
Nouvelle version de Hybrid-T1 : Mamba, redéfinissant la vitesse d'inférence

Récemment, le domaine de la modélisation linguistique à grande échelle a fait l'objet d'une attention croissante de la part de l'industrie pour de nouveaux paradigmes d'apprentissage par renforcement dans les dernières étapes de la formation. Suite à l'introduction de modèles de la série O, tels que GPT-4o par OpenAI et le modèle Profondeur de l'eau-R1 L'excellente performance du modèle démontre le rôle clé de l'apprentissage par renforcement dans le processus d'optimisation.
L'équipe Tencent Mixed Meta Model a également réalisé des progrès significatifs récemment. À la mi-février de cette année, l'équipe a lancé le modèle d'inférence Mixed Yuan T1-Preview basé sur une base Mixed Yuan de taille moyenne sur l'APP Yuanbao de Tencent. Aujourd'hui, le modèle Deep Thinking de la série Mixed Meta Model est passé à la version officielle Mixed Meta-T1.
Adresse de l'expérience :
https://llm.hunyuan.tencent.com/#/chat/hy-t1
https://huggingface.co/spaces/tencent/Hunyuan-T1
L'Hybrid-T1 est basé sur la version de début mars du TurboS TurboS est le premier modèle d'expertise (MoE) mixte à grande échelle au monde. Transformateur et Mamba. Grâce à un post-entraînement à grande échelle, les capacités d'inférence de Mamba-T1 sont considérablement étendues et mieux alignées sur les préférences humaines.
Hybrid-T1 présente des avantages uniques en matière de raisonnement profond. Tout d'abord, la capacité de TurboS à capturer des textes longs permet de résoudre efficacement les problèmes courants de perte de contexte et de dépendance à l'égard d'informations distantes dans l'inférence de textes longs. Deuxièmement, l'architecture Mamba est spécifiquement optimisée pour les séquences longues et réduit considérablement la consommation de ressources informatiques grâce à des méthodes de calcul efficaces, tout en garantissant la capacité de capturer des informations textuelles longues. Dans les mêmes conditions de déploiement, la vitesse de décodage est multipliée par 2.
Dans la phase de formation ultérieure du modèle, 96,7% des ressources informatiques sont investies dans la formation à l'apprentissage par renforcement, en se concentrant sur l'amélioration de l'inférence pure et l'optimisation de l'alignement sur les préférences humaines.
Pour atteindre cet objectif, l'équipe de recherche a rassemblé des problèmes scientifiques et de raisonnement de classe mondiale couvrant les domaines des mathématiques, du raisonnement logique, de la science et du code. Ces ensembles de données couvrent un large éventail de tâches allant du raisonnement mathématique de base à la résolution de problèmes scientifiques complexes. Ces données, combinées à un retour d'information réel (vérité de terrain), garantissent que le modèle fonctionne bien face à un large éventail de tâches de raisonnement.
La formation a été réalisée en utilisant une approche d'apprentissage par curriculum (CLE), qui augmente progressivement la difficulté des données tout en élargissant progressivement la longueur du contexte du modèle, de sorte que le modèle apprenne à l'utiliser efficacement tout en améliorant sa capacité de raisonnement jeton Raisonnement.
En termes de stratégies de formation, les stratégies classiques d'apprentissage par renforcement telles que le rejeu de données et la réinitialisation périodique de la politique sont empruntées pour améliorer la stabilité à long terme de la formation du modèle de plus de 50%. Dans la phase d'alignement sur les préférences humaines, un système de récompense unifié, comprenant des modes d'auto-récompense (évaluation complète et notation des résultats du modèle sur la base d'une version antérieure de T1-Preview) et de récompense, est utilisé pour guider le modèle vers l'auto-amélioration. Les modèles présentent un contenu plus riche et des informations plus efficaces dans leurs réponses.
En plus d'obtenir des résultats comparables ou légèrement supérieurs à ceux de DeepSeek-R1 sur les tests de référence publics de connaissance du chinois et de l'anglais, de mathématiques de niveau compétition et de raisonnement logique tels que MMLU-pro, CEval, AIME, Zebra Logic et autres, Mixed Elements-T1 obtient également de bons résultats sur les ensembles de données d'évaluation humaine interne, avec de légers avantages en matière de suivi des instructions culturelles et créatives, de résumé de texte et de compétence smart-body. .
En termes de mesures d'évaluation globale, la performance générale de l'hybride T1 est comparable à celle d'un modèle d'inférence de frontière de première classe. Dans l'évaluation des capacités globales, le modèle T1 se situe à MMLU-PRO Deuxième sur la liste après O1, l'obtention de 87.2 des scores élevés. L'ensemble du test comprend des questions dans 14 domaines des sciences humaines, des sciences sociales, des sciences et de l'ingénierie, et vise à tester la mémoire et la compréhension d'un large éventail de connaissances. En outre, en mettant l'accent sur la connaissance de domaines spécialisés et le raisonnement scientifique complexe GPQA-diamant(T1 a obtenu les résultats suivants (principalement des problèmes de niveau doctoral en physique, chimie et biologie) 69.3 Le score.
Les scénarios nécessitant de fortes capacités de raisonnement, comme le codage, les mathématiques et le raisonnement logique, ont été testés dans les domaines des sciences et de l'ingénierie. Dans le domaine de l'ingénierie, les scénarios ont été testés en sciences et en ingénierie. LiveCodeBench Dans l'évaluation du code, T1 a atteint 64.9 Score. Pendant ce temps, T1 a excellé en mathématiques. Particulièrement en MATH-500 En outre, il a rendu 96.2 Les excellents résultats obtenus à la suite de DeepSeek-R1 ont démontré la capacité globale de T1 à résoudre des problèmes mathématiques. En outre, T1 a fait preuve d'une grande capacité d'adaptation dans de multiples tâches d'alignement, de suivi de commandes et d'utilisation d'outils. Par exemple, T1 a obtenu de bons résultats dans la tâche ArenaHard La mission a été récompensée par la 91.9 Le score.
effet de modélisation


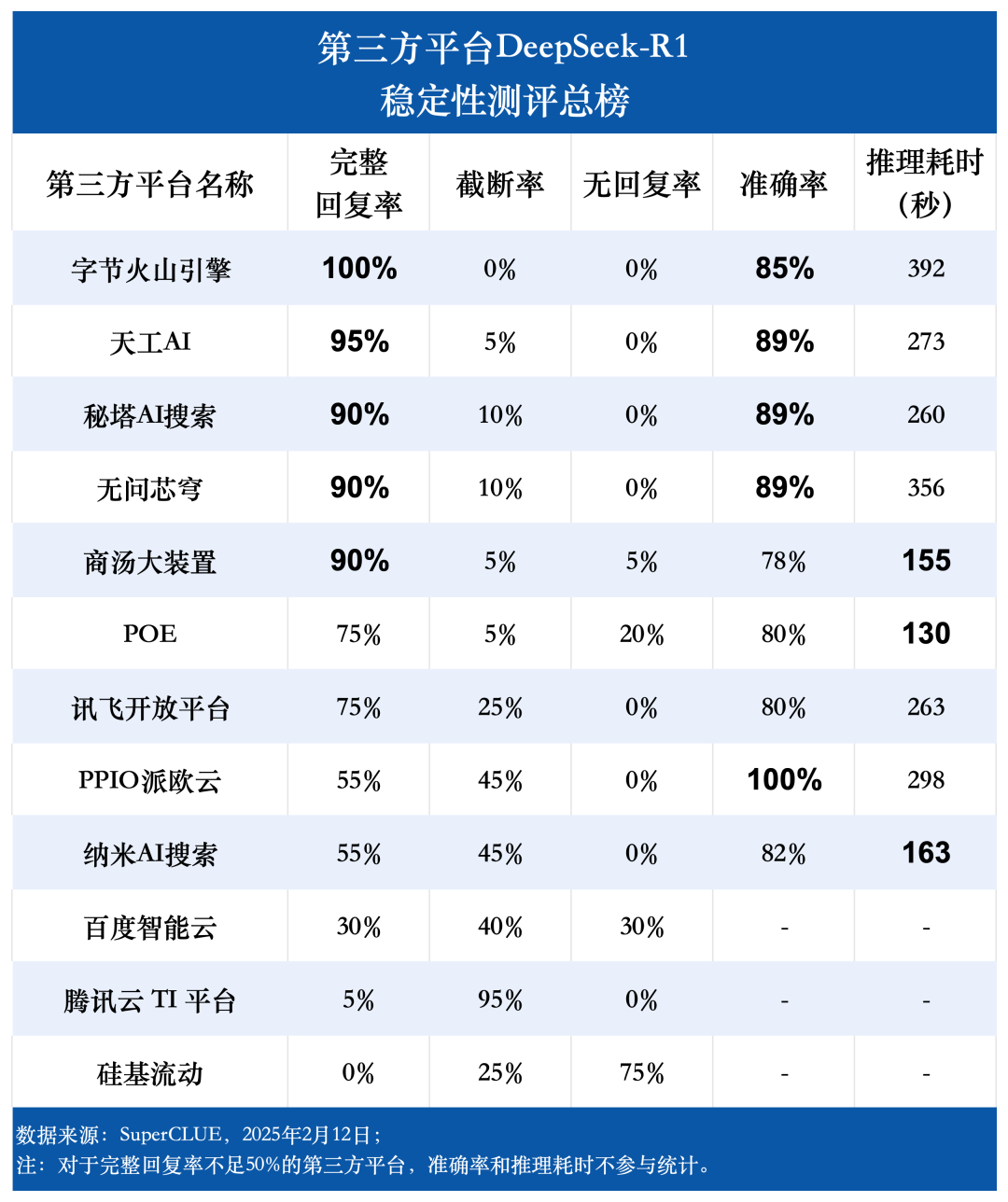
Note : Les indicateurs d'évaluation des autres modèles figurant dans le tableau proviennent des résultats d'évaluation officiels. Pour les parties qui ne sont pas incluses dans les résultats d'évaluation officiels, les données proviennent de la plateforme d'évaluation interne d'Hybrid.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...