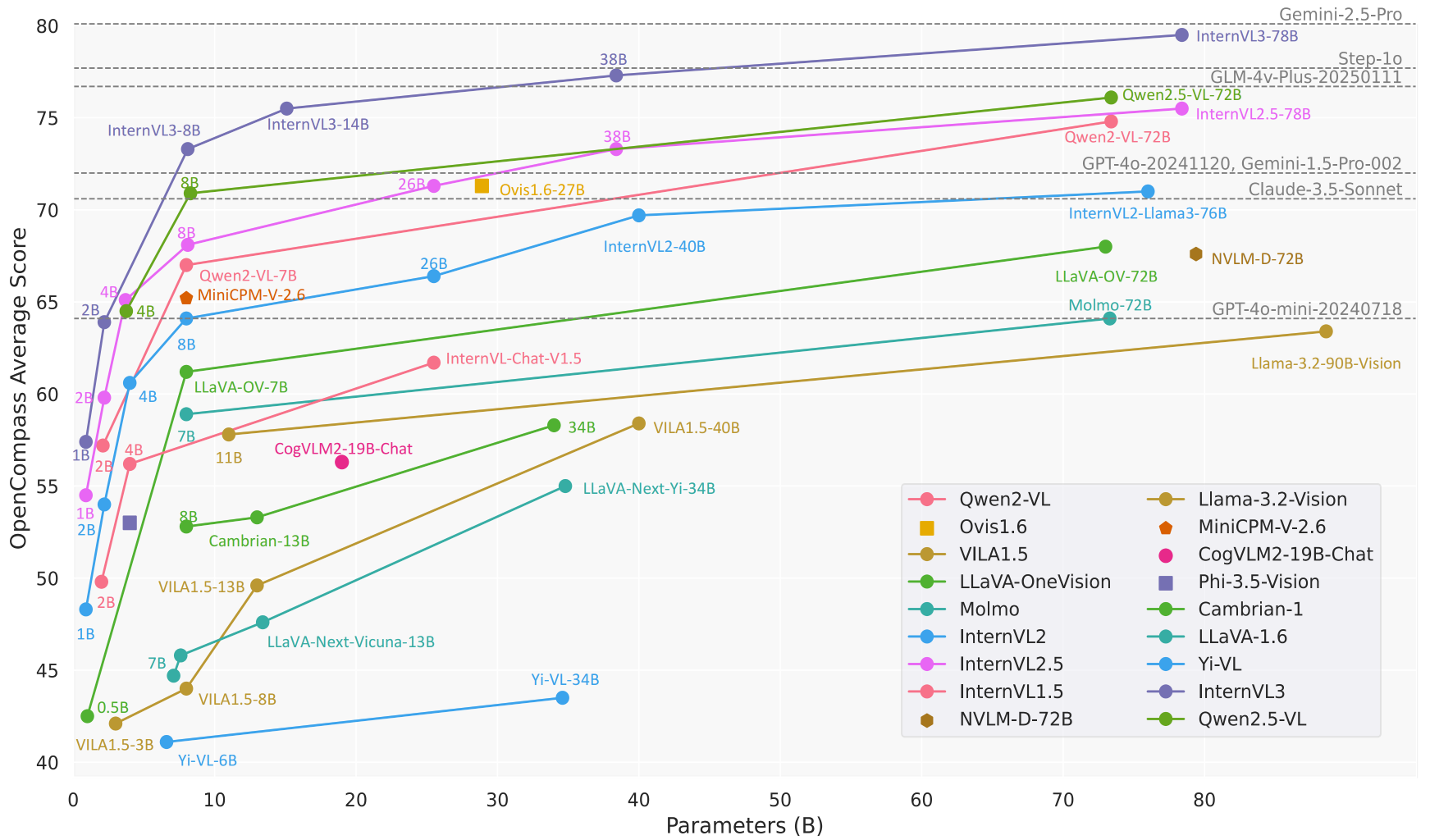
Serveur MCP Firecrawl : Service MCP de crawler Web basé sur Firecrawl

Introduction générale
Firecrawl MCP Server est un outil open source développé par MendableAI, basé sur la technologie Modèle Contexte Protocole (MCP), intégrée à l'API Firecrawl, permet de réaliser de puissantes opérations d'exploration du web et d'extraction de données. Conçue pour les modèles d'intelligence artificielle tels que Cursor, Claude et d'autres clients LLM, elle prend en charge un large éventail d'opérations, de l'exploration d'une seule page à l'exploration par lots, en passant par la recherche et l'extraction de données structurées. Qu'il s'agisse du rendu JavaScript de pages web dynamiques, de l'exploration en profondeur et du filtrage de contenu, Firecrawl MCP Server accomplit le travail efficacement. L'outil prend en charge les déploiements en nuage et auto-hébergés avec des tentatives automatiques, une limitation du taux et des systèmes de journalisation pour les développeurs, les chercheurs et les ingénieurs de données. Depuis mars 2025, le projet est continuellement mis à jour sur GitHub et est largement reconnu par la communauté.

Liste des fonctions
- Page unique Grab: extrait des données Markdown ou structurées d'une URL spécifiée.
- chenillard en vracTraitement efficace de plusieurs URL avec prise en charge du fonctionnement en parallèle et limitation intégrée du débit.
- Recherche sur le web: extrait le contenu des résultats de recherche en fonction d'une requête.
- recherche en profondeurLe système d'information sur les sites web : il prend en charge la découverte d'URL et l'exploration de sites web à plusieurs niveaux.
- extraction de donnéesLe projet de loi sur la protection de l'environnement a été adopté par l'Assemblée nationale.
- Rendu JavaScriptCapturez le contenu complet d'une page web dynamique.
- Filtration intelligenteFiltrage du contenu par inclusion/exclusion de balises.
- Surveillance des conditionsLe système d'information sur les crédits : il fournit des informations sur l'état d'avancement des tâches par lot et sur l'utilisation des crédits.
- système d'enregistrementLe système de gestion de l'information : enregistre l'état de fonctionnement, les performances et les messages d'erreur.
- Support mobile/ordinateur de bureauLes données de l'enquête sur l'utilisation de l'Internet : Adaptation aux différentes fenêtres de visualisation des appareils.
Utiliser l'aide
Processus d'installation
Le serveur Firecrawl MCP propose plusieurs méthodes d'installation pour différents scénarios d'utilisation. Les étapes suivantes sont détaillées :
Voie 1 : Exécution rapide avec npx
- Obtenez la clé API de Firecrawl (enregistrez-vous sur le site de Firecrawl pour l'obtenir).
- Ouvrez un terminal et définissez les variables d'environnement :
export FIRECRAWL_API_KEY="fc-YOUR_API_KEY"
l'interchangeabilité "fc-YOUR_API_KEY" pour votre clé actuelle.
3) Exécuter la commande :
npx -y firecrawl-mcp
- Après un démarrage réussi, le terminal affiche
[INFO] FireCrawl MCP Server initialized successfully.
Mode 2 : Installation manuelle
- Installation globale :
npm install -g firecrawl-mcp - Définir les variables d'environnement (comme ci-dessus).
- La course à pied :
firecrawl-mcp
Approche 3 : Déploiement autonome
- Cloner un dépôt GitHub :
git clone https://github.com/mendableai/firecrawl-mcp-server.git cd firecrawl-mcp-server - Installer la dépendance :
npm install - Construire un projet :
npm run build - Définissez les variables d'environnement et exécutez le programme :
node dist/src/index.js
Méthode 4 : Exécuter sur le curseur
- sécurisé Curseur Version 0.45.6 ou supérieure.
- Ouvrez Cursor Settings > Features > MCP Servers.
- Cliquez sur "+ Add New MCP Server" et entrez :
- Nom.
firecrawl-mcp - Type.
command - Commandement.
env FIRECRAWL_API_KEY=your-api-key npx -y firecrawl-mcp - Les utilisateurs de Windows qui rencontrent des problèmes peuvent essayer :
cmd /c "set FIRECRAWL_API_KEY=your-api-key && npx -y firecrawl-mcp"
- Nom.
- Sauvegarder et actualiser la liste des serveurs MCP, que Composer Agent invoque automatiquement.
Voie 5 : Courir sur une planche à voile
- compilateur
./codeium/windsurf/model_config.json: :{ "mcpServers": { "mcp-server-firecrawl": { "command": "npx", "args": ["-y", "firecrawl-mcp"], "env": { "FIRECRAWL_API_KEY": "YOUR_API_KEY_HERE" } } } } - Sauvegardez et lancez Windsurf.
Configuration des variables d'environnement
Configuration requise
FIRECRAWL_API_KEYClé de l'API du nuage : clé de l'API du nuage, qui doit être définie lors de l'utilisation des services du nuage.
Configurations optionnelles
FIRECRAWL_API_URLLes points de terminaison de l'API pour les instances auto-hébergées, tels que les points de terminaison de l'API pour les instances auto-hébergées, sont les suivantshttps://firecrawl.your-domain.com.- Réessayer la configuration :
FIRECRAWL_RETRY_MAX_ATTEMPTSNombre maximal de tentatives, par défaut 3.FIRECRAWL_RETRY_INITIAL_DELAY: Délai de la première tentative (en millisecondes), par défaut 1000.FIRECRAWL_RETRY_MAX_DELAYDélai maximum en millisecondes, par défaut 10000.FIRECRAWL_RETRY_BACKOFF_FACTOR: Le facteur de repli, par défaut 2.
- Surveillance du crédit :
FIRECRAWL_CREDIT_WARNING_THRESHOLD: Seuil d'alerte, par défaut 1000.FIRECRAWL_CREDIT_CRITICAL_THRESHOLD: Seuil d'urgence, valeur par défaut 100.
Exemple de configuration
Utilisation de l'informatique en nuage :
export FIRECRAWL_API_KEY="your-api-key"
export FIRECRAWL_RETRY_MAX_ATTEMPTS=5
export FIRECRAWL_RETRY_INITIAL_DELAY=2000
export FIRECRAWL_CREDIT_WARNING_THRESHOLD=2000
Principales fonctions
Fonction 1 : Scrape d'une seule page (firecrawl_scrape)
- procédure: :
- Après avoir démarré le serveur, envoyez une requête POST :
curl -X POST http://localhost:端口/firecrawl_scrape \ -H "Content-Type: application/json" \ -d '{"url": "https://example.com", "formats": ["markdown"], "onlyMainContent": true, "timeout": 30000}' - Renvoie le contenu principal au format Markdown.
- Après avoir démarré le serveur, envoyez une requête POST :
- Description des paramètres: :
onlyMainContentLes éléments principaux sont les seuls à être extraits.includeTags/excludeTagsLes balises HTML à inclure ou à exclure : Spécifiez les balises HTML à inclure ou à exclure.
- scénario d'applicationLes informations de base d'un article ou d'une page peuvent être extraites rapidement.
Fonction 2 : Crawl par lots (firecrawl_batch_scrape)
- procédure: :
- Envoi d'une demande groupée :
curl -X POST http://localhost:端口/firecrawl_batch_scrape \ -H "Content-Type: application/json" \ -d '{"urls": ["https://example1.com", "https://example2.com"], "options": {"formats": ["markdown"]}}' - Obtenir l'identifiant de l'opération, par exemple
batch_1. - Vérifier l'état :
curl -X POST http://localhost:端口/firecrawl_check_batch_status \ -H "Content-Type: application/json" \ -d '{"id": "batch_1"}'
- Envoi d'une demande groupée :
- caractérisationLes données sont collectées à grande échelle grâce à un système de limitation de la vitesse et de traitement parallèle intégré.
Fonction 3 : Recherche sur le web (firecrawl_search)
- procédure: :
- Envoyer une demande de recherche :
curl -X POST http://localhost:端口/firecrawl_search \ -H "Content-Type: application/json" \ -d '{"query": "AI tools", "limit": 5, "scrapeOptions": {"formats": ["markdown"]}}' - Renvoie le contenu Markdown des résultats de la recherche.
- Envoyer une demande de recherche :
- utiliserLes données de la page web sont accessibles en temps réel en fonction de la requête.
Fonction 4 : Recherche en profondeur (firecrawl_crawl)
- procédure: :
- Lancer une demande d'exploration (crawl) :
curl -X POST http://localhost:端口/firecrawl_crawl \ -H "Content-Type: application/json" \ -d '{"url": "https://example.com", "maxDepth": 2, "limit": 100}' - Renvoie les résultats de la recherche.
- Lancer une demande d'exploration (crawl) :
- paramètres: :
maxDepthcontrôler la profondeur de la marche à quatre pattes.limitLimiter le nombre de pages.
Fonction 5 : Extraction de données (firecrawl_extract)
- procédure: :
- Envoi d'une demande d'extraction :
curl -X POST http://localhost:端口/firecrawl_extract \ -H "Content-Type: application/json" \ -d '{"urls": ["https://example.com"], "prompt": "Extract product name and price", "schema": {"type": "object", "properties": {"name": {"type": "string"}, "price": {"type": "number"}}}}' - Renvoie des données structurées.
- Envoi d'une demande d'extraction :
- caractérisationSupport pour l'extraction LLM, schéma personnalisé pour assurer le format de sortie.
Conseils et astuces
- Vue du journal: Gardez un œil sur les journaux du terminal au moment de l'exécution (par ex.
[INFO] Starting scrape) pour déboguer. - traitement des erreursSi vous rencontrez
[ERROR] Rate limit exceeded, ajuster les paramètres de réessai ou attendre. - Intégration avec le LLMDans le curseur ou dans l'écran Claude L'outil est automatiquement invoqué en entrant les exigences de l'exploration directement dans le champ
Grâce à ces opérations, les utilisateurs peuvent facilement déployer et utiliser Firecrawl MCP Server pour répondre à des besoins diversifiés en matière de données web.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...