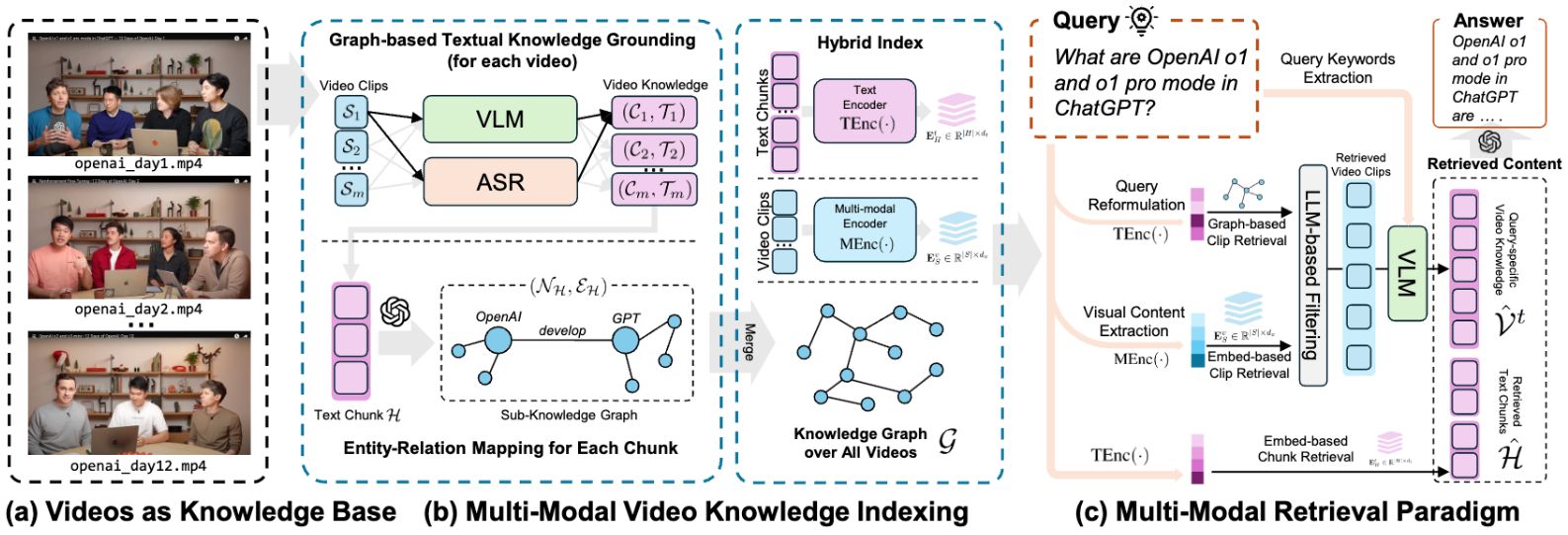
DeepResearcher : IA de conduite basée sur l'apprentissage par renforcement pour étudier les problèmes complexes

Introduction générale
DeepResearcher est un projet open source développé par l'équipe GAIR-NLP de l'Université Jiao Tong de Shanghai. Il s'agit d'un outil de recherche intelligent basé sur de grands modèles de langage (LLM), formés de bout en bout dans un environnement de réseau réel grâce à l'apprentissage par renforcement (RL). Le projet vise à aider les utilisateurs à accomplir efficacement des tâches de recherche complexes. Il recherche automatiquement des informations, vérifie l'exactitude des données et génère des résultats détaillés. DeepResearcher prend en charge 7B modèles paramétriques et a été mis en open source sur Hugging Face. Le code est disponible sur GitHub et convient aux chercheurs, aux étudiants et aux passionnés de technologie.


Liste des fonctions
- Recherche en automatisationLe site Internet de la Commission européenne : Lorsqu'une question est posée, une recherche est automatiquement effectuée sur le web et les informations pertinentes sont rassemblées.
- l'authentification intersourceLes résultats de l'enquête doivent être vérifiés à partir de plusieurs sources (par exemple, Google, Bing) afin d'assurer la fiabilité des résultats.
- Ajustements autoréflexifsLes résultats de la recherche doivent être évalués et la recherche doit être réorientée afin d'en améliorer la précision.
- Développement d'un programme de rechercheLes outils de recherche : Générer automatiquement des étapes de recherche lorsqu'il s'agit de traiter des problèmes complexes.
- Restez honnête.Les limites sont énoncées directement lorsqu'aucune réponse claire ne peut être trouvée.
- Prise en charge des modèles open sourceLe modèle paramétrique 7B est fourni et peut être téléchargé et personnalisé par l'utilisateur.
Utiliser l'aide
L'installation et l'utilisation de DeepResearcher nécessitent un certain niveau de connaissances techniques, mais la documentation officielle fournit des directives claires. Vous trouverez ci-dessous des étapes détaillées pour aider les utilisateurs à démarrer rapidement.
Processus d'installation
- Cloner le dépôt de code
Exécutez la commande suivante dans le terminal pour télécharger le projet localement :
git clone https://github.com/GAIR-NLP/DeepResearcher.git
Accédez au catalogue de projets :
cd DeepResearcher
- Créer un environnement virtuel
Utilisez conda pour créer un environnement Python distinct et éviter les conflits de dépendances :
conda create -n deepresearcher python=3.10
Activer l'environnement :
conda activate deepresearcher
- Installation des dépendances de base
Installez PyTorch et les autres bibliothèques nécessaires en exécutant les commandes suivantes dans l'ordre à partir du répertoire racine du projet :
pip3 install torch==2.4.0 --index-url https://download.pytorch.org/whl/cu124
pip3 install flash-attn --no-build-isolation
cd verl
pip3 install -e .
cd ../
pip3 install -r requirements.txt
Ces étapes permettent de s'assurer que l'environnement de base nécessaire à l'exécution du modèle est en place.
- Vérifier l'installation
Entrez la commande suivante pour vérifier si PyTorch est installé correctement :
python -c "import torch; print(torch.__version__)"
Si le numéro de version s'affiche (par exemple 2.4.0), l'installation a réussi.
Configuration et démarrage
DeepResearcher utilise le framework Ray pour l'entraînement et l'inférence, et nécessite également la configuration du service de recherche. Voici comment procéder.
Démarrage du service Ray
- Définition du classement des nœuds
Entrez la commande suivante dans le terminal pour définir le numéro de nœud (cela est nécessaire même s'il n'y a qu'une seule machine) :
export PET_NODE_RANK=0
ray start --head
- Configuration des services de recherche
- spectacle (un billet)
./scrl/handler/config.yamlSi vous souhaitez modifier la clé API de recherche, vous pouvez le faire en cliquant sur le bouton "Recherche" :- Utilisation de l'API Serper : remplir le formulaire
serper_api_key. - Utiliser Azure Bing : remplir
azure_bing_search_subscription_keyet mettre en placesearch_enginepour Bing.
- Utilisation de l'API Serper : remplir le formulaire
- compilateur
./scrl/handler/server_handler.pySi vous souhaitez ajouter une clé API Qwen-Plus, ajoutez la clé API Qwen-Plus :client = OpenAI( api_key="sk-xxx", base_url="xxxx" )
- Démarrage du Service Processor
S'exécute dans le terminal :
python ./scrl/handler/server_handler.py
Après le démarrage du service, enregistrez l'adresse du service et mettez à jour la rubrique ./scrl/handler/config.yaml a fait mouche server_url_list.
- Fonctionnement du processeur principal
S'exécute sur l'hôte de formation :
python ./scrl/handler/handler.py
Modèles de formation
- Exécution de scripts de formation
Exécutez-le dans le répertoire racine du projet :
bash train_grpo.sh
Le processus de formation optimisera le modèle en se basant sur l'apprentissage par renforcement et requiert de la patience.
Utilisation et raisonnement
- Produire des résultats de recherche
Exécutez le script d'évaluation :
bash evaluate.sh
Le fichier de sortie est enregistré dans le répertoire ./outputs/{project_name}/{experiment_name}/rollout/rollout_step_0.json.
- Voir les résultats
Renommer le fichier de sortie en{experiment_name}_result.jsonPasser à./evaluate/et l'exécuter :
python ./evaluate/cacluate_metrics.py {experiment_name}
Le score est sauvegardé dans la base de données ./evaluate/{experiment_name}_score.json.
Fonction en vedette Fonctionnement
- Recherche automatisée et validation croisée des sources
Après que l'utilisateur a saisi une question, DeepResearcher recueille des données auprès des moteurs de recherche configurés (par exemple Google, Bing) et procède à une validation croisée des résultats. Fichiers journaux./outputs/research_log.txtLe processus de validation sera documenté. - Ajustements autoréflexifs
Si les premiers résultats ne sont pas satisfaisants, le système ajustera automatiquement les mots-clés ou la stratégie de recherche. Par exemple, si l'on tape "Applications de l'IA dans le domaine de la santé", on peut passer à "Dernières technologies médicales de l'IA", ce qui permet d'obtenir des résultats plus précis. - Restez honnête.
Lorsqu'il n'y a pas de réponse claire à une question, il renvoie quelque chose comme "il n'y a pas assez d'informations pour donner une conclusion définitive" au lieu de deviner.
mise en garde
- Assurez-vous que votre connexion internet est stable et que la fonction de recherche repose sur des données en temps réel.
- L'entraînement et l'inférence nécessitent des ressources informatiques importantes et les GPU sont recommandés.
- Le projet étant encore en cours de développement, nous vous recommandons de suivre les mises à jour sur GitHub.
Avec ces étapes, les utilisateurs peuvent facilement installer et utiliser DeepResearcher pour expérimenter ses capacités de recherche intelligente.
scénario d'application
- recherche universitaire
Les chercheurs peuvent l'utiliser pour rechercher des documents papier, vérifier les sources et produire les premières ébauches de rapports de recherche. - Apprentissage des élèves
Les étudiants peuvent l'utiliser pour organiser les connaissances liées aux cours et réaliser rapidement des travaux ou des recherches sur des projets. - développement technologique
Les développeurs peuvent l'utiliser pour explorer les tendances technologiques et obtenir des mises à jour et des solutions sectorielles.
QA
- DeepResearcher prend-il en charge le chinois ?
Prise en charge. Les utilisateurs peuvent saisir des questions en chinois et l'application donnera la priorité à la recherche de ressources en chinois et pourra également traiter des données en anglais. - Besoin d'un GPU ?
Ce n'est pas obligatoire, mais le GPU peut accélérer l'entraînement et l'inférence. Le CPU peut également le faire fonctionner, mais plus lentement. - Comment obtenir la dernière version ?
Exécuter dans le répertoire du projetgit pullpuis réinstallez les dépendances à mettre à jour.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes

Pas de commentaires...