
Comment les grands modèles deviennent-ils plus "intelligents" ? L'université de Stanford révèle la clé de l'amélioration de soi : quatre comportements cognitifs

Le domaine de l'intelligence artificielle a fait des progrès impressionnants ces dernières années, en particulier dans le domaine de la modélisation des grandes langues (LLM). De nombreux modèles, tels que Qwen, ont fait preuve d'une capacité étonnante à vérifier eux-mêmes leurs réponses et à corriger leurs erreurs. Cependant, tous les modèles n'ont pas la même capacité d'auto-amélioration. Avec les mêmes ressources informatiques supplémentaires et le même temps de "réflexion", certains modèles sont capables de tirer le meilleur parti de ces ressources et d'améliorer considérablement leurs performances, tandis que d'autres n'obtiennent que peu de résultats. Ce phénomène soulève la question suivante : quels sont les facteurs responsables de cet écart ?
Tout comme les êtres humains passent plus de temps à réfléchir en profondeur lorsqu'ils sont confrontés à des problèmes difficiles, certains modèles avancés de grands langages commencent à afficher un comportement de raisonnement similaire lorsqu'ils sont formés à l'auto-amélioration par l'apprentissage par renforcement. Cependant, il existe des différences significatives dans l'auto-amélioration entre les modèles formés avec le même apprentissage par renforcement. Par exemple, Qwen-2.5-3B surpasse de loin Llama-3.2-3B dans le jeu Countdown. Bien que les deux modèles soient relativement faibles au stade initial, à la fin de la formation par apprentissage par renforcement, Qwen atteint une précision d'environ 60%, tandis que Llama n'est qu'à environ 30%. Quel est le mécanisme caché à l'origine de cet écart significatif ?
Une étude récente de Stanford a permis d'approfondir les mécanismes qui sous-tendent la capacité des grands modèles à s'auto-améliorer, en révélant que des modèles linguistiques clés dans le système sous-jacent d'analyse de l'information sont à l'origine de l'amélioration de la qualité de l'information. comportement cognitif L'importance de l'IA. Cette recherche offre de nouvelles perspectives pour comprendre et améliorer les capacités d'auto-amélioration des systèmes d'IA.
L'étude a été largement commentée dès sa publication. Le PDG de Synth Labs, par exemple, estime que cette découverte est passionnante car elle promet d'être intégrée dans n'importe quel modèle pour en améliorer les performances.

Quatre comportements cognitifs clés
Afin d'étudier les raisons de ces différences, les chercheurs se sont concentrés sur deux modèles de base, Qwen-2.5-3B et Llama-3.2-3B. En les entraînant avec l'apprentissage par renforcement dans le jeu Countdown, les chercheurs ont observé des différences significatives : la capacité de résolution de problèmes de Qwen s'est améliorée de manière significative, tandis que Llama-3 a montré une amélioration relativement limitée au cours du même processus d'entraînement. Quelles sont donc les propriétés du modèle qui expliquent cette différence ?

Afin d'examiner systématiquement cette question, l'équipe de recherche a mis au point un cadre d'analyse des comportements cognitifs essentiels à la résolution de problèmes. Ce cadre décrit quatre comportements cognitifs clés :
- Vérification: : Vérification systématique des erreurs.
- Retour en arrièreLes résultats de l'évaluation des risques : : Abandonner les approches qui ont échoué et essayer de nouvelles voies.
- Définition des sous-objectifsLes problèmes complexes sont décomposés en étapes faciles à gérer.
- Penser à l'enversLa dérivation inversée : dérivation inversée du résultat souhaité à l'entrée initiale.
Ces modèles de comportement sont très similaires à la manière dont les experts en résolution de problèmes abordent les tâches complexes. Par exemple, les mathématiciens effectuent des preuves en vérifiant soigneusement chaque étape de la dérivation, en revenant en arrière pour vérifier les étapes précédentes en cas de contradictions, et en décomposant les théorèmes complexes en lemmes plus simples pour des preuves étape par étape.

Les analyses préliminaires indiquent que le modèle Qwen présente naturellement ces comportements d'inférence, en particulier dans les domaines de la validation et du retour en arrière, alors que le modèle Llama-3 en est manifestement dépourvu. Sur la base de ces observations, les chercheurs ont formulé l'hypothèse centrale : Certains comportements de raisonnement dans la stratégie initiale sont essentiels pour que le modèle utilise efficacement le temps de test accru. En d'autres termes, si un modèle d'IA veut devenir "plus intelligent" lorsqu'il dispose de plus de temps pour "penser", il doit d'abord posséder certaines compétences de base en matière de réflexion, comme l'habitude de rechercher les erreurs et de vérifier les résultats. Si le modèle ne possède pas ces compétences de base dès le départ, il ne sera pas en mesure d'améliorer efficacement ses performances, même si on lui donne plus de temps de réflexion et de ressources informatiques. Si les étudiants ne disposent pas des compétences de base en matière d'autocontrôle et de correction des erreurs, le simple fait de passer des examens plus longs n'améliorera probablement pas leurs performances de manière significative.
Validation expérimentale : l'importance du comportement cognitif
Pour tester l'hypothèse ci-dessus, les chercheurs ont mené une série d'expériences d'intervention astucieuses.
Tout d'abord, ils ont tenté d'amorcer le modèle Llama-3 en utilisant des trajectoires d'inférence synthétiques contenant des comportements cognitifs spécifiques (en particulier la rétrospection). Les résultats montrent que le modèle Llama-3 ainsi guidé présente des améliorations significatives en matière d'apprentissage par renforcement, avec des gains de performance même comparables à Qwen-2.5-3B.
Deuxièmement, même si les trajectoires de raisonnement utilisées pour le bootstrapping contenaient des réponses incorrectes, le modèle Llama-3 était toujours capable de progresser tant que ces trajectoires présentaient des schémas de raisonnement corrects. Cette constatation suggère que le modèle Le facteur clé de l'auto-amélioration du modèle est la présence d'un comportement de raisonnement, et non l'exactitude de la réponse elle-même.
Enfin, les chercheurs ont filtré l'ensemble de données OpenWebMath pour mettre l'accent sur ces comportements de raisonnement et ont utilisé ces données pour pré-entraîner le modèle Llama-3. Les résultats expérimentaux montrent que cette adaptation ciblée des données de pré-entraînement est efficace pour induire les comportements d'inférence nécessaires pour que le modèle utilise efficacement les ressources informatiques. La trajectoire d'amélioration des performances du modèle Llama-3 pré-entraîné est étonnamment cohérente avec celle du modèle Qwen-2.5-3B.
Les résultats de ces expériences révèlent un lien étroit entre le comportement initial de raisonnement d'un modèle et sa capacité à s'améliorer. Ce lien permet d'expliquer pourquoi certains modèles de langage sont capables d'utiliser efficacement des ressources informatiques supplémentaires, alors que d'autres stagnent. Une compréhension plus approfondie de cette dynamique est essentielle pour développer des systèmes d'intelligence artificielle capables d'améliorer de manière significative la résolution de problèmes.
Jeu de compte à rebours avec sélection de modèles
L'étude s'ouvre sur une observation surprenante : des modèles de langage de taille similaire, issus de familles de modèles différentes, présentent des améliorations de performance très différentes lorsqu'ils sont entraînés avec l'apprentissage par renforcement. Pour explorer ce phénomène en profondeur, les chercheurs ont choisi le jeu Countdown comme principal banc d'essai.
Le compte à rebours est un casse-tête mathématique dans lequel le joueur doit combiner un ensemble donné de nombres pour atteindre un nombre cible en utilisant les quatre opérations de base que sont l'addition, la soustraction, la multiplication et la division. Par exemple, avec les nombres 25, 30, 3, 4 et le nombre cible 32, le joueur doit obtenir le nombre exact 32 par une série d'opérations, par exemple (30 - 25 + 3) × 4 = 32.
Le jeu Countdown a été choisi pour cette étude parce qu'il permet d'examiner les capacités de raisonnement mathématique, de planification et de stratégie de recherche du modèle, tout en offrant un espace de recherche relativement restreint qui permet au chercheur de mener des analyses approfondies. Par rapport à des domaines plus complexes, le jeu Countdown réduit la difficulté de l'analyse tout en permettant d'examiner efficacement un raisonnement complexe. En outre, le succès du jeu Countdown repose davantage sur les compétences en matière de résolution de problèmes que sur d'autres tâches mathématiques, plutôt que sur des connaissances mathématiques pures.
Les chercheurs ont choisi deux modèles de base, Qwen-2.5-3B et Llama-3.2-3B, pour comparer les différences d'apprentissage entre les différentes familles de modèles. Les expériences d'apprentissage par renforcement sont basées sur la bibliothèque VERL et mises en œuvre à l'aide de TinyZero. Ils ont utilisé l'algorithme PPO (Proximal Policy Optimization) pour entraîner le modèle pendant 250 étapes, en échantillonnant 4 trajectoires par repère. La raison du choix de l'algorithme PPO est que, par rapport à l'algorithme GRPO et d'autres algorithmes d'apprentissage par renforcement tels que REINFORCE, PPO fait preuve d'une meilleure stabilité en fonction de divers paramètres hyperparamétriques, bien que la différence de performance globale entre les algorithmes ne soit pas significative. (Note de l'éditeur : Il est possible que le terme "GRPO" soit une erreur d'écriture et qu'il faille lire "PPO".)
Les résultats expérimentaux révèlent des trajectoires d'apprentissage très différentes pour les deux modèles. Bien que les deux modèles aient des performances similaires au début de la tâche, avec des scores faibles, Qwen-2.5-3B présente un "saut qualitatif" autour de la 30e étape de la formation, comme en témoignent les réponses significativement plus longues générées par le modèle, et une augmentation significative de la précision. À la fin de la formation, Qwen-2.5-3B atteint une précision d'environ 601 TP3T, ce qui est beaucoup plus élevé que les 301 TP3T du lama-3.2-3B.
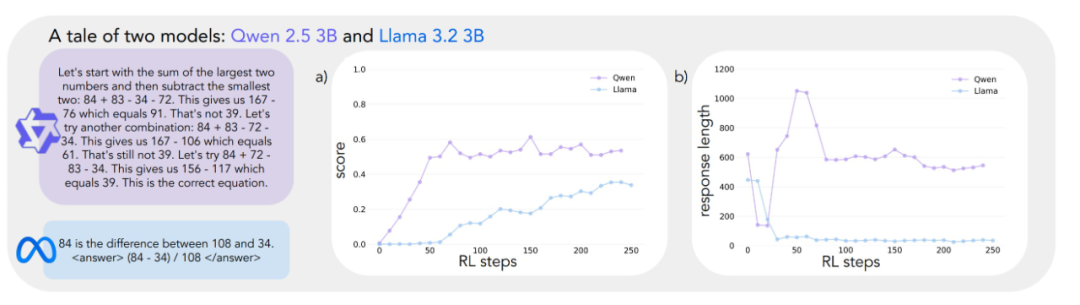
Au cours des dernières étapes de la formation, les chercheurs ont observé un changement intéressant dans le comportement de Qwen-2.5-3B : le modèle est progressivement passé de l'utilisation d'énoncés de validation explicites (par exemple, "8*35 est 280, trop élevé") à la vérification implicite de la solution. Le modèle последовательно (en russe, traduit par "последовательно land" ou "séquentiellement") essaie différentes solutions jusqu'à ce qu'il trouve la bonne, au lieu d'évaluer son propre travail à l'aide de mots. Le contraste est frappant. Ce contraste conduit à une question centrale : quelles sont les capacités sous-jacentes qui permettent à un modèle de s'auto-améliorer avec succès sur la base du raisonnement ? Pour répondre à cette question, il faut disposer d'un cadre systématique d'analyse du comportement cognitif.
Cadre de l'analyse cognitivo-comportementale
Afin de mieux comprendre les trajectoires d'apprentissage très différentes des deux modèles, les chercheurs ont mis au point un cadre permettant d'identifier et d'analyser les comportements cognitifs clés dans les résultats des modèles. Ce cadre se concentre sur quatre comportements de base :
- Retour en arrièreLes méthodes d'évaluation des risques : modifier explicitement la méthode lorsqu'une erreur est détectée (par exemple, "Cette méthode ne fonctionne pas parce que ..."). .").
- VérificationLes résultats intermédiaires sont systématiquement vérifiés (par exemple, "Validons ce résultat par..."). pour vérifier ce résultat").
- Définition des sous-objectifs... : Décomposer les problèmes complexes en étapes gérables (par exemple, "Pour résoudre ce problème, nous devons d'abord ..."). .
- Penser à l'enversDans les problèmes de raisonnement orienté vers un but, commencez par un résultat souhaité et travaillez à rebours pour trouver un chemin vers la solution (par exemple, "Pour atteindre le but de 75, nous avons besoin d'un nombre qui est ... divisible par ..."). .").
Ces comportements ont été choisis parce qu'ils représentent une stratégie de résolution de problèmes très différente des schémas de raisonnement linéaires et monotones courants dans les modèles de langage. Ces comportements cognitifs permettent des trajectoires de raisonnement plus dynamiques, proches de la recherche, où les solutions peuvent évoluer de manière non linéaire. Bien que cet ensemble de comportements ne soit pas exhaustif, les chercheurs les ont choisis parce qu'ils sont faciles à identifier et qu'ils correspondent naturellement aux stratégies humaines de résolution de problèmes dans les jeux de compte à rebours et dans des tâches de raisonnement mathématique plus larges, telles que la construction de preuves mathématiques.
Chaque comportement cognitif peut être compris à travers son rôle dans le raisonnement de la jeton Par exemple, le retour en arrière est représenté par l'annulation et le remplacement explicites des séquences de jetons des étapes précédentes. Par exemple, le retour en arrière est représenté par une séquence de jetons qui annulent et remplacent explicitement les étapes précédentes ; la validation est représentée par la génération de jetons qui comparent les résultats aux critères de solution ; le retour en arrière est représenté par des jetons qui construisent progressivement un chemin de solution vers l'état initial à partir du but ; et la définition de sous-objectifs est représentée par la suggestion explicite d'étapes intermédiaires à atteindre le long du chemin vers le but final. Les chercheurs ont développé un pipeline de classification utilisant le modèle GPT-4o-mini qui identifie de manière fiable ces modèles dans la sortie du modèle.
L'effet du comportement initial sur l'amélioration de soi
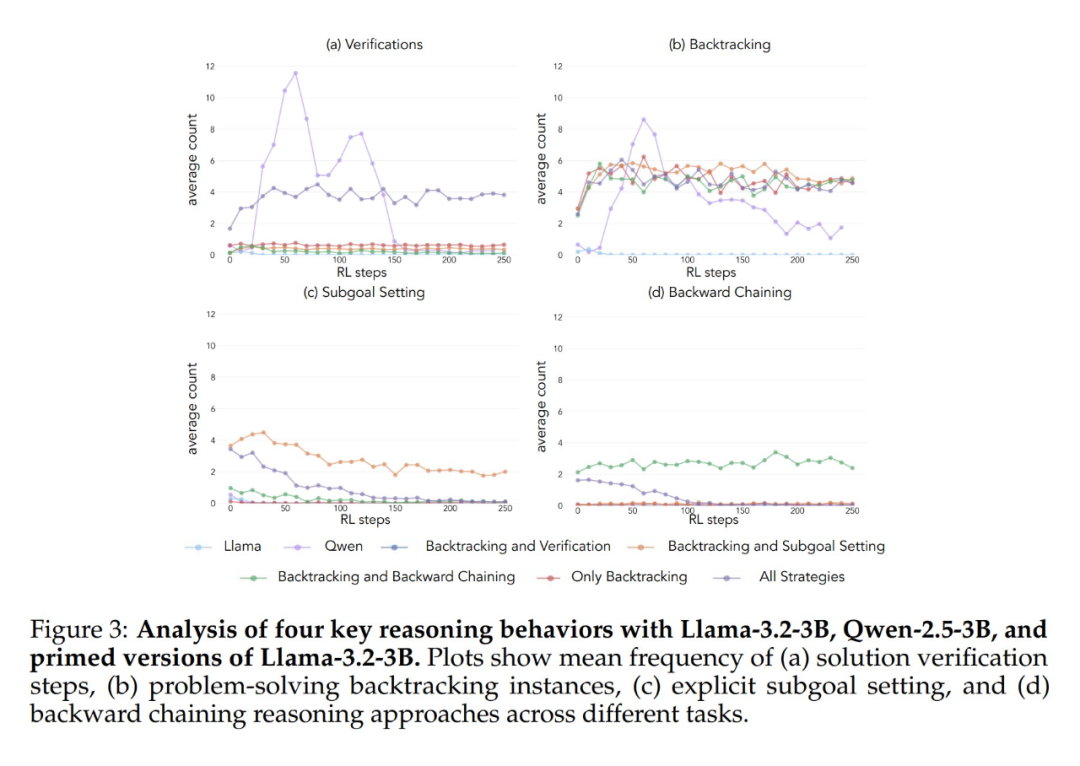
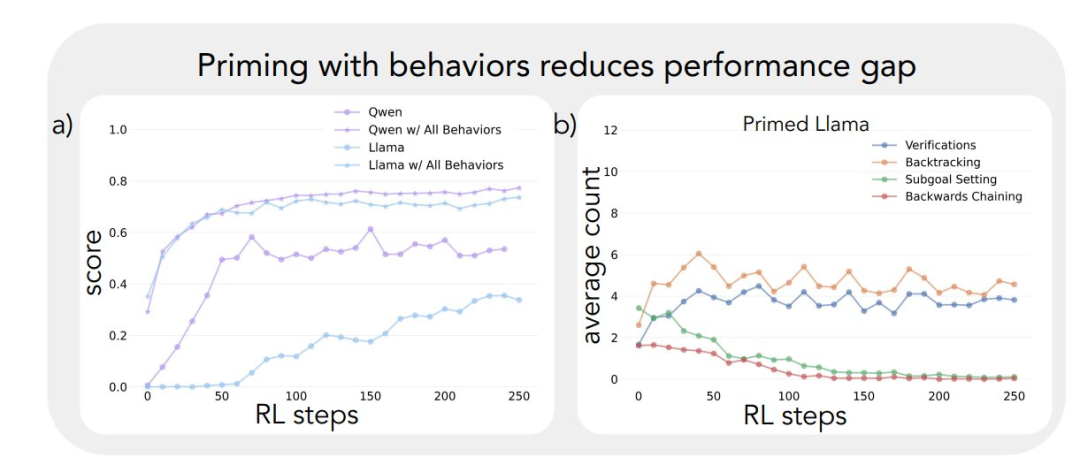
L'application du cadre analytique ci-dessus aux expériences initiales a permis de dégager une idée clé : L'amélioration significative des performances du modèle Qwen-2.5-3B se produit parallèlement à l'émergence de comportements cognitifs, en particulier de comportements de vérification et de retour en arrière. En revanche, le modèle Llama-3.2-3B a montré peu de signes de ces comportements tout au long de l'entraînement.
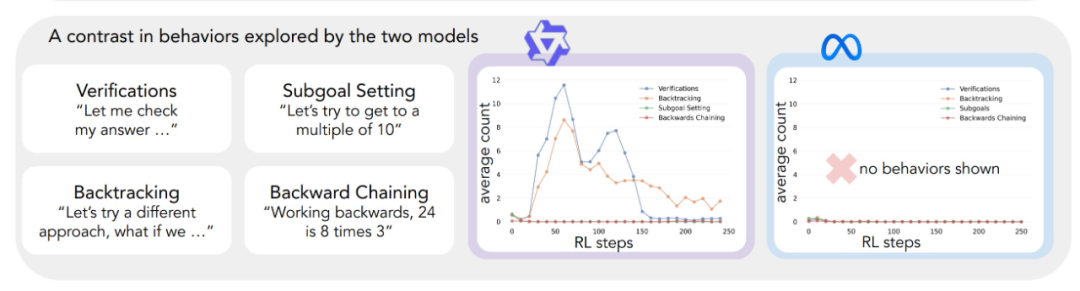
Afin de mieux comprendre cette différence, les chercheurs ont analysé les schémas de raisonnement de base des trois modèles : Qwen-2.5-3B, Llama-3.2-3B et Llama-3.1-70B. Les résultats des analyses ont montré que le modèle Qwen-2.5-3B produisait des proportions plus élevées de tous les comportements cognitifs que les deux variantes du modèle Llama, Llama-3.2-3B et Llama-3.1-70B. Le modèle Qwen-2.5-3B a produit une proportion plus élevée de tous les comportements cognitifs. Bien que le modèle Llama-3.1-70B, plus grand, ait généralement activé ces comportements plus fréquemment que le modèle Llama-3.2-3B, cette augmentation était inégale, en particulier pour les comportements rétrospectifs, qui sont restés limités même dans le modèle plus grand.

Ces observations révèlent deux choses importantes :
- La présence de certains comportements cognitifs dans la stratégie initiale peut être une condition préalable nécessaire pour que le modèle utilise efficacement l'augmentation du temps de calcul du test en étendant la séquence d'inférence.
- L'augmentation de la taille du modèle peut améliorer la fréquence de l'activation contextuelle de ces comportements cognitifs dans une certaine mesure.
Ce modèle est crucial car l'apprentissage par renforcement ne peut qu'amplifier les comportements déjà présents dans les trajectoires réussies. Cela signifie que la disponibilité initiale de ces comportements cognitifs est une condition préalable à un apprentissage efficace dans le modèle.
Intervenir sur le comportement initial : guider l'apprentissage du modèle
Après avoir établi l'importance des comportements cognitifs dans le modèle de base, la question suivante est la suivante : ces comportements peuvent-ils être induits artificiellement dans le modèle par des interventions ciblées ? Les chercheurs ont émis l'hypothèse qu'en créant des variantes du modèle de base qui affichent sélectivement des comportements cognitifs spécifiques avant la formation à l'apprentissage par renforcement, il serait possible de mieux comprendre quels modèles comportementaux sont essentiels à un apprentissage efficace.
Pour tester cette hypothèse, ils ont d'abord conçu sept ensembles de données de départ différents à l'aide du jeu Countdown. Cinq de ces jeux de données mettaient l'accent sur différentes combinaisons de comportements : toutes les combinaisons de stratégies, le retour en arrière uniquement, le retour en arrière et la validation, le retour en arrière et la définition d'un sous-objectif, et le retour en arrière et la réflexion à rebours. Ils ont utilisé le modèle Claude-3.5-Sonnet pour générer ces ensembles de données en raison de la capacité de Claude-3.5-Sonnet à générer des trajectoires d'inférence avec des caractéristiques comportementales spécifiées avec précision.
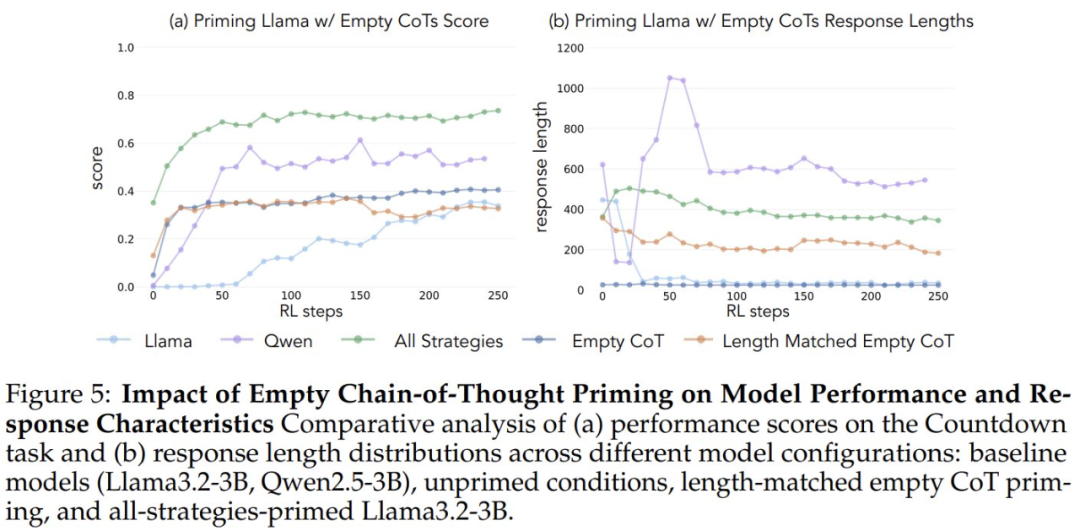
Afin de vérifier que les gains de performance étaient dus à des comportements cognitifs spécifiques et non à une simple augmentation du temps de calcul, les chercheurs ont également introduit deux conditions de contrôle : une chaîne de pensée vide et une condition de contrôle qui remplissait la chaîne de jetons fictifs et faisait correspondre la longueur des points de données à l'ensemble de données "toutes les combinaisons de stratégies". L'ensemble de données "toutes les combinaisons de stratégies". Ces ensembles de données de contrôle ont aidé les chercheurs à vérifier que toute amélioration des performances observée était en fait due à des comportements cognitifs spécifiques, plutôt qu'à une simple augmentation du temps de calcul.
En outre, les chercheurs ont créé une variante de l'ensemble de données "Full Strategy Combination", qui ne contient que des solutions incorrectes, mais conserve les schémas de raisonnement requis. L'objectif de cette variante est de distinguer la différence entre l'importance du comportement cognitif et la précision des solutions.
Les résultats expérimentaux montrent que les modèles Llama-3 et Qwen-2.5-3B présentent des améliorations significatives des performances grâce à l'apprentissage par renforcement lorsqu'ils sont initialisés avec un ensemble de données contenant un comportement rétrospectif. L'analyse comportementale montre en outre que L'apprentissage par renforcement amplifie de manière sélective les comportements dont l'utilité a été empiriquement démontrée, tout en inhibant d'autres comportements. Par exemple, dans la condition de combinaison complète de stratégies, le modèle conserve et renforce les comportements rétrospectifs et de validation, tout en réduisant la fréquence des comportements de réflexion rétrospective et de fixation de sous-objectifs. Cependant, lorsqu'il est associé uniquement à des comportements rétrospectifs, les comportements supprimés (par exemple, la réflexion rétrospective et la définition d'un sous-objectif) persistent tout au long de l'entraînement.
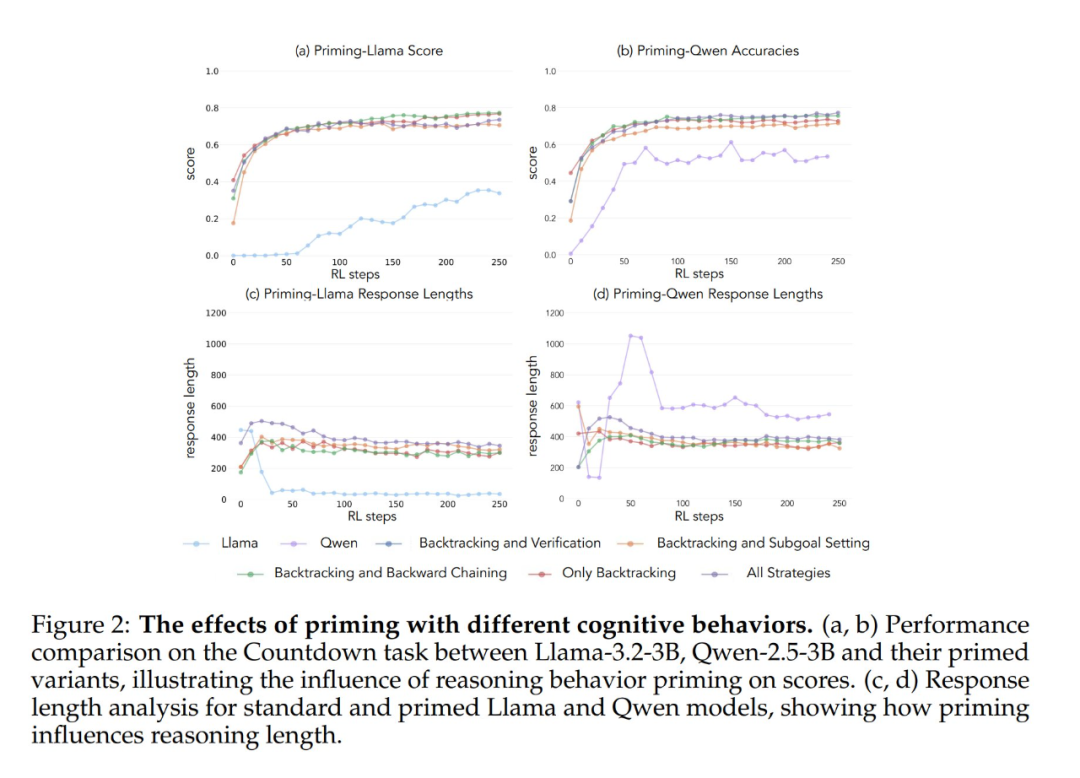
Lorsqu'ils ont été initiés en utilisant une chaîne de pensée vide comme condition de contrôle, les deux modèles ont obtenu des résultats comparables à ceux du modèle Llama-3 de base (précision d'environ 30%-35%). Cela suggère que la simple attribution de jetons supplémentaires sans inclure les comportements cognitifs n'est pas une utilisation efficace du calcul du temps de test. Plus surprenant encore, l'entraînement avec des chaînes de pensée vides a même eu un effet néfaste, puisque le modèle Qwen-2.5-3B a cessé d'explorer de nouveaux modèles de comportement. Il s'agit là d'une preuve supplémentaire que Ces comportements cognitifs sont essentiels pour que le modèle utilise efficacement les ressources informatiques étendues grâce à des séquences d'inférence plus longues.
Plus surprenant encore, les modèles initialisés avec des solutions incorrectes, mais avec un comportement cognitif correct, ont atteint presque le même niveau de performance que les modèles formés sur des ensembles de données contenant des solutions correctes. Ce résultat suggère fortement que La présence de comportements cognitifs (plutôt que l'acquisition de réponses correctes) est un facteur clé de la réussite de l'amélioration de soi par l'apprentissage par renforcement. Ainsi, les schémas de raisonnement issus de modèles relativement faibles peuvent guider efficacement le processus d'apprentissage pour construire des modèles plus solides. Cela prouve une fois de plus que La présence d'un comportement cognitif est plus importante que la justesse du résultat.

Sélection comportementale dans les données de pré-entraînement
Les résultats de ces expériences suggèrent que certains comportements cognitifs sont essentiels à l'auto-amélioration des modèles. Cependant, les méthodes utilisées pour induire des comportements spécifiques dans les modèles initiaux de l'étude précédente étaient spécifiques à un domaine et reposaient sur des jeux de compte à rebours. Cela peut nuire à la capacité de généralisation de l'inférence finale. Est-il donc possible d'augmenter la fréquence des comportements d'inférence bénéfiques en modifiant la distribution des données de préformation pour le modèle afin d'obtenir une capacité d'auto-amélioration plus générale ?
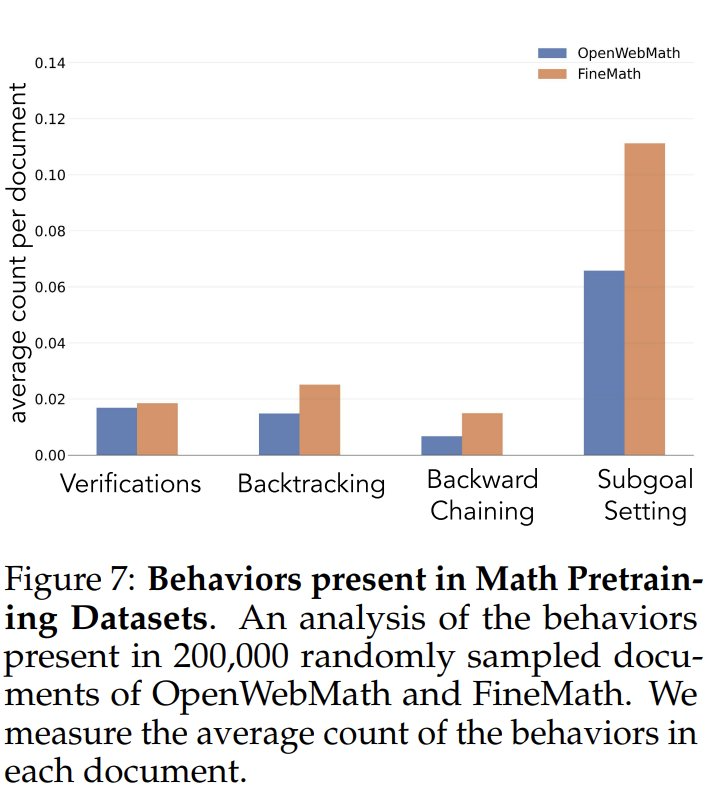
Afin d'étudier la fréquence des comportements cognitifs dans les données de préformation, les chercheurs ont d'abord analysé les fréquences naturelles des comportements cognitifs dans les données de préformation. Ils se sont concentrés sur les ensembles de données OpenWebMath et FineMath, qui ont été conçus spécifiquement pour le raisonnement mathématique. En utilisant le modèle Qwen-2.5-32B comme classificateur, les chercheurs ont analysé 200 000 documents sélectionnés au hasard dans ces deux ensembles de données pour détecter la présence du comportement cognitif cible. Les résultats ont montré que même dans ces corpus axés sur les mathématiques, la fréquence des comportements cognitifs tels que le retour en arrière et la validation restait faible. Cela suggère que les processus de préformation standard ont limité l'exposition à ces comportements clés.
Pour vérifier si l'augmentation artificielle de l'exposition aux comportements cognitifs renforce le potentiel d'auto-amélioration du modèle, les chercheurs ont développé un ensemble de données de pré-entraînement continu ciblé à partir de l'ensemble de données OpenWebMath. Ils ont d'abord utilisé le modèle Qwen-2.5-32B comme classificateur pour analyser les documents mathématiques du corpus de pré-entraînement afin d'identifier la présence du comportement de raisonnement cible. Sur cette base, ils ont créé deux ensembles de données de comparaison : un ensemble riche en comportements cognitifs et un ensemble de données de contrôle avec très peu de contenu cognitif. Ils ont ensuite utilisé le modèle Qwen-2.5-32B pour réécrire chaque document des deux ensembles de données dans un format structuré de questions-réponses, tout en préservant la présence ou l'absence naturelle de comportements cognitifs dans les documents sources. Cette approche a permis aux chercheurs d'isoler efficacement les effets du comportement de raisonnement tout en contrôlant le format et la quantité de contenu mathématique pendant la préformation.
Après avoir pré-entraîné le modèle Llama-3.2-3B sur ces ensembles de données et appliqué l'apprentissage par renforcement, les chercheurs ont observé :
- Les modèles pré-entraînés riches en comportement atteignent finalement un niveau de performance comparable à celui du modèle Qwen-2.5-3B, avec une amélioration relativement limitée de la performance du modèle de contrôle.
- L'analyse comportementale des modèles post-entraînement a montré que la variante enrichie sur le plan comportemental du modèle pré-entraîné a maintenu une forte activation du comportement d'inférence tout au long du processus d'entraînement, tandis que le modèle de contrôle a présenté des schémas comportementaux similaires à ceux du modèle Llama-3 de base.
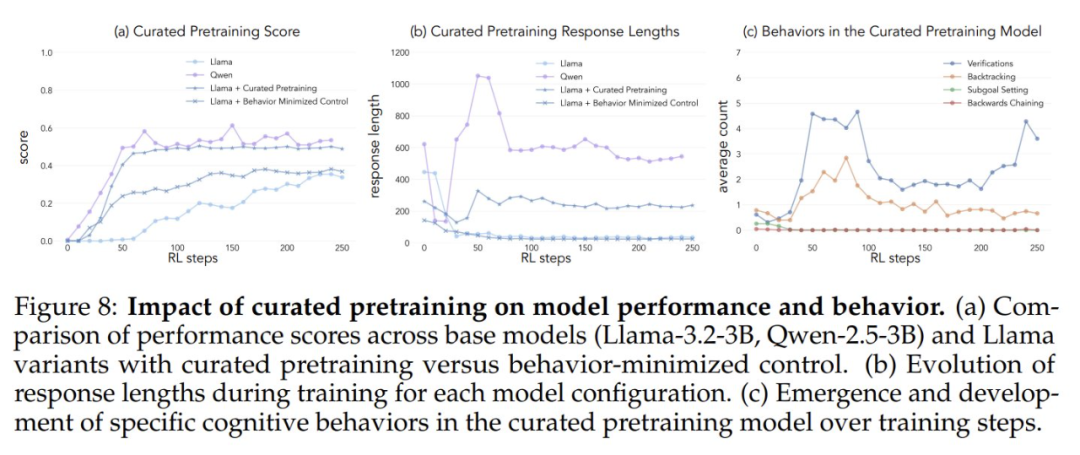
Les résultats de ces expériences suggèrent fortement que La modification ciblée des données de pré-entraînement peut générer avec succès les comportements cognitifs clés nécessaires à une amélioration efficace de soi par le biais de l'apprentissage par renforcement. Cette étude fournit de nouvelles idées et méthodes pour comprendre et améliorer les capacités d'auto-amélioration des grands modèles de langage. Pour plus de détails, veuillez vous référer à l'article original.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes



Pas de commentaires...