ER NeRF : Construction d'un système de synthèse vidéo pour des têtes parlantes de haute fidélité

Introduction générale
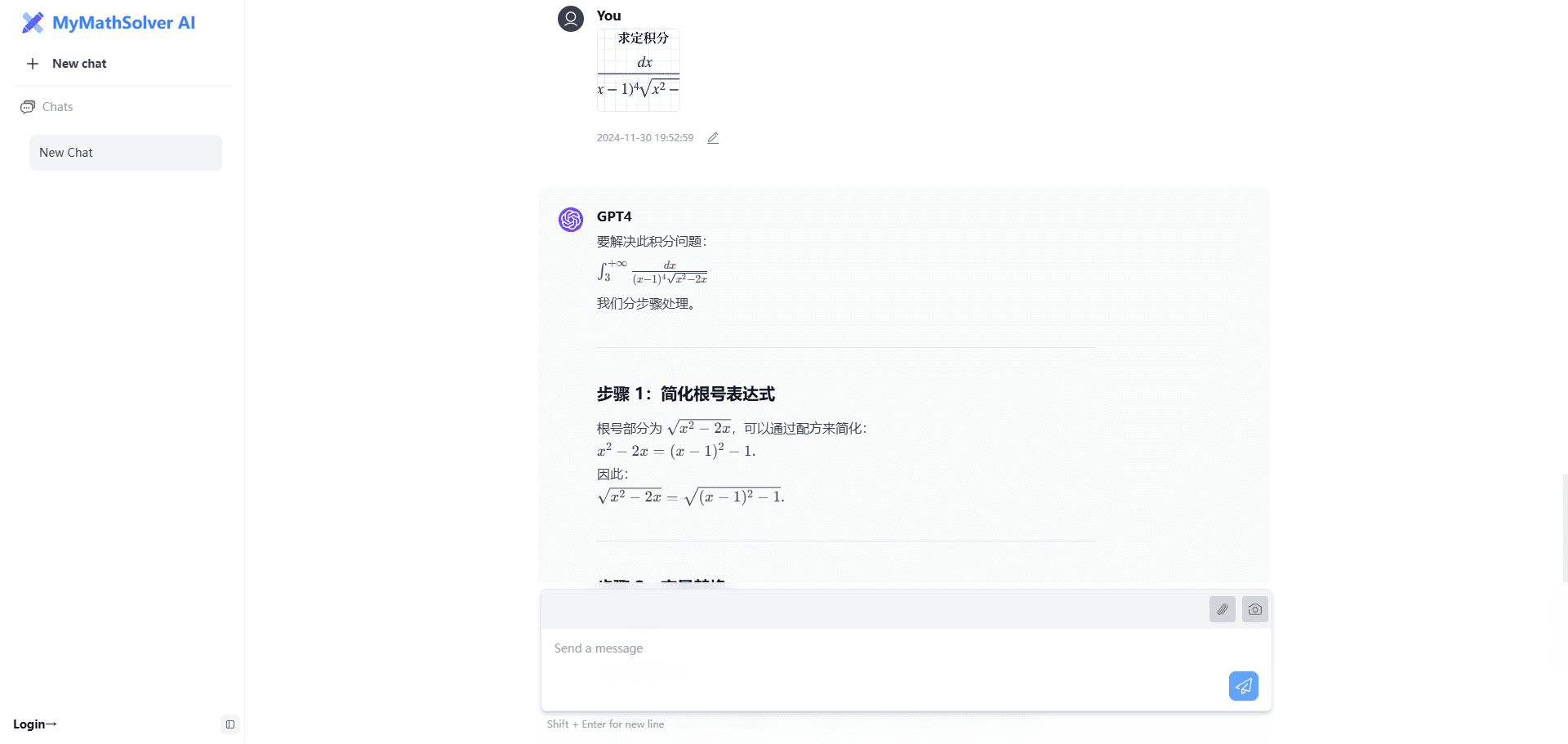
ER-NeRF (Efficient Region-Aware Neural Radiance Fields) est un système open source de synthèse de personnages parlants présenté à l'ICCV 2023. Le projet utilise la technique Region-Aware Neural Radiance Fields pour générer efficacement des vidéos de haute fidélité de personnages parlants. Les principales caractéristiques du système sont un schéma de traitement régionalisé qui modélise la tête et le torse du personnage séparément, et une technique innovante de décomposition de l'espace audio qui permet une synchronisation labiale plus précise. Le projet fournit un code d'entraînement et d'inférence complet, prend en charge les vidéos d'entraînement personnalisées et peut utiliser différents extracteurs de caractéristiques audio (par exemple, DeepSpeech, Wav2Vec, HuBERT, etc.) pour traiter l'entrée audio. Le système réalise des améliorations significatives à la fois en termes de qualité visuelle et d'efficacité de calcul, fournissant une solution technique importante dans le domaine de la synthèse de caractères parlants.
Nouveau projet : https://github.com/Fictionarry/TalkingGaussian

Liste des fonctions
- Composition vidéo haute fidélité de têtes parlantes
- Rendu neuronal du champ de rayonnement pour la perception des zones
- Permet de modéliser séparément la tête et le torse
- Synchronisation précise des lèvres
- Prise en charge de l'extraction de caractéristiques audio multiples (DeepSpeech/Wav2Vec/HuBERT)
- Support de formation vidéo personnalisé
- Génération d'animations de personnages pilotées par l'audio
- Contrôle des mouvements de la tête en douceur
- Prise en charge du mouvement de clignotement (fonction AU45)
- Fonction d'optimisation du réglage fin LPIPS
Utiliser l'aide
1. configuration de l'environnement
Exigences relatives à l'environnement d'exploitation du système :
- Système d'exploitation Ubuntu 18.04
- PyTorch version 1.12
- CUDA 11.3
Étapes de l'installation :
- Créer un environnement conda :
conda create -n ernerf python=3.10
conda install pytorch==1.12.1 torchvision==0.13.1 cudatoolkit=11.3 -c pytorch
pip install -r requirements.txt
- Installer les dépendances supplémentaires :
pip install "git+https://github.com/facebookresearch/pytorch3d.git"
pip install tensorflow-gpu==2.8.0
2. préparation des modèles de prétraitement
Les fichiers modèles suivants doivent être téléchargés et préparés :
- Modèle d'analyse des visages
- Modèle d'estimation de l'attitude de la tête 3DMM
- Bâle Face Model 2009
3. personnaliser le processus de formation vidéo
- Préparation de la vidéo :
- Format : MP4
- Taux de rafraîchissement : 25FPS
- Résolution : 512x512 recommandée
- Durée : 1-5 minutes
- Chaque image doit contenir des caractères parlants
- Prétraitement des données :
python data_utils/process.py data/<ID>/<ID>.mp4
- Extraction de caractéristiques audio (une parmi trois) :
- Extraction des caractéristiques de DeepSpeech :
python data_utils/deepspeech_features/extract_ds_features.py --input data/<n>.wav
- Extraction de caractéristiques Wav2Vec :
python data_utils/wav2vec.py --wav data/<n>.wav --save_feats
- Extraction des caractéristiques HuBERT (recommandée) :
python data_utils/hubert.py --wav data/<n>.wav
4. formation au modèle
La formation est divisée en deux phases : la formation de la tête et la formation du tronc :
- Formation des chefs :
python main.py data/obama/ --workspace trial_obama/ -O --iters 100000
python main.py data/obama/ --workspace trial_obama/ -O --iters 125000 --finetune_lips --patch_size 32
- Entraînement du torse :
python main.py data/obama/ --workspace trial_obama_torso/ -O --torso --head_ckpt <head>.pth --iters 200000
5. tests de modèles et inférence
- Tester les effets du modèle :
# 仅渲染头部
python main.py data/obama/ --workspace trial_obama/ -O --test
# 渲染头部和躯干
python main.py data/obama/ --workspace trial_obama_torso/ -O --torso --test
- Raisonner avec l'audio cible :
python main.py data/obama/ --workspace trial_obama_torso/ -O --torso --test --test_train --aud <audio>.npy
Conseil : l'ajout du paramètre --smooth_path réduit l'instabilité de la tête, mais peut réduire la précision de l'attitude.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...