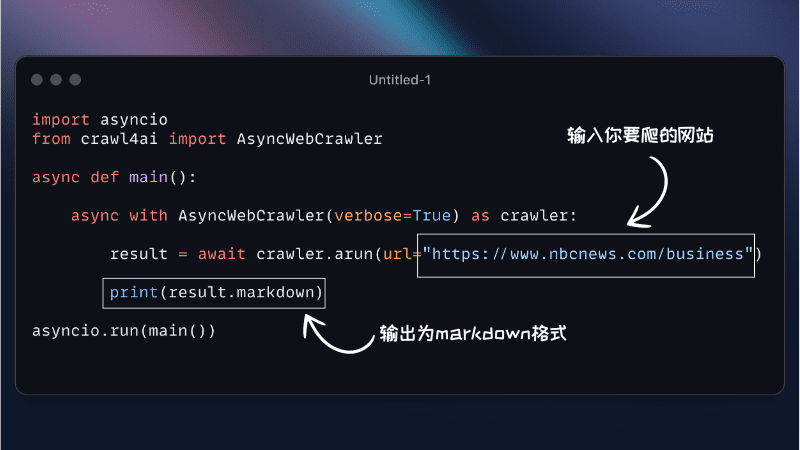
Crawl4AI : outil open source d'exploration asynchrone du web pour extraire des données structurées sans LLM

Introduction générale
Crawl4AI est un outil d'exploration du web asynchrone open source conçu pour les grands modèles de langage (LLM) et les applications d'intelligence artificielle (IA). Il simplifie le processus d'exploration du web et d'extraction de données, supporte une exploration efficace du web, et fournit des formats de sortie adaptés aux LLM tels que JSON, HTML nettoyé et Markdown.Crawl4AI supporte l'exploration de plusieurs URL en même temps, entièrement gratuit et open source, adapté à une variété de besoins d'exploration de données.
Documentation d'aide officielle
Liste des fonctions
- Architecture asynchrone : traitement efficace de plusieurs pages web, exploration rapide des données
- Formats de sortie multiples : Prise en charge de JSON, HTML, Markdown
- Exploration multi-URL : exploration de plusieurs pages web en même temps
- Extraction des balises média : extraction des balises d'images, d'audio et de vidéo
- Extraction de liens : extraction de tous les liens externes et internes
- Extraction de métadonnées : extraction de métadonnées à partir de pages
- Crochets personnalisés : prise en charge de l'authentification, des en-têtes de requête et des modifications de page
- Personnalisation des agents utilisateurs : personnalisation des agents utilisateurs
- Capture d'écran de la page : Capture d'écran de la page d'exploration
- Exécuter un JavaScript personnalisé : Exécuter plusieurs JavaScripts personnalisés avant l'exploration.
- Assistance par procuration : renforcer la protection de la vie privée et l'accès à l'information
- Gestion des sessions : gérer des scénarios complexes d'exploration multi-pages
Utiliser l'aide
Processus d'installation
Crawl4AI offre des options d'installation flexibles pour une variété de scénarios d'utilisation. Vous pouvez l'installer en tant que paquetage Python ou utiliser Docker.
Installation avec pip
- Installation de base
pip install crawl4aiCeci installera par défaut la version asynchrone de Crawl4AI, en utilisant Playwright pour l'exploration du web.
- Installation manuelle de Playwright (si nécessaire)
playwright installou
python -m playwright install chromium
Installation avec Docker
- Extraction d'une image Docker
docker pull unclecode/crawl4ai - Exécution des conteneurs Docker
docker run -it unclecode/crawl4ai
Lignes directrices pour l'utilisation
- Utilisation de base
from crawl4ai import AsyncWebCrawler crawler = AsyncWebCrawler() results = crawler.crawl(["https://example.com"]) print(results) - Paramètres personnalisés
from crawl4ai import AsyncWebCrawler crawler = AsyncWebCrawler( user_agent="CustomUserAgent", headers={"Authorization": "Bearer token"}, custom_js=["console.log('Hello, world!')"] ) results = crawler.crawl(["https://example.com"]) print(results) - Extraction de données spécifiques
from crawl4ai import AsyncWebCrawler crawler = AsyncWebCrawler() results = crawler.crawl(["https://example.com"], extract_media=True, extract_links=True) print(results) - Gestion des sessions
from crawl4ai import AsyncWebCrawler crawler = AsyncWebCrawler() session = crawler.create_session() session_results = session.crawl(["https://example.com"]) print(session_results)
Crawl4AI offre un ensemble riche de fonctionnalités et d'options de configuration flexibles pour une variété de besoins en matière d'exploration de sites web et de données. Grâce à des guides d'installation et d'utilisation détaillés, les utilisateurs peuvent facilement démarrer et profiter pleinement des puissantes fonctionnalités de l'outil.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...