoin de spéculer car beaucoup d'autres spéculent également, et je vais mentionner leurs spéculations.
- Vous avez peut-être entendu l'expression "agent du corps intelligent", elle est assez courante et je suis sûr qu'un jour ou l'autre, les gens penseront que les corps intelligents sont l'avenir.
- Plus précisément, mais aussi de manière un peu vague, les données synthétiques. Mais que signifient les données synthétiques ? C'est un défi énorme, et je suis sûr que différentes personnes font toutes sortes de progrès intéressants dans ce domaine.
- Il y a aussi le calcul du temps d'inférence, ou peut-être plus récemment (OpenAI) o1, le modèle o1 qui montre le plus clairement que les gens essaient de comprendre ce qu'il faut faire après le pré-entraînement.
Ce sont là de très bonnes choses. 
Je voudrais mentionner un autre exemple tiré de la biologie que je trouve très intéressant. Il y a de nombreuses années, lors de cette conférence, j'ai également assisté à une présentation où quelqu'un a montré ce graphique qui illustre la relation entre la taille du corps et la taille du cerveau chez les mammifères. Dans ce cas, il s'agissait d'un cerveau massif. Cette présentation, je m'en souviens très bien, disait qu'en biologie, tout est confus, mais ici, vous avez un exemple rare d'une relation très forte entre la taille du corps d'un animal et celle de son cerveau.
C'est par hasard que j'ai commencé à m'intéresser à cette photo.  Je suis donc allé sur Google et j'ai fait une recherche par image.
Je suis donc allé sur Google et j'ai fait une recherche par image.
Dans cette image, une variété de mammifères est répertoriée, ainsi que les non-primates, mais en grande partie les mêmes, et les primitifs. Pour autant que je sache, les primitifs étaient des proches parents des humains dans leur évolution, comme les Néandertaliens. Par exemple, l'"homme énergisé". Il est intéressant de noter qu'ils ont des pentes différentes de l'indice du rapport cerveau/corps. Très intéressant.
Cela signifie qu'il y a un cas, un cas où la biologie trouve une sorte d'échelle différente. Il est évident que quelque chose est différent. Je tiens d'ailleurs à souligner que l'axe des x est une échelle logarithmique. Il s'agit de 100, 1 000, 10 000, 100 000, toujours en grammes, 1 gramme, 10 grammes, 100 grammes, un kilogramme. Il est donc possible que les choses soient différentes.
Ce que nous faisons, ce que nous avons fait jusqu'à présent en termes de mise à l'échelle, nous constatons en fait que la façon dont nous mettons à l'échelle devient la priorité numéro un. Il ne fait aucun doute que tous ceux qui travaillent ici trouveront ce qu'il faut faire. Mais je veux en parler ici. Je voudrais prendre quelques minutes pour faire une projection à long terme, ce à quoi nous sommes tous confrontés, n'est-ce pas ?  Tous les progrès que nous réalisons sont étonnants. Je veux dire que les personnes qui ont travaillé dans ce domaine il y a dix ans se souviennent de l'impuissance dans laquelle elles se trouvaient. Si vous avez rejoint le domaine de l'apprentissage profond au cours des deux dernières années, vous ne pouvez probablement pas vous en souvenir.
Tous les progrès que nous réalisons sont étonnants. Je veux dire que les personnes qui ont travaillé dans ce domaine il y a dix ans se souviennent de l'impuissance dans laquelle elles se trouvaient. Si vous avez rejoint le domaine de l'apprentissage profond au cours des deux dernières années, vous ne pouvez probablement pas vous en souvenir.
Je voudrais parler un peu de la "superintelligence" parce que c'est clairement la direction que prend le domaine et ce qu'il essaie de construire.
Si les modèles linguistiques ont des capacités incroyables à l'heure actuelle, ils ne sont pas non plus très fiables. Il n'est pas évident de concilier ces deux aspects, mais tôt ou tard, l'objectif sera atteint : ces systèmes deviendront réellement des intelligences. Pour l'instant, ces systèmes ne sont pas des intelligences perceptives puissantes et significatives ; en fait, ils commencent à peine à raisonner. D'ailleurs, plus un système raisonne, plus il devient imprévisible.
Nous sommes habitués à ce que l'apprentissage en profondeur soit très prévisible. En effet, si vous avez travaillé sur la reproduction de l'intuition humaine, en revenant à un temps de réaction de 0,1 seconde, quel type de traitement notre cerveau effectue-t-il ? C'est l'intuition, et nous avons donné à l'AIS une partie de cette intuition.
Mais en ce qui concerne le raisonnement, certains signes précurseurs montrent que le raisonnement est imprévisible. Les échecs, par exemple, sont imprévisibles pour les meilleurs joueurs humains. Nous aurons donc affaire à des systèmes d'IA très imprévisibles. Ils comprendront les choses à partir de données limitées et ne seront pas désorientés.
Tout cela est très limitatif. D'ailleurs, je n'ai pas dit comment ou quand toutes ces choses se produiraient avec la "conscience de soi", car pourquoi la "conscience de soi" ne serait-elle pas utile ? Nous faisons nous-mêmes partie du modèle de notre propre monde.
Lorsque tous ces éléments seront réunis, nous aurons des systèmes dotés de qualités et d'attributs complètement différents de ceux qui existent aujourd'hui. Ils auront, bien sûr, des capacités incroyables et stupéfiantes. Mais le problème d'un tel système est que je soupçonne qu'il sera très différent.
Je dirais que prédire l'avenir est certainement impossible aussi. Vraiment, toutes sortes de choses sont possibles. Je vous remercie tous.
Après une salve d'applaudissements lors de la conférence Neurlps, Ilya a répondu à quelques brèves questions posées par plusieurs intervenants.
Q : En 2024, pensez-vous qu'il existe d'autres structures biologiques liées à la cognition humaine qui méritent d'être explorées de la même manière, ou y a-t-il d'autres domaines qui vous intéressent ?
Ilya :Je répondrais à la question de la manière suivante : si vous ou quelqu'un d'autre a une idée sur un problème spécifique, comme "hé, nous ignorons clairement que le cerveau fait quelque chose, et nous ne le faisons pas", et que c'est réalisable, alors ils devraient s'engager plus avant dans cette direction. Personnellement, je n'ai pas de telles idées. Bien sûr, cela dépend aussi du niveau d'abstraction de la recherche sur laquelle vous vous concentrez. De nombreuses personnes aspirent à développer une IA inspirée par la biologie. D'une certaine manière, on pourrait dire que l'IA d'inspiration biologique a été un énorme succès - après tout, la base de l'apprentissage profond est l'IA d'inspiration biologique - mais d'un autre côté, cette inspiration biologique est en fait très, très limitée. Il s'agit essentiellement d'utiliser des neurones, c'est tout ce que l'on entend par "bio-inspirée". Des niveaux plus détaillés et plus profonds de bio-inspiration sont plus difficiles à atteindre, mais je ne l'exclurais pas. Je pense qu'il serait très utile que quelqu'un de particulièrement perspicace puisse découvrir un nouvel angle d'attaque. Q : J'aimerais poser une question sur l'autocorrection.
Vous avez mentionné que l'inférence pourrait être l'un des principaux axes de développement des modèles à l'avenir et qu'elle pourrait constituer un élément de différenciation. Dans certaines des sessions de présentation de posters, nous avons constaté qu'il existe une "illusion" des modèles actuels. Notre méthode actuelle pour analyser si les modèles sont hallucinants (veuillez me corriger si j'ai mal compris, vous êtes l'expert dans ce domaine) est principalement basée sur des analyses statistiques, par exemple en déterminant s'il y a une déviation de la moyenne par une certaine déviation de la déviation standard. À l'avenir, pensez-vous que si le modèle a la capacité de raisonner, il sera capable de s'autocorriger comme l'autocorrection et deviendra ainsi une caractéristique essentielle des modèles futurs ? De cette façon, le modèle n'aurait pas autant d'hallucinations car il serait capable de reconnaître les situations où il génère son propre contenu hallucinatoire. Il s'agit peut-être d'une question plus complexe, mais pensez-vous que les futurs modèles seront capables de comprendre et de détecter l'apparition d'hallucinations par le raisonnement ?
Ilya :Réponse : Oui.
Je pense que la situation que vous décrivez est très probable. Bien que je n'en sois pas sûr, je vous suggère de vérifier, et ce scénario a peut-être déjà eu lieu dans certains des premiers modèles de raisonnement. Mais à long terme, pourquoi cela ne serait-il pas possible ?
Q : Je veux dire que c'est comme la fonction d'autocorrection dans Microsoft Word, c'est une fonction essentielle.
Ilya :Oui, je pense que parler de "correction automatique" est en fait un peu exagéré. Lorsque l'on parle de "correction automatique", cela évoque des images de fonctions relativement simples, mais le concept va bien au-delà de la correction automatique. Dans l'ensemble, cependant, la réponse est oui.
QUESTIONNAIRE : Merci. Le deuxième intervenant est le suivant.
Q : Bonjour Ilya. J'ai beaucoup aimé la fin avec le mystérieux voile blanc. Les IA vont-elles nous remplacer ou nous sont-elles supérieures ? Ont-elles besoin de droits ? Il s'agit d'une toute nouvelle espèce. L'Homo sapiens a donné naissance à cette intelligence, et je pense que les gens de Reinforcement Learning pourraient penser que nous avons besoin de droits pour ces êtres.
J'ai une question sans rapport avec celle-ci : comment créer les bonnes incitations pour que les humains les créent d'une manière qui leur permette de jouir des mêmes libertés que celles dont nous, Homo sapiens, jouissons ?
Ilya :Je pense qu'il s'agit là de questions auxquelles les gens devraient réfléchir davantage. Mais pour ce qui est de votre question sur le type d'incitations que nous devrions créer, je ne pense pas pouvoir répondre en toute confiance à une telle question. Il semble que nous parlions de créer une sorte de structure descendante ou de modèle de gouvernance, mais je n'en suis pas très sûr.
Le dernier intervenant est le suivant.
Q : Bonjour Ilya, merci pour cette excellente présentation. Je suis de l'Université de Toronto. Je vous remercie pour tout le travail que vous avez accompli. J'aimerais vous demander si vous pensez que les LLM sont capables de généraliser l'inférence multi-sauts en dehors de la distribution ?
Ilya :D'accord, cette question suppose que la réponse est soit "oui", soit "non", mais il ne faut pas vraiment y répondre de cette façon. En effet, nous devons d'abord déterminer ce que signifie la généralisation hors distribution. Qu'est-ce qui est intra-distributif ? Qu'est-ce que la généralisation hors distribution ? Parce qu'il s'agit d'un discours sur le "time-testing". Je dirais qu'il y a très longtemps, avant l'apprentissage profond, les gens utilisaient la correspondance de chaînes et les n-grammes pour faire de la traduction automatique. À l'époque, les gens s'appuyaient sur des tableaux statistiques de phrases. Vous imaginez ? Ces méthodes comportaient des dizaines de milliers de lignes de code, d'une complexité inimaginable. Et à l'époque, la généralisation était définie comme le fait que le résultat de la traduction n'était pas littéralement identique à la représentation de la phrase dans l'ensemble de données. Aujourd'hui, nous pourrions dire : "Mon modèle a obtenu d'excellents résultats à un concours de mathématiques, mais il se peut que certaines des idées de ces questions de mathématiques aient été discutées dans un forum sur l'internet à un moment donné, et que le modèle s'en soit simplement souvenu". On pourrait faire valoir que cela pourrait être dans la distribution, ou que cela pourrait être le résultat de la mémorisation. Mais je pense qu'il est vrai que nos critères de généralisation se sont considérablement élevés - on pourrait même dire de manière significative et inconcevable.
Ma réponse est donc la suivante : dans une certaine mesure, les modèles ne sont probablement pas aussi bons que les humains en matière de généralisation. Je pense que les humains sont bien meilleurs en matière de généralisation. Mais en même temps, il est également vrai que les modèles d'IA sont capables de généraliser en dehors de la distribution dans une certaine mesure. J'espère que cette réponse vous sera utile, même si elle semble un peu redondante.
Q : Merci.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes



Pas de commentaires...