F5-TTS : clonage vocal sans échantillon pour générer des voix clonées fluides et riches en émotions

Introduction générale
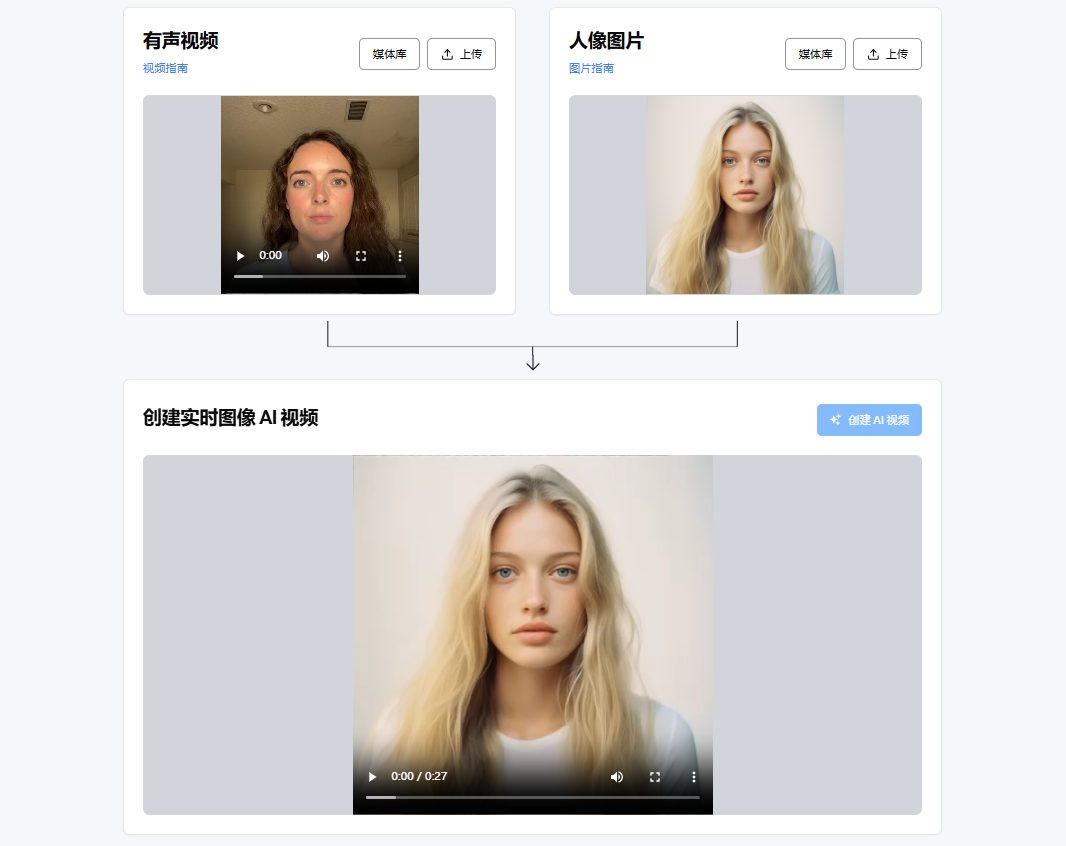
F5-TTS est un nouveau système de synthèse vocale non autorégressif basé sur un convertisseur de diffusion adapté au flux (Diffusion TransformateurF5-TTS prend en charge la formation sur des ensembles de données multilingues avec une synthèse hautement naturelle et efficace). Le système améliore considérablement la qualité et l'efficacité de la synthèse en utilisant le modèle ConvNeXt pour optimiser la représentation du texte afin de faciliter l'alignement avec la parole.F5-TTS prend en charge la formation sur des ensembles de données multilingues avec des capacités d'échantillonnage zéro hautement naturelles et expressives, une commutation de code transparente et une efficacité de contrôle de la vitesse. Le projet est open source et vise à encourager le développement de la communauté.
Ce modèle se passe des modules complexes des systèmes TTS traditionnels, tels que les modèles de durée, l'alignement des phonèmes et les codeurs de texte, et permet de générer de la parole en remplissant le texte de la même longueur que la parole d'entrée et en appliquant des méthodes de débruitage.
L'une des principales innovations du F5-TTS est la suivante Échantillonnage de l'oscillation qui améliore considérablement l'efficacité de la phase d'inférence et permet des capacités de traitement en temps réel. Cette caractéristique convient aux scénarios nécessitant une synthèse vocale rapide, tels que les assistants vocaux et les systèmes vocaux interactifs.
Support F5-TTS clonage vocal à zéro échantillonIl permet également de générer un large éventail de voix et d'accents sans nécessiter de grandes quantités de données d'apprentissage. le contrôle des émotions répondre en chantant Réglage de la vitesse Caractéristiques. Grâce à sa forte prise en charge multilingue, le système est particulièrement bien adapté aux applications qui nécessitent la génération de contenus audio diversifiés, tels que les livres audio, les modules d'apprentissage en ligne et les documents de marketing.


Liste des fonctions
- Conversion texte-parole : convertit le texte saisi en une parole naturelle et fluide.
- Génération d'échantillons zéro : génère un discours de haute qualité sans échantillons préenregistrés.
- Reproduction émotionnelle : aide à la génération de discours avec des émotions.
- Contrôle de la vitesse : l'utilisateur peut contrôler la vitesse de génération de la parole.
- Prise en charge multilingue : prise en charge de la génération vocale dans plusieurs langues.
- Code source ouvert : le code complet et les points de contrôle du modèle sont fournis pour faciliter l'utilisation et le développement par la communauté.
Utiliser l'aide
Processus d'installation
conda create -n f5-tts python=3.10 conda activate f5-tts sudo apt update sudo apt install -y ffmpeg pip uninstall torch torchvision torchaudio transformers # 安装 PyTorch(包含 CUDA 支持) pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 # 安装 transformers pip install transformers git clone https://github.com/SWivid/F5-TTS.git cd F5-TTS pip install -e . # Launch a Gradio app (web interface) f5-tts_infer-gradio # Specify the port/host f5-tts_infer-gradio --port 7860 --host 0.0.0.0 # Launch a share link f5-tts_infer-gradio --share
Commande d'installation en un clic de F5-TTS
conda create -n f5-tts python=3.10 -y && \ conda activate f5-tts && \ sudo apt update && sudo apt install -y ffmpeg && \ pip uninstall -y torch torchvision torchaudio transformers && \ pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 transformers && \ git clone https://github.com/SWivid/F5-TTS.git && \ cd F5-TTS && \ pip install -e . && \ f5-tts_infer-gradio --port 7860 --host 0.0.0.0
F5-TTS google Colab running
Remarque : l'inscription au ngrok est nécessaire pour demander une clé permettant de pénétrer dans l'intranet.

!pip install pyngrok transformers gradio
# 导入所需库
import os
from pyngrok import ngrok
!apt-get update && apt-get install -y ffmpeg
!pip uninstall -y torch torchvision torchaudio transformers
!pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 transformers
# 克隆并安装项目
!git clone https://github.com/SWivid/F5-TTS.git
%cd F5-TTS
!pip install -e .
!ngrok config add-authtoken 2hKI7tLqJVdnbgM8pxM4nyYP7kQ_3vL3RWtqXQUUdwY5JE4nj
# 配置 ngrok 和 gradio
import gradio as gr
from pyngrok import ngrok
import threading
import time
import socket
import requests
def is_port_in_use(port):
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
return s.connect_ex(('localhost', port)) == 0
def wait_for_server(port, timeout=60):
start_time = time.time()
while time.time() - start_time < timeout:
if is_port_in_use(port):
try:
response = requests.get(f'http://localhost:{port}')
if response.status_code == 200:
return True
except:
pass
time.sleep(2)
return False
# 确保 ngrok 没有在运行
ngrok.kill()
# 在新线程中启动 Gradio
def run_gradio():
import sys
import f5_tts.infer.infer_gradio
sys.argv = ['f5-tts_infer-gradio', '--port', '7860', '--host', '0.0.0.0']
f5_tts.infer.infer_gradio.main()
thread = threading.Thread(target=run_gradio)
thread.daemon = True
thread.start()
# 等待 Gradio 服务启动
print("等待 Gradio 服务启动...")
if wait_for_server(7860):
print("Gradio 服务已启动")
# 启动 ngrok
public_url = ngrok.connect(7860)
print(f"\n=== 访问信息 ===")
print(f"Ngrok URL: {public_url}")
print("===============\n")
else:
print("Gradio 服务启动超时")
# 保持程序运行
while True:
try:
time.sleep(1)
except KeyboardInterrupt:
ngrok.kill()
break
!f5-tts_infer-cli \
--model "F5-TTS" \
--ref_audio "/content/test.MP3" \
--ref_text "欢迎来到首席AI分享圈,微软发布了一款基于大模型的屏幕解析工具OmniParser.这款工具是专为增强用户界面自动化而设计的它." \
--gen_text "欢迎来到首席AI分享圈,今天将为大家详细演示另一款开源语音克隆项目。"
Processus d'utilisation
Modèles de formation
- Configurer les paramètres d'accélération, tels que l'utilisation de plusieurs GPU et de FP16 :
accelerate config - Lancer la formation :
accelerate launch test_train.py
déduction
- Télécharger les points de contrôle des modèles pré-entraînés.
- Raisonnement unique :
- Modifier le fichier de configuration pour répondre aux exigences, par exemple la durée fixe et la taille du pas :
python test_infer_single.py
- Modifier le fichier de configuration pour répondre aux exigences, par exemple la durée fixe et la taille du pas :
- Raisonnement par lots :
- Préparer l'ensemble de données de test et mettre à jour le chemin d'accès :
bash test_infer_batch.sh
- Préparer l'ensemble de données de test et mettre à jour le chemin d'accès :
Procédure d'utilisation détaillée
- Conversion texte-parole: :
- Une fois le texte saisi, le système le convertit automatiquement en parole et l'utilisateur peut sélectionner différents styles de parole et d'émotions.
- Génération d'un échantillon zéro: :
- L'utilisateur n'a pas besoin de fournir d'échantillons préenregistrés et le système génère un discours de haute qualité sur la base du texte d'entrée.
- la reproduction émotionnelle: :
- Les utilisateurs peuvent sélectionner différentes étiquettes d'émotion et le système génère un discours avec l'émotion correspondante.
- contrôle de la vitesse: :
- Les utilisateurs peuvent contrôler la vitesse de génération de la parole en ajustant les paramètres pour répondre aux besoins de différents scénarios.
- Prise en charge multilingue: :
- Le système prend en charge la génération vocale dans plusieurs langues, et les utilisateurs peuvent choisir différentes langues en fonction de leurs besoins.
F5 One-Click Installer
Quark : https://pan.quark.cn/s/3a7054a379ce
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...