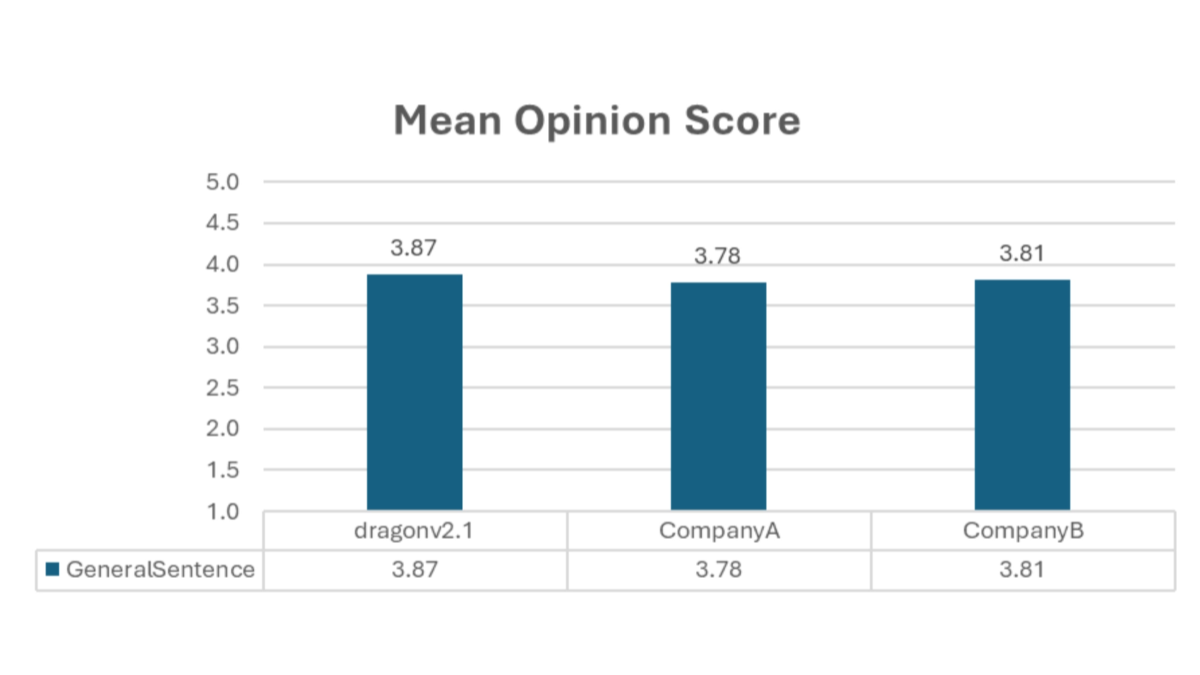
DragonV2.1 - Modèles de synthèse vocale sans échantillon de Microsoft

Qu'est-ce que DragonV2.1 ?
DragonV2.1 est un modèle avancé de synthèse vocale sans échantillon de Microsoft. Ce modèle est basé sur Transformateur L'architecture prend en charge le clonage vocal multilingue et sans échantillon, générant un discours naturel et expressif en seulement 5 à 90 secondes de messages vocaux. Le modèle offre des améliorations significatives en termes de précision, de naturel et de contrôle de l'articulation, et prend en charge l'étiquetage des phonèmes SSML et les dictionnaires personnalisés pour un contrôle précis de la prononciation et de l'accent. DragonV2.1 peut être largement utilisé pour la création de contenu vidéo, le service client intelligent, l'éducation et la formation, les assistants intelligents et la stratégie de marque des entreprises, offrant aux utilisateurs des solutions de synthèse vocale efficaces et personnalisées.
Principales caractéristiques de DragonV2.1
- Obtenir des échantillons de voixPréparer un message vocal de 5 à 90 secondes qui sera utilisé pour générer une copie vocale personnalisée.
- Sélectionner la langue et l'accentLangues : Sélectionnez les langues prises en charge et les accents spécifiques (par ex. anglais britannique, anglais américain, etc.) en fonction des besoins.
- Contrôler la prononciation avec SSMLContrôle précis de la prononciation, de l'intonation et du rythme de la parole grâce aux balises SSML et aux dictionnaires personnalisés.
- Générer un discoursLe texte est introduit dans le modèle, qui génère une parole naturelle et expressive en fonction des paramètres.
- Techniques de filigrane appliquéesLes services d'aide à l'enfance et à la famille : Veiller à ce que le contenu vocal généré soit protégé par un filigrane afin d'éviter toute utilisation abusive.
Site officiel de DragonV2.1
- Site web du projet: https://techcommunity.microsoft.com/blog/azure-ai-services-blog/personal-voice-upgraded-to-v2-1-in-azure-ai-speech-more- expressive-than-ever-bef/4435233
Comment utiliser DragonV2.1
Obtenir le modèle
- Obtenir le modèle: à la mi-août 2025 par l'intermédiaire du service Azure AI Speech Service.
BaseModels_ListOpération Rechercher et obtenir le nom du modèleDragonV2.1Neural. - Préparation d'échantillons vocauxEnregistrement d'un échantillon vocal clair de 5 à 90 secondes qui peut être utilisé pour générer une copie personnalisée de votre voix à télécharger sur Azure Storage ou d'autres services de stockage pris en charge.
- Configuration du clonage vocalPour cela, vous devez vous connecter au service Azure AI Speech, sélectionner la fonction de clonage vocal DragonV2.1, télécharger des échantillons de voix et définir des paramètres tels que la langue et l'accent.
- Rédiger des documents SSMLLes fichiers sont écrits en SSML (Speech Synthesis Markup Language), qui sont utilisés pour contrôler avec précision l'articulation, l'intonation et le rythme de la parole, et sont téléchargés vers le service vocal.
- Générer un discoursLes fonctionnalités de DragonV2.1 sont les suivantes : invocation du modèle DragonV2.1 via l'API du service Azure AI Speech ou le portail Azure, saisie de texte ou de fichiers SSML, génération de la parole et vérification des résultats de la génération.
Principaux avantages de DragonV2.1
- Génération de parole personnalisée à faible seuilLa nouvelle technologie est conçue pour générer une voix personnalisée à partir d'un échantillon vocal très court, ce qui réduit considérablement le seuil technique du clonage vocal et permet à un plus grand nombre d'utilisateurs d'obtenir facilement leur propre voix.
- Des interactions en temps réel très efficacesLe système d'interaction en temps réel : avec une latence ultra-faible et un temps réel élevé, il peut rapidement générer de la parole pour répondre aux besoins des scénarios d'interaction en temps réel, tels que le service client intelligent et la diffusion en direct.
- Sortie vocale de haute qualitéLe dernier ajout à l'architecture Transformer est une nouvelle génération de parole naturelle et fluide, qui améliore considérablement la qualité globale de la synthèse vocale et offre aux utilisateurs une meilleure expérience d'écoute.
- Personnalisation flexible de la voixLe système de gestion de l'information : Hautement personnalisable par les utilisateurs en fonction de leurs besoins spécifiques afin de répondre à divers scénarios d'application.
- Une puissante capacité d'adaptation linguistiqueLa synthèse vocale : elle ajuste automatiquement l'émotion et l'accent en fonction du contexte, s'adaptant ainsi aux besoins de la synthèse vocale dans des environnements linguistiques différents.
- Sécurité dans la synthèse vocaleLa synthèse vocale : prévenir efficacement l'utilisation abusive du contenu de la synthèse vocale et garantir la conformité et la sécurité de la synthèse vocale.
Qui peut utiliser DragonV2.1 ?
- créateur de contenuLes producteurs vidéo et les créateurs de contenu audio ajoutent des voix off personnalisées à leur travail afin d'améliorer l'attrait de leur contenu.
- Entreprises et marquesLes entreprises créent rapidement des images vocales spécifiques à leur marque pour les utiliser dans la publicité et le service à la clientèle afin d'améliorer la reconnaissance de la marque.
- Établissements d'enseignement et enseignantsLe domaine de l'éducation aide les étudiants à pratiquer la prononciation et l'écoute afin d'améliorer l'enseignement et l'apprentissage.
- Développeur technologiqueLes développeurs intègrent des fonctions d'interaction vocale naturelle dans les assistants intelligents, les maisons intelligentes et d'autres applications afin d'améliorer l'expérience de l'utilisateur.
- utilisateur individuelLes utilisateurs individuels, en particulier les apprenants de langues, s'exercent à la prononciation et améliorent leurs compétences linguistiques grâce à une synthèse vocale de haute qualité.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes




Pas de commentaires...