PDF gratuit de Fundamentals of Large Models de l'Université de Zhejiang - avec lien de téléchargement

Fundamentals of Large Models fournit une analyse approfondie des technologies de base et des voies pratiques des grands modèles de langage (LLM). Partant de la théorie de base de la modélisation linguistique, il explique systématiquement les principes de la conception de modèles basés sur des architectures statistiques, de réseaux neuronaux récurrents (RNN) et de transformateurs, en se concentrant sur les trois principales architectures de grands modèles linguistiques (encodeur seul, encodeur-décodeur, décodeur seul) et sur des modèles représentatifs (par exemple, les séries BERT, T5, série GPT). Associé à de riches études de cas, le livre démontre les pratiques d'application dans différents scénarios, fournissant aux lecteurs un apprentissage complet et approfondi ainsi que des conseils pratiques, aidant les lecteurs à maîtriser l'application et l'optimisation des technologies de modélisation des langues de grande taille.

Les bases de la modélisation linguistique
- Modélisation linguistique basée sur des méthodes statistiquesLes modèles de n-grammes : une analyse approfondie des modèles de n-grammes et des statistiques qui les sous-tendent, y compris les hypothèses de Markov et l'estimation de la grande vraisemblance.
- Modélisation linguistique basée sur les RNNLes réseaux neuronaux récurrents (RNN) : une explication détaillée des caractéristiques structurelles des réseaux neuronaux récurrents (RNN), des problèmes courants de disparition et d'explosion du gradient lors de l'apprentissage, et des applications pratiques dans la modélisation des langues.
- Modélisation linguistique basée sur des transformateursLe projet "Transformer" : une analyse complète des principaux composants de l'architecture Transformer, tels que le mécanisme d'auto-attention, les réseaux neuronaux de type "feed-forward" (FFN), la normalisation des couches et la connectivité résiduelle, ainsi que leur application efficace à la modélisation linguistique.
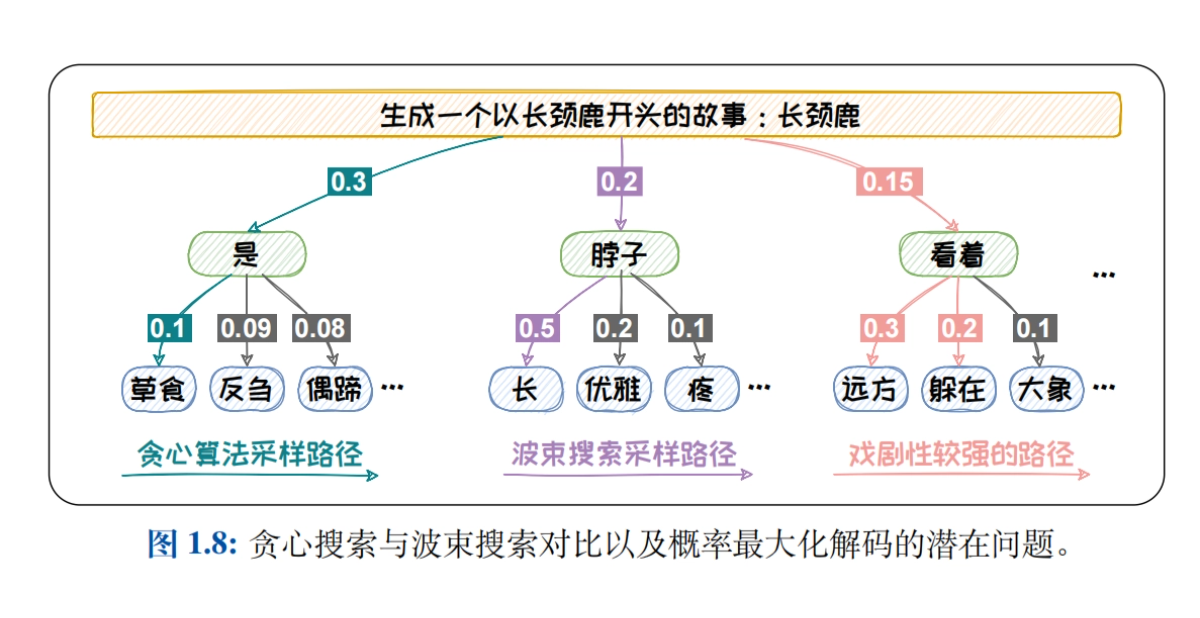
- Méthodes d'échantillonnage pour la modélisation linguistiqueLes stratégies de décodage telles que Greedy Search, Beam Search, Top-K Sampling, Top-P Sampling et le mécanisme de température sont systématiquement introduites afin d'explorer l'impact des différentes stratégies sur la qualité du texte généré.
- Examen des modèles linguistiquesLes résultats de l'évaluation des modèles de langage sont présentés de manière à analyser les points forts et les limites de chaque rubrique dans l'évaluation de la performance des modèles de langage.
Architecture du modèle de Big Language
- Big Data + Big Models → New IntelligenceCe qui suit est une analyse approfondie de l'impact de la taille du modèle et de la taille des données sur la capacité du modèle, une explication détaillée des lois d'échelle (telles que la loi de Kaplan-McCandlish et la loi de Chinchilla), et une discussion sur la façon d'améliorer la performance du modèle en optimisant la taille du modèle et des données.
- Vue d'ensemble de l'architecture du modèle Big LanguageL'objectif est de comparer et d'analyser les mécanismes d'attention et les tâches applicables à trois architectures courantes, à savoir le codeur seul, le codeur-décodeur et le décodeur seul, afin d'aider les lecteurs à comprendre les caractéristiques et les avantages des différentes architectures.
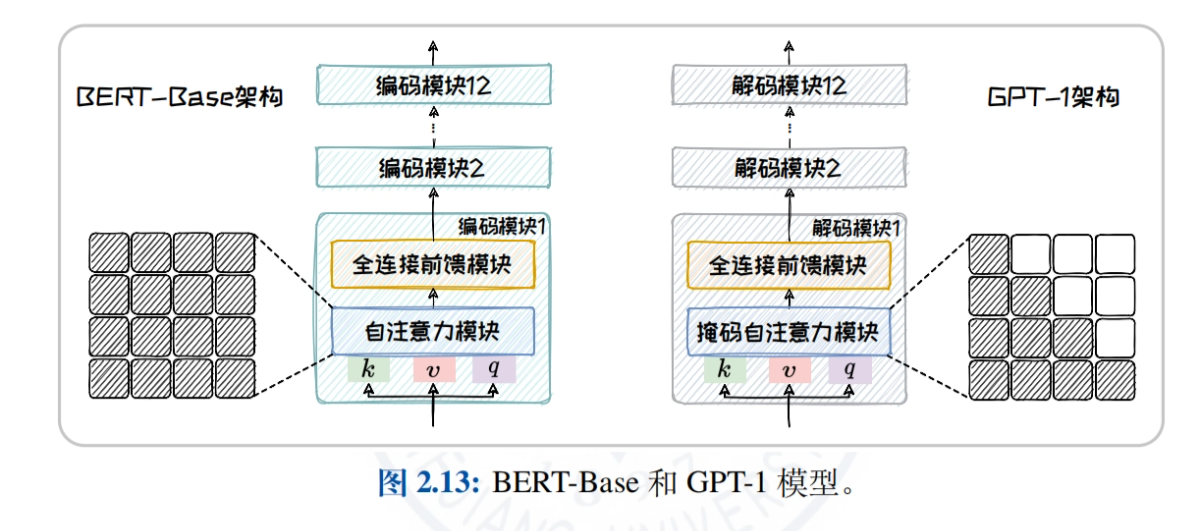
- Architecture de l'encodeur uniquementBERT : En prenant BERT comme exemple, nous expliquons en profondeur la structure de son modèle, les tâches de pré-entraînement (par exemple, MLM, NSP) et les modèles dérivés (par exemple, RoBERTa, ALBERT, ELECTRA) pour explorer l'application du modèle dans les tâches de compréhension du langage naturel.
- Architecture codeur-décodeurT5 et BART sont utilisés comme exemples pour présenter le cadre unifié de génération de texte et diverses tâches de pré-entraînement, et pour analyser les performances des modèles dans des tâches telles que la traduction automatique et le résumé de texte.
- Architecture à décodeur seul: L'histoire du développement et les caractéristiques de la famille GPT (de GPT-1 à GPT-4) et de la famille LLaMA (LLaMA1/2/3) sont décrites en détail, en explorant les avantages des modèles pour les tâches de génération de texte dans un domaine ouvert.
- architecture sans transformateurIntroduction de modèles d'espace d'état (SSM) tels que RWKV, Mamba et le paradigme Training While Testing (TTT), explorant le potentiel d'architectures non conventionnelles à appliquer dans des scénarios spécifiques.
Ingénierie rapide
- Introduction au projet PromptDéfinir Prompt et Prompt Engineering, expliquer en détail le processus de désambiguïsation et de vectorisation (Tokenization, Embedding), et explorer comment générer un texte de haute qualité grâce à un modèle d'amorçage de Prompt bien conçu.
- Apprentissage en contexte (ICL)Les modèles d'apprentissage : Présentation des concepts d'apprentissage à zéro échantillon, à un seul échantillon et à quelques échantillons, exploration des stratégies de sélection des exemples (par exemple, la similarité et la diversité) et analyse de la manière dont l'apprentissage contextuel peut être utilisé pour améliorer l'adaptabilité des modèles à une tâche donnée.
- Chaîne de pensée (CoT)Expliquer les trois modes de CoT : étape par étape (CoT, Zero-Shot CoT, Auto-CoT), réflexion (ToT, GoT) et remue-méninges (Self-Consistency), et explorer comment améliorer le raisonnement des modèles à travers la chaîne de pensée.
- Conseils pour la rédaction d'un texteIl présente des techniques telles que la standardisation de la rédaction des questions, le résumé rationnel des questions, l'utilisation des CoT au bon moment et la bonne utilisation des indices psychologiques (par exemple, le jeu de rôle, la substitution situationnelle) afin d'aider les lecteurs à améliorer la conception de leurs questions.
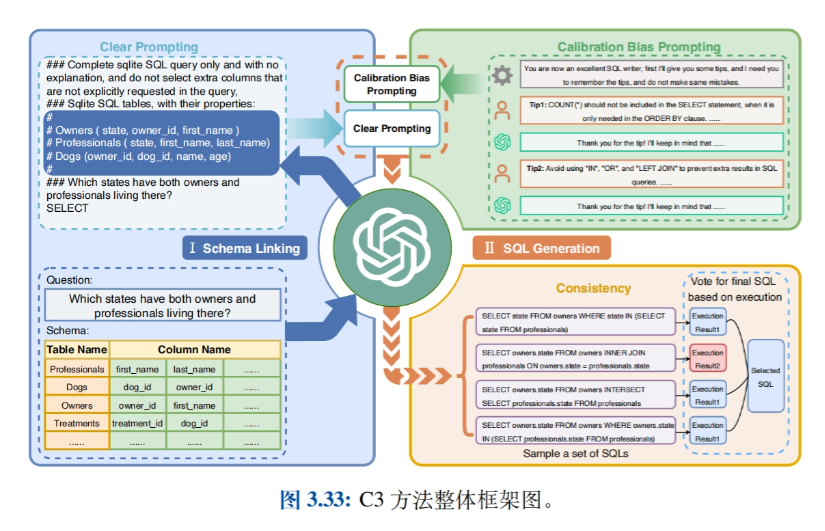
- Applications connexesLes applications telles que l'intelligence basée sur les grands modèles (agents), la synthèse de données, la conversion de texte en SQL, le GPTS, etc. sont présentées et des cas pratiques d'utilisation de l'ingénierie des messages-guides sont explorés dans différents domaines.
Réglage précis et efficace des paramètres
- Introduction à la mise au point efficace des paramètresL'article présente les deux approches dominantes de l'adaptation des tâches en aval - l'apprentissage contextuel et le réglage fin des instructions - et débouche sur la technique du réglage fin efficace des paramètres (Parameter Efficient Fine-Tuning - PEFT), dont il détaille les avantages significatifs en termes de réduction des coûts et d'efficacité.
- Méthodes de fixation des paramètresLes méthodes de mise au point efficace par l'ajout de nouveaux modules plus petits à la structure du modèle, y compris la mise en œuvre et les avantages des entrées complémentaires (par exemple, Prompt-tuning), des modèles complémentaires (par exemple, Prefix-tuning et Adapter-tuning), et des sorties complémentaires (par exemple, Proxy-tuning).
- Méthode de sélection des paramètresLe projet de recherche a pour but de présenter des méthodes permettant d'affiner seulement une partie des paramètres du modèle, divisées en méthodes basées sur des règles (par exemple, BitFit) et en méthodes basées sur l'apprentissage (par exemple, Child-tuning), en explorant comment réduire la charge de calcul et améliorer la performance du modèle en mettant à jour les paramètres de manière sélective.
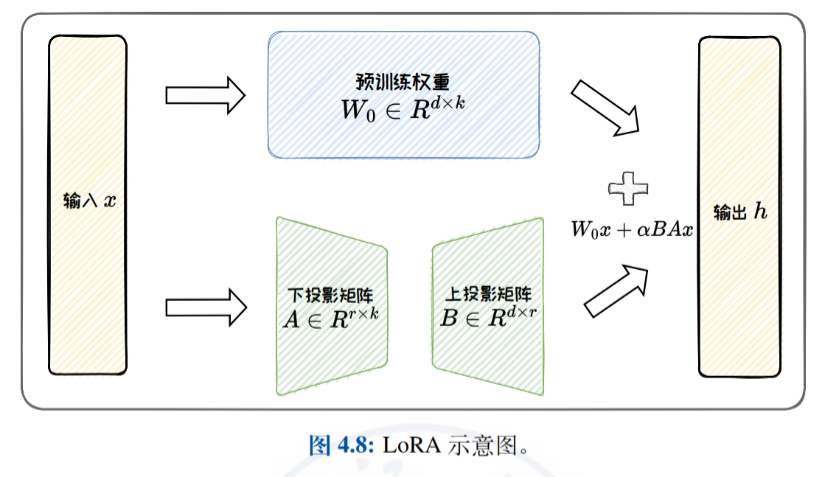
- Méthodes d'adaptation de faible rangIntroduction détaillée à la mise au point efficace par approximation de la matrice originale de mise à jour des poids par une matrice de faible rang, en mettant l'accent sur LoRA et ses variantes (par exemple, ReLoRA, AdaLoRA et DoRA), et discussion de l'efficacité paramétrique de LoRA et de ses capacités de généralisation des tâches.
- Pratique et applicationIl présente l'utilisation du cadre HF-PEFT et des techniques connexes, démontre des cas d'utilisation des techniques PEFT dans l'interrogation et l'analyse de données tabulaires, et prouve l'efficacité de PEFT dans l'amélioration de la performance de tâches spécifiques à des modèles de grande envergure.
Montage du modèle
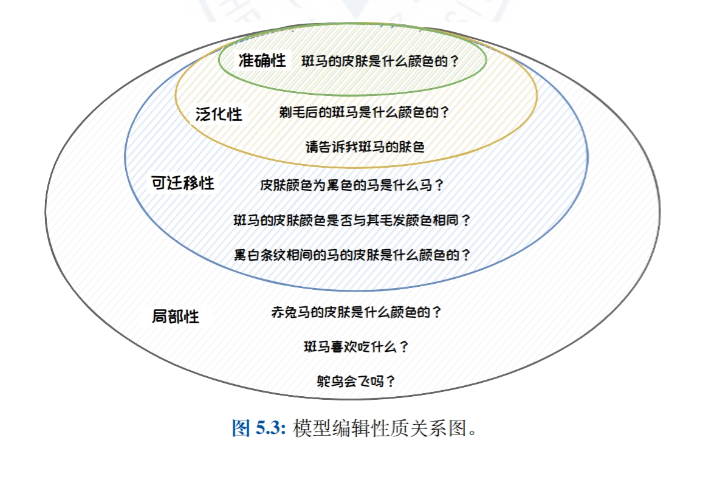
- Introduction à l'édition de modèles: Une introduction à l'idée, à la définition et à la nature de l'édition de modèles, détaillant l'importance de l'édition de modèles dans la correction des biais, de la toxicité et des erreurs de connaissance dans les grands modèles de langage.
- Approche classique de l'édition de modèlesLes méthodes d'édition de modèles sont classées en méthodes d'expansion externe (par exemple, les méthodes de mise en cache des connaissances et de paramètres supplémentaires) et en méthodes de modification interne (par exemple, les méthodes de méta-apprentissage et d'édition positionnelle), et des travaux représentatifs sont présentés pour chaque type de méthode.
- Méthode de paramétrage supplémentaire : T-PatcherLa méthode T-Patcher est décrite en détail. Elle permet un contrôle précis des résultats du modèle en y associant des paramètres spécifiques et convient aux scénarios qui nécessitent une correction rapide et précise de points de connaissance spécifiques dans le modèle.
- Méthode d'édition du lieu : ROMELa méthode ROME, qui permet un contrôle précis des résultats du modèle en localisant et en modifiant des couches ou des neurones spécifiques au sein du modèle, est adaptée aux scénarios nécessitant une modification en profondeur de la structure de connaissance interne du modèle.
- Applications d'édition de modèlesCe document présente les applications pratiques de l'édition de modèles dans la mise à jour précise des modèles, la protection du droit à l'oubli et l'amélioration de la sécurité des modèles, et démontre le potentiel d'application de la technologie de l'édition de modèles dans différents scénarios.
Génération améliorée par la recherche
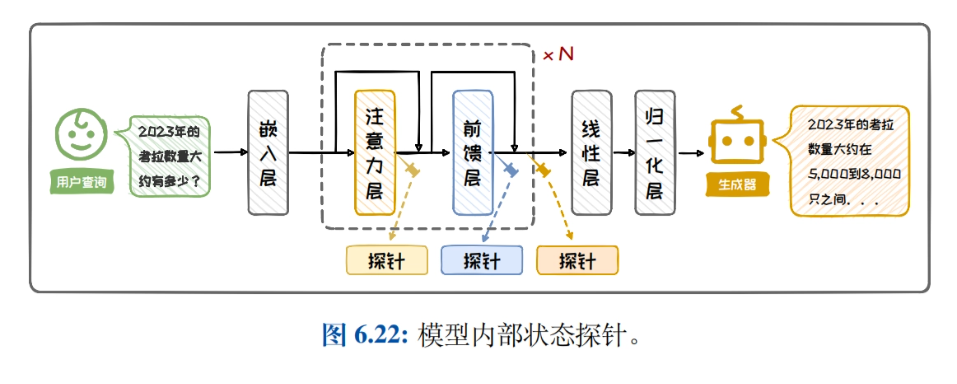
- Amélioration de la recherche Profil de générationCe document présente le contexte et la composition de la génération améliorée par la recherche, en détaillant l'importance et les scénarios d'application de l'amélioration de la performance des modèles en combinant la recherche et la génération dans les tâches de traitement du langage naturel.
- Récupération de l'architecture de génération amélioréeIl présente la classification de l'architecture RAG, l'architecture d'amélioration à boîte noire et l'architecture d'amélioration à boîte blanche, compare et analyse les caractéristiques et les scénarios applicables des différentes architectures, et aide les lecteurs à choisir l'architecture appropriée.
- recherche de connaissancesCe document présente une introduction détaillée à la construction de bases de connaissances, à l'amélioration des requêtes, aux chercheurs et à l'amélioration de l'efficacité de la recherche, en explorant la manière d'améliorer l'efficacité de la recherche et d'optimiser le processus de recherche de connaissances grâce au réarrangement des résultats de la recherche.
- Amélioration de la générationIl présente quand et où améliorer, les améliorations multiples et les méthodes de réduction des coûts, discute des stratégies d'application de l'amélioration générative à différentes tâches, et améliore la qualité et l'efficacité du texte généré.
- Pratique et applicationCe livre présente les étapes de la construction d'un système RAG simple, montre des exemples de RAG dans des applications typiques et aide les lecteurs à comprendre et à appliquer des techniques de génération améliorées par la recherche afin d'améliorer la performance de leurs modèles dans des tâches du monde réel.
Adresse de téléchargement du matériel d'information
Le rapport "Fundamentals of Large Modelling" peut être téléchargé à l'adresse suivante : https://url23.ctfile.com/f/65258023-8434020435-605e6e?p=8894 (code d'accès : 8894).
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...