
Combien de temps un grand modèle peut-il comprendre une vidéo ? Smart Spectrum GLM-4V-Plus : 2 heures


Sur la base des deux générations précédentes de modèles vidéo (CogVLM2-Video et GLM-4V-PLUS), nous avons encore optimisé les techniques de compréhension vidéo avec la sortie de la version bêta GLM-4V-Plus-0111. Cette version introduit des techniques telles que la résolution variable native, qui améliore la capacité du modèle à s'adapter à différentes longueurs et résolutions de vidéo.
- Compréhension plus détaillée des vidéos courtes : pour les contenus de courte durée, le modèle prend en charge les vidéos natives en haute résolution afin de garantir une capture précise des informations détaillées.
- Meilleure compréhension des vidéos longues : face à des vidéos d'une durée maximale de 2 heures, le modèle peut s'adapter automatiquement à une résolution plus petite, équilibrant ainsi efficacement la capture d'informations temporelles et spatiales afin de permettre une compréhension approfondie des vidéos longues.
Avec cette mise à jour, la version bêta GLM-4V-Plus-0111 ne se contente pas de conserver les avantages des deux générations précédentes de modèles en termes de Q&R temporel, mais apporte également des améliorations significatives en termes de longueur de vidéo et d'adaptabilité de la résolution.
I. Comparaison des performances
Dans la nouvelle version du modèle Smart Spectrum Realtime, 4V, Air, publiée récemment et synchronisée avec le nouvel article sur l'API, nous avons détaillé les résultats de l'examen du modèle GLM-4V-Plus-0111 (bêta) dans le domaine de la compréhension d'images. Le modèle a atteint le niveau sota sur plusieurs listes d'évaluation publiques.
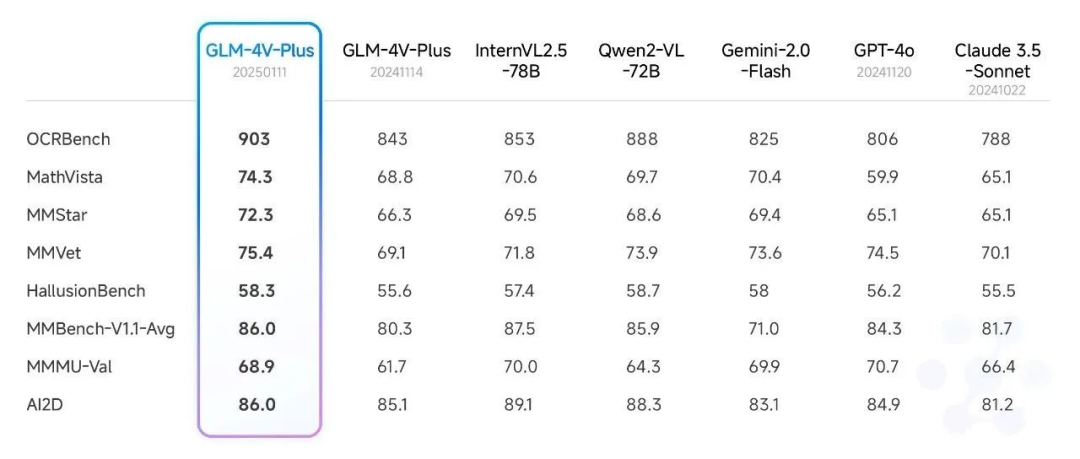
En outre, nous avons également effectué un test complet par rapport à un ensemble d'examens de compréhension vidéo faisant autorité, et nous avons également atteint un niveau relativement élevé. En particulier, le modèle bêta GLM-4V-Plus-0111 surpasse de manière significative les modèles de compréhension vidéo comparables en termes de compréhension fine de l'action dans la vidéo et de compréhension de la vidéo longue.
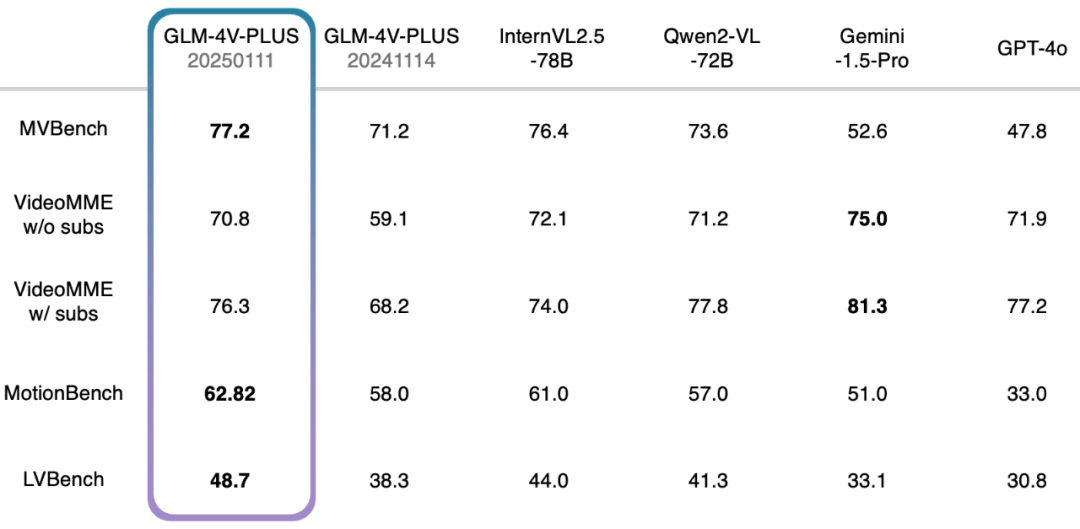
- MVBench : cet ensemble d'examens se compose de 20 tâches vidéo complexes conçues pour évaluer de manière exhaustive les capacités combinées des macromodèles multimodaux dans la compréhension des vidéos.
- VideoMME w/o subs : en tant que référence d'évaluation multimodale, VideoMME est utilisé pour évaluer les capacités d'analyse vidéo des grands modèles de langage. Dans ce cas, la version w/o subs désigne une entrée multimodale sans sous-titres, se concentrant sur l'analyse de la vidéo elle-même.
- VideoMME w/ subs : similaire à la version w/o subs, mais avec l'ajout de sous-titres en tant qu'entrées multimodales afin de fournir une évaluation plus complète de la performance globale du modèle lorsqu'il traite des données multimodales.
- MotionBench : axé sur la compréhension fine des mouvements, MotionBench est un ensemble de données de référence complet contenant diverses données vidéo et des annotations humaines de haute qualité pour évaluer les capacités des modèles de compréhension vidéo pour l'analyse des mouvements.
- LVBench : Destiné à évaluer la capacité du modèle à comprendre de longues vidéos, LVBench met à l'épreuve les performances des modèles multimodaux lorsqu'ils traitent de longues tâches vidéo, et vérifie la stabilité et la précision des modèles dans l'analyse de longues séries temporelles.
II. application du scénario
Au cours de l'année écoulée, les domaines d'application des modèles de compréhension vidéo se sont élargis, offrant diverses capacités telles que la génération de descriptions vidéo, la segmentation des événements, la classification, l'étiquetage et l'analyse des événements pour les nouveaux médias, la publicité, l'examen de la sécurité, la fabrication industrielle et d'autres industries. Notre nouveau modèle de compréhension vidéo GLM-4V-Plus-0111 beta hérite de ces fonctions de base et les renforce, tout en améliorant les capacités de traitement et d'analyse des données vidéo.
Capacité de description vidéo plus précise : en s'appuyant sur des entrées de résolution natives et sur l'optimisation continue des fantômes de données, le nouveau modèle réduit considérablement le taux de fantômes dans la génération de descriptions vidéo et permet une description plus complète du contenu vidéo, fournissant aux utilisateurs des informations vidéo plus précises et plus riches.


Traitement efficace des données vidéo : le nouveau modèle permet non seulement de fournir des descriptions vidéo détaillées, mais aussi de réaliser efficacement les tâches de classification, de génération de titres et d'étiquetage des vidéos. Les utilisateurs peuvent encore améliorer l'efficacité du traitement en personnalisant les messages-guides ou en créant des processus de données vidéo automatisés pour une gestion intelligente.

Prise en compte précise du temps : en réponse à la nature temporelle des données vidéo, notre modèle a été consacré à l'amélioration des capacités d'interrogation temporelle depuis sa première génération. Aujourd'hui, le nouveau modèle peut localiser avec plus de précision les points temporels d'événements spécifiques, permettre la segmentation sémantique et l'édition automatisée de vidéos, et fournir un support puissant pour l'édition et l'analyse de vidéos.
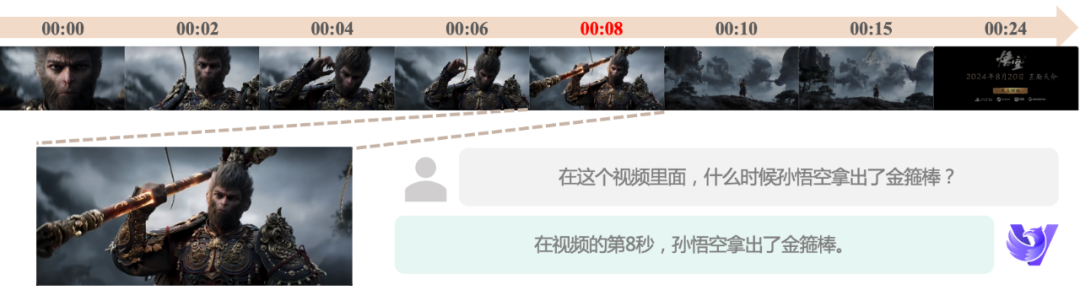
Capacité de compréhension fine du mouvement : le nouveau modèle prend en charge des entrées à fréquence d'images plus élevée, ce qui permet de capturer de petits changements de mouvement et de parvenir à une compréhension fine du mouvement même lorsque la fréquence d'images vidéo est faible, ce qui constitue une garantie solide pour les scénarios d'application qui nécessitent une analyse précise du mouvement.


Compréhension vidéo ultra longue : grâce à une technologie innovante de résolution variable, le nouveau modèle dépasse les limites du temps de traitement vidéo et prend en charge jusqu'à 2 heures de compréhension vidéo, ce qui élargit considérablement les scénarios d'application commerciale du modèle de compréhension vidéo ; voici une démonstration d'une heure de compréhension vidéo :

Capacité d'appel vidéo en temps réel : sur la base d'un puissant modèle de compréhension vidéo, nous avons développé un modèle d'appel vidéo en temps réel, GLM-Realtime, avec une capacité de compréhension vidéo et de questions-réponses en temps réel, et une mémoire d'appel pouvant aller jusqu'à 2 minutes. Le modèle est désormais en lignePlate-forme ouverte Smart Spectrum AIGLM-Realtime aide non seulement les clients à créer des appels vidéo intelligents, mais peut également être combiné avec du matériel en réseau existant pour créer facilement des maisons intelligentes, des jouets d'IA, des lunettes d'IA et d'autres produits innovants.
Actuellement, les utilisateurs ordinaires peuvent également passer des appels vidéo avec l'IA sur l'application Smart Spectrum Clear Speech.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes




Pas de commentaires...